
10 问 10 答,带你快速入门前端算法
引言
各位大佬好,本节主要内容包括:
前端进阶算法1:如何分析、统计算法的执行效率和资源消耗? 前端进阶算法2:从Chrome V8源码看JavaScript数组(附赠腾讯面试题) 前端进阶算法3:从浏览器缓存淘汰策略和Vue的keep-alive学习LRU算法 前端进阶算法4:链表原来如此简单(+leetcode刷题) ... 下面进入正文吧👇
一、前端进阶算法1:如何分析、统计算法的执行效率和资源消耗?
好的数据结构与算法能够大大缩短代码的执行时间与存储空间,那么我们如何去衡量它喃?这节就主要介绍算法性能的衡量指标—复杂度分析。
复杂度可分为:
时间复杂度 空间复杂度
1. 如何表示算法复杂度?
通常采用 大 O 表示法 来表示复杂度。它并不代表真正的执行时间或存储空间消耗,而是表示代码执行时间随数据规模增长的变化趋势(时间复杂度)或存储空间随数据规模增长的变化趋势(空间复杂度),所以,也叫作渐进时间(或空间)复杂度(asymptotic time complexity),简称时间(或空间)复杂度。
2. 常见复杂度
多项式量级:
常量阶:O(1):当算法中不存在循环语句、递归语句,即使有成千上万行的代码,其时间复杂度也是Ο(1) 对数阶:O(logn): 简单介绍一下
let i=1;
while (i <= n) {
i = i * 2;
}
每次循环 i都乘以2,直至i > n,即执行过程是:20、21、22、…、2k、…、2x、 n
所以总执行次数 x ,可以写成 2x = n ,则时间复杂度为 O(log2n) 。这里是2,也可以是其他常量k,时间复杂度也是:O(log~3~n) = O(log32 * log2n) = O(log2n)线性阶:O(n) 线性对数阶:O(nlogn) 平方阶、立方阶、….、k次方阶:O(n2)、O(n3)、…、O(nk)
非多项式量阶:
指数阶:O(2n) 阶乘阶:O(n!)
3. 复杂度的划分
以时间复杂度为例,时间复杂度受数据本身影响,还分为:
最好时间复杂度:在最理想的情况下,执行这段代码的时间复杂度 最坏时间复杂度:在最糟糕的情况下,执行这段代码的时间复杂度 平均时间复杂度:所有情况下,求一个平均值,可以省略掉系数、低阶、常量
详情:前端进阶算法1:如何分析、统计算法的执行效率和资源消耗?[10]
二、前端进阶算法2:从Chrome V8源码看JavaScript数组(附赠腾讯面试题)
1. JavaScript 中,数组的应用
let arr = [1, 2, 3]
它的这种特定的存储结构决定了:
优点
随机访问:可以通过下标随机访问数组中的任意位置上的数据
缺点
对数据的删除和插入不是很友好
查找: 根据下标随机访问的时间复杂度为 O(1);
插入或删除: 时间复杂度为 O(n);
在 JavaScript 中的数组几乎是万能的,它不光可以作为一个普通的数组使用,可以作为栈或队列使用。
数组:
let array = [1, 2, 3]
栈:
let stack = [1, 2, 3]
// 进栈
stack.push(4)
// 出栈
stcak.pop()
队列:
let queue = [1, 2, 3]
// 进队
queue.push(4)
// 出队
queue.shift()
2. JavaScript 中,数组的独特之处
我们知道在 JavaScript 中,可以在数组中保存不同类型值,并且数组可以动态增长,不像其它语言,例如 C,创建的时候要决定数组的大小,如果数组满了,就要重新申请内存空间。这是为什么喃?
JavaScript 中, JSArray 继承自 JSObject ,或者说它就是一个特殊的对象,内部是以 key-value 形式存储数据,所以 JavaScript 中的数组可以存放不同类型的值。它有两种存储方式,快数组与慢数组,初始化空数组时,使用快数组,快数组使用连续的内存空间,当数组长度达到最大时,JSArray 会进行动态的扩容,以存储更多的元素,相对慢数组,性能要好得多。当数组中 hole 太多时,会转变成慢数组,即以哈希表的方式( key-value 的形式)存储数据,以节省内存空间。
具体快慢数组、动态扩容前往:前端进阶算法2:从Chrome V8源码看JavaScript数组(附赠腾讯面试题)[11]
三、前端进阶算法3:从浏览器缓存淘汰策略和Vue的keep-alive学习LRU算法
1. 浏览器缓存淘汰策略
当我们打开一个网页时,例如 https://github.com/sisterAn/JavaScript-Algorithms ,它会在发起真正的网络请求前,查询浏览器缓存,看是否有要请求的文件,如果有,浏览器将会拦截请求,返回缓存文件,并直接结束请求,不会再去服务器上下载。如果不存在,才会去服务器请求。
其实,浏览器中的缓存是一种在本地保存资源副本,它的大小是有限的,当我们请求数过多时,缓存空间会被用满,此时,继续进行网络请求就需要确定缓存中哪些数据被保留,哪些数据被移除,这就是浏览器缓存淘汰策略,最常见的淘汰策略有 FIFO(先进先出)、LFU(最少使用)、LRU(最近最少使用)。
LRU ( Least Recently Used :最近最少使用 )缓存淘汰策略,故名思义,就是根据数据的历史访问记录来进行淘汰数据,其核心思想是 如果数据最近被访问过,那么将来被访问的几率也更高 ,优先淘汰最近没有被访问到的数据。
画个图帮助我们理解 LRU:

2. Vue 的 keep-alive 源码解读
在 keep-alive 缓存超过 max 时,使用的缓存淘汰算法就是 LRU 算法,它在实现的过程中用到了 cache 对象用于保存缓存的组件实例及 key 值,keys 数组用于保存缓存组件的 key ,当 keep-alive 中渲染一个需要缓存的实例时:
判断缓存中是否已缓存了该实例,缓存了则直接获取,并调整 key在keys中的位置(移除keys中key,并放入keys数组的最后一位)如果没有缓存,则缓存该实例,若 keys的长度大于max(缓存长度超过上限),则移除keys[0]缓存
主要实现LRU代码:
// --------------------------------------------------
// 下面就是 LRU 算法了,
// 如果在缓存里有则调整,
// 没有则放入(长度超过 max,则淘汰最近没有访问的)
// --------------------------------------------------
// 如果命中缓存,则从缓存中获取 vnode 的组件实例,
// 并且调整 key 的顺序放入 keys 数组的末尾
if (cache[key]) {
vnode.componentInstance = cache[key].componentInstance;
// make current key freshest
remove(keys, key);
keys.push(key);
}
// 如果没有命中缓存,就把 vnode 放进缓存
else {
cache[key] = vnode;
keys.push(key);
// prune oldest entry
// 如果配置了 max 并且缓存的长度超过了 this.max,还要从缓存中删除第一个
if (this.max && keys.length > parseInt(this.max)) {
pruneCacheEntry(cache, keys[0], keys, this._vnode);
}
}
源码详情:前端进阶算法3:从浏览器缓存淘汰策略和Vue的keep-alive学习LRU算法[12]
四、前端进阶算法4:链表原来如此简单(+leetcode刷题)
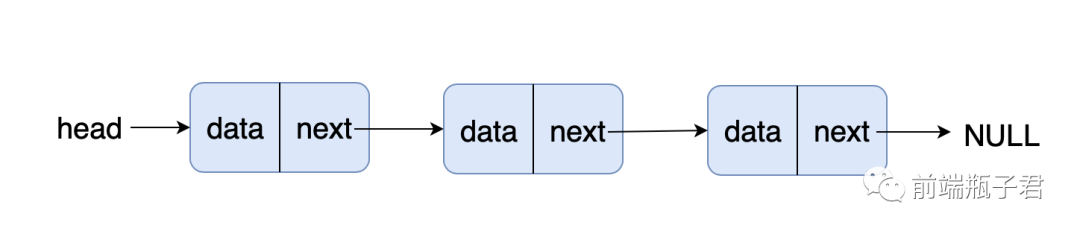
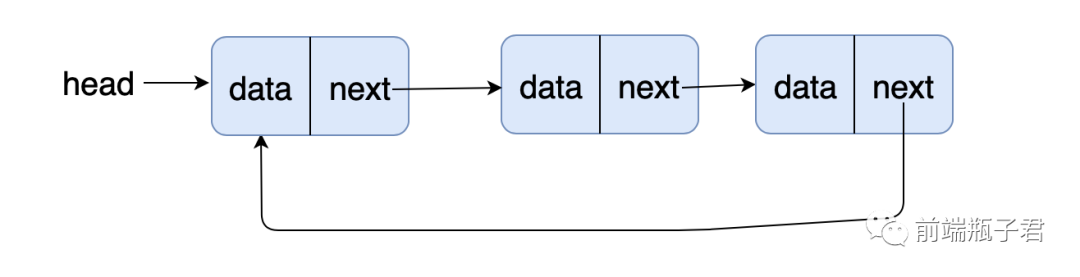
1. 图解链表
常用的链表类型有单链表、双链表以及循环链表,其中 next 为后继指针,指向它的后继节点,prev 为前驱指针,指向它的前驱节点。
单链表
双链表

循环链表
2. 链表复杂度一览表
单链表
| 操作方法 | 时间复杂度 | 说明 |
|---|---|---|
| append | O(n) | 在链表尾部追加节点 |
| search | O(n) | 在链表中查找任意元素 |
| insert | O(n) | 在链表中任意位置插入一个节点 |
| remove | O(n) | 删除链表中任意位置的一个节点 |
| searchNext | O(1) | 查找某节点的后继节点 |
| insertNext | O(1) | 在某一节点后插入一个节点(后继节点) |
| removeNext | O(1) | 在某一节点后删除一个节点(后继节点) |
双链表
| 操作方法 | 时间复杂度 | 说明 |
|---|---|---|
| search | O(n) | 在链表中查找任意元素 |
| insert | O(n) | 在链表中任意位置插入一个节点 |
| remove | O(n) | 删除链表中任意位置的一个节点 |
| searchNext 或 searchPre | O(1) | 查找某节点的后继节点或前驱节点 |
| insertNext 或 insertPre | O(1) | 插入某节点的后继节点或前驱节点 |
| removeNext 或 removePre | O(1) | 删除某节点的前驱节点或后继节点 |
循环链表
| 操作方法 | 时间复杂度 | 说明 |
|---|---|---|
| search | O(n) | 在链表中查找任意元素 |
| insert | O(n) | 在链表中任意位置插入一个节点 |
| remove | O(n) | 删除链表中任意位置的一个节点 |
| searchNext | O(1) | 查找某节点的后继节点 |
| insertNext | O(1) | 在某一节点后插入一个节点(后继节点) |
| removeNext | O(1) | 在某一节点后删除一个节点(后继节点) |
详情:前端进阶算法4:链表原来如此简单(+leetcode刷题)[13]
五、图解leetcode88:合并两个有序数组
1. 题目
给你两个有序整数数组 nums1 和 nums2,请你将 nums2 合并到 nums1 中,使 num1 成为一个有序数组。
说明:
初始化 nums1 和 nums2 的元素数量分别为 m 和 n 。你可以假设 nums1 有足够的空间(空间大小大于或等于 m + n )来保存 nums2 中的元素。
示例:
输入:
nums1 = [1,2,3,0,0,0], m = 3
nums2 = [2,5,6], n = 3
输出: [1,2,2,3,5,6]
2. 解答
解题思路:

nums1、nums2有序,若把nums2全部合并到nums1,则合并后的nums1长度为m+n我们可以从下标 m+n-1的位置填充nums1,比较nums1[len1]与nums2[len2]的大小,将最大值写入nums1[len],即nums1[len1]>=nums2[len2],nums1[len--] = nums1[len1--],这里--是因为写入成功后,下标自动建议,继续往前比较否则 nums1[len--] = nums2[len2--]边界条件: 若 len1 < 0,即len2 >= 0,此时nums1已重写入,nums2还未合并完,仅仅需要将nums2的剩余元素(0…len)写入nums2即可,写入后,合并完成若 len2 < 0,此时nums2已全部合并到nums1,合并完成
时间复杂度为 O(m+n)
代码实现:
var merge = function(nums1, m, nums2, n) {
let len1 = m - 1,
len2 = n - 1,
len = m + n - 1
while(len2 >= 0) {
if(len1 < 0) {
nums1[len--] = nums2[len2--]
continue
}
nums1[len--] = nums1[len1] >= nums2[len2] ? nums1[len1--]: nums2[len2--]
}
};
3. 更多解答请看:图解leetcode88:合并两个有序数组[14]
六、字节&leetcode1:两数之和
1. 题目
给定一个整数数组 nums 和一个目标值 target ,请你在该数组中找出和为目标值的那 两个 整数,并返回他们的数组下标。
你可以假设每种输入只会对应一个答案。但是,你不能重复利用这个数组中同样的元素。
示例:
给定 nums = [2, 7, 11, 15], target = 9
因为 nums[0] + nums[1] = 2 + 7 = 9
所以返回 [0, 1]
2. 解答
解题思路:
初始化一个 map = new Map()从第一个元素开始遍历 nums获取目标值与 nums[i]的差值,即k = target - nums[i],判断差值在map中是否存在不存在( map.has(k)为false) ,则将nums[i]加入到map中(key为nums[i], value为i,方便查找map中是否存在某值,并可以通过get方法直接拿到下标)存在( map.has(k)),返回[map.get(k), i],求解结束遍历结束,则 nums中没有符合条件的两个数,返回[]
时间复杂度:O(n)
代码实现:
var twoSum = function(nums, target) {
let map = new Map()
for(let i = 0; i< nums.length; i++) {
let k = target-nums[i]
if(map.has(k)) {
return [map.get(k), i]
}
map.set(nums[i], i)
}
return [];
};
3. 更多解答请看:字节&leetcode1:两数之和[15]
七、腾讯:数组扁平化、去重、排序
1. 题目
已知如下数组:var arr = [ [1, 2, 2], [3, 4, 5, 5], [6, 7, 8, 9, [11, 12, [12, 13, [14] ] ] ], 10];
编写一个程序将数组扁平化去并除其中重复部分数据,最终得到一个升序且不重复的数组
2. 答案:
var arr = [ [1, 2, 2], [3, 4, 5, 5], [6, 7, 8, 9, [11, 12, [12, 13, [14] ] ] ], 10]
// 扁平化
let flatArr = arr.flat(4)
// 去重
let disArr = Array.from(new Set(flatArr))
// 排序
let result = disArr.sort(function(a, b) {
return a-b
})
console.log(result)
// [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14]
感谢 352800205 的补充:flat() 方法对node版本有要求,至少需要12.0以上
3. 更多解答请看:腾讯:数组扁平化、去重、排序[16]
八、leetcode349:给定两个数组,编写一个函数来计算它们的交集
1. 题目
给定两个数组,编写一个函数来计算它们的交集。
示例 1:
输入: nums1 = [1,2,2,1], nums2 = [2,2]
输出: [2]
示例 2:
输入: nums1 = [4,9,5], nums2 = [9,4,9,8,4]
输出: [9,4]
说明:
输出结果中的每个元素一定是唯一的。我们可以不考虑输出结果的顺序。
2. 答案
解题思路:
filter过滤Set去重
代码实现:
var intersection = function(nums1, nums2) {
return [...new Set(nums1.filter((item)=>nums2.includes(item)))]
};
3. 更多解答请看:leetcode349:给定两个数组,编写一个函数来计算它们的交集[17]
九、leetcode146:设计和实现一个LRU(最近最少使用)缓存机制
1. 题目
运用你所掌握的数据结构,设计和实现一个 LRU (最近最少使用) 缓存机制。它应该支持以下操作:获取数据 get 和写入数据 put 。
获取数据 get(key) - 如果密钥 ( key ) 存在于缓存中,则获取密钥的值(总是正数),否则返回 -1 。写入数据 put(key, value) - 如果密钥不存在,则写入数据。当缓存容量达到上限时,它应该在写入新数据之前删除最久未使用的数据,从而为新数据留出空间。
进阶:
你是否可以在 O(1) 时间复杂度内完成这两种操作?
示例:
LRUCache cache = new LRUCache( 2 /* 缓存容量 */ );
cache.put(1, 1);
cache.put(2, 2);
cache.get(1); // 返回 1
cache.put(3, 3); // 该操作会使得密钥 2 作废
cache.get(2); // 返回 -1 (未找到)
cache.put(4, 4); // 该操作会使得密钥 1 作废
cache.get(1); // 返回 -1 (未找到)
cache.get(3); // 返回 3
cache.get(4); // 返回 4
2. 答案
基础解法:数组+对象实现
类 vue keep-alive 实现
var LRUCache = function(capacity) {
this.keys = []
this.cache = Object.create(null)
this.capacity = capacity
};
LRUCache.prototype.get = function(key) {
if(this.cache[key]) {
// 调整位置
remove(this.keys, key)
this.keys.push(key)
return this.cache[key]
}
return -1
};
LRUCache.prototype.put = function(key, value) {
if(this.cache[key]) {
// 存在即更新
this.cache[key] = value
remove(this.keys, key)
this.keys.push(key)
} else {
// 不存在即加入
this.keys.push(key)
this.cache[key] = value
// 判断缓存是否已超过最大值
if(this.keys.length > this.capacity) {
removeCache(this.cache, this.keys, this.keys[0])
}
}
};
// 移除 key
function remove(arr, key) {
if (arr.length) {
const index = arr.indexOf(key)
if (index > -1) {
return arr.splice(index, 1)
}
}
}
// 移除缓存中 key
function removeCache(cache, keys, key) {
cache[key] = null
remove(keys, key)
}
进阶:Map
利用 Map 既能保存键值对,并且能够记住键的原始插入顺序
var LRUCache = function(capacity) {
this.cache = new Map()
this.capacity = capacity
}
LRUCache.prototype.get = function(key) {
if (this.cache.has(key)) {
// 存在即更新
let temp = this.cache.get(key)
this.cache.delete(key)
this.cache.set(key, temp)
return temp
}
return -1
}
LRUCache.prototype.put = function(key, value) {
if (this.cache.has(key)) {
// 存在即更新(删除后加入)
this.cache.delete(key)
} else if (this.cache.size >= this.capacity) {
// 不存在即加入
// 缓存超过最大值,则移除最近没有使用的
this.cache.delete(this.cache.keys().next().value)
}
this.cache.set(key, value)
}
3. 更多解答请看:leetcode146:设计和实现一个LRU(最近最少使用)缓存机制[18]
十、阿里算法题:编写一个函数计算多个数组的交集
1. 题目
要求:输出结果中的每个元素一定是唯一的
2. 答案
使用 reducer 函数
var intersection = function(...args) {
if (args.length === 0) {
return []
}
if (args.length === 1) {
return args[0]
}
return [...new Set(args.reduce((result, arg) => {
return result.filter(item => arg.includes(item))
}))]
};
3. 更多解答请看:阿里算法题:编写一个函数计算多个数组的交集[19]
十一、leetcode21:合并两个有序链表
1. 题目
将两个升序链表合并为一个新的升序链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
示例:
输入:1->2->4, 1->3->4
输出:1->1->2->3->4->4
2. 答案
解答:
确定解题的数据结构: 单链表
确定解题思路: 从链表头开始比较,l1 与 l2 是有序递增的,所以比较 l1.val 与 l2.val 的较小值就是合并后链表的最小值,次小值就是小节点的 next.val 与大节点的 val 比较的较小值,依次递归,直到递归到 l1 l2 均为 null
画图实现: 画图帮助理解一下
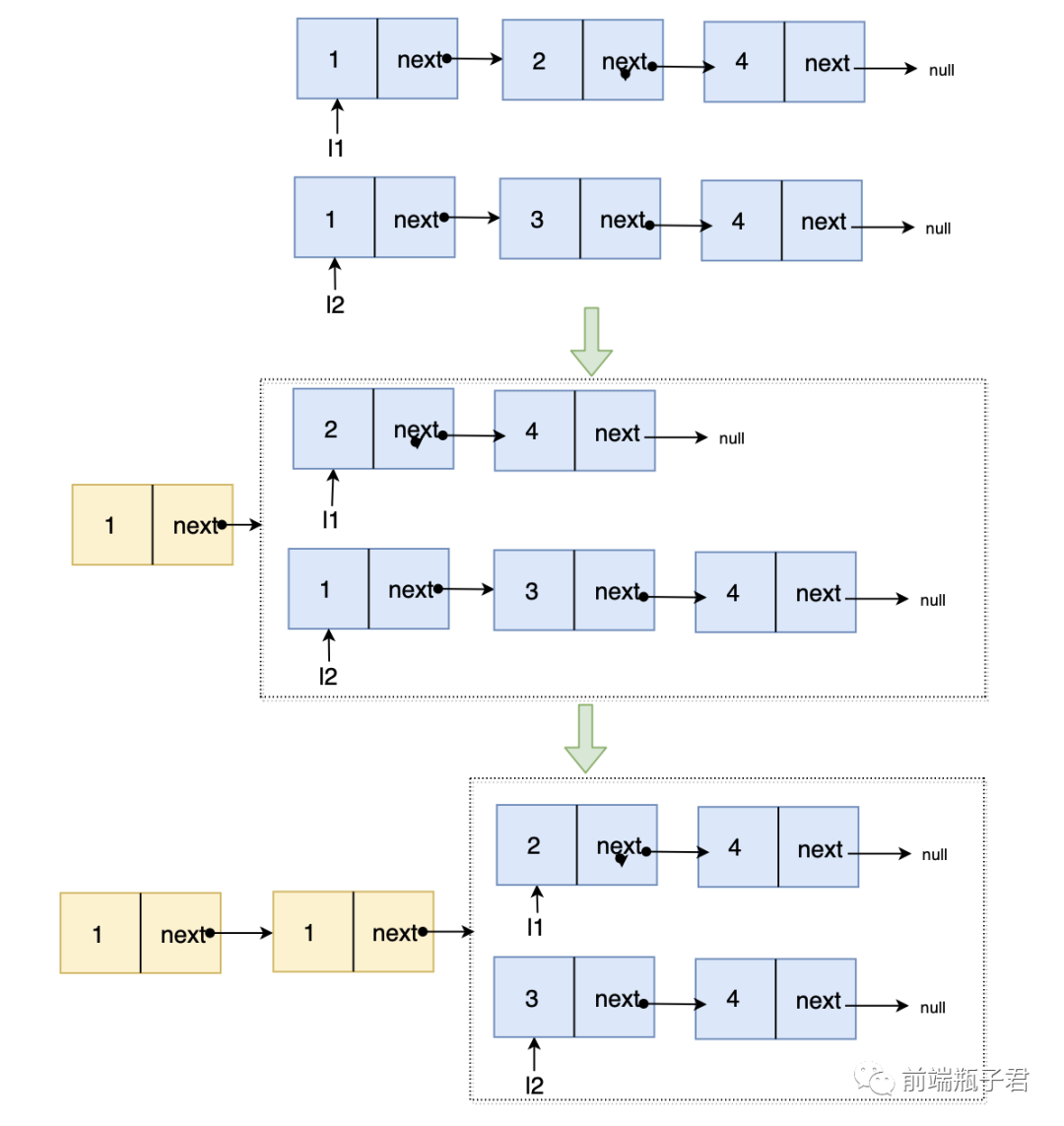
确定边界条件: 当递归到任意链表为 null ,直接将 next 指向另外的链表即可,不需要继续递归了
代码实现:
function mergeTwoLists(l1, l2) {
if(l1 === null) {
return l2
}
if(l2 === null) {
return l1
}
if(l1.val <= l2.val) {
l1.next = mergeTwoLists(l1.next, l2)
return l1
} else {
l2.next = mergeTwoLists(l2.next, l1)
return l2
}
}
3. 更多解答请看:leetcode21:合并两个有序链表[20]
十二、有赞&leetcode141:判断一个单链表是否有环
1. 题目
给定一个链表,判断链表中是否有环。
为了表示给定链表中的环,我们使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。如果 pos 是 -1,则在该链表中没有环。
示例 1:
输入:head = [3,2,0,-4], pos = 1
输出:true
解释:链表中有一个环,其尾部连接到第二个节点。

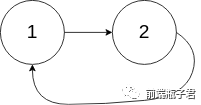
示例 2:
输入:head = [1,2], pos = 0
输出:true
解释:链表中有一个环,其尾部连接到第一个节点。
示例 3:
输入:head = [1], pos = -1
输出:false
解释:链表中没有环。

进阶:
你能用 O(1)(即,常量)内存解决此问题吗?
2. 答案
解法一:标志法
给每个已遍历过的节点加标志位,遍历链表,当出现下一个节点已被标志时,则证明单链表有环
var hasCycle = function(head) {
while(head) {
if(head.flag) return true
head.flag = true
head = head.next
}
return false
};
时间复杂度:O(n)
空间复杂度:O(n)
解法二:利用 JSON.stringify() 不能序列化含有循环引用的结构
var hasCycle = function(head) {
try{
JSON.stringify(head);
return false;
}
catch(err){
return true;
}
};
时间复杂度:O(n)
空间复杂度:O(n)
解法三:快慢指针(双指针法)
设置快慢两个指针,遍历单链表,快指针一次走两步,慢指针一次走一步,如果单链表中存在环,则快慢指针终会指向同一个节点,否则直到快指针指向 null 时,快慢指针都不可能相遇
var hasCycle = function(head) {
if(!head || !head.next) {
return false
}
let fast = head.next.next, slow = head
while(fast !== slow) {
if(!fast || !fast.next) return false
fast = fast.next.next
slow = slow.next
}
return true
};
时间复杂度:O(n)
空间复杂度:O(1)
3. 更多解答请看:有赞&leetcode141:判断一个单链表是否有环[21]
十三、图解leetcode206:反转链表
1. 题目
示例:
输入: 1->2->3->4->5->NULL
输出: 5->4->3->2->1->NULL
进阶:你可以迭代或递归地反转链表。你能否用两种方法解决这道题?
2. 解答
解法一:迭代法
解题思路: 将单链表中的每个节点的后继指针指向它的前驱节点即可
画图实现: 画图帮助理解一下
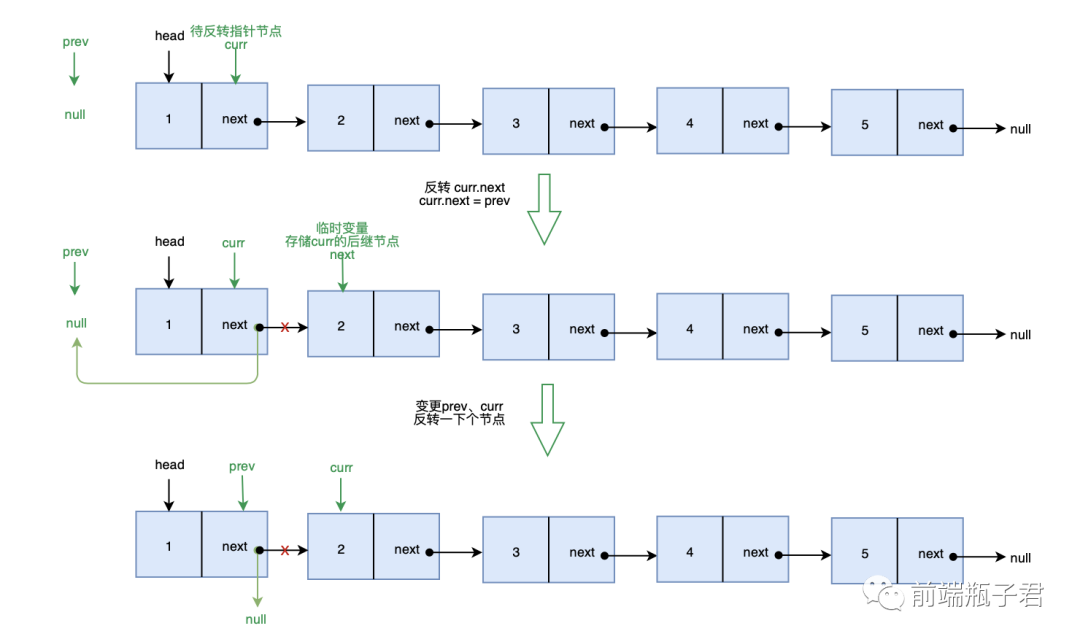
确定边界条件: 当链表为 null 或链表中仅有一个节点时,不需要反转
代码实现:
var reverseList = function(head) {
if(!head || !head.next) return head
var prev = null, curr = head
while(curr) {
// 用于临时存储 curr 后继节点
var next = curr.next
// 反转 curr 的后继指针
curr.next = prev
// 变更prev、curr
// 待反转节点指向下一个节点
prev = curr
curr = next
}
head = prev
return head
};
时间复杂度:O(n)
空间复杂度:O(1)
解法二:尾递归法
解题思路: 从头节点开始,递归反转它的每一个节点,直到 null ,思路和解法一类似
代码实现:
var reverseList = function(head) {
if(!head || !head.next) return head
head = reverse(null, head)
return head
};
var reverse = function(prev, curr) {
if(!curr) return prev
var next = curr.next
curr.next = prev
return reverse(curr, next)
};
时间复杂度:O(n)
空间复杂度:O(n)
解法三:递归法
解题思路: 不断递归反转当前节点 head 的后继节点 next
画图实现: 画图帮助理解一下
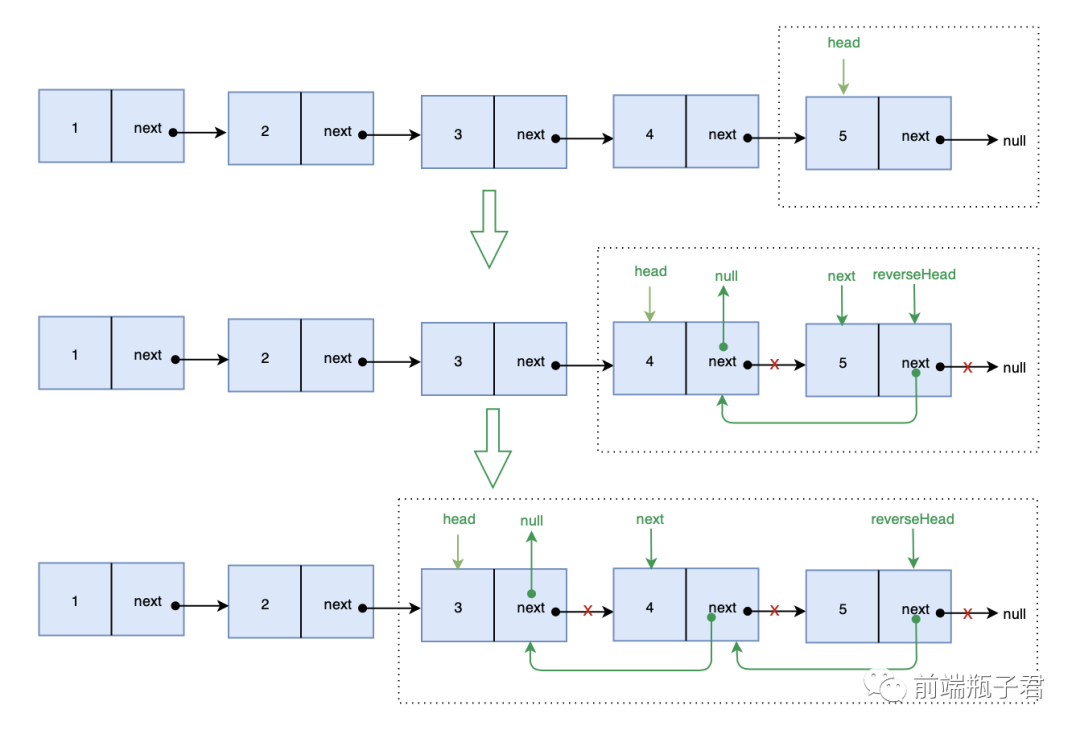
代码实现:
var reverseList = function(head) {
if(!head || !head.next) return head
var next = head.next
// 递归反转
var reverseHead = reverseList(next)
// 变更指针
next.next = head
head.next = null
return reverseHead
};
时间复杂度:O(n)
空间复杂度:O(n)
3. 更多解答请看:图解 leetcode206:反转链表[22]
github地址
图解leetcode88:合并两个有序数组: https://github.com/sisterAn/JavaScript-Algorithms/issues/3
[2]字节&leetcode1:两数之和: https://github.com/sisterAn/JavaScript-Algorithms/issues/4
[3]腾讯:数组扁平化、去重、排序: https://github.com/sisterAn/JavaScript-Algorithms/issues/5
[4]leetcode349:给定两个数组,编写一个函数来计算它们的交集: https://github.com/sisterAn/JavaScript-Algorithms/issues/6
[5]leetcode146:设计和实现一个LRU(最近最少使用)缓存机制: https://github.com/sisterAn/JavaScript-Algorithms/issues/7
[6]阿里算法题:编写一个函数计算多个数组的交集: https://github.com/sisterAn/JavaScript-Algorithms/issues/10
[7]leetcode21:合并两个有序链表: https://github.com/sisterAn/JavaScript-Algorithms/issues/11
[8]有赞&leetcode141:判断一个单链表是否有环: https://github.com/sisterAn/JavaScript-Algorithms/issues/13
[9]图解leetcode206:反转链表: https://github.com/sisterAn/JavaScript-Algorithms/issues/14
[10]前端进阶算法1:如何分析、统计算法的执行效率和资源消耗?: https://github.com/sisterAn/JavaScript-Algorithms/issues/1
[11]前端进阶算法2:从Chrome V8源码看JavaScript数组(附赠腾讯面试题): https://github.com/sisterAn/JavaScript-Algorithms/issues/2
[12]前端进阶算法3:从浏览器缓存淘汰策略和Vue的keep-alive学习LRU算法: https://github.com/sisterAn/JavaScript-Algorithms/issues/9
[13]前端进阶算法4:链表原来如此简单(+leetcode刷题): https://github.com/sisterAn/JavaScript-Algorithms/issues/12
[14]图解leetcode88:合并两个有序数组: https://github.com/sisterAn/JavaScript-Algorithms/issues/3
[15]字节&leetcode1:两数之和: https://github.com/sisterAn/JavaScript-Algorithms/issues/4
[16]腾讯:数组扁平化、去重、排序: https://github.com/sisterAn/JavaScript-Algorithms/issues/5
[17]leetcode349:给定两个数组,编写一个函数来计算它们的交集: https://github.com/sisterAn/JavaScript-Algorithms/issues/6
[18]leetcode146:设计和实现一个LRU(最近最少使用)缓存机制: https://github.com/sisterAn/JavaScript-Algorithms/issues/7
[19]阿里算法题:编写一个函数计算多个数组的交集: https://github.com/sisterAn/JavaScript-Algorithms/issues/10
[20]leetcode21:合并两个有序链表: https://github.com/sisterAn/JavaScript-Algorithms/issues/11
[21]有赞&leetcode141:判断一个单链表是否有环: https://github.com/sisterAn/JavaScript-Algorithms/issues/13
[22]图解 leetcode206:反转链表: https://github.com/sisterAn/JavaScript-Algorithms/issues/14