
【建议收藏】HBase配置检查清单
点击上方 "大数据肌肉猿"关注, 星标一起成长
后台回复【加群】,进入高质量学习交流群

来自:大数据研习社
1.集群巡检
HBase是使用HDFS作为底层存储的NoSQL数据库,提供了满足实时性和随即读写功能的数据库服务。
每日早晚巡检HBase服务,检查各集群的HMaster和RegionServer状态,是否事务积压等问题。
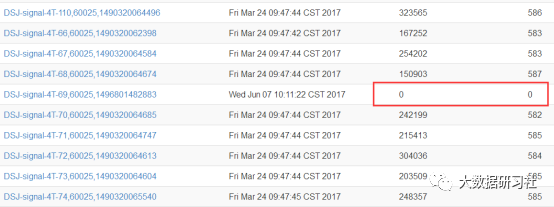
1.1 查看Requests Per Second和Num.Regions
若为图中所示为0,则需要登录主机查看,通常这种情况会发生在重启节点主机后发生。
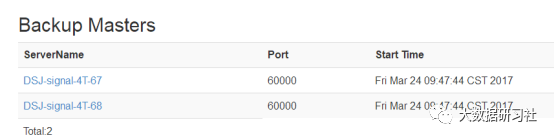
1.2 查看备用HMaster
每个库正常来说都有3个主节点,一个正在跑,两个备用,如图所示。
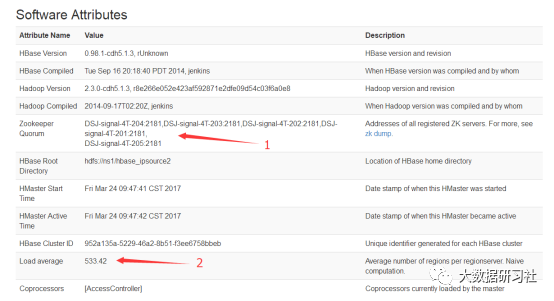
1.3 查看Software Attributes
图中所示,比较重要的是两个标出部分:
1:代表着本库的zookeeper节点,如果出现异常,总数会不正常的
2:代表着本库的平均region数,理论超过300就要进行合并操作的,但这个是根据业务的需求进行操作,业务侧提出数据库卡顿了,再进行合并操作即可。
1.4 查看Dead Region Servers
此项是以库为单位,登录每个库的HBase UI,若当前库内有HBaseregionserver宕掉的节点,则页面上会显示出如下情况:

出现这种情况,则说明当前库有非正常节点,可以尝试登陆该故障节点,查看故障原因(如HBase进程消失,主机意外重启,主机死机等)
2.参数调优
2.1 HBase HRegion 最大化压缩
hbase.hregion.majorcompaction:所有 HStore-
Files“最大化”压缩之间的时间,要禁用自动的最大化压缩,请将此值设置为 0。

2.2 RegionServer 小型压缩线程计数
hbase.regionserver.thread.compaction.small:
regionserver做Minor Compaction时线程池里线程数目,可以设置为5

2.3 HBase Region 分割限制
hbase.regionserver.regionSplitLimit:控制最大的region数量,超过则不可以进行split操作,默认是2147483647,设置1可以禁止自动的split,通过人工, 或者写脚本在集群空闲时执行。

2.4 HBase 文件最大大小
hbase.hregion.max.filesize:默认是10G, 如果任何一个column familiy里的StoreFile超过这个值, 那么这个Region会一分为二,因为region分 裂会有短暂的region下线时间(通常在5s以内),为减少对业务端的影响,建议手动定时分裂,可以设置大些。

2.5 HBase 客户端写入缓冲
hbase.client.write.buffer:客户端写buffer,设置autoFlush为false时,当客户端写满buffer才flush 默认为2M,写缓存大小,推荐设置为5M,单位是字节,当然越大占用的内存越多。

2.6 HBase Region Server 处理程序计数
hbase.regionserver.handler.count:该设置决定了处理RPC的线程数量,默认值是30,通常可以调大,但不是越大越好,设置过大会占用过多的内存, 导致频繁的gc,或者出现oom。

2.7 HFile 块缓存大小
hfile.block.cache.size:默认值0.25,regionser-
ver的block cache的内存大小限制,在偏向读的业务中,可以适当调大该值,需要注意的是 hbase.regionserver.global.memstore.upperLimit的值和hfile.block.cache.size的值之和必须小于0.8。

2.8 RegionServer 中所有 Memstore 的最大大小
hbase.regionserver.global.memstore.upperLimit,hbase.regionserver.global.memstore.size:默认值0.4 这个参数的作用是防止内存占用过大,当ReigonServer内所有region的memstores所占用内存总和达到heap的 40%时,HBase会强制block所有的更新并flush这些region以释放所有memstore占用的内存。
2.9 Memstore 刷新的低水位线
hbase.regionserver.global.memstore.lowerLimit,hbase.regionserver.global.memstore.size.lower.limit:默认值0.35 同upperLimit,只不过lowerLimit在所有region的memstores所占用内存达到Heap的35%时,不flush所有的 memstore。它会找一个memstore内存占用最大的region,做个别flush,此时写更新还是会被block。lowerLimit 算是一个在所有region强制flush导致性能降低前的补救措施。在日志中,表现为 “** Flush thread woke up with memory above low water
2.10 HBase Memstore 刷新大小
hbase.hregion.memstore.flush.size:如 memst-
ore 大小超过此值(字节数),Memstore 将刷新到磁盘。这个参数的作用是当单个Region内所有的 memstore大小总和超过指定值时,flush该region的所有memstore。RegionServer的flush是通过将请求添加一个 队列,模拟生产消费模式来异步处理的。那这里就有一个问题,当队列来不及消费,产生大量积压请求时,可能会导致内存陡增,最坏的情况是触发OOM。

--end--
扫描下方二维码 添加好友,备注【交流】 可私聊交流,也可进资源丰富学习群
更文不易,点个“在看”支持一下👇