
浅谈分库分表那些事儿
本文适合:需要从单库单表改造为多库多表的新手。
本文主要阐述在分库分表改造过程中需要考虑的因素以及对应的解法,还有踩过的那些坑。
一 前言
我们既然要做分库分表,那总要有个做事的动机。那么,在动手之前,首先就要弄明白下面两个问题。
1 什么是分库分表?
其实就是字面意思,很好理解:
分库:从单个数据库拆分成多个数据库的过程,将数据散落在多个数据库中。
分表:从单张表拆分成多张表的过程,将数据散落在多张表内。
2 为什么要分库分表?
关键字:提升性能、增加可用性。
从性能上看
随着单库中的数据量越来越大、数据库的查询QPS越来越高,相应的,对数据库的读写所需要的时间也越来越多。数据库的读写性能可能会成为业务发展的瓶颈。对应的,就需要做数据库性能方面的优化。本文中我们只讨论数据库层面的优化,不讨论缓存等应用层优化的手段。
如果数据库的查询QPS过高,就需要考虑拆库,通过分库来分担单个数据库的连接压力。比如,如果查询QPS为3500,假设单库可以支撑1000个连接数的话,那么就可以考虑拆分成4个库,来分散查询连接压力。
如果单表数据量过大,当数据量超过一定量级后,无论是对于数据查询还是数据更新,在经过索引优化等纯数据库层面的传统优化手段之后,还是可能存在性能问题。这是量变产生了质变,这时候就需要去换个思路来解决问题,比如:从数据生产源头、数据处理源头来解决问题,既然数据量很大,那我们就来个分而治之,化整为零。这就产生了分表,把数据按照一定的规则拆分成多张表,来解决单表环境下无法解决的存取性能问题。
从可用性上看
单个数据库如果发生意外,很可能会丢失所有数据。尤其是云时代,很多数据库都跑在虚拟机上,如果虚拟机/宿主机发生意外,则可能造成无法挽回的损失。因此,除了传统的Master-Slave、Master-Master等部署层面解决可靠性问题外,我们也可以考虑从数据拆分层面解决此问题。
此处我们以数据库宕机为例:
单库部署情况下,如果数据库宕机,那么故障影响就是100%,而且恢复可能耗时很长。
如果我们拆分成2个库,分别部署在不同的机器上,此时其中1个库宕机,那么故障影响就是50%,还有50%的数据可以继续服务。
如果我们拆分成4个库,分别部署在不同的机器上,此时其中1个库宕机,那么故障影响就是25%,还有75%的数据可以继续服务,恢复耗时也会很短。
当然,我们也不能无限制的拆库,这也是牺牲存储资源来提升性能、可用性的方式,毕竟资源总是有限的。
二 如何分库分表
1 分库?分表?还是既分库又分表?
从第一部分了解到的信息来看,分库分表方案可以分为下面3种:

2 如何选择我们自己的切分方案?
如果需要分表,那么分多少张表合适?
由于所有的技术都是为业务服务的,那么,我们就先从数据方面回顾下业务背景。
比如,我们这个业务系统是为了解决会员的咨询诉求,通过我们的XSpace客服平台系统来服务会员,目前主要以同步的离线工单数据作为我们的数据源来构建自己的数据。
假设,每一笔离线工单都会产生对应一笔会员的咨询问题(我们简称:问题单),如果:
在线渠道:每天产生3w笔聊天会话,假设,其中50%的会话会生成一笔离线工单,那么每天可生成 3w * 50% = 1.5w 笔工单;
热线渠道:每天产生2.5w通电话,假设,其中80%的电话都会产生一笔工单,那么每天可生成 2.5w * 80% = 2w 笔/天;
离线渠道:假设离线渠道每天直接生成3w笔。
合计共 1.5w + 2w + 3w = 6.5w 笔/天
考虑到以后可能要继续覆盖的新的业务场景,需要提前预留部分扩展空间,这里我们假设为每天产生8w笔问题单。
除问题单外,还有另外2张常用的业务表:用户操作日志表、用户提交的表单数据表。
其中,每笔问题单都会产生多条用户操作日志,根据历史统计数据来可以看到,平均每个问题单大约会产生8条操作日志,我们预留一部分空间,假设每个问题单平均产生约10条用户操作日志。
如果系统设计使用年限5年,那么问题单数据量大约为 5年 * 365天/年 * 8w/天 = 1.46亿,那么估算出的表数量如下:
问题单需要:1.46亿/500w = 29.2 张表,我们就按32张表来切分;
操作日志需要 :32 * 10 = 320 张表,我们就按 32 * 16 = 512 张表来切分。
如果需要分库,那么分多少库合适?
分库的时候除了要考虑平时的业务峰值读写QPS外,还要考虑到诸如双11大促期间可能达到的峰值,需要提前做好预估。
根据我们的实际业务场景,问题单的数据查询来源主要来自于阿里客服小蜜首页。因此,可以根据历史QPS、RT等数据评估,假设我们只需要3500数据库连接数,如果单库可以承担最高1000个数据库连接,那么我们就可以拆分成4个库。
3 如何对数据进行切分?
根据行业惯例,通常按照 水平切分、垂直切分 两种方式进行切分,当然,有些复杂业务场景也可能选择两者结合的方式。
(1)水平切分
这是一种横向按业务维度切分的方式,比如常见的按会员维度切分,根据一定的规则把不同的会员相关的数据散落在不同的库表中。由于我们的业务场景决定都是从会员视角进行数据读写,所以,我们就选择按照水平方式进行数据库切分。
(2)垂直切分
垂直切分可以简单理解为,把一张表的不同字段拆分到不同的表中。
比如:假设有个小型电商业务,把一个订单相关的商品信息、买卖家信息、支付信息都放在一张大表里。可以考虑通过垂直切分的方式,把商品信息、买家信息、卖家信息、支付信息都单独拆分成独立的表,并通过订单号跟订单基本信息关联起来。
也有一种情况,如果一张表有10个字段,其中只有3个字段需要频繁修改,那么就可以考虑把这3个字段拆分到子表。避免在修改这3个数据时,影响到其余7个字段的查询行锁定。
三 分库分表之后带来的新问题
1 分库分表后,如何让数据均匀散落在各个分库分表内?
比如,当热点事件出现后,怎么避免热点数据集中存取到某个特定库/表,造成各分库分表读写压力不均的问题。
其实,细思之下可以发现这个问题其实跟负载均衡的问题很相似,所以,我们可以去借鉴下负载均衡的解法来解决。我们常见的负责均衡算法如下:
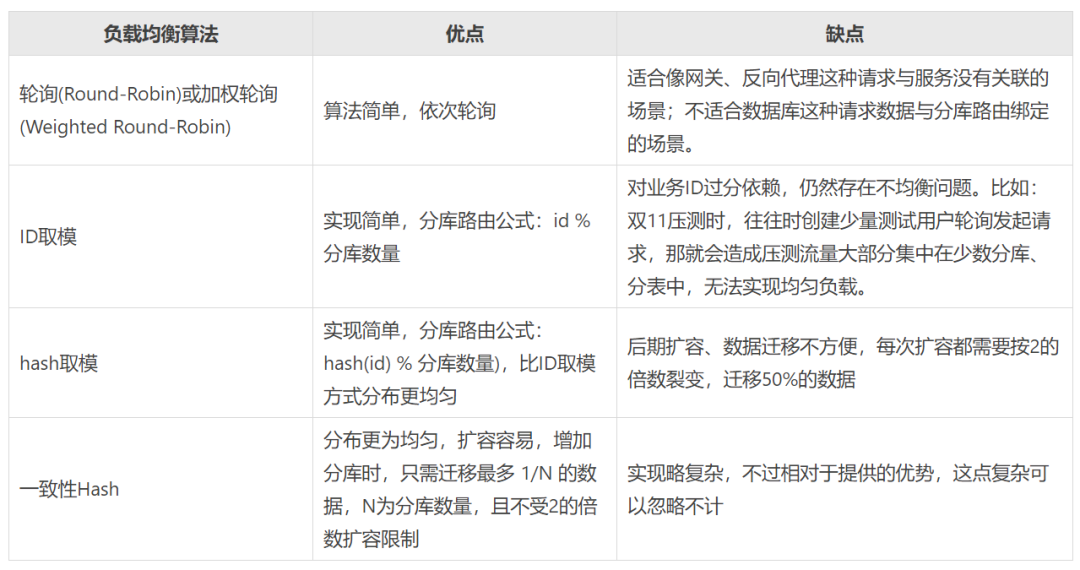
我们的选择:基于 一致性Hash算法 裁剪,相较于一致性Hash算法,我们裁剪后的算法主要区别在以下几点:
(1)Hash环节点数量的不同
一致性Hash有 2^32-1 个节点,考虑到我们按照buyerId切分,而且buyerId基数本就很庞大,整体已经具备一定的均匀度,所以,我们把Hash环的数量降低到4096个;
(2)DB索引算法的不同
一致性Hash通过类似 hash(DB的IP) % 2^32 公式计算DB在Hash环的位置。如果DB数量较少,需要通过增加虚拟节点来解决Hash环偏斜问题,而且DB的位置可能会随着IP的变动而变化,尤其是在云环境下。
数据均匀分布到Hash环的问题,经过之前的判断,我们可以通过 Math.abs(buyerId.hashCode()) % 4096 计算定位到Hash环位置,那么剩下的问题就是让DB也均匀分布到这个Hash环上即可。由于我们都是使用阿里的TDDL中间件,只需要通过逻辑上的分库索引号定位DB,因此,我们把分库DB均分到这个Hash环上即可,如果是hash环有4096个环节,拆分4库的话,那么4个库分别位于第1、1025、2049、3073个节点上。分库的索引定位可通过 (Math.abs(buyerId.hashCode()) % 4096) / (4096 / DB_COUNT) 这个公式计算得出。
分库索引的Java伪代码实现如下:
/*** 分库数量*/public static final int DB_COUNT = 4;/*** 获取数据库分库索引号** @param buyerId 会员ID* @return*/public static int indexDbByBuyerId(Long buyerId) {return (Math.abs(buyerId.hashCode()) % 4096) / (4096 / DB_COUNT);}
2 分库分表环境下,如何解决分库后主键ID的唯一性问题?
在单库环境下,我们的问题单主表的ID采用的MySQL自增的方式。但是,分库之后如果还继续使用数据库自增的方式,就很容易出现各门口的主键ID重复问题。
对于这种情况,有很多种解决方案,比如采用UUID的方式,不过UUID太长,查询性能太差,占用空间也大,而且主键的类型也变了,也不利于应用平滑迁移。
其实,我们也可以对ID继续拆分,比如对ID进行分段,不同的库表使用不同的ID段,但也会产生新的问题,这个ID段要多长才合适?如果ID段分配完了,那可能会占用第二个库的ID段,产生ID不唯一问题。
但是,如果我们让所有的分库使用的ID段按照等差数列进行分隔,每次ID段用完之后,再按照固定的步长比递增的话,那是不是就可以解决这个问题了。
比如,像下面这样,假设每次分配的ID间隔为1000,也就是步长1000,那么每次分配的ID段起止索引则可以按照下面的公式计算得出:
第X库、第Y次分配的ID段起始索引就是:
X * 步长 + (Y-1) * (库数量 * 步长)
第X库、第Y次分配的ID段结束索引就是:
X * 步长 + (Y-1) * (库数量 * 步长) + (1000 -1)
如果是分4库,那么最终分配的ID段就会是下面这个样子:
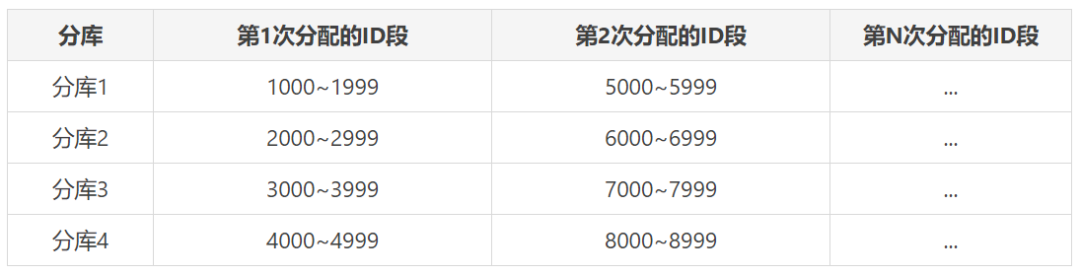
我们的问题单库采用的就是这种先对ID分段,再按固定步长递增的方式。这也是TDDL官方提供的解决方案。
除此之外,实际场景下,通常为了分析排查问题方便,往往会在ID中增加一些额外信息,比如我们自己的问题单ID就包含了日期、版本、分库索引等信息。
问题单ID生成Java伪代码参考:
import lombok.Setter;import org.apache.commons.lang3.time.DateFormatUtils;/*** 问题单ID构建器* <p>* ID格式(18位):6位日期 + 2位版本号 + 2位库索引号 + 8位序列号* 示例:180903010300001111* 说明这个问题单是2018年9月3号生成的,采用的01版本的ID生成规则,数据存放在03库,最后8位00001111是生成的序列号ID。* 采用这种ID格式还有个好处就是每天都有1亿(8位)的序列号可用。* </p>*/public class ProblemOrdIdBuilder {public static final int DB_COUNT = 4;private static final String DATE_FORMATTER = "yyMMdd";private String version = "01";private long buyerId;private long timeInMills;private long seqNum;public Long build() {int dbIndex = indexDbByBuyerId(buyerId);StringBuilder pid = new StringBuilder(18).append(DateFormatUtils.format(timeInMills, DATE_FORMATTER)).append(version).append(String.format("%02d", dbIndex)).append(String.format("%08d", seqNum % 10000000));return Long.valueOf(pid.toString());}/*** 获取数据库分库索引号** @param buyerId 会员ID* @return*/public int indexDbByBuyerId(Long buyerId) {return (Math.abs(buyerId.hashCode()) % 4096) / (4096 / DB_COUNT);}}
3 分库分表环境下,事务问题怎么解决?
由于分布式环境下,一个事务可能跨多个分库,所以,处理起来相对复杂。目前常见的有2种解决方案:
(1)使用分布式事务
优点:由应用服务器/数据库去管理事务,实现简单。
缺点:性能代价较高,尤其是涉及到分库数量较多时尤为明显。而且,还依赖于一些特定的应用服务器/数据库提供的分布式事务实现方案。
(2)由应用程序+数据库共同控制
原理:大事化小,将多个大事务拆分成可由单个分库处理的小事务,由应用程序去控制这些小事务。
优点:性能良好,少了一个分布式事务协调处理层。
缺点:需要从应用程序自身上做事务控制的灵活设计。从业务应用上做处理,应该改造成本高。
针对上面2种分布式事务解决方案,我们该如何选择?
首先,没有万能的解决方案,只有适合自己的方案。那就先看看我们的业务中,事务的使用场景有哪些吧。
无论是来咨询问题的会员,还是为会员解决问题的客服小二,亦或者从第三方系统同步相关数据,主要有2个核心动作:
以会员维度查询相关进度数据,包含会员问题数据,以及对应的问题处理操作日志/进度数据;
以会员视角提交相关凭证/反馈新情况等数据,或者是客服小二代会员提交这些数据。提交的数据也可能会决定问题是否解决(被完结)。
由于问题单数据、操作日志都是分开查询,所以,不涉及分布式关联查询场景,这个可以忽略不考虑。
那么就剩下用户提交数据场景了,可能会同时写入问题单以及操作日志数据。
既然使用场景确定了,那么可以选择事务解决方案了。虽然分布式事务实现简单,但这个简单是因为中间件帮我们解决了它本身的复杂性。复杂性越高,必然会带来一定的性能损耗。而且,目前大部分应用都是基于SpringBoot开发,默认使用的都是内嵌tomcat容器,不像IBM提供的WebSphere Application Server、Oracle的WebLogic这些重量级应用服务器,都提供了内置的分布式事务管理器。因此,如果我们要接入,必然要自己引入额外的分布式事务管理器,这个接入成本就更高了。所以,这种方案就暂不考虑了。那么,就只能自己想办法把大事务切分成单库可以解决的小事务了。
所以,现在问题就成了,如何让同一个会员的问题单数据和这个问题单相关的操作日志数据写入到同一个分库中。其实,解决方案也比较简单,由于都是使用会员ID做切分,那么使用相同的分库路由规则即可。
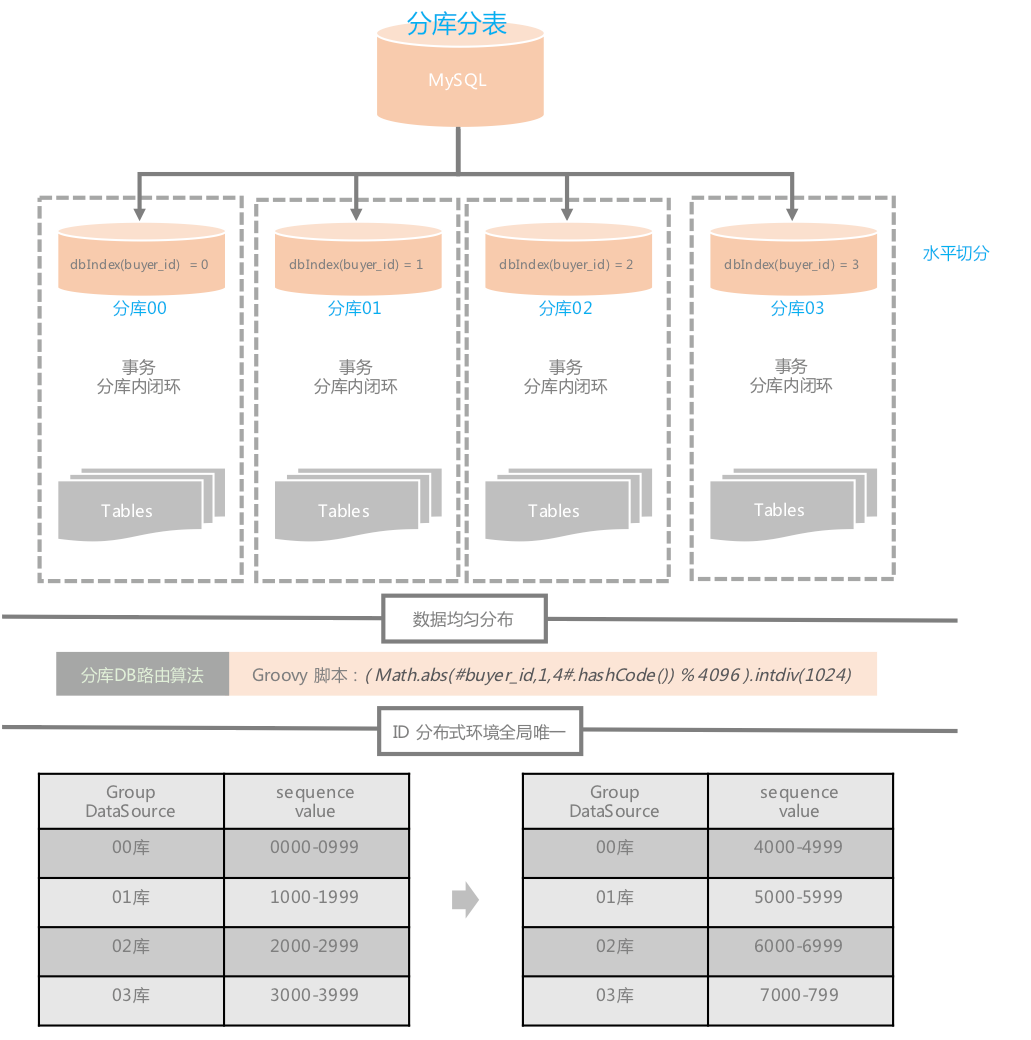
最后,我来看下最终的TDDL分库分表规则配置:
<beans><bean id="vtabroot" class="com.taobao.tddl.interact.rule.VirtualTableRoot" init-method="init"><property name="dbType" value="MYSQL" /><property name="defaultDbIndex" value="PROBLEM_0000_GROUP" /><property name="tableRules"><map><entry key="problem_ord" value-ref="problem_ord" /><entry key="problem_operate_log" value-ref="problem_operate_log" /></map></property></bean><!-- 问题(诉求)单表 --><bean id="problem_ord" class="com.taobao.tddl.interact.rule.TableRule"><property name="dbNamePattern" value="PROBLEM_{0000}_GROUP" /><property name="tbNamePattern" value="problem_ord_{0000}" /><property name="dbRuleArray" value="((Math.abs(#buyer_id,1,4#.hashCode()) % 4096).intdiv(1024))" /><property name="tbRuleArray"><list><value><![CDATA[def hashCode = Math.abs(#buyer_id,1,32#.hashCode());int dbIndex = ((hashCode % 4096).intdiv(1024)) as int;int tableCountPerDb = 32 / 4;int tableIndexStart = dbIndex * tableCountPerDb;int tableIndexOffset = (hashCode % tableCountPerDb) as int;int tableIndex = tableIndexStart + tableIndexOffset;return tableIndex;]]></value></list></property><property name="allowFullTableScan" value="false" /></bean><!-- 问题操作日志表 --><bean id="problem_operate_log" class="com.taobao.tddl.interact.rule.TableRule"><property name="dbNamePattern" value="PROBLEM_{0000}_GROUP" /><property name="tbNamePattern" value="problem_operate_log_{0000}" /><!-- 【#buyer_id,1,4#.hashCode()】 --><!-- buyer_id 代表分片字段;1代表分库步长;4代表一共4个分库,当执行全表扫描时会用到 --><property name="dbRuleArray" value="((Math.abs(#buyer_id,1,4#.hashCode()) % 4096).intdiv(1024))" /><property name="tbRuleArray"><list><value><![CDATA[def hashCode = Math.abs(#buyer_id,1,512#.hashCode());int dbIndex = ((hashCode % 4096).intdiv(1024)) as int;int tableCountPerDb = 512 / 4;int tableIndexStart = dbIndex * tableCountPerDb;int tableIndexOffset = (hashCode % tableCountPerDb) as int;int tableIndex = tableIndexStart + tableIndexOffset;return tableIndex;]]></value></list></property><property name="allowFullTableScan" value="false" /></bean></beans>
4 分库分表后,历史数据如何平滑迁移?
数据库复制方案,阿里云上面也开放了以前阿里内部使用的数据库复制、迁移方案《数据传输服务(Data Transmission Service)》[1],详情可咨询阿里云客服或者阿里云数据库专家。
分库切换发布流程可选择停机、不停机发布两种:
(1)如果选择停机发布
首先,要选择一个夜黑风高、四处无人的夜晚。寒风刺骨能让你清醒,四处无人,你好办事打劫偷数据,我们就挑了个凌晨4点寂静无人的时候做切换;如果可以,能临时关闭业务访问入口最好。
然后,在DTS上面新增一个全量的数据复制任务,把单库的数据复制到新的分库中(这个过程很快,千万级数据应该10分左右就能搞定)。
之后,切换TDDL配置(单库->分库),并重启应用,检查是否生效。
最后,开放业务访问入口,提供服务。
(2)如果选择不停机发布话,流程会略微复杂点
首先,同样需要选择一个夜黑风高的夜晚,来衬托你的帅气。
然后,通过DTS复制某个时间点前的数据,比如:今天前的历史数据。
之后,从单库切换到分库(最好是提前发布好应用、准备好配置),这样切换时只需要几分钟重启生效即可。在切换到分库前,联系DBA在切换期间停止老的单库读写。
最后,分库切换完成后,再通过DTS增量复制老的单库中今天凌晨之后产生的数据。
最后的最后,持续观察一段时间,如果没问题,老的单库就可以下线了。
5 TDDL配置分库分表路由时的注意事项
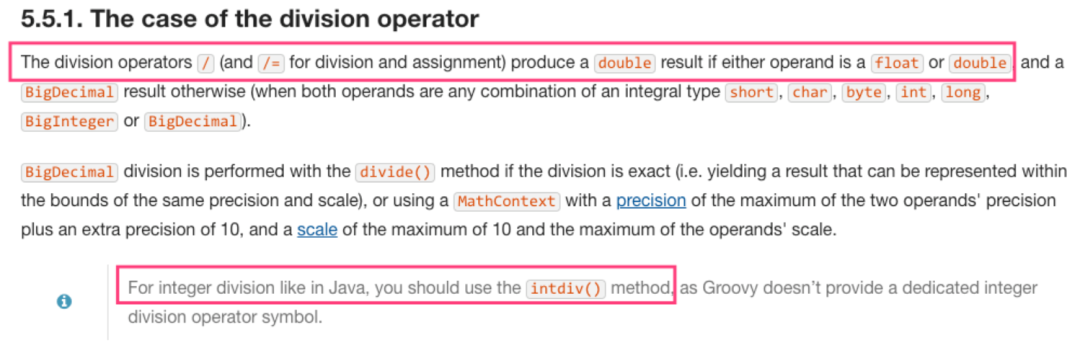
由于阿里的TDDL中间件使用Groovy脚本计算分库分表路由,而Groovy的 / 运算符或者 /= 运算符可能会产生一个double类型的结果,并非像Java那样得出一个整数,因此需要使用 x.intdiv(y) 函数做整除运算。
// 在 Java 中System.out.println(5 / 3); // 结果 = 1// 在 Groovy 中println (5 / 3); // 结果 = 1.6666666667println (5.intdiv(3)); // 结果 = 1(Groovy整除正确用法)
详情可查看Groovy官方说明《The case of the division operator》:
四 分库分表文中案例图示
参考资料 [1]https://baijiahao.baidu.com/s?id=1622441635115622194&wfr=spider&for=pc [2]http://www.zsythink.net/archives/1182 [3]https://www.aliyun.com/product/dts [4]https://docs.groovy-lang.org/latest/html/documentation/core-syntax.html#integer_division [5]https://github.com/alibaba/tb_tddl
有道无术,术可成;有术无道,止于术
欢迎大家关注Java之道公众号
好文章,我在看❤️