
Hive查询的18种方式
前言
相信大家一定对 Hive 不陌生!Hive 是基于Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能(HQL)。Hive的优点是学习成本低,可以通过类似SQL语句实现快速MapReduce统计,使MapReduce变得更加简单,而不必开发专门的MapReduce应用程序。因此,hive十分适合对数据仓库进行统计分析。
今天呢,我们就来探讨一下,关于Hive数据查询的18种方式!
准备
我们本期内容大部分HQL操作都需要依赖如下两张表,具体的数据内容如下:
course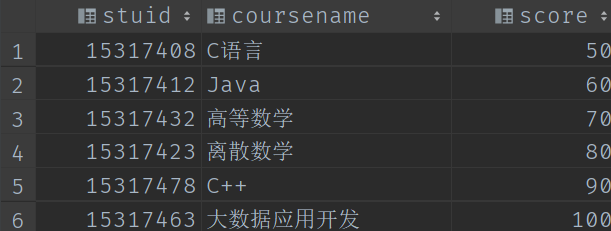
student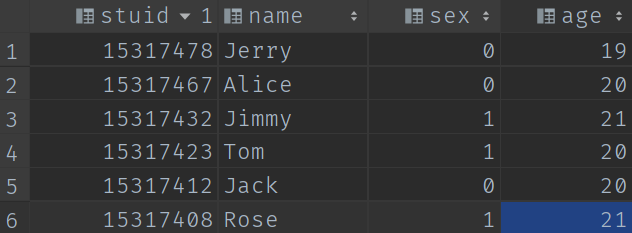
1、SELECT查询语句
SELECT 查询语句比较简单,后面跟要查询的字段,如下所示:
hive (hypers)> select name from student;
OK
name
Rose
Jack
Jimmy
Tom
Jerry
可以为查询语句中的列和表加上别名,如下所示:
hive (hypers)> select t.name from student t;
OK
t.name
Rose
Jack
Jimmy
Tom
Jerry
可以使用如下语句进行嵌套查询:
hive (hypers)> select a.name, b.coursename
> from (select stuid, name from student) a
> join (select stuid, coursename from course) b on a.stuid = b.stuid;
OK
a.name b.coursename
Rose C语言
Jack Java
Jimmy 高等数学
Tom 离散数学
Jerry C++
可以使用正则表达式指定查询的列,如下所示:
hive (hypers)> select t.* from student t;
OK
t.stuid t.name t.sex t.age
15317408 Rose 1 21
15317412 Jack 0 20
15317432 Jimmy 1 21
15317423 Tom 1 20
15317478 Jerry 0 19
15317467 Alice 0 20
可以使用 LIMIT 限制查询的结果条数,如下所示:
hive (hypers)> select * from student limit 1;
OK
student.stuid student.name student.sex student.age
15317408 Rose 1 21
可以使用ORDER BY语句对结果进行排序,升序我们可以不在排序的字段后加上ASC(默认),但是倒序需要指定DESC,如下所示:
hive (hypers)> select * from student order by age desc;
OK
student.stuid student.name student.sex student.age
15317432 Jimmy 1 21
15317408 Rose 1 21
15317467 Alice 0 20
15317423 Tom 1 20
15317412 Jack 0 20
15317478 Jerry 0 19
Time taken: 10.631 seconds, Fetched: 5 row(s)
hive (hypers)> select * from student order by age;
OK
student.stuid student.name student.sex student.age
15317478 Jerry 0 19
15317467 Alice 0 20
15317423 Tom 1 20
15317412 Jack 0 20
15317432 Jimmy 1 21
15317408 Rose 1 21
我们还可以使用CASE...WHEN...THEN语句对某一列的值进行处理,如下所示:
hive (hypers)> SELECT stuid,
> name,
> age,
> sex,
> CASE
> WHEN sex = '1' THEN '男'
> WHEN sex = '0' THEN '女'
> ELSE '未知'
> END
> FROM student;
OK
stuid name age sex _c4
15317408 Rose 21 1 男
15317412 Jack 20 0 女
15317432 Jimmy 21 1 男
15317423 Tom 20 1 男
15317478 Jerry 19 0 女
15317478 Alice 20 0 女
2、WHERE 条件语句
WHERE 条件语句主要是对查询进行条件限制,如下所示:
hive (hypers)> select * from student where age = 21;
OK
student.stuid student.name student.sex student.age
15317408 Rose 1 21
15317432 Jimmy 1 21
WHERE 条件语句常用的操作符如该表所示
| 操作符 | 支持的数据类型 | 说明 |
|---|---|---|
| A=B | 基本数据类型 | 如果A等于B,则返回true,否则返回false |
| A<=>B | 基本数据类型 | 如果A和B都为NULL,则返回true,其他情况和 A=B 相同 |
| A<>B,A != B | 基本数据类型 | 如果A或者B为NULL,则返回NULL;如果A不等于B返回 true,否则返回 false |
A| 基本数据类型 | 如果A或者B为NULL,则返回NULL;如果A小于B返回 true,否则返回 false | |
| A<=B | 基本数据类型 | 如果A或者B为NULL,则返回NULL;如果A小于或等于B返回 true,否则返回 false |
| A>B | 基本数据类型 | 如果A 或者B为NULL,则返回NULL;如果A大于B返回true,否则返回 false |
| A>=B | 基本数据类型 | 如果A 或者B为NULL,则返回NULL;如果A大于或者等于B返回true,否则返回 false |
| A IS NULL | 所有数据类型 | 如果A为NULL返回true,否则返回 false |
| A IS NOT NULL | 所有数据类型 | 如果A不为NULL返回true,否则返回 false |
| A BETWEEN B AND C | 基本数据类型 | 如果A、B、C任一为NULL,则返回NULL;如果A大于或者等于B并且A小于或等于C,则返回true,否则返回false |
| A NOT BETWEEN B AND C | 基本数据类型 | 如果A、B、C任一为NULL,则返回NULL;如果A小于B或者A大于C,则返回true,否则返回false |
| A LIKE B | STRING类型 | 如果A模糊匹配B,则返回true,否则返回false |
| A NOT LIKE B | STRING类型 | 如果A不模糊匹配B,则返回true,否则返回false |
| A RLIKE B,A REGEXP B | STRING类型 | B是一个正则表达式,如果A匹配正则表达式,则返回true,否则返回false |
3、GROUP BY 语句
GROUP BY语句主要是对查询的数据进行分组,通常会和聚合函数一起使用,如下所示:
hive (hypers)> select sex,avg(age) from student group by sex;
OK
sex _c1
0 19.666666666666668
1 20.666666666666668
4、HAVING语句
HAVING语句主要用来对GROUP BY语句的结果进行条件限制,如下所示:
hive (hypers)> select sex,avg(age) from student group by sex having avg(age) > 20;
OK
sex _c1
1 20.666666666666668
5、INNER JOIN语句
在 INNER JOIN 语句中,只有进行连接的两个表中都存在与连接条件相匹配的数据时才会被显示在结果数据中,如下所示:
hive (hypers)> select t1.name,t2.coursename from student t1 join course t2 on t1.stuid = t2.stuid;
OK
t1.name t2.coursename
Rose C语言
Jack Java
Jimmy 高等数学
Tom 离散数学
Jerry C++
6、 LEFT OUTER JOIN语句
LEFT OUTER JOIN语句表示左外连接,左外连接查询数据会包含左表中的全部记录,而右表中不符合条件的结果将以NULL的形式出现,如下所示:
hive (hypers)> select t1.name,t2.coursename from student t1 left outer join course t2 on t1.stuid = t2.stuid;
OK
t1.name t2.coursename
Rose C语言
Jack Java
Jimmy 高等数学
Tom 离散数学
Jerry C++
Alice NULL
7、RIGHT OUTER JOIN语句
RIGHT OUTER JOIN表示右外连接,右外连接查询数据会包含右表中的全部记录,而左表中不符合条件的结果将以 NULL 的形式出现,如下所示:
hive (hypers)> select t1.name,t2.coursename from student t1 right outer join course t2 on t1.stuid = t2.stuid;
OK
t1.name t2.coursename
Rose C语言
Jack Java
Jimmy 高等数学
Tom 离散数学
Jerry C++
NULL 大数据应用开发
8、FULL OUTER JOIN语句
FULL OUTER JOIN语句表示全外连接,结果数据会包含左表和右表的全部数据,不符合条件的用NULL表示,如下所示:
hive (hypers)> select t1.name,t2.coursename from student t1 FULL outer join course t2 on t1.stuid = t2.stuid;
OK
t1.name t2.coursename
Rose C语言
Jack Java
Tom 离散数学
Jimmy 高等数学
NULL 大数据应用开发
Alice NULL
Jerry C++
9、 LEFT SEMI JOIN语句
LEFT SEMI JOIN语句表示左半连接,其结果数据对应右表满足 ON 语句中的条件,如下所示:
hive (hypers)> select t1.name from student t1 LEFT SEMI JOIN course t2 on t1.stuid = t2.stuid;
OK
t1.name
Rose
Jack
Jimmy
Tom
Jerry
注意:| 在 LEFT SEMI JOIN 语句中,SELECT 和 WHERE 子句中不能引用右表中的字段。|
10、笛卡尔积 JOIN 语句
笛卡尔积 JOIN 语句 表示左表的行数乘以右表的行数等于结果集的大小,如下所示:
hive (hypers)> select * from student join course;
OK
student.stuid student.name student.sex student.age course.stuid course.coursename course.score
15317408 Rose 1 21 15317408 C语言 50
15317412 Jack 0 20 15317408 C语言 50
15317432 Jimmy 1 21 15317408 C语言 50
15317423 Tom 1 20 15317408 C语言 50
15317478 Jerry 0 19 15317408 C语言 50
15317467 Alice 0 20 15317408 C语言 50
15317408 Rose 1 21 15317412 Java 60
15317412 Jack 0 20 15317412 Java 60
15317432 Jimmy 1 21 15317412 Java 60
15317423 Tom 1 20 15317412 Java 60
15317478 Jerry 0 19 15317412 Java 60
15317467 Alice 0 20 15317412 Java 60
15317408 Rose 1 21 15317432 高等数学 70
15317412 Jack 0 20 15317432 高等数学 70
15317432 Jimmy 1 21 15317432 高等数学 70
15317423 Tom 1 20 15317432 高等数学 70
15317478 Jerry 0 19 15317432 高等数学 70
15317467 Alice 0 20 15317432 高等数学 70
15317408 Rose 1 21 15317423 离散数学 80
15317412 Jack 0 20 15317423 离散数学 80
15317432 Jimmy 1 21 15317423 离散数学 80
15317423 Tom 1 20 15317423 离散数学 80
15317478 Jerry 0 19 15317423 离散数学 80
15317467 Alice 0 20 15317423 离散数学 80
15317408 Rose 1 21 15317478 C++ 90
15317412 Jack 0 20 15317478 C++ 90
15317432 Jimmy 1 21 15317478 C++ 90
15317423 Tom 1 20 15317478 C++ 90
15317478 Jerry 0 19 15317478 C++ 90
15317467 Alice 0 20 15317478 C++ 90
15317408 Rose 1 21 15317463 大数据应用开发 100
15317412 Jack 0 20 15317463 大数据应用开发 100
15317432 Jimmy 1 21 15317463 大数据应用开发 100
15317423 Tom 1 20 15317463 大数据应用开发 100
15317478 Jerry 0 19 15317463 大数据应用开发 100
15317467 Alice 0 20 15317463 大数据应用开发 100
注意:| 如果将 Hive 的属性hive.mapred.mode 设置为 strict,则会阻止执行笛卡尔积查询。|
11、map-side JOIN语句
map-site JOIN语句会在Map阶段将小表读到内存,直接在 Map 端 进行JOIN,这种连接需要在查询语句中显式申明,如下所示:
SELECT /* + MapJOIN(t1) */ s1.stuid,s2.stuid from student s1 JOIN student s2 ON s1.stuid = s2.stuid;
可以通过设置Hive的属性 hive.auto.convert.join=true自动开启 map-side JOIN;也可以设置 Hive 的属性 hive.mapjoin.smalltable.filesize定义表的大小,默认为 25 000 000 B。
12、多表JOIN语句
Hive支持多张表进行连接,语句如下所示:
hive (hypers)> SELECT *
FROM test1 t1
JOIN test2 t2 ON t1.id = t2.id
JOIN test3 t3 ON t2.id = t3.id
每个 JOIN 都会启动一个 MapReduce 作业。第一个MapReduce作业连接 test1 表和 test2 表,第二个MapReduce作业连接第一个MapReduce作业的输出结果和 test3 表。
13、ORDER BY 和 SORT BY 语句
Hive中的 ORDER BY语句和SQL语句一样,可以实现对结果集的排序,如下所示:
hive (hypers)> select * from student order by age asc,stuId desc;
OK
student.stuid student.name student.sex student.age
15317478 Jerry 0 19
15317467 Alice 0 20
15317423 Tom 1 20
15317412 Jack 0 20
15317432 Jimmy 1 21
15317408 Rose 1 21
Time taken: 11.929 seconds, Fetched: 6 row(s)
上述语句表示按照age字段升序,stuId字段降序排序。
如果Hive表中的数据非常多,使用 ORDER BY排序可能会导致执行的时间过长,此时可以设置Hive的属性 hive.mapred.mode为strict,则排序语句后面必须加上 LIMIT限制查询的结果条数,以避免数据量太多造成的执行时间过长的问题,如下所示:
hive (hypers)> SET hive.mapred.mode = strict;
hive (hypers)> select * from student order by age asc,stuId desc limit 100;
OK
student.stuid student.name student.sex student.age
15317478 Jerry 0 19
15317467 Alice 0 20
15317423 Tom 1 20
15317412 Jack 0 20
15317432 Jimmy 1 21
15317408 Rose 1 21
Time taken: 9.378 seconds, Fetched: 6 row(s)
SORT BY语句会在每个Reduce中对数据进行排序,可以保证每个Reduce输出的数据是有序的(全局不一定有序),并可以提高全局排序的性能,如下所示:
hive (hypers)> select * from student sort by age asc,stuId desc limit 100;
OK
student.stuid student.name student.sex student.age
15317478 Jerry 0 19
15317467 Alice 0 20
15317423 Tom 1 20
15317412 Jack 0 20
15317432 Jimmy 1 21
15317408 Rose 1 21
上述语句会在每个Reduce中对age字段进行升序排序,同时对create_time字段进行降序排序。如果Reduce个数为1,则ORDER BY和SORT BY语句的查询结果相同;如果Reduce个数大于1,则SORT BY输出的结果为局部有序。
14、 DISTRIBUTE BY 和 SORT BY语句
DISTRIBUTE语句结合SORT BY语句可以实现在第一列数据相同时,能够按照第二列数据进行排序,如下所示:
hive (hypers)> select * from student distribute by sex sort by age,stuId;
OK
student.stuid student.name student.sex student.age
15317478 Jerry 0 19
15317412 Jack 0 20
15317423 Tom 1 20
15317467 Alice 0 20
15317408 Rose 1 21
15317432 Jimmy 1 21
DISTRIBUTE BY语句能够保证sex相同的数据进入同一个 Reduce 函数,在 Reduce中再按照 age 和 stuId 排序即可实现在第一列数据相同时,按照第二列数据排序。
15、CLUSTER BY语句
如果 DISTRIBUTE BY 和 SORT BY 语句中的列完全相同,并且都是按照升序排序,则可以使用CLUSTER BY语句代替DISTRIBUTE BY和SORT BY语句,如下所示:
select * from student distribute by age sort by age;
上面的语句等价于:
hive (hypers)> select * from student cluster by age;
OK
student.stuid student.name student.sex student.age
15317478 Jerry 0 19
15317467 Alice 0 20
15317423 Tom 1 20
15317412 Jack 0 20
15317432 Jimmy 1 21
15317408 Rose 1 21
16、类型转换
类型转换可以使用 cast(value As TYPE)语法,如下所示:
hive (hypers)> select * from student where cast(stuId AS INT) >= 15317450;
OK
student.stuid student.name student.sex student.age
15317478 Jerry 0 19
15317467 Alice 0 20
上述语句表示将 stuId 转化为 INT 类型。
17、分桶抽样
Hive支持分桶抽样查询,如下所示:
hive (hypers)> SELECT * FROM student TABLESAMPLE (BUCKET 2 OUT OF 6 ON stuid);
OK
student.stuid student.name student.sex student.age
15317467 Alice 0 20
上述语句表示查询时分6个桶,取第2个桶,分桶的依据是将id值的哈希值除以桶数6的余数。也可以采用随机抽样的方式,如下所示:
hive (hypers)> SELECT * FROM student TABLESAMPLE (BUCKET 2 OUT OF 6 ON RAND());
OK
student.stuid student.name student.sex student.age
15317478 Jerry 0 19
Time taken: 0.04 seconds, Fetched: 1 row(s)
可以在创建表时指定分桶,需要提前将 Hive 的 hive.enforce.bucketing属性设置为 true。该属性可以在 hive-site.xml文件中配置,如下所示:
hive.enforce.bucketing
true
也可以在Hive命令行设置,如下所示:
hive (default)> SET hive.enforce.bucketing = true;
创建表时指定分桶,并插入 student 表中的 id列数据,如下所示:
hive (hypers)> CREATE TABLE test_bucket(id INT) CLUSTERED BY (id) INTO 3 BUCKETS ;
OK
Time taken: 0.086 seconds
hive (hypers)> INSERT OVERWRITE TABLE test_bucket SELECT stuid FROM student;
OK
stuid
Time taken: 24.261 seconds
上述语句首先创建一个 test_bucket表,并将 test_bucket 表划分为3个桶,然后将 student 表中的 id 列数据插入 test_bucket表中。插入的数据会被保存在3个文件中,每个桶一个文件,保存在 test_bucket表路径下。
18、 UNION ALL 语句
Hive 支持 UNION ALL查询,其主要用于多表数据合并的场景。使用 UNION ALL语句要求各表查询出的字段类型必须完全匹配,如下所示:
SELECT t.id,t.name
FROM (
SELECT t1.id,t1.name FROM test1 t1
UNION ALL
SELECT t2.id,t2.name FROM test2 t2
UNION ALL
SELECT t3.id,t3.name FROM test3 t3
) t
注意:| 在Hive中使用
UNION ALL语句,必须使用嵌套查询 。|