
当用户输入一堆这样的字符串到 Elasticsearch ?
1、问题引出
如下样例数据已导入 Elasticsearch,如何实现特定字段检索?并计算出特定子字段的长度?
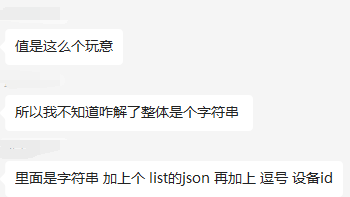
"message": "[策略排序]排序后结果:[{\"intentItems\":[\"200001\"],\"level\":1,\"moduleCode\":\"CENTER_PIT\",\"priority\":100,\"ruleId\":3947,\"sortScore\":9900.0,\"strategyId\":1000,\"strategyItemId\":1003}],deviceId:0aa81c2d-5ec9-3c09-81ba-7857709379ad"
2、问题拆解
大前提:Elasticsearch document 都是以 json 形式存储的。
问题引出部分的数据不够规范,本意是 json 数据,实则存储为了字符串。
存储为字符串就带来了后续检索的极大不便利性。
所以,需要考虑做一下转换。
转换的方式有很多,写入的时候 json 解析一下再写入,大家都能想到。
有没有更为快捷的方式呢?这时候考虑用一下 ingest pipeline 的预处理功能中的 json processor。

3、具体实现
第一步:样例数据格式化。
POST test-009/_bulk
{"index":{"_id":1}}
{"message":"{\"rst\":[{\"intentItems\":[\"200001\", \"200002\"],\"level\":1,\"moduleCode\":\"CENTER_PIT\",\"priority\":100,\"ruleId\":3947,\"sortScore\":9900.0,\"strategyId\":1000,\"strategyItemId\":1003}],\"deviceId\":\"0aa81c2d-5ec9-3c09-81ba-7857709379ad\"}"}
写入后,Kibana 检索召回如下所示。
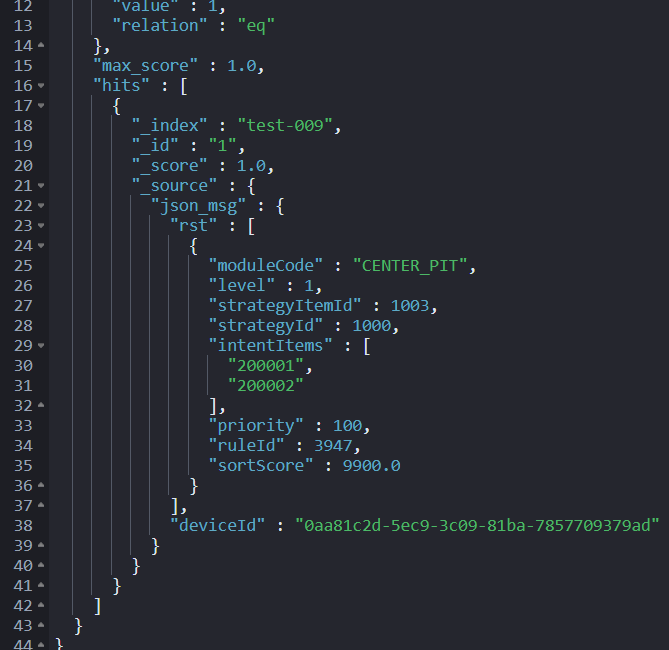
第二步:字符串转 json
PUT _ingest/pipeline/msg2json_pipeline
{
"processors": [
{
"json": {
"field": "message",
"target_field" : "json_msg"
}
},
{
"remove": {
"field": "message",
"if": "ctx.message != null"
}
}
]
}
json processor
用途:message 文本串转为 json_msg 目标 json 串。
remove processor
用途:原有的 message 字段已无实际意义,删除之,实际是“清理门户”,释放空间。
注意:ingest processor 是 Elasticsearch 5.0 开始就有的功能,随着版本的更迭,相关预处理器逐步丰富、扩展、完善和壮大。
第三步:验证 json 转换是否ok
POST test-009/_update_by_query?pipeline=msg2json_pipeline
{
"query": {
"match_all": {}
}
}
POST test-009/_search
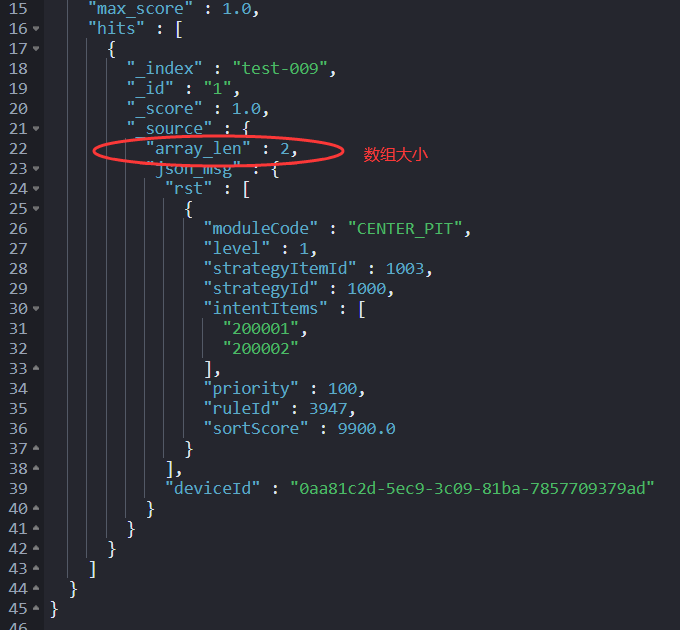
第四步:再求 intentItems 数组大小。
PUT _ingest/pipeline/len_pipeline
{
"processors": [
{
"script": {
"lang": "painless",
"source": """
ctx.array_len = ctx.json_msg.rst[0].intentItems.size();
"""
}
}
]
}
POST test-009/_update_by_query?pipeline=len_pipeline
{
"query": {
"match_all": {}
}
}
POST test-009/_search
当然,update_by_query 不是最优方案,本文只是方便大家看到没一个细分步骤故意为之。
更为便捷的方案是:创建索引的时候指定 default_pipeline,把上面写的 json processor、ingest processor、remove processor 都整合到
default_pipeline
即可。
篇幅原因,不再展开。
4、小结
之前文章也多次强调,Elasticsearch 自带预处理功能比较强大,能满足绝大多数业务的基础数据清理、清洗、转换功能。
也有同学提问道:能否完全替换到 logstash 的 filter 功能。官方也强调过,是不可以的!!
以当下(2023-01-12)最新 Elasticsearch 8.6 版本为例,从数据量上跟大家详细说明一下:Logstash filter 插件个数为
48
个,而 Elasticsearch Ingest processors 个数为
40
个。再具体一点,Logstash filter 下的:logstash-integration-jdbc、logstash-filter-uuid 等 Elasticsearch Ingest processors 是不具备的。
一句话概括:Elasticsearch Ingest pipeline 能搞定的都交给它搞定预处理,搞不定的如果技术栈里面有 Logstash转交给 Logstash 的 filter 插件处理即可。
推荐阅读
全网首发!从 0 到 1 Elasticsearch 8.X 通关视频
重磅 | 死磕 Elasticsearch 8.X 方法论认知清单(2022年国庆更新版)
Elasticsearch 预处理没有奇技淫巧,请先用好这一招!
更短时间更快习得更多干货!
和全球 1800+ Elastic 爱好者一起精进!

比同事
抢先
一步学习进阶干货
!