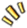作为前端,工作中处理过什么复杂的需求?
点击上方 前端Q,关注公众号
回复加群,加入前端Q技术交流群
恶狠狠的休息了几天,今天,大年初7,开工大吉,在新的年轮里,祝各位,位高权重责任轻,钱多事少离家近,工资领到手抽筋,别人加班你加薪!新的年轮里,帅编也会继续加油,为大家推荐更多优质有料的文章

正文
先说背景,我目前在腾讯IMWeb团队,负责在线教育腾讯课堂的前端研发。
从春节假期到现在,我们遭遇了前所未有的流量峰值,虽然具体数字不方便透露,但是可以预想得到,那么多所学校在期间强制网络上课,学生加老师的数量是多么庞大。
如果说双十一是所有具有消费能力和冲动的人群冲击,那么这一次则是所有学生和老师的强制访问,访问者没有选择权,这是最可怕的一点。比双十一更可怕的是,我们没有时间准备,双十一也许可以提前几个月甚至半年开始谋划,这次的流量则完全是毫无预兆的突发性事件,要求我们在短时间内必须做出快速的决策响应。

截止现在,流量高峰已经冲击三波了,每一次都是几倍的增长,流量逐渐平稳,也让我能够偷闲刷一刷知乎。。
对于前端而言,最大的影响莫过于主域,一旦我们的主域扛不住,html都打不开了,整个全玩完。
在我们团队,主域的Nginx主要是由前端负责管理,在腾讯的运维体系下,STGW在下一层统统是交由业务来维护,运维同学完全不了解业务是如何发布和控制的。从某种程度来说,我们才是真正的DevOps,夸张一点说,运维同学与我们打交道也许仅限于机器申领与容量。

除了承载核心HTML入口,主域还承接了CDN的降级策略,防止某处运营商等问题直接导致CDN无响应,之前的教训让我们做了这层容灾。所以主域的稳定性至关重要。
所幸这里仅仅是静态渲染,抗住高并发不是太难的事情,不过Nginx对于前端的能力提出了更高的要求,对于Nginx的改动,有着严格的流程把控,务必做好充分的验证。
音视频链路对于课堂而言是重中之重,老师和学生的核心目的就是通过直播来上课,一旦音视频挂了,腾讯课堂所有其他功能形同鸡肋,这是前端第二项影响巨大的考验。

课堂前端团队针对于音视频领域做了非常多的优化,在疫情期间,音视频作为核心模块被重点关注,快速上线了快直播,简化WebRTC信令,分摊更大的流量,HLS降级WebRTC,混流开关等等。
由于我不主要负责音视频开发,音视频所做的工作远远大于这里提到的,我们组负责音视频的小姐姐已经不知道通宵了多少回,十分辛苦~

这个平台承接了所有的运营、类目、产品配置,对接CKV与CDB平台做数据存储,对接云COS做文件存储,通过JSON Schema配置出数据服务,同步ZK节点供后台查询。

目前成百上千张表都在这个平台上,一旦挂了,后果不可预料。这个平台整体运用了GraphQL技术作为访问查询,属于前端团队的第二大考验。
得益于SAS平台最初设计的简洁性,监控非常的充足,扩容也较为容易,非常轻松地挺过流量高峰。
IMPush是前端团队自研的消息通道,承接了所有socket消息转发。这个系统承接了聊天区所有的消息服务,与后台保持全双工长连接通道,利用Redis进行数据缓存,整体agent与center都会受到比较大的压力挑战。

这个服务如果挂了,所有的聊天区、弹幕都将面临瘫痪,影响也是非常大的。
同样的手段,借助于现有的负载均衡L5体系和资源,需要抗住巨大的并发量。
我习惯将监控、日志和灰度称为前端三板斧,是衡量一个前端团队是否专业的重要指标。很多前端并不注重这点,最多只有一个脚本报错的监控,最基本的测速返回码等监控都没有。
单论脚本报错监控,我们其实已经准备三套方案,BadJS+Sentry+FullLink,在超高的访问量下,可以预计所有的平台基本上都会挂,而脚本监控对于前端来说是非常重要的,三套系统的降级方案保证了我们在外网出问题的时候第一时间定位到问题所在,快速响应bug。
日志上报是前端最容易忽略的,当用户量多了你就会发现,很多问题是没有脚本报错的,如果只依赖于报错监控,很多外网问题两眼一抹黑,无从下手了。作为专业的前端,我们需要全链路的日志定位。

前端团队在这里借用开源的ELK方案,与后台全链路系统打通,在基础上通过DC通道上报落地,Agent代理不同监控系统,做成了上报中台方案,在Kibana系统上统一查询和定制报表。
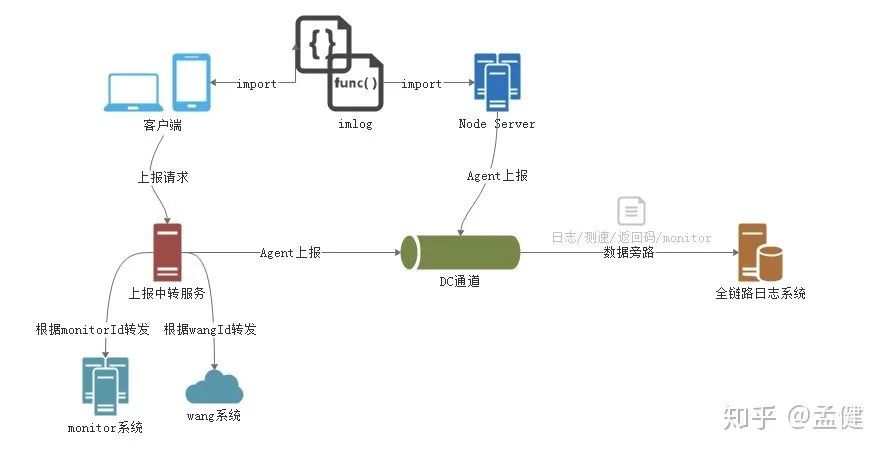
灰度方案其实相对是比较难做的,最简单的是按照机器灰度,但这种方案在实际环境中基本上是不可用的,对于一个需求来说,如果同时修改了老页面和新页面,会导致用户前后访问不一,甚至出现404情况。更好的方式是按照登录态灰度,这时候我们需要统一接入层,Nginx、TSW都是可以的选择,在白名单内用户进行灰度。
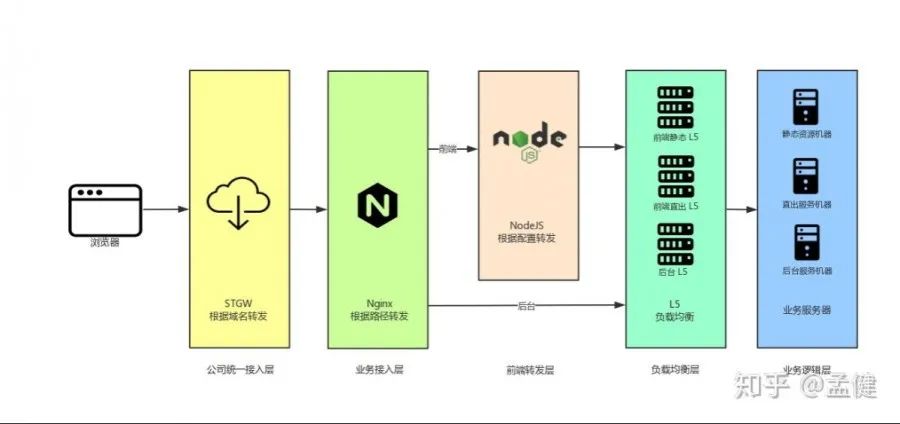
但针对CDN,我们无法架设统一的Node服务来接入,这时需要考虑离线方案,制作离线包以及PWA管理平台,利用离线版本进行登录态灰度,可与Node服务保持一致。
有了这三点的保障,我们才可以做到心中有底,数据支撑指导我们的行动,来抗住高并发流量。
在这场战役面前,前端不能自己独善其身,不仅仅要做好自己的分内事,更要帮助后台团队共渡难关。
首先,在核心场景下,按需屏蔽不重要的接口,帮助后台减轻压力,可根据后台的负载情况动态调整。

其次,前端自己要保持柔性,除了核心CGI外,其他接口无论是超时还是返错,都不要影响页面核心功能的正常运行,这对前端的代码提出了很高的要求,所幸平时团队CR习惯养成良好,对接口的异常处理也做的比较完善,只是模拟接口测试验证花费了一些时间。
你以为上面就是全部了?Too Naive!上面的几点只是挤出时间去做一些调整,重头戏还在于极度紧张的业务需求。
腾讯课堂之前的toB部分针对的是开课机构、个人老师,现在是学校教务、学校老师、学校领导、教育局领导,老板们直接重点关注,可想而知产品的压力有多大。
我们在两天内就推出了腾讯课堂极速版(https://ke.qq.com/s),支持老师10s开课,随时随地开课,目前已经迭代到了第4版。
众所周知,对于一个系统而言,由简入繁易,由繁入简难。腾讯课堂有着一套复杂的B侧管理体系,极速版要将这一切推翻,让老师极速开课,学生极速上课,这是多么困难的一件事情。课堂在这么短时间内拿下极速版的版本发布,体现了极强的开发战斗力。

在此期间,开发承接的工作量大约在平时的五倍左右,不仅仅需要通宵达旦,更需要快速响应,课堂前端每日均发布版本达到10次以上,如何在高频次的发布中不影响质量也是巨大的考验。
要保持高强度的战斗力,对于团队的基础效率工具建设提出了很高的要求。
Nohost方案对于测试环境多需求并行开发做了很好的支持,不仅支持前端分发,还利用docker打通了后台环境。
开发很便捷使用分支部署,产品可以在家切不同的需求环境体验,测试也可在家访问不同环境进行测试。

Tolstoy打通了后台的PB、CGI,让后台定义的协议能够自动生成文档、Mock、声明文件、测试用例等等,尤其是TS的自动生成,为开发提供了很大的遍历,让我们的TS项目开发的更快更好。
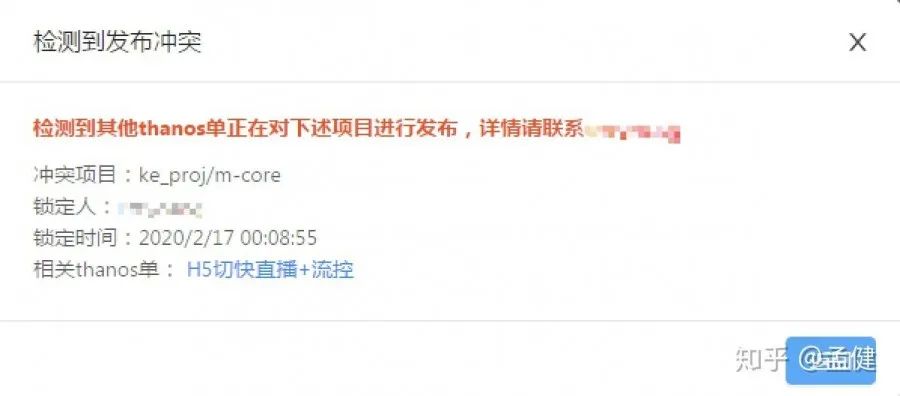
2.3 稳定上线需求——Thanos方案
Thanos方案是我核心主导的,它解决的是发布链路的问题,对于大公司而言,发布除了CI/CD之外,还有一些其他的额外流程保障,形成发布闭环。
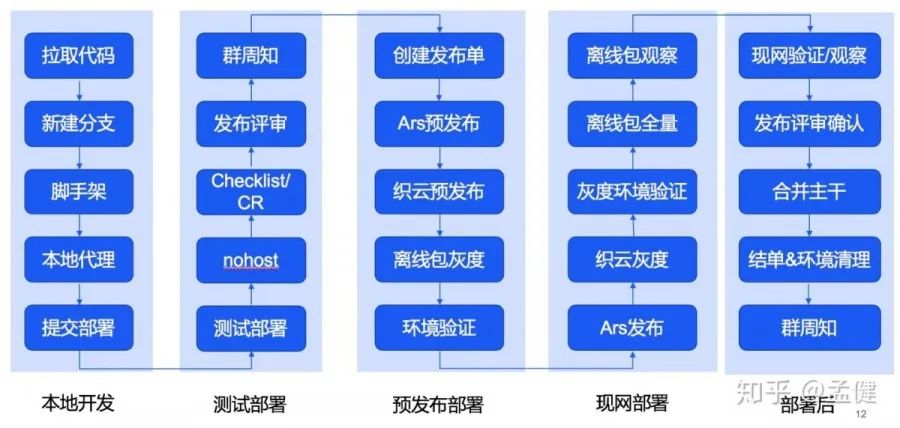
如果没有一个系统承载流程,这些杂乱无章的步骤可能成为发布事故的罪魁祸首。

另一方面,分支模型也是关键因素,采取分支发布的策略带来的好处很多,但缺点也有,其中很重要的是分支准入问题,以及发布覆盖问题,这两个普遍性问题在Thanos方案得到保障。
在高需求量,deadline又非常紧的情况下,对每个人的技术能力要求很高。腾讯课堂的前端复杂度还有很重要的一点体现在端上,老师端、学生端、机构端、APP端、PC端、小程序端、微信公众号、QQ公众号、题库、直播间等等等等……,这些端和项目可谓是眼花缭乱,数不过来。
很多项目历史悠久,包含了众多技术栈,从古老的FIS、QQ客户端内嵌、jQuery,到React、TypeScript、RN、音视频等等,切换一个项目,如同换了家公司,需要重新适应技术栈。
在人力不足的情况下,每个人都要去应对自己不熟悉的领域,可能你还没搞清楚什么是HLS就被拉去做音视频,或者完全没接触过fis的情况下去熟悉整个项目的构建打包流程,这对于个人快速上手能力和编程速度质量都提出很高的要求。
另一方面,文档在这一刻发挥出应有的价值,一般团队不怎么注重文档建设,一来写起来废时间,二来对于晋升和成长没什么帮助,看起来完全是利他性质,但实际上是互利。这时团队的价值观和管理者就非常重要了,文档的程度可以从侧面反映出团队的管理水平。
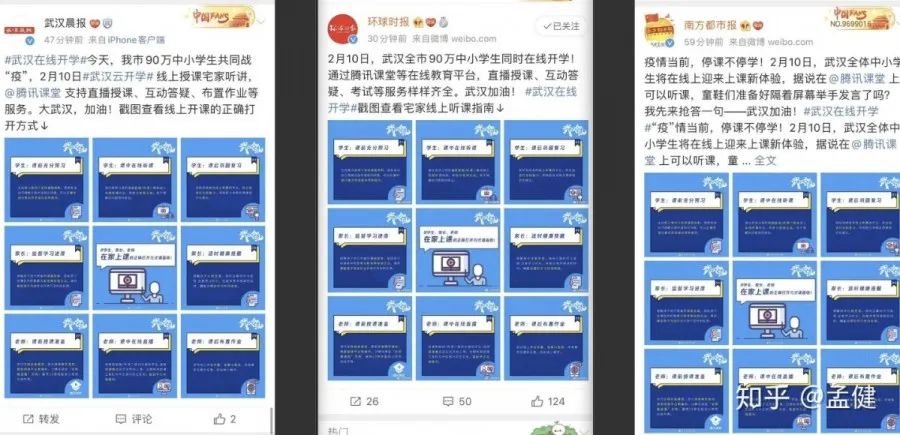
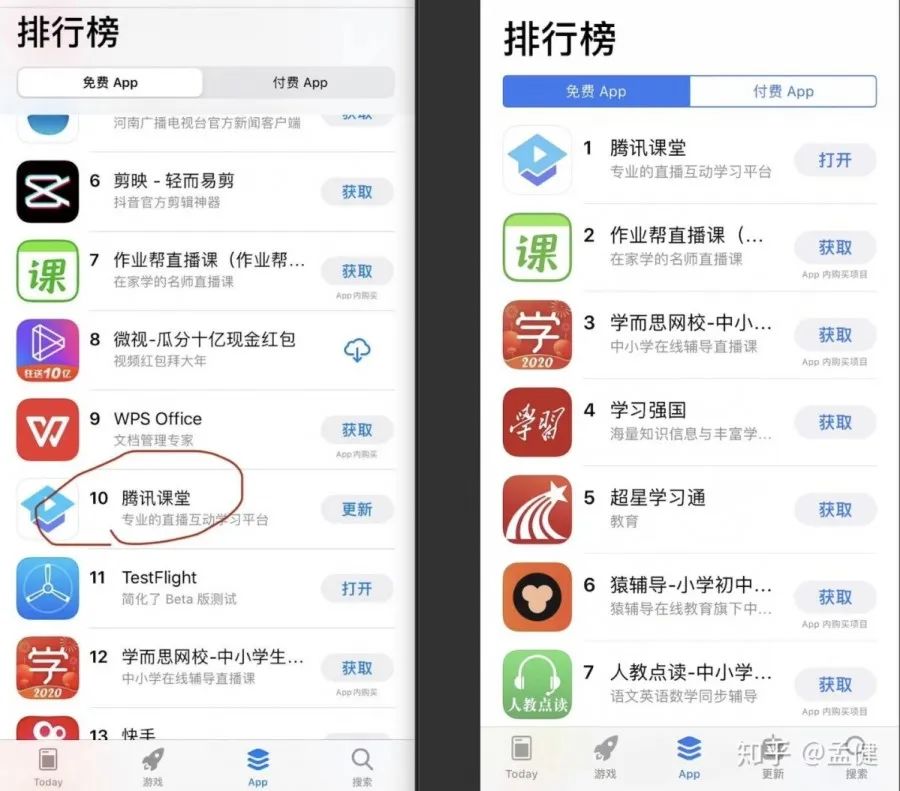
在大家共同努力下,腾讯课堂获得了更高的曝光度和认可度,也算是对我们付出结果的肯定。

最后,回归正题,前端的复杂度也许很多,比如之前我参与的CPU负载过高问题排查,用尽手段定位一个月之后发现是一条正则语句引发的,这种性质的复杂属于特定场景下的复杂度。而我今天提到的“复杂度”则比较普适,所有团队都存在面临这种场景的可能性,而对于每个团队而言,我认为没有一个团队会觉得应对起来很简单。更多需要的是公司资源调度+团队技术积累+个人能力的配合。
成长最高效的方式,不是一个人单枪匹马孤军奋斗,而是和大家并肩作战享受狂欢。
真正复杂的需求,个人的力量是有限的,如何协调整个团队的力量更为艰难。当团队在技术视野、技术方向上有前瞻性,沉淀性,个人不仅仅是埋头写业务时,是团队在推着个人成长,在高手云集的团队中保持核心竞争力,才是个人成长最合适的方向。
来源:腾讯IMWeb团队
往期推荐
第一次拿全年年终奖的前端女程序员的2021 速来!腾讯微信团队&广告团队招人,简历直推面试官! 当webpack有了vite的速度你会喜欢吗?
最后
欢迎加我微信,拉你进技术群,长期交流学习...
欢迎关注「前端Q」,认真学前端,做个专业的技术人...
点个在看支持我吧