在上周介绍Iceberg原理的文章中,我有提到Iceberg的设计初衷是为了解决Hive数仓所遇到的问题,主要有4点:
没有ACID保证
只能支持partition粒度的谓词下推
确定扫描的文件需要使用文件系统的list操作
partition字段必须显式出现在query里面
其中2和3都是直接影响query性能的问题,而Iceberg的主打卖点正是更快的查询速度。作者Ryan Blue在DataWorks Summit上宣讲Iceberg的ppt上就有列出Netflix在使用了Iceberg之后的性能提升情况Hive光是确定查询计划就要9.6分钟,而Iceberg确定查询计划只要42秒首先,对于存储层的数据湖系统(Delta,Hudi,Iceberg)来说,query在存储层发生的事情粗略地可分为两个阶段:确定需要读取的文件列表(planning阶段)
读取数据并传递给计算引擎(execution阶段)
对于execution阶段,相信比较符合直觉,是所有人都认可的存储层需要做的事情。但是对于planning阶段,或许有些朋友会有疑问:Spark等计算引擎需要产生执行计划,我还能理解,为什么存储层也需要执行计划?其实存储层的执行计划没有计算层的那么复杂,但确实也有一些需要做计划的事情,主要是以下2点:需要读取哪些partition
每个partition下有哪些文件
讲完了planning阶段需要解决的问题,回到我们最初的主题,来讲讲Iceberg所做的优化。其实Iceberg在这两个阶段都有做优化,优化机制总的来说主要有2种:
接下来就会讲一讲Iceberg是如何实现这两个功能的。Partition Pruning(分区剪枝),主要针对的是planning阶段中的第一个问题:需要读取哪些partition。分区剪枝并不是一个新鲜事物。比如Hive就会根据查询条件来决定是否使用分区查询,以及具体查询哪个或哪几个分区,其实就是一种分区剪枝。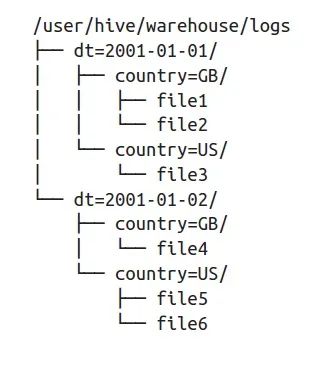
Hive会根据查询条件确定读取哪个分区
Iceberg没有沿用Hive相对简单的分区规则,而是自己实现了一套更为复杂的分区系统及分区剪枝算法,名为Hidden Partition。Iceberg选择自己实现,目的是为了克服Hive的分区功能在使用上的不方便以及容易出错。在Iceberg里面,分区是存储系统的一个实现细节,用户无需理解分区和文件系统的路径是如何对应的。(关于Hive的分区功能的问题,请见上一篇文章)首先在Iceberg中我们用下面的CREATE语句来创建分区表
CREATE TABLE foobar (id bigint, data string) USING iceberg PARTITIONED BY (truncate(id, 3))
和Hive不同的是,Iceberg实现分区剪枝不是依赖文件所在的目录,而是利用了Iceberg特有的manifest文件。上一篇文章中有提到,Iceberg每次写入都会产生一个新的snapshot,而一个snapshot在文件系统上就对应一个manifest文件。{ ... "snapshot_id": { "long": 4370069137697126000 }, "data_file": { "file_path": ".../table/data/id_trunc=0/00000-0-1c1865ee-a812-465c-87cb-7588478c2d8f-00001.parquet", "file_format": "PARQUET", "partition": { "id_trunc": { "long": 0 } }, ... }}{ ... "snapshot_id": { "long": 4370069137697126000 }, "data_file": { "file_path": ".../table/data/id_trunc=3/00001-1-b18c1240-86bb-48da-85e9-4a0e41a82b26-00001.parquet", "file_format": "PARQUET", "partition": { "id_trunc": { "long": 3 } }, ... }}
其中的data_file字段记录的是这个snapshot里包含的数据文件的信息,注意到data_file字段里有一个字段是partition,里面记录的就是这个data_file所在的partition信息。Iceberg正是使用这些元数据确定每个分区里包含哪些文件的。相比于Hive,Iceberg的这种partition实现方式有以下好处:直接定位到parquet文件,无需调用文件系统的list操作。
partition的存储方式对用户透明,用户在修改partition定义时Iceberg可以自动地修改存储布局而无需用户操作。
讲完了分区剪枝,接下来再讲一讲Predicate Pushdown(谓词下推)。前几篇文章中也有提到过,谓词下推是计算引擎(Spark等)把查询的过滤条件(where条件)下推到存储层,在存储层面就把一部分必然不满足条件的数据过滤掉,从而减少存储层返回给计算引擎的数据量。在讲Iceberg如何实现谓词下推之前,我先讲一讲Spark是如何实现谓词下推的。Spark作为计算层的系统,自己并不实现谓词下推,而是交给文件格式的reader来解决。例如,对于parquet文件,Spark使用下面这个类读取parquet文件/** * @param readSupport Object which helps reads files of the given type, e.g. Thrift, Avro. * @param filter for filtering individual records */ public ParquetRecordReader(ReadSupport readSupport, Filter filter) { internalReader = new InternalParquetRecordReader(readSupport, filter); }
注意ParquetRecordReader的第二个参数filter,就是parquet对计算引擎提供的接口,用于传入过滤条件。而ParquetRecordReader从parquet文件中读取数据后,会首先使用filter过滤掉不满足的record,然后再交给计算引擎。
相比于Spark,Iceberg做得更多一些。Iceberg会在两个层面实现谓词下推:1. 在snapshot层面,过滤掉不满足条件的data file2. 在data file层面,过滤掉不满足条件的数据其中第一点是Iceberg特有的,也是利用了manifest文件里保存的元数据。Iceberg在manifest文件里记录了每个字段的上界和下界。所以在planning阶段,Iceberg就可以利用这个信息,过滤掉不满足条件的文件,进一步减少文件的扫描量。{ ... "data_file": { "file_path": ".../table/data/id_trunc=0/00000-0-1c1865ee-a812-465c-87cb-7588478c2d8f-00001.parquet", ... "lower_bounds": { "array": [ { "key": 1, "value": 1 }, { "key": 2, "value": "a" } ] }, "upper_bounds": { "array": [ { "key": 1, "value": 2 }, { "key": 2, "value": "b" } ] }, ... }}
这个文件包含两条数据,(1, “a”)和(2, “b”)。可以看到上界和下界分别是1和2,a和b第二点则和Spark类似,也是在读取文件时,过滤掉不满足条件的数据。不过和Spark不同的是,Iceberg作为存储层的系统,使用的是parquet更偏底层的ParquetFileReader接口,自己实现了过滤逻辑。和Spark的ParquetRecordReader有什么不同呢?Iceberg的这种实现方式可以直接跳过整个row group,更进一步地减少io量,不过碍于篇幅,细节我就不展开讲了。
以上就是Iceberg在优化查询性能方面所实现的优化机制,本质都是为了减少数据查询量。可以看到manifest文件在Iceberg的优化逻辑中起到非常关键的作用,正是因为Iceberg利用了云原生数据仓库的文件大多不可变的特性,收集了非常多关于数据分布的元数据的关系。相信未来存储层会在这方面有更多的发展,然后和计算引擎的结合更为紧密,从而进一步提高查询的性能。最后你或许会问,既然Iceberg有这些query优化机制,那Hudi有同样的功能吗?就我从Hudi的源代码看来,现阶段Hudi实现了一半。Hudi实现了分区剪枝功能,但是谓词下推功能目前似乎还没有实现。- Iceberg对减少数据查询量提供了两种优化机制:分区剪枝和谓词下推。
- Iceberg收集了关于数据分布的元数据,并利用这些元数据实现更高效的数据裁剪,减少了数据的查询量。


