
Hudi 实践 | 使用 Apache Hudi 构建下一代 Lakehouse
1. 概括
本文介绍了一种称为Data Lakehouse的现代数据架构范例。Data Lakehouse相比于传统的数据湖具有很多优势,本文说明了如何通过现代化数据平台并使用Lakehouse架构来应对客户端所面临的可扩展性、数据质量和延迟方面的挑战。本文介绍了使用Apache Hudi实现Data Lakehouse的基本知识和步骤。
2. 前言
过去十年随着物联网、云应用、社交媒体和机器学习的发展,公司收集的数据量呈指数级增长,同时对高质量数据的需求从几天和几小时的频率变为几分钟甚至几秒钟的时间。
数年来数据湖作为存储原始和丰富数据的存储库发挥了重要作用。但是随着它们的成熟,企业意识到维护高质量、最新和一致的数据是非常复杂的。除了摄取增量数据的复杂性之外,填充数据湖还需业务环境和高度依赖批处理。以下是现代数据湖的主要挑战:
•基于查询的变更数据捕获:提取增量源数据的最常见方法是依赖定义过滤条件的查询。当表没有有效字段来增量提取数据时,在源数据库上添加额外负载或无法捕获数据库的每一次变更,基于查询的CDC不包括已删除的记录,因为没有简单的方法来确定是否已删除了记录。基于日志的CDC是首选方法,可以解决上述挑战。本文将进一步讨论该方法。•数据湖中的增量数据处理:负责更新数据湖的ETL作业必须读取数据湖中的所有文件进行更改,并将整个数据集重写为新文件(因为没有简单的方法更新记录所在的文件)。•缺少对ACID事务的支持:如果同时存在读写,不遵从ACID事务会导致结果不一致。
数据体量的增加和保持最新数据使上述挑战更加复杂。Uber、Databricks和Netflix提出了旨在解决数据工程师面临的挑战的解决方案的数据湖处理框架,旨在在分布式文件系统(例如S3、OSS或HDFS)上的数据湖中执行插入和删除操作。下一代Data Lakes旨在以可扩展性、适应性和可靠的方式提供最新数据,即Data Lakehouse。
3. 什么是Lakehouse
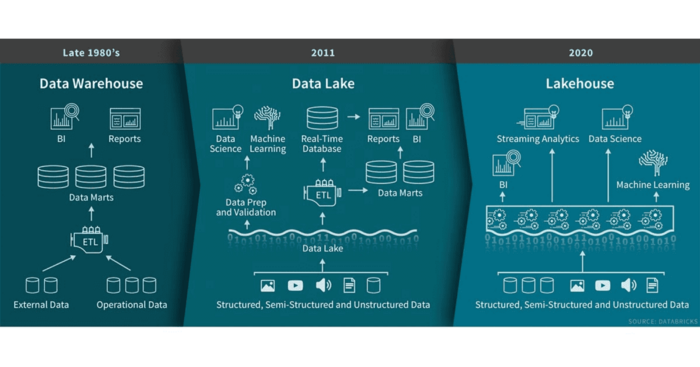
更多详情可参考如下文章:Lakehouse: 统一数据仓库和高级分析的新一代开放平台,什么是LakeHouse
简而言之:Data Lakehouse = Data Lake + Data Warehouse
传统数据仓库旨在提供一个用于存储已针对特定用例/数据进行了转换/聚合的历史数据平台,以便与BI工具结合使用获取见解。通常数据仓库仅包含结构化数据,成本效益不高,使用批处理ETL作业加载。
Data Lakes 可以克服其中一些限制,即通过低成本存储支持结构化,半结构化和非结构化数据,以及使用批处理和流传输管道。与数据仓库相比,数据湖包含多种存储格式的原始数据,可用于当前和将来的用例。但是数据湖仍然存在局限性,包括事务支持(很难使数据湖保持最新状态)和ACID合规性(不支持并发读写)。
数据湖中心可利用S3,OSS,GCS,Azure Blob对象存储的数据湖低成本存储优势,以及数据仓库的数据结构和数据管理功能。支持ACID事务并确保并发读取和更新数据的一致性来克服数据湖的限制。此外与传统的数据仓库相比,Lakehouse能够以更低的延迟和更高的速度消费数据,因为可以直接从Lakehouse查询数据。
Lakehouse的主要特性如下
•事务支持•Schema enforcement and governance(模式实施和治理)•BI支持•存储与计算分离•开放性•支持从非结构化数据到结构化数据的多种数据类型•支持各种工作负载•端到端流
为了构建Lakehouse,需要一个增量数据处理框架,例如Apache Hudi。
4. 什么是Apache Hudi
Apache Hudi代表Hadoop Upserts Deletes Incrementals,是Uber在2016年开发的开源框架,用于管理分布式文件系统(如云存储,HDFS或任何其他Hadoop FileSystem兼容存储)上的大型文件集,实现了数据湖中原子性、一致性、隔离性和持久性(ACID)事务。Hudi的commit模型基于时间轴,该时间轴包含对表执行的所有操作,Hudi提供了以下功能:
•通过快速,可插拔的索引支持Upsert。•具有回滚的原子发布,保存点。•读写快照隔离。•使用统计信息管理文件大小和布局。•行和列数据的异步压缩。•时间轴元数据以跟踪血统。
4.1 使用用例
1. 使用变更数据捕获来更新/删除目标数据
变更数据捕获(CDC)是指识别和捕获源数据库中所做的变更。它将更改从源数据库复制到目的端(在本例中为数据湖)。这对于将插入、更新和删除操作捕获到目标表中特别重要。
一下列举了三种最常用的CDC方法
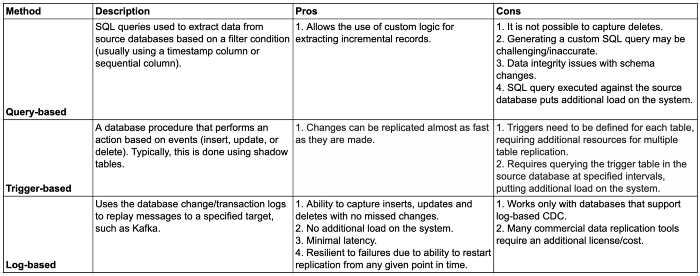
基于日志的CDC为将更改从源数据库复制到数据湖库是最好的方案,因为它能够捕获已删除的记录,而这些记录无法使用基于查询的CDC捕获,因为如果在源数据中不存在删除标志,则无法捕获。
Hudi可以通过在现有数据集中找到适当的文件并重写它们来处理更改数据捕获。此外它还提供了基于特定时间点查询数据集的功能,并提供了时间旅行。
使用CDC工具(例如Oracle GoldenGate,Qlik Replicate(以前称为Attunity Replicate)和DMS)进行近实时数据摄取非常通用,将这些变更应用于现有数据集至关重要。
2. 隐私条例
GDPR等最新的隐私法规要求公司必须具有记录级别的更新和删除功能。通过支持Hudi数据集中的删除,可以大大简化针对特定用户或在特定时间范围内更新或删除信息的过程。
4.2 不同类型表
**COPY ON WRITE(写时复制)**:数据以Parquet文件格式存储(列存储),并且每次更新都会创建文件的新版本。此存储类型最适合于繁重的批处理工作负载,因为数据集的最新版本立刻可用。
**MERGE ON READ(读取时合并)**:数据存储为Parquet(列存储)和Avro(基于行的存储)文件格式的组合。更新记录到基于行的增量文件中,当进行压缩(Compaction)时将产生新版本列存文件。这种存储类型更适合于繁重的流工作负载,因为提交是作为增量文件写入的,而读取数据集则需要合并Parquet和Avro文件。
一般经验法则:对于仅通过批处理ETL作业进行更新的表,可使用"写时复制"。对于通过流ETL作业更新的表,可使用"读取时合并"。有关更多详细信息,请参阅Hudi文档中的如何为工作负载选择存储类型[1]。
4.3 不同查询类型
•快照读:指定提交/压缩操作的表的最新快照。对于"读时合并"表,快照查询将即时合并基本文件和增量文件;因此有一定的延迟。•增量读:指定提交/压缩以来表中的所有变更。•读优化:指定的提交/压缩操作的表的最新快照。对于"读时合并"表,读取优化查询返回一个视图,该视图仅包含基本文件中的数据,而不合并增量文件。
4.4 Hudi的优势
•解决数据质量问题,例如重复记录,延迟到达的更新等,这些问题通常在传统的增量批处理ETL管道中存在。•提供对实时管道的支持。•异常检测,机器学习用例,实时检测等•创建可用于跟踪更改的机制(时间轴)。•提供对通过Hive和Presto进行查询的原生支持。
Apache Hudi增量数据处理框架实现Lakehouse,我们着手设计一种解决方案来克服寻求增强其数据平台的客户所面临的关键挑战。
5. 问题
我们与需要改进、具有成本效益和可扩展性的数据平台的客户合作,该平台将使他们的数据科学家能够使用最新数据并以较低的延迟进行近乎实时的预测,从而获得更好的见解。他们现有的批处理ETL作业按时进行,并且计算量大,因为它需要重新处理整个数据集。此外这些过程使用基于查询的CDC方法,导致无法捕获每个源库变更。过时的数据和不准确的数据导致对数据平台缺乏信任,而不能从数据中获得任何直接价值。
6. 解决方案
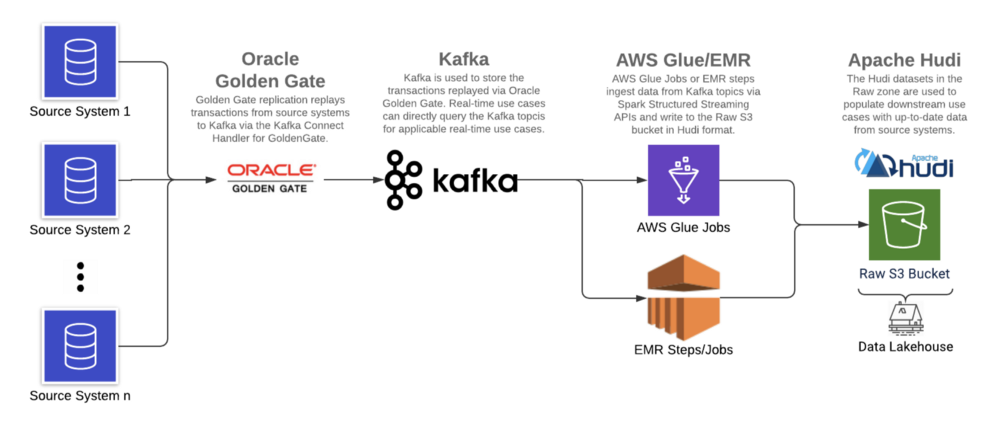
使用基于日志的CDC工具(Oracle GoldenGate),Apache Kafka和增量数据处理框架(在AWS上运行的Apache Hudi),我们在AWS S3上构建了数据湖,以减少延迟,改善数据质量并支持ACID事务。
6.1 架构
6.2 环境
•Oracle大数据Oracle GoldenGate[2]:19c•Confluent Kafka[3]:5.5.0•Apache Spark(Glue)[4]:2.4.3•ABRiS[5]:3.2•Apache Hudi[6]:0.5.3
由于客户现有的Oracle GoldenGate产品系列,Oracle GoldenGate被用作基于日志的CDC工具从源系统日志中提取数据,日志实时地复制到Kafka,从中读取消息并以Hudi格式写入数据湖。
Apache Hudi与AWS EMR和Athena集成,是增量数据处理框架的理想选择。
6.3 实施步骤
6.3.1 使用Oracle GoldenGate复制源数据
如前所述,基于日志的CDC是最佳解决方案,因为它可以同时处理批量和流式案例。对于批处理和流式源,不再需要具有单独的摄取模式。传统上批处理工作负载是利用一条SQL语句,并以所需频率运行该SQL语句。相反,基于日志的CDC可以捕获任何更改,然后将其重播到目的端(即Kafka)。摄取与消费的解耦引入了灵活性,可根据需要在Lakehouse内更新数据的频率来提取增量数据。这样可以最大程度地降低成本,因为可以在定义的保留期内从Kafka检索数据。
Oracle GoldenGate是一种数据复制工具,用于从源系统捕获事务并将其复制到目标(例如Kafka主题或另一个数据库)中。它利用数据库事务日志来工作,该日志记录了数据库中发生的所有操作,OGG将读取事务并将其推送到指定的目的端, GoldenGate支持多个关系数据库,包括Oracle,MySQL,DB2,SQL Server和Teradata。
此解决方案中使用Oracle GoldenGate将变更从源数据库流式传输到Kafka过程分为三个步骤:
•通过Oracle GoldenGate 12c(经典版本)从源数据库跟踪日志中提取数据:源数据库发生的事务以中间日志格式(跟踪日志)存储被实时提取。•将跟踪日志送到辅助远程跟踪日志:将提取的跟踪日志送到另一个跟踪日志(由Oracle GoldenGate for Big Data 12c实例管理)。•使用Kafka Connect处理程序,通过Oracle GoldenGate for Big Data 12c将跟踪日志复制到Kafka:接收提取的事务并将其复制到Kafka消息中,在发布到Kafka之前,此过程将序列化(带有或不带有Schema Registry)Kafka消息,并对从事务日志重播的消息执行类型转换(如果需要)。
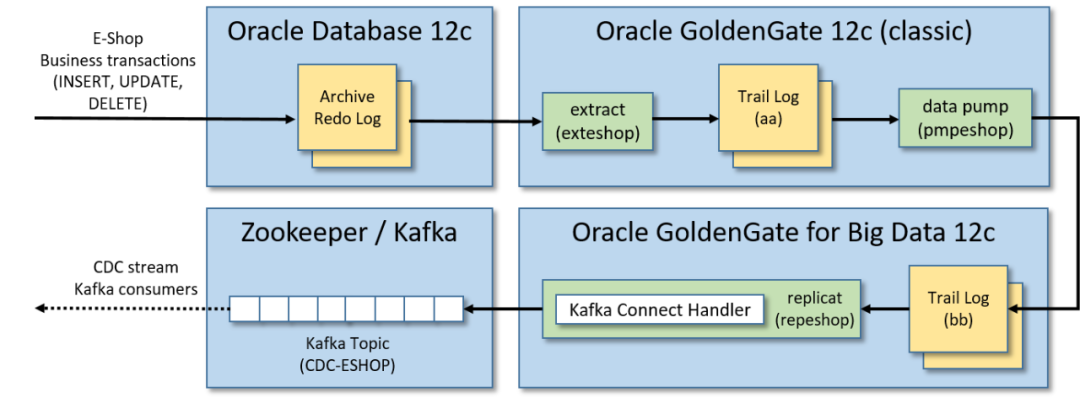
注意:默认情况下更新的记录仅包含通过GoldenGate复制时更新的列,为了确保增量记录可以以最小的转换合并到数据湖中(即复制具有所有列的整个记录),必须启用补充日志记录[7],这将包括每个记录的"before"和"after"图像。
GoldenGate复制包含一个"op_type"字段,该字段指示源跟踪文件中数据库操作的类型:I表示插入,U表示更新,D表示删除。该字段对于确定如何在数据湖库中增加/删除记录很有帮助。
以下是样本插入记录:
{"table": "GG.TCUSTORD","op_type": "I","op_ts": "2013-06-02 22:14:36.000000","current_ts": "2015-09-18T10:17:49.570000","pos": "00000000000000001444","primary_keys": ["CUST_CODE","ORDER_DATE","PRODUCT_CODE","ORDER_ID"],"tokens": {"R": "AADPkvAAEAAEqL2AAA"},"before": null,"after": {"CUST_CODE": "WILL","CUST_CODE_isMissing": false,"ORDER_DATE": "1994-09-30:15:33:00","ORDER_DATE_isMissing": false,"PRODUCT_CODE": "CAR","PRODUCT_CODE_isMissing": false,"ORDER_ID": "144","ORDER_ID_isMissing": false,"PRODUCT_PRICE": 17520,"PRODUCT_PRICE_isMissing": false,"PRODUCT_AMOUNT": 3,"PRODUCT_AMOUNT_isMissing": false,"TRANSACTION_ID": "100","TRANSACTION_ID_isMissing": false}}
注意:GoldenGate记录在"before"包含一个空值,在"after"包含一个非空值。
样本更新记录[8]
注意:GoldenGate更新记录包含映像前非空和映像后非空。
样本删除记录[9]
注意:GoldenGate删除记录在映像之前包含非null,在映像之后包含null。
6.3.2 在Kafka中捕获复制的数据
GoldenGate 复制的目标是 Kafka。由于 GoldenGate for BigData 将通过 Kafka Connect 处理程序将记录复制到 Kafka,因此支持模式演变和通过Schema Registry提供的其他功能[10]。
为什么选择Kafka充当CDC工具和数据湖库之间的中间层,主要有两个原因。
•第一个原因是GoldenGate无法以Apache Hudi格式将CDC数据直接从源数据库复制到 Lakehouse 。Kafka 和 Spark Structured Streaming 之间现有集成使Kafka成为暂存增量记录的理想选择,然后可以以Hudi格式对其进行处理和写入。•第二个原因是解决需要近实时延迟的消费者,例如基于一组事务来检测并避免用户的服务丢失。
6.3.3 从Kafka读取数据并以Hudi格式写入S3
Spark Structured Streaming 作业执行以下操作:
1. 读取kafka记录
TOPIC_NAME = "topic_name"KAFKA_BOOTSTRAP_SERVERS = "host1:port1,host2:port2"# read data from Kafkadf = (spark.readStream.format("kafka").option("kafka.bootstrap.servers", KAFKA_BOOTSTRAP_SERVERS).option("subscribe", TOPIC_NAME).load())
2. 使用Schema Registry反序列化记录
注意:使用 Confluent Avro 格式序列化的 Kafka 主题中的任何数据都无法使用 Spark API 在本地进行反序列化,从而阻止了对数据的任何下游处理。使用 GoldenGate 复制的记录就是这种情况。ABRiS 是一个 Spark 库,可以根据 Schema Registry 中的模式对Confluent Avro 格式的 Kafka 记录进行反序列化。该解决方案中使用的ABRiS版本为3.2。
from pyspark import SparkContextfrom pyspark.sql.column import Column, _to_java_columnfrom pyspark.sql.functions import col# instantiates a Scala Map containing configurations for communicating with Schema Regsitry APIsdef get_schema_registry_conf_map(spark, schema_registry_url, topic_name):sc = spark.SparkContextjvm_gateway = sc._gateway.jvmschema_registry_config_dict = {"schema.registry.url": schema_registry_url,"schema.registry.topic": topic_name,"value.schema.id": "latest","value.schema.naming.strategy": "topic.name"}conf_map = getattr(getattr(jvm_gateway.scala.collection.immutable.Map, "EmptyMap$"), "MODULE$")for k, v in schema_registry_config_dict.items():conf_map = getattr(conf_map, "$plus")(jvm_gateway.scala.Tuple2(k, v))return conf_map# returns deserialized column (using Schema Registry)def from_avro(col, conf_map):jvm_gateway = SparkContext._active_spark_context._gateway.jvmabris_avro = jvm_gateway.za.co.absa.abris.avroreturn Column(abris_avro.functions.from_confluent_avro(_to_java_column(col), conf_map))TOPIC_NAME = "topic_name"SCHEMA_REGISTRY_URL = "host1:port1,host2:port2"# instantiate Scala Map for communicating with Schema Regsitry APIsconf_map = get_schema_registry_conf_map(spark, SCHEMA_REGISTRY_URL, TOPIC_NAME)# deserialize column containing data (using Schema Registry) and select pertinent columns for processing anddeserialized_df = df.select(col("key").cast("string"),col("partition"),col("offset"),col("timestamp"),col("timestampType"),from_avro(df.value, conf_map).alias("value"))
3. 根据Oracle GoldenGate "op_type"提取所需的前后映像,并将记录以Hudi格式写入数据湖
Spark代码使用GoldenGate记录中的"op_type"字段将传入记录的批次分为两组:一组包含插入/更新,第二组包含删除。这样做是为了可以相应地设置Hudi写操作配置。随后进一步转换之前或之后的映像。最后一步是设置下面提到的适当的Hudi属性,然后以流或批处理方式通过foreachBatch Spark Structured Streaming API将Hudi格式的upserts和deletes写入S3中。
import copy# write to a path using the Hudi formatdef hudi_write(df, schema, table, path, mode, hudi_options):hudi_options = {"hoodie.datasource.write.recordkey.field": "recordkey","hoodie.datasource.write.precombine.field": "precombine_field","hoodie.datasource.write.partitionpath.field": "partitionpath_field","hoodie.datasource.write.operation": "write_operaion","hoodie.datasource.write.table.type": "table_type","hoodie.table.name": TABLE,"hoodie.datasource.write.table.name": TABLE,"hoodie.bloom.index.update.partition.path": True,"hoodie.index.type": "GLOBAL_BLOOM","hoodie.consistency.check.enabled": True,# Set Glue Data Catalog related Hudi configs"hoodie.datasource.hive_sync.enable": True,"hoodie.datasource.hive_sync.use_jdbc": False,"hoodie.datasource.hive_sync.database": SCHEMA,"hoodie.datasource.hive_sync.table": TABLE,}if (hudi_options.get("hoodie.datasource.write.partitionpath.field")and hudi_options.get("hoodie.datasource.write.partitionpath.field") != ""):hudi_options.setdefault("hoodie.datasource.write.keygenerator.class","org.apache.hudi.keygen.ComplexKeyGenerator",)hudi_options.setdefault("hoodie.datasource.hive_sync.partition_extractor_class","org.apache.hudi.hive.MultiPartKeysValueExtractor",)hudi_options.setdefault("hoodie.datasource.hive_sync.partition_fields",hudi_options.get("hoodie.datasource.write.partitionpath.field"),)hudi_options.setdefault("hoodie.datasource.write.hive_style_partitioning", True)else:hudi_options["hoodie.datasource.write.keygenerator.class"] = "org.apache.hudi.keygen.NonpartitionedKeyGenerator"hudi_options.setdefault("hoodie.datasource.hive_sync.partition_extractor_class","org.apache.hudi.hive.NonPartitionedExtractor",)df.write.format("hudi").options(**hudi_options).mode(mode).save(path)# parse the OGG records and write upserts/deletes to S3 by calling the hudi_write functiondef write_to_s3(df, path):# select the pertitent fields from the dfflattened_df = df.select("value.*", "key", "partition", "offset", "timestamp", "timestampType")# filter for only the inserts and updatesdf_w_upserts = flattened_df.filter('op_type in ("I", "U")').select("after.*","key","partition","offset","timestamp","timestampType","op_type","op_ts","current_ts","pos",)# filter for only the deletesdf_w_deletes = flattened_df.filter('op_type in ("D")').select("before.*","key","partition","offset","timestamp","timestampType","op_type","op_ts","current_ts","pos",)# invoke hudi_write function for upsertsif df_w_upserts and df_w_upserts.count() > 0:hudi_write(df=df_w_upserts,schema="schema_name",table="table_name",path=path,mode="append",hudi_options=hudi_options)# invoke hudi_write function for deletesif df_w_deletes and df_w_deletes.count() > 0:hudi_options_copy = copy.deepcopy(hudi_options)hudi_options_copy["hoodie.datasource.write.operation"] = "delete"hudi_options_copy["hoodie.bloom.index.update.partition.path"] = Falsehudi_write(df=df_w_deletes,schema="schema_name",table="table_name",path=path,mode="append",hudi_options=hudi_options_copy)TABLE = "table_name"SCHEMA = "schema_name"CHECKPOINT_LOCATION = "s3://bucket/checkpoint_path/"TARGET_PATH="s3://bucket/target_path/"STREAMING = True# instantiate writeStream objectquery = deserialized_df.writeStream# add attribute to writeStream object for batch writesif not STREAMING:query = query.trigger(once=True)# write to a path using the Hudi formatwrite_to_s3_hudi = query.foreachBatch(lambda batch_df, batch_id: write_to_s3(df=batch_df, path=TARGET_PATH)).start(checkpointLocation=CHECKPOINT_LOCATION)# await termination of the write operationwrite_to_s3_hudi.awaitTermination()
4. 重要的Hudi配置项
hoodie.datasource.write.precombine.field:表的precombine字段是必填配置,并且字段不能为空(即对于记录不存在)。如果数据源不满足此要求,则可能有必要为这些表实现自定义重复数据删除逻辑。
hoodie.datasource.write.keygenerator.class:对于包含复合键或被多个列分区的表,请将此值设置为org.apache.hudi.keygen.ComplexKeyGenerator。对于非分区表,将此值设置为org.apache.hudi.keygen.NonpartitionedKeyGenerator。
hoodie.datasource.hive_sync.partition_extractor_class:将此值设置为org.apache.hudi.hive.MultiPartKeysValueExtractor以创建由多个列组成分区字段的Hive表。将此值设置为org.apache.hudi.hive.NonPartitionedExtractor以创建无分区的Hive表。
hoodie.index.type:默认情况下,它设置为BLOOM,它将仅在单个分区内强制键的唯一性。使用GLOBAL_BLOOM在所有分区上保证唯一性。Hudi会将传入记录与整个数据集中的文件进行比较,以确保recordKey仅出现在单个分区中。非常大的数据集会有延迟。
hoodie.bloom.index.update.partition.path:对于删除操作,请确保将其设置为False(如果使用GLOBAL_BLOOM索引)。
hoodie.datasource.hive_sync.use_jdbc:将此值设置为False可将表同步到Glue Data Catalog(如果需要)。
有关配置的完整列表,请参阅Apache Hudi配置页面[11];有关其他任何查询,请参阅Apache Hudi FAQ页面[12]。
注意(Apache Hudi与AWS Glue一起使用)
Maven[13]上提供的hudi-spark-bundle_2.11-0.5.3.jar不能与AWS Glue一起使用。需要通过更改原始pom.xml来创建自定义jar。
1.下载并更新pom.xml[14]的内容。a)从
<include>org.apache.httpcomponents:httpclient</include>b)将以下行添加到
<relocation><pattern>org.eclipse.jetty.</pattern><shadedPattern>org.apache.hudi.org.eclipse.jetty.</shadedPattern></relocation>
1.构建JAR:
mvn clean package -DskipTests -DskipITs然后可以使用上面的命令(位于"target / hudi-spark-bundle_2.11-0.5.3.jar"目录)构建的JAR作为Glue作业参数传递[15]。
完成上述步骤后即可使用Lakehouse。使用上面提到的Apache Hudi API可用的一种查询方法,可以从Raw S3存储桶中使用数据。
7. 结论
该方案成功解决了传统数据湖所面临的挑战:
•基于日志的CDC是用于捕获数据库事务/事件的更可靠的机制。•Apache Hudi负责(以前由数据平台所有者所有)通过管理大规模Lakehouse所需的索引和相关元数据来更新数据湖库中的目标数据。•ACID事务的支持消除了并发操作的麻烦,因为Apache Hudi API支持并发读写,而不会产生不一致的结果。
随着越来越多的企业采用数据平台并增强其数据分析/机器学习功能,必须为服务于数据的基础CDC工具和管道的重要性不断发展以应对一些最普遍面临的挑战。数据延迟和交付给下游消费者的数据的整体质量的改善表明Data Lakehouse范式是下一代数据平台。这将成为企业从其数据中获得更大价值和洞察力的基础。
我们希望本文为您提供了使用Apache Hudi构建Data Lakehouse的思路。
推荐阅读
Apache Hudi与Apache Flink更好地集成,最新方案了解下?
查询时间降低60%!Apache Hudi数据布局黑科技了解下
引用链接
[1] 如何为工作负载选择存储类型: https://cwiki.apache.org/confluence/display/HUDI/FAQ#FAQ-HowdoIchooseastoragetypeformyworkload[2] Oracle大数据Oracle GoldenGate: https://www.oracle.com/integration/goldengate/big-data/[3] Confluent Kafka: https://docs.confluent.io/5.5.0/index.html[4] Apache Spark(Glue): https://spark.apache.org/docs/2.4.3/structured-streaming-programming-guide.html[5] ABRiS: https://github.com/AbsaOSS/ABRiS/tree/branch-3.2[6] Apache Hudi: https://hudi.apache.org/docs/0.5.3-quick-start-guide.html[7] 补充日志记录: https://docs.oracle.com/en/middleware/goldengate/core/19.1/oracle-db/preparing-database-oracle-goldengate.html#GUID-357BCE43-5951-466E-8EFF-C14D46A252D3[8] 样本更新记录: https://gist.github.com/rnbtechnology/2e3ffafb6f5e21727a27f149abef898c[9] 样本删除记录: https://gist.github.com/rnbtechnology/168a92d3629474b5b1c024bf628f8b45[10] 其他功能: https://docs.confluent.io/platform/current/schema-registry/index.html#ak-serializers-and-deserializers-background[11] Apache Hudi配置页面: https://hudi.apache.org/docs/configurations.html[12] Apache Hudi FAQ页面: https://cwiki.apache.org/confluence/display/HUDI/FAQ[13] Maven: https://mvnrepository.com/artifact/org.apache.hudi/hudi-spark-bundle_2.11/0.5.3[14] pom.xml: https://github.com/apache/hudi/blob/release-0.5.3/packaging/hudi-spark-bundle/pom.xml[15] 参数传递: https://docs.aws.amazon.com/glue/latest/dg/aws-glue-programming-etl-glue-arguments.html