
OpenCV空间人工智能竞赛:第一部分
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
介绍
著名的开源计算机视觉库OpenCV宣布了其将首次举行由英特尔赞助的空间人工智能竞赛。
随着OAK-D(OpenCV-AI-Kit With Depth)模块的发布,OpenCV呼吁参与者使用其模块解决现实世界中的问题。OAK-D模块有内置立体摄像头和RGB摄像头,同时还配备了一个强大的视觉处理单元(来自英特尔的Myriad X),可以进行深度神经网络推断。
我们对这种传感器的潜力感到兴奋,于是决定在7月份提交一份竞赛项目建议书。我们会从我们的235个提案中选出了32个!并在journal上发布一系列的博客文章,分享我们在整个开发过程中的进展、想法和挑战。
我们的工作:使用空间人工智能来检测室内地标(indoor Landmarks),并使用基于图的姿态地标(Graph-Based Pose-Landmark)SLAM
OAK-D不仅能够检测物体,还能够提供物体的相对三维位置,这使得解我们的问题成为了可能。一般来说,姿态图SLAM问题是一个优化问题,它使用多个移动代理的姿态估计值,并通过调整这些估计值来最小化这些估计值之间的误差。这种优化允许我们在其环境中定位代理,同时允许我们缝合机器人的传感器测量值以创建环境的地图表示。
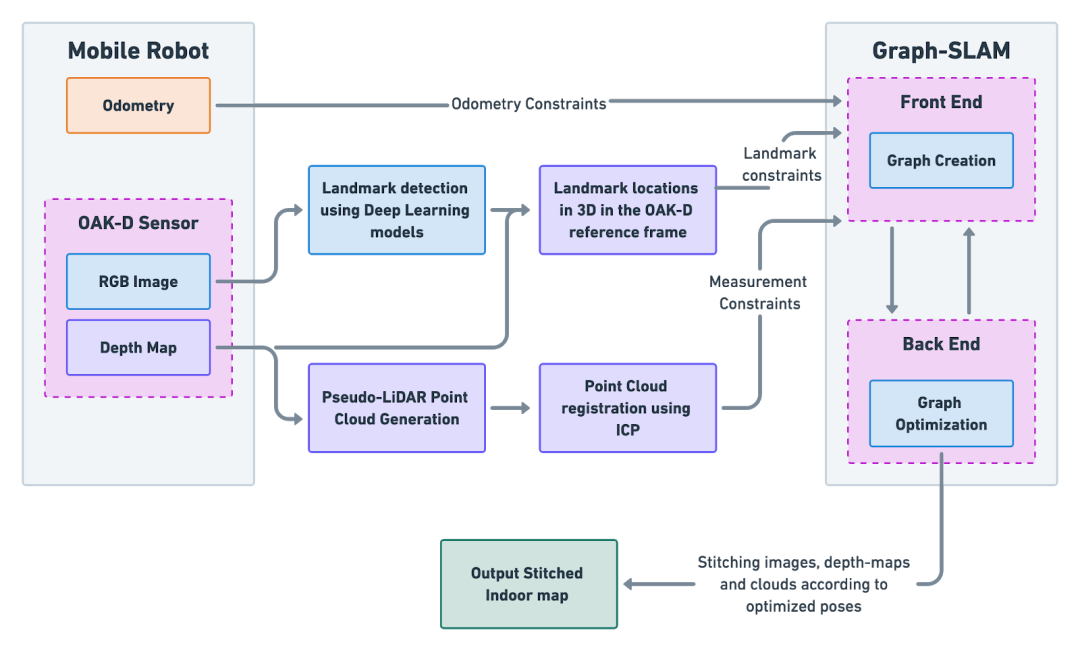
大多数室内SLAM的实现使用以下两种姿态估计来源:
里程计(Wheel odometry)
2D激光雷达
在我们的实践中,首先里程计是我们必备的来源,然后使用OAK-D来代替2D激光雷达。上图显示了我们建议的实现流程图。OAK-D能够唯一地解决这些问题:
1.姿态-姿态(pose-pose)约束的来源:通常,来自2D激光雷达的激光扫描可以通过使用诸如迭代最近点(ICP)等对准算法来估计位姿图中的位姿约束。而另外一种考虑ICP的非正式方式——如果你从两个不同的位置得到两个激光扫描,你需要如何移动和旋转来使这两个激光扫描对齐,这个运动+旋转给了我们一个pose-pose约束的估计。
在使用OAK-D时,我们想使用类似的方法,为此,我们需要利用OAK-D深度图(depth maps)来创建点云 ,然后将它们与ICP对齐,这将给我们更丰富和更准确的pose-pose约束,因为我们可以利用3D信息。
2.姿态-地标(pose-landmark)约束的来源:使用OAK-D的主要好处是,它可以直接在边缘进行3D对象检测,这允许我们使用基于深度学习的对象检测器来检测对象,并将它们作为姿态图优化问题中的地标。
在多次OAK-D测量中观察到的环境中任何静止的物体都可以作为地标,因为它在世界坐标系中的位置是不变的,而代理相对于地标的相对位置是不断进化的。
对同一对象的观察允许我们创建pose-landmark约束,其中地标的位置被认为是固定的。这些地标可以作为整个室内地图的“锚点”。
有了这些源,我们就能够创建一个既包含姿态-姿态约束又包含姿态-地标约束的图形,然后我们将使用优化技术来优化这些姿态的位置。固定好姿态后,我们只需缝合OAK-D观测值(可以是RGB图像、深度图或点云)就能来创建室内地图。
机器人平台设置- Jetson Nano + TurtleBot3 Waffle + OAK-D
接下来我们将提供一些执行细节和我们迄今为止取得的成就。我们首先需要的是一个室内移动机器人,我们可以在上面安装OAK-D。该机器人必须满足以下条件:
它提供一个里程计的来源:虽然我们可以自己添加这个,但由于这不是本项目的主要任务,所以最好使用一个已经有马达和编码器的平台。
支持机器人操作系统(Robot Operating System,ROS):我们的目标是使用ROS作为本项目的主干,因此必须有一个支持ROS的机器人。
它应该能够为OAK-D和单板计算机(SBC)供电。
为了满足这些要求,我们修改了TurtleBot3 Waffle(http://www.robotis.us/turtlebot-3-waffle-pi/)。我们选择它的原因很简单——这基本就是我们需要的!以下是它提供的功能和我们需要修改的东西:
TB3有里程计:TB3配备了 DynamicXel马达,内置编码器提供里程表。
TB3配备了OpenCR嵌入式平台,可以为我们选择的SBC(NVIDIA Jetson Nano)以及OAK-D提供足够的功率。
默认情况下,TB3带有树莓派3B+,但是,我们希望使用Jetson Nano作为SBC,这是因为我们希望有更高的性能余量来解决这个问题。
我们移除了TB3附带的2D激光扫描仪。
我们将在TB3平台上安装OAK-D。
下图显示了改进后的机器人平台,该平台已经安装并配置为与TB3一起运行。我们还没有安装和外部校准OAK-D。


用Jetson Nano作为TurtleBot3的单板机
如前所述,TurtleBot3默认附带一个树莓派3b+,而且设置Jetson Nano作为TB3的SBC不是很难。为了让Jetson Nano和OpenCR板通过ROS进行通信,需要执行以下步骤。
在OpenCR板上安装/更新固件
1.OpenCR嵌入式平台板负责为DYNAMIXEL电机供电并与之通信,这意味着它从马达读取编码器读数并生成里程表信息,同时接收速度指令并将其发送给这些马达,这两个过程对这个项目都至关重要。我们按照这里提供的说明更新OpenCR板的固件。
在Jetson Nano上安装TurtleBot ROS
1.由于这款Jetson Nano已经用于其他机器人项目,我们已经在上面安装了ROS Melodic。
但是为了让它与OpenCR板一起工作,我们需要把这个板设置成TurtleBot3的大脑,为此,我们在Jetson Nano的新ROS工作区中设置了tb3 ROS,这可以简单地通过sudo apt install ros-melodic-turtlebot3来实现。现在,我们可以通过micro-USB将Jetson Nano连接到OpenCR板了。
2.使用roslaunch turtlebot3_bringup turtlebot3_robot.launch启动TB3机器人。现在我们已经准备好接收里程表,并从Jetson Nano向TB3发送速度指令。
接收里程表并发送速度指令
1.我们可以启动远程操作节点来控制马达并查看里程表的更新,这可以使用roslaunch turtlebot3_teleop turtlebot3_teleop_key.launch来启动
2.为了查看流式里程表的数值,我们使用了rostopic echo /odom。里程计信息示例如下所示:
---
header:
seq: 987
stamp:
secs: 1597031283
nsecs: 652199083
frame_id: "odom"
child_frame_id: "base_footprint"
pose:
pose:
position:
x: -0.147986590862
y: -0.0244562737644
z: 0.0
orientation:
x: 0.0
y: 0.0
z: 0.179800972342
w: 0.983703017235
covariance: [0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0]
twist:
twist:
linear:
x: -0.11722844094
y: 0.0
z: 0.0
angular:
x: 0.0
y: 0.0
z: 0.217905953526
covariance: [0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0]
---
这样,SBC和TB3的设置就完成了。下一步是将OAK-D添加到这个设置中,这将在以后的文章中讨论。
从OAK-D获取深度图
OAK-D模块由三个摄像头组成:两个单色全局快门式摄像头,用于提供深度感知,以及一个RGB摄像头。OAK-D提供了两种不同的方法来估计深度。
第一种方法使用半全局匹配(SGBM)算法计算深度图,使用左右摄像机以及在摄像机(左、右或RGB)上运行神经推理来执行目标检测,然后使用深度图在摄影机的参照系中定位检测到的对象。
第二种方法在左右两个摄像头上并行运行神经网络推理,来估计两幅图像之间的差异。检测到特征之后利用相机的内在特性计算它们的三维位置。在这个项目中,我们将利用第一种方法,因为它同时为我们提供了一个密集的深度图(用于创建点云)和三维物体检测(在SLAM问题中用作地标)。

图3:OAK-D模块带有两个用于深度的黑白相机,中间有一个RGB相机。

图4:OAK-D相机的样本深度图。如图所示,它可以检测对象(这里是一个人),还可以报告它们在相机坐标系中的三维位置
在我们开始流式传输来自OAK-D的深度图之前,我们首先需要获得内在的摄像机校准矩阵,这对于将深度图转换为点云至关重要(如下一节所述)。我们能够通过遵循官方depthaiapi for OAK-D的立体声校准教程获得OAK-D的固有参数。
DepthAI API支持Python 3和C++,可以用于从OAK-D中流数据。由于我们的ROS版本(MyDoice)不支持Python 3,所以我们决定使用C++ API。
我们遵循这里提供的示例(https://github.com/luxonis/depthai-core/tree/develop/example),经过一些尝试和错误之后,在DepthAI开发人员的帮助下,我们构建一个能够从OAK-D传输深度图的程序。这些深度图将通过ROS发布,以供下游节点使用。在接下来的几周里,我们将致力于提高这些深度图的质量。
将深度图转换为点云
使用OAK-D的好处之一是它能够生成原始深度图。深度图的每个像素都包含估计深度信息。通常,当我们知道摄像机的固有校准矩阵(我们称之为K)之后,我们可以将场景中的3D点投影到2D图像平面上,这个过程称为透视投影。
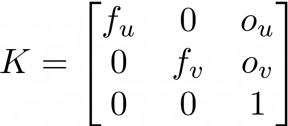
3x3固有校准矩阵由4个不同的参数组成。
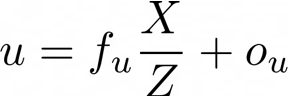
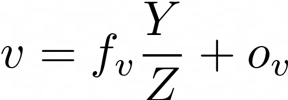
上面的方程告诉我们,如果我们知道像素的固有校准矩阵和深度,或者Z坐标,我们也可以将坐标(u,v)的2D像素反投影到3D空间中。求解X和Y,我们得到以下方程:
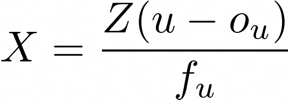
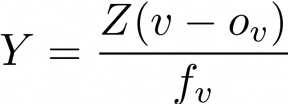
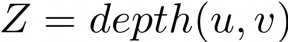
为了构造由N个点组成的点云(其中N等于2D深度图中的像素数),你可以简单地访问深度图中的每个像素并计算该点的(X,Y,Z)逆投影,但是使用双重循环访问每个像素可能会非常消耗资源的,因此我们可以使用线性代数以更具计算优化的方式来解决这一问题。
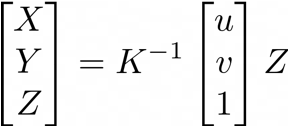
利用上面的方程,我们只需要找到内部校准矩阵的逆,然后进行矩阵乘法。根据上面的方程,我们可以导出K⁻¹内部的元素。
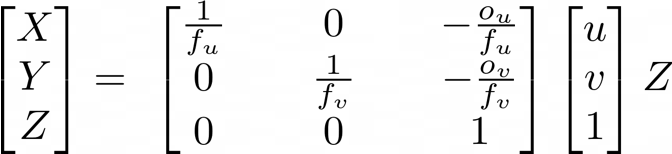

这个过程使我们能够将来自OAK-D的深度图转换成点云。上图显示了使用此过程生成的示例点云,这个点云没有进行二次采样或清理,也没有从原始深度图生成,这就是为什么质量不高的原因,这将在将来得到改进。
我们使用迭代最近点(ICP)算法进行点云注册过程将在以后的博客文章中讨论。
团队成员
Deepak Talwar目前是圣何塞州立大学计算机工程专业最后一年的硕士研究生,专注于机器人技术和人工智能。他曾在FarmWise实验室实习,目前在DeepMap公司实习。 Seung Won Lee最近从圣何塞州立大学获得计算机工程硕士学位,在那里他完成了各种与计算机视觉相关的项目,特别是在自动驾驶方面。他的硕士论文“Enhancing Point Cloud Density using Stereo Images”采用了规则点云和伪激光雷达点云相结合的方法来提高三维目标的检测能力。 Sachin Guruswamy最近从圣何塞州立大学获得了计算机工程硕士学位,主攻机器人技术和计算机视觉,他目前在Depth.ai产品上工作。
参考链接:https://medium.com/the-inverse-project/opencv-spatial-ai-competition-progress-journal-part-i-ef1ad85016a1