
我的音视频技术路线
共 16305字,需浏览 33分钟
·
2022-02-09 17:34
目录


抖音/快手等短视频APP的风靡,让音视频成为当下最火热的技术,越来越多的人想要进入到这个领域,我自己也是从图形方向刚刚踏入这领域不久,音视频方向所包含的技术栈非常复杂,我自己也在一点一点慢慢钻研,这里面每一个方向都值得深入研究,而且随着5G时代的到来,音视频方向的应用会更加广泛,所以希望自己能掌握更多的关于音视频方向的技能,未来可以探索更多的音视频玩法。然后这篇博客主要是想梳理一下我自己关于音视频这个方向的学习路线,分享出来的同时也能鼓励自己朝着这个方向继续深耕下去。
关于音视频方向的基础技能分支,先来看一张图(图片来自网上)

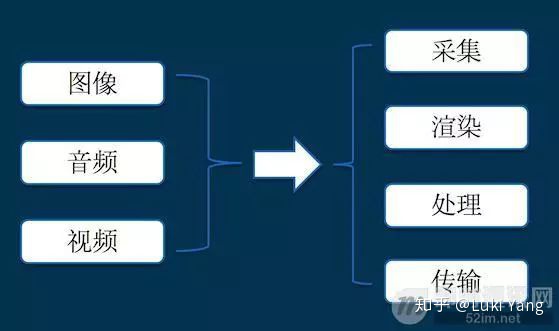
采集:音视频数据来源,比如Android Camera数据采集
渲染:将采集得到的数据展示到Surface上,并添加一些图形效果
处理:对源数据的加工,比如添加滤镜、特效,还有多视频剪辑、变速、转场等等
编解码:对音视频数据进行压缩封装,减少数据量,方便传输
传输:对采集加工完成的数据传输至客户端,比如直播推流、拉流
1. 关于音视频数据采集(Android)
因为自己主要是对Android Camera比较熟悉,所以我主要梳理一下这方面的知识点,我会从最基础的Android Camera API的接口以及基本流程开始梳理,后面进阶部分主要是结合Camera HAL高通架构进一步详细梳理底层的Camera原理,最后是我对于Camera专业视频方向的一些探索。
1.1 Android Camera API
Android 5.0之后Camera接口升级成API2,因为Camera API 1接口过于简单,根本体现不出硬件能力,用户能控制的不多,比如拿不到RAW数据,控制不了相机参数的下发等等,如下代码看下他内部的基本接口
Camera API 1
try {
mCamera = Camera.open(mCurrentCamera);
Camera.Parameters params = mCamera.getParameters();
List<Camera.Size> previewSizes = params.getSupportedPreviewSizes();
Camera.Size preViewSize = previewSizes.get(previewSizes.size() > 4 ? previewSizes.size() - 4 : 0);
params.setPreviewSize(preViewSize.width, preViewSize.height);
mPreviewHeight = preViewSize.height;
mPreviewWidth = preViewSize.width;
Log.e(TAG, "preViewSize->width: " + preViewSize.width + ", preViewSize->height: " + preViewSize.height);
params.setPictureFormat(ImageFormat.JPEG);
params.setJpegQuality(100);
//是否开启闪光
List<String> flashModes = params.getSupportedFlashModes();
if (flashModes != null && flashModes.contains(Camera.Parameters.FLASH_MODE_OFF)) {
params.setFlashMode(Camera.Parameters.FLASH_MODE_OFF);
}
mCamera.setPreviewCallback(this);
mCamera.setDisplayOrientation(PORTRAIT_MODE);
mCamera.setParameters(params);
if(!Consts.SHOW_CAMERA) {
LogUtils.log_main_step("相机开始preview");
mCamera.startPreview();
}
LogUtils.logd(TAG, "camera init finish.....");
} catch (Exception e) {
LogUtils.loge(TAG, e.getMessage());
e.printStackTrace();
}然后在CameraPreview callback里面就可以处理相机数据了
@Override
public void onPreviewFrame(byte[] data, Camera camera) {
Camera.CameraInfo mCameraInfo = new Camera.CameraInfo();
//如果使用前置摄像头,请注意显示的图像与帧图像左右对称,需处理坐标
boolean frontCamera = (mCurrentCamera == Camera.CameraInfo.CAMERA_FACING_FRONT);
//获取重力传感器返回的方向
int dir = getDirection();
int rotate = (dir ^ 1);
//Log.e("stRotateCamera ", (dir ^ 1) + " rotate result");
//在使用后置摄像头,且传感器方向为0或2时,后置摄像头与前置orentation相反
if (!frontCamera && dir == 0) {
dir = 2;
} else if (!frontCamera && dir == 2) {
dir = 0;
}
dir = (dir ^ 2);
//.....
process(data)
}Camera 2.0: New computing platforms for computational photography
Camera API2对比API 1改动非常大,主要配合HAL3进行使用,功能和接口都更加齐全,同时使用起来也会更加复杂,但如果熟悉之后,也能拍摄出更加丰富的效果。下图关于Camera API 2的几个使用场景


然后结合具体代码讲几个Camera2的主要接口
- CameraManager
关于硬件能力的统一封装接口
CameraManager cameraManager = (CameraManager)mContext.getSystemService(Context.CAMERA_SERVICE);
//可以拿到所以的相机列表,比如Wide,Tele,Macro,Tele2x,Tele4x等等
String[] cameraIdList = cameraManager.getCameraIdList();
//根据Camera ID拿到对应设备支持的能力
CameraCharacteristics cameraCharacteristics =
cameraManager.getCameraCharacteristics(cameraIdStr);
//比如用这个去判断支持的最小Focus distance
Float focusDistance = mCharacteristics.get(CameraCharacteristics.LENS_INFO_MINIMUM_FOCUS_DISTANCE); 现如今机型的摄像头的数量越来越多,组合也越来越丰富,不同的Camera负责不同的能力,比如我们需要更大的拍摄范围会选择Ultra Wide,比如小米一亿像素的Wide,还有Macro等等
2. CaptureDevice
我们可以在OpenCamera Callback拿到CameraDevice
String cameraIdStr = String.valueOf(mCameraId);
cameraManager.openCamera(cameraIdStr, mCameraStateCallback, mMainHandler);
//
private CameraDevice.StateCallback mCameraStateCallback = new CameraDevice.StateCallback() {
@Override
public void onOpened(@NonNull CameraDevice camera) {
synchronized (SnapCamera.this) {
mCameraDevice = camera;
}
if (mStatusListener != null) {
mStatusListener.onCameraOpened();
}
}
@Override
public void onDisconnected(@NonNull CameraDevice camera) {
Log.w(TAG, "onDisconnected");
// fail-safe: make sure resources get released
release();
}
@Override
public void onError(@NonNull CameraDevice camera, int error) {
Log.e(TAG, "onError: " + error);
// fail-safe: make sure resources get released
release();
}
}; 3. CaptureRequest
通过CameraDevice可以创建CaptureRequest,类型主要有以下几种,1-6分布用于预览、拍照、录制、录制中拍照、ZSL、手动。
public static final int TEMPLATE_MANUAL = 6;
public static final int TEMPLATE_PREVIEW = 1;
public static final int TEMPLATE_RECORD = 3;
public static final int TEMPLATE_STILL_CAPTURE = 2;
public static final int TEMPLATE_VIDEO_SNAPSHOT = 4;
public static final int TEMPLATE_ZERO_SHUTTER_LAG = 5;
//创建的代码
mPreviewRequestBuilder = mCameraDevice.createCaptureRequest(CameraDevice.TEMPLATE_PREVIEW);
//这里是更加专业一点的用法,可以不看,就是拿到RequestBuilder之后我们可以去下发各种TAG,如下设置AE/AWB锁
CaptureRequestBuilder.applyAELock(request, mConfigs.isAELocked());
CaptureRequestBuilder.applyAWBLock(request, mConfigs.isAWBLocked());4. Surface
Surface主要是用来接相机返回的数据,可以支持不同的数据类型和分辨率
//SurfaceTexture的方式,用于预览
mSurfaceTexture = new SurfaceTexture(false);
mSurfaceTexture.setDefaultBufferSize(optimalSize.width, optimalSize.height);
mPreviewSurface = new Surface(mSurfaceTexture);
//ImageReader 的方式, Format可以是YUV、RAW,DEPTH等
mPhotoImageReader = ImageReader.newInstance(size.getWidth(), size.getHeight(),
ImageFormat.JPEG, /* maxImages */ 2);
mPhotoImageReader.setOnImageAvailableListener(mPhotoAvailableListener, mCameraHandler);
//创建session
List<Surface> surfaces = Arrays.asList(mPreviewSurface, mPhotoImageReader.getSurface());
mCameraDevice.createCaptureSession(surfaces, mSessionCallback, mCameraHandler);5. CaptureSession
通过上面的CameraDevice创建Session,在Callback里面拿到Session
mCameraDevice.createCaptureSession(surfaces, mSessionCallback, mCameraHandler);
private CameraCaptureSession.StateCallback
mSessionCallback = new CameraCaptureSession.StateCallback() {
@Override
public void onConfigured(@NonNull CameraCaptureSession session) {
synchronized (SnapCamera.this) {
if (mCameraDevice == null) {
Log.e(TAG, "onConfigured: CameraDevice was already closed.");
session.close();
return;
}
mCaptureSession = session;
}
startPreview();
capture();
}
@Override
public void onConfigureFailed(@NonNull CameraCaptureSession session) {
Log.e(TAG, "sessionCb: onConfigureFailed");
}
}; 后面所有的采集工作都是基于Session,关于Session机制最早是诺基亚提出来的,后面苹果的IOS也采取Session作为相机拍照,录制的会话单元。
/*发起请求,后续相机开始往surface输出数据,这个可以在onConfigured里面调用,如上面的代码 startPreview();
capture();*/
mCaptureSession.setRepeatingRequest(mPreviewRequestBuilder.build(),
mCaptureCallback, mCameraHandler);
mCaptureSession.capture(requestBuilder.build(), mCaptureCallback, mCameraHandler);
// 这个是针对120/240/960Fps recording
mCaptureSession.setRepeatingBurst(requestList, mCaptureCallback, mCameraHandler);
mCaptureSession.captureBurst(requestList, listener, handler);然后还可以通过Session控制结束动作
mCaptureSession.abortCaptures();
mCaptureSession.stopRepeating(); 对象更加专业一点的系统相机而言,在setRepeatingRequest之前可以还需要做很多工作,比如拍照要等Focus finish,还需要Apply一些列参数,比如FocusMode, Zoom, AE/F Lock, Video FPS.....
总结:上面只是一个大概流程,至于每个流程你需要去控制什么可能就会更加复杂,但其实对于第三方APP,需要控制的不多,基本就是OpenCamera -> 配置Surface -> 创建Session -> 设置参数 -> RepeatingRequest ->ImageReader或者GLSurafce回调接数据做后续处理。可能有些更加专业一点的相机应用,可能会涉及的一些专业参数的下发,比如IOS, FocusDistance, Shutter Time, EV....
1.2 Camera HAL
Android Camera硬件抽象层(HAL,Hardware Abstraction Layer)主要用于把底层camera drive与硬件和位于android.hardware中的framework APIs连接起来。Camera子系统主要包含了camera pipeline components 的各种实现,而camera HAL提供了这些组件的使用接口
官网的系统架构图:

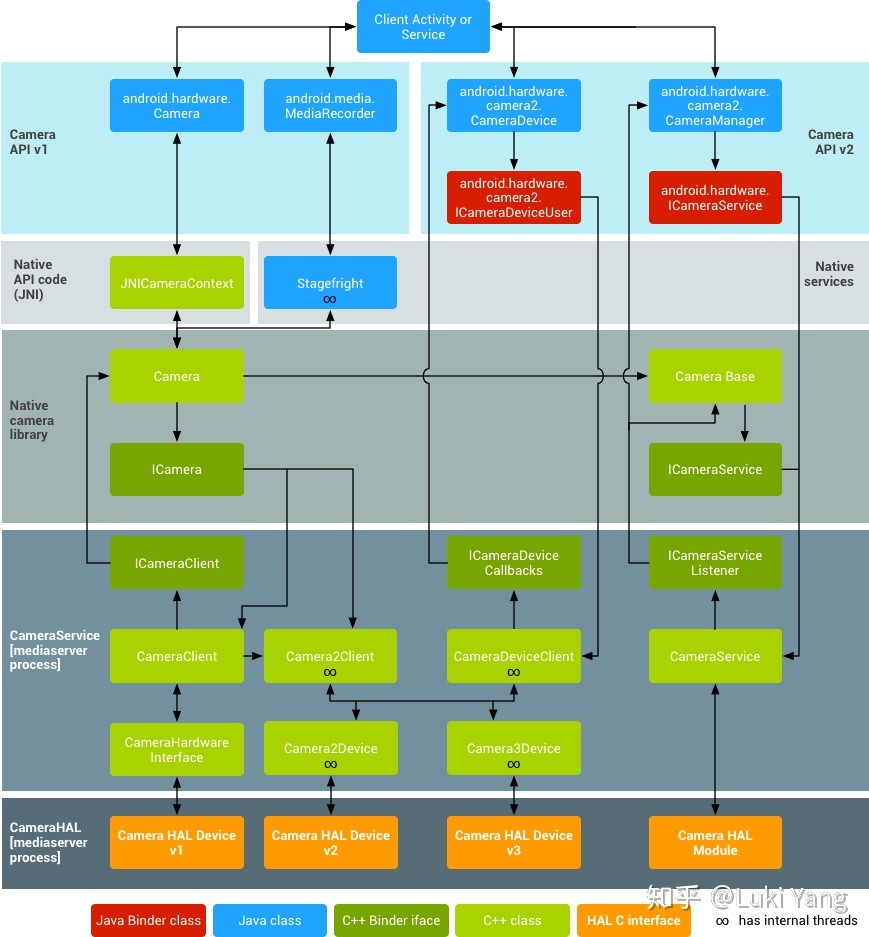
做相机开发除了第一部分讲到的APP层面的相机控制,然后就是HAL层的开发了,HAL层由芯片厂商定制(比如高通等),手机厂商可以再其上增加一些内容。Camera HAL 经历1-3的版本迭代,不同的硬件支持的Camera2程度不一样,主要有以下等级
//每一个等级啥意思自己搜吧
INFO_SUPPORTED_HARDWARE_LEVEL_LEGACY
INFO_SUPPORTED_HARDWARE_LEVEL_LIMITED
INFO_SUPPORTED_HARDWARE_LEVEL_FULL
INFO_SUPPORTED_HARDWARE_LEVEL_3
INFO_SUPPORTED_HARDWARE_LEVEL_EXTERNAL想了一下这一块比较复杂,我自己也不是非常的清楚,而且好像第三方APP一般不会涉及,后面有机会单独整理吧(挖坑1)
1.3 CameraX
如上看到的Camera API2非常复杂,为了简化流程,Google推出CameraX,借助 CameraX,开发者只需两行代码就能利用与预安装的相机应用相同的相机体验和功能。 CameraX Extensions 是可选插件,通过该插件,您可以在支持的设备上向自己的应用中添加人像、HDR、夜间模式和美颜等效果。如下预览和拍照的代码:
//预览
PreviewConfig config = new PreviewConfig.Builder().build();
Preview preview = new Preview(config);
preview.setOnPreviewOutputUpdateListener(
new Preview.OnPreviewOutputUpdateListener() {
@Override
public void onUpdated(Preview.PreviewOutput previewOutput) {
// Your code here. For example, use previewOutput.getSurfaceTexture()
// and post to a GL renderer.
};
});
CameraX.bindToLifecycle((LifecycleOwner) this, preview);
//拍照
ImageCaptureConfig config =
new ImageCaptureConfig.Builder()
.setTargetRotation(getWindowManager().getDefaultDisplay().getRotation())
.build();
ImagesCapture imageCapture = new ImageCapture(config);
CameraX.bindToLifecycle((LifecycleOwner) this, imageCapture, imageAnalysis, preview);
ImageCapture.Metadata metadata = new ImageCapture.Metadata();
metadata.isReversedHorizontal = mCameraLensFacing == LensFacing.FRONT;
imageCapture .takePicture(saveLocation, metadata, executor, OnImageSavedListener);1.4 Camera专业视频(进阶)
现如今手机相机功能越来越强大,现在已经基本可以取代卡片机,手机相机已经作为手机厂商最重要的一个卖点,尤其是DXO刷榜的行为,之后让厂商投入更多的研发相机上面,在可以预见的未来,手机相机发展势必会更加激进,后面进一步取代部分单反也是有可能的,所以相机未来应该更多的体现起作为生产力工具的一部分,尤其是现在视频作为人们记录生活的方式,越来越得到普及。
如果说到视频和相机,我的想法是如何去拍摄更加专业的视频,借助手机相机强大的功能,能否让一部分专业人士用他作为生产力工具,部分取代非常不便携的单反设备,比如借助Camera2参数调节功能去实现长曝光、延时、流光快门等效果。
相机更加专业的方向,主要体现手机厂商的系统相机,尤其是Android端,很多硬件能力只能由手机厂商自己控制,比如系统相机里面的专业模式,还有就是类似大疆这种,也是自己做相机硬件,然后能够结合硬件能力,去实现一些更加专业的拍摄效果。目前软件这块做的比较专业的就是Fimic Pro。

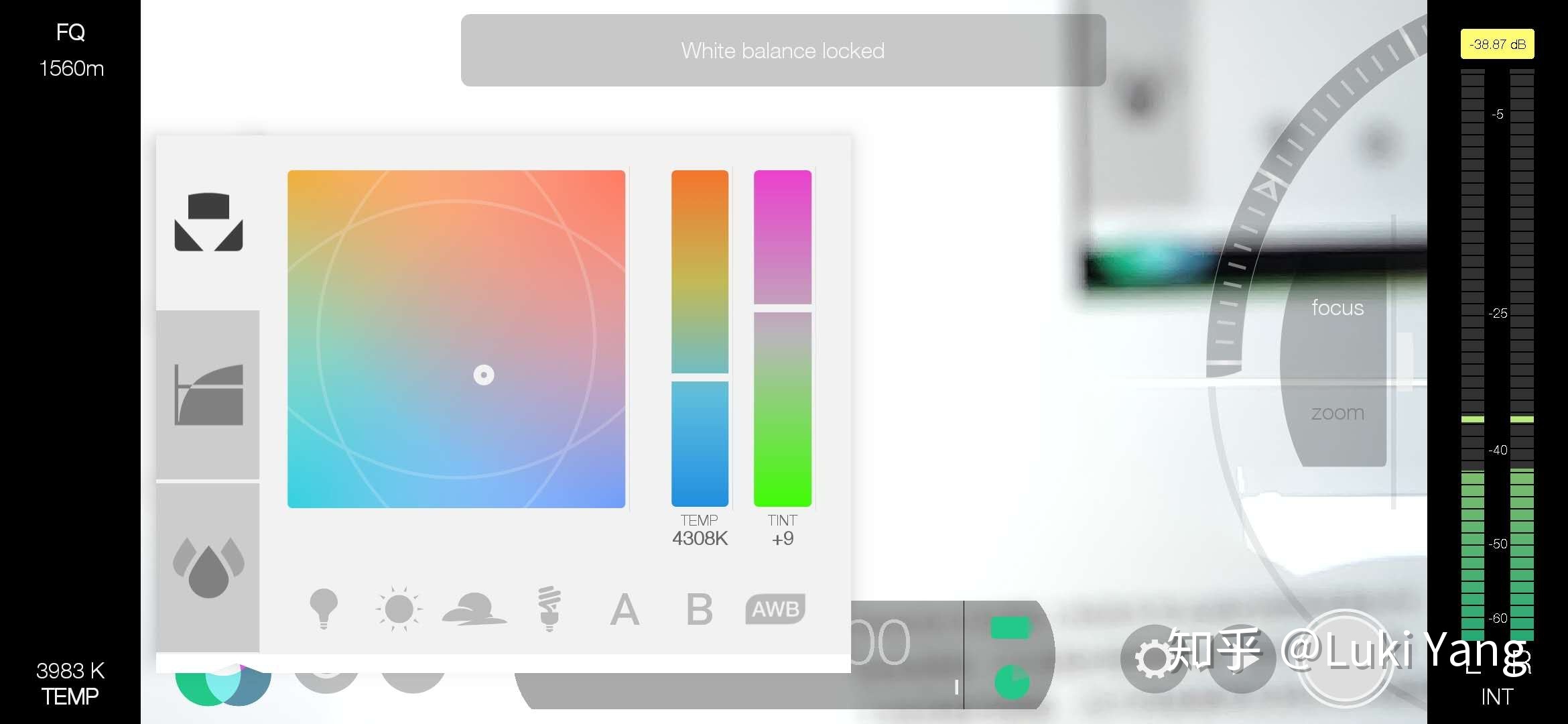
支持各种调参:ISO ,Exposure time,WB,EV,Focus distance
支持平滑变焦,光焦分离
支持曲线调整:亮度、饱和度、阴影、Gamma曲线等
支持LOG格式,还有专业的音频采集
有非常多的辅助信息,比如峰值对焦、曝光反馈、RGB直方图信息等
音视频各种格式自定义:画幅比例、FPS、分辨率、音频采样率、编码格式等等
真的是一个非常强大的生产力工具
2. 关于图形渲染
音视频第二部分肯定是图形渲染方向啦,因为之前一直有做图形渲染方面的工作,也写过自己的渲染引擎,链接如下
https://github.com/LukiYLS/SimpleRenderer
以及关于这个引擎的介绍
所以可以大概分享一下自己的学习过程,以及关于Android GLES相关总结
2.1 图形学基础
我觉图形方面基础的应该需要掌握如下:
- 整个图形矩阵变换过程
World Matrix:将场景中所有对象统一到一个坐标系下
ViewMatrix:World Matrix 变换的相机坐标系,根据相机的三个参数生成
ProjectionMatrix:3D世界投影的2D平面
NDC:转换到[-1 1]
Screen Matrix:转换的屏幕坐标系
这部分想要理解就要自己用笔手推一遍,非常管用
2. OpenGL API
熟悉API,比如纹理贴图方式,绘制点线面,VAO/VBO创建等等
3. 光照
首先需要理解传统的Phong光照,然后要看PBR,理解BRDF模型和公式推导
还有就是Shadow这快,理解shadowmap的原理,不同的光照怎样生成深度图,然后shadow acne,处理边缘锯齿等很多细节,还有阴影体这块
4. 模版测试/深度测试/Alpha混合
深度测试实现遮挡
模版测试也是非常有用,比如我有篇博客里面讲到的 阴影体结合模版测试实现矢量紧贴地形的效果
5. 地形
怎用利用perlin noise生成地形顶点数据
LOD的地形:规则四叉树划分(Google Earth地形),以及不规则的CLOD(自适应三角网)
6. 粒子系统
主要就是怎么控制粒子发射器,粒子加速的,粒子运动轨迹等等
7. 场景管理
如何利用四叉树、八叉树管理场景节点,做视锥体裁剪
........
之前写的渲染引擎,都包含这些基本模块,大概持续完善了半年左右,对我图形渲染方面的提升非常大,包括自己也写过软光栅器

总结:
学习图形学最好的方式就是造轮子造轮子造轮子,自己写引擎,自己写软光栅器
学习资料分享:
https://learnopengl-cn.github.io/
https://www.scratchapixel.com/
阅读源码:OGRE/OSG/THREEJS
工具: unity3d processing
2.2 OpenGL/GLES
- EGL环境创建
eglGetDisplay //获取display信息
eglChooseConfig //设置RGBA bit depth
eglCreatePbufferSurface // 创建离屏surface, 也可以eglCreateWindowSurface
eglCreateContext //创建上下文
2. GL多线程
shareContext 方式
这个网上也有很多资料,eglCreateContext 的时候传入其它线程的Context,既可以共享一些GPU Buffer,比如:MediaCodec录制的用的Surface,和预览去sharedContext
- Render pass如何做同步glFenceSync
如果用glFinish可能会在某个点等的时间很长,可以用glFenceSync做同步,非常不错
3. 渲染优化
帧率如何优化,涉及到很多方面,这方面游戏引擎有很多技巧,比如提前视锥体裁剪,遮挡剔除等等,我这里只是简单讲一下在不涉及到大场景的优化有哪些
个人关于效率优化的总结:
尽量在渲染之前先做视锥体裁剪工作,减少不必要的IO
尽量少使用一些同步阻塞操作,比如glReadPixel、glFinish、glTeximage2D等
Shader里面少使用if/for这种操作
必要时做下采样
利用好内存对齐,会有意想不到的效率提升
渲染之前做好一些列准备工作,比如编译Shader
2.3 音视频渲染引擎(扒抖音)
现在短视频应用关于特效部分底层都有会有一套渲染引擎,不管的抖音还是快手,你把抖音的的APP package pull出来就能看到,里面是同lua脚本去调用底层的渲染引擎,lua脚本负责下发一些参数,主要是AI的一些识别结果以及用户的交互事件。
虽然没有游戏引擎那么强大,但基本模块应该都会包含模型、资源管理、相机控制、裁剪、渲染等等,毕竟写这套引擎的基本都是以前搞游戏的那拨人,算是降维来写音视频渲染引擎。
下面通过拆解抖音内部的资源文件,探究内部关于音视频渲染引擎的模块组成,对比短视频引擎和游戏引擎的区别。
一起来看看抖音最近很火的一个游戏:潜水艇,通过移动鼻子控制潜水艇

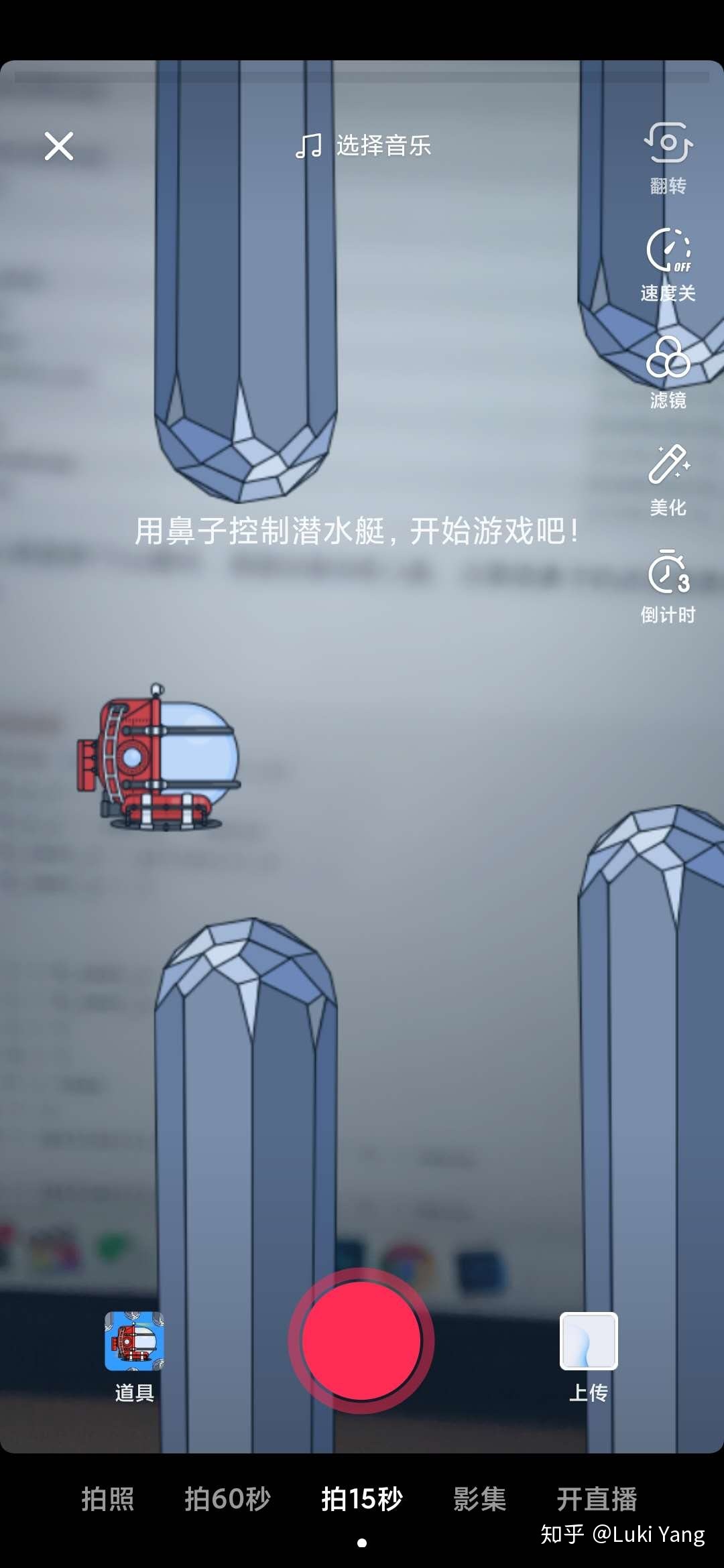
如下是download 的资源包

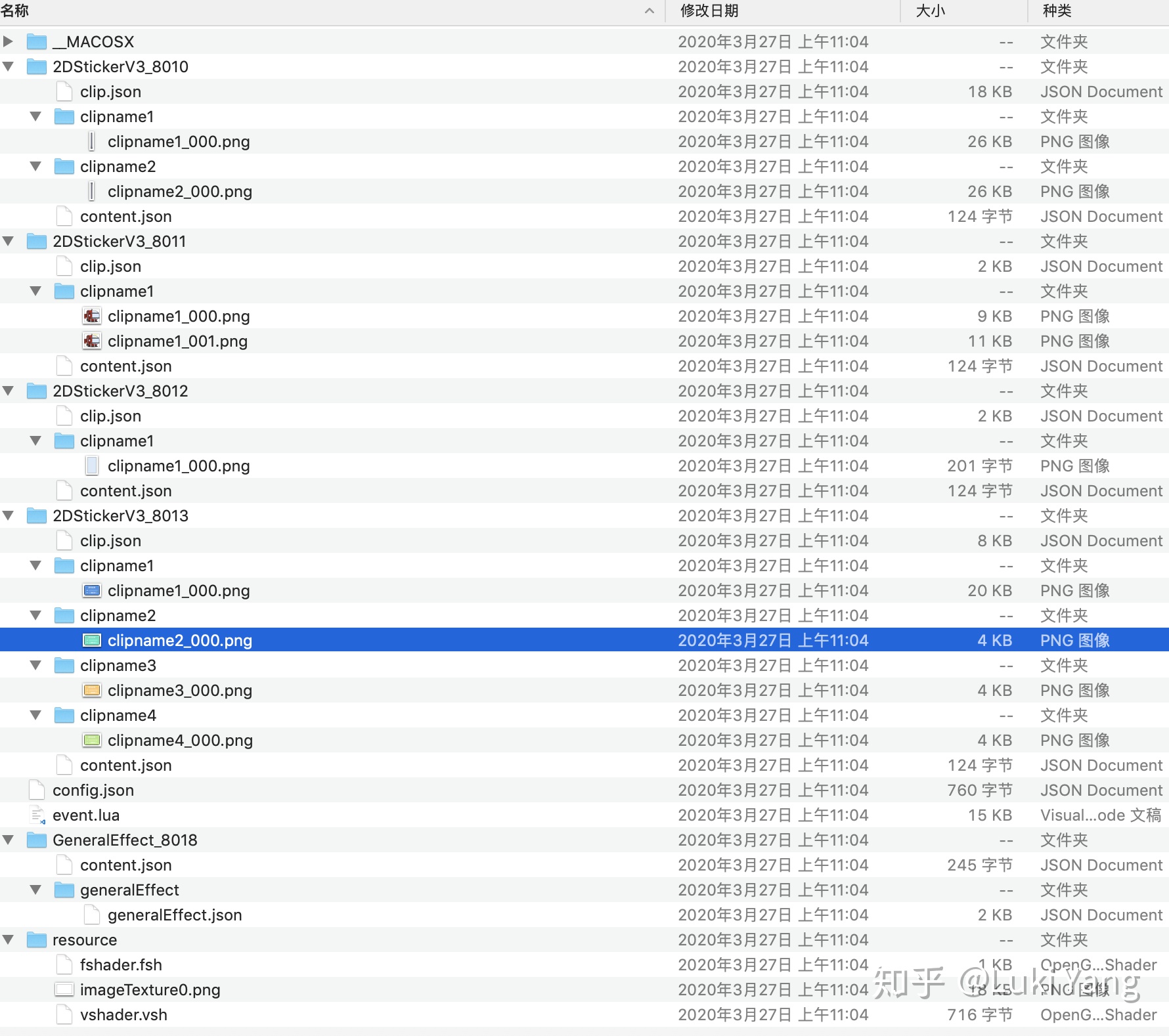
这里面的核心控制逻辑就是那个lua基本,里面会负责把人脸关键点信息传给底层引擎,实时更新潜水艇的位置,脚本实现了两个碰撞检测函数,用于潜水艇和柱子之间做碰撞检测。Collision玩过游戏引擎的都很熟悉,有些游戏引擎Collision detect做的不好的会出现穿模的现象。
rectCollision: 潜水艇中心坐标和柱子底部坐标之间的距离,与潜水艇半径比较,小于0.9*R,就是碰撞了
circleCollision: 两个圆心坐标之间的距离和他们各自半径之和比较,小于半径和,就是碰撞了
local intpx = 220 --柱子左右间隔
local intpy = 550 --柱子中间缝隙宽度
local range_y = {0.3, 0.7} --柱子缝隙中央随机范围,{0.3,0.7}代表缝隙可能在屏幕高度30%-70%的位置随机出现
local sp = {0.5,1.0} --速度初始和最终速度,{0.5,1.0}代表初始速度为1秒走过0.5个屏幕,最终速度为1秒走过1个屏幕
local ptime = 3 --准备时间3s
local range_s = {5,10} --分数分段,{5,10}代表0-5第一段,6-10第二段,10以上第三段;10以上未碰撞第四段
local smul = 0.8 --字号倍率
//.....此次省略N行
//两个碰撞检测函数
//u=1,2 代码上面和下面柱子
local function rectCollision(i,u)
local K_s_x = sub.x
local K_s_y = sub.y * ratio
local K_rect_x = pillar[i].x
local K_rect_y = 0
local l = K_rect_x - r
local r = K_rect_x + r
local t = 0
local b = 0
if u == 1 then
t = -1
b = (pillar[i].y - interval_y / 2) * ratio
else
t = (pillar[i].y + interval_y / 2) * ratio
b = 2
end
local closestP_x = 0.0
local closestP_y = 0.0
closestP_x = clamp(K_s_x, l , r)
closestP_y = clamp(K_s_y, t , b)
local dist = distance(closestP_x, closestP_y, K_s_x, K_s_y)
if dist <= sub.r * 0.9 then
return true
else
return false
end
return false
end
local function circleCollision(i,u)
local K_s_x = sub.x
local K_s_y = sub.y * ratio
local K_cir_x = pillar[i].x
local K_cir_y = 0
if u == 1 then
K_cir_y = (pillar[i].y - interval_y / 2) * ratio
else
K_cir_y = (pillar[i].y + interval_y / 2) * ratio
end
local dist = distance(K_cir_x, K_cir_y, K_s_x, K_s_y)
if dist <= sub.r * 0.9 + r then
return true
else
return false
end
return false
end
还有两个重要的函数,分别处理预览和录制,游戏过程的逻辑,比如柱子随着时间线一直在移动,speed在加快
handleTimerEvent = function(this, timerId, milliSeconds)
if timerId == timer_ID_Fast and gaming then
if init_state ~= 0 then
return true
end
timeThis = getTime(this)
timeDelta = getDiffTime(timeLast, timeThis)
timeCumu = timeCumu + timeDelta
timeLast = timeThis
local speed = sp[1] + clamp(timeCumu / 14, 0,1) * (sp[2] - sp[1])
if timeCumu > 14 then
gaming = false
Sticker2DV3.playClip(this, feature_0.folder, feature_0.entity[1], feature_0.clip[1], 0)
CommonFunc.setFeatureEnabled(this, feature_t.folder, true)
if score >= 10 then
realTimeFunc.initRealTime(this, feature_t.folder, true, feature_t.realTimeParams[1])
else
realTimeFunc.initRealTime(this, feature_t.folder, true, feature_t.realTimeParams[2])
end
realTimeFunc.setRealTime(this, feature_t.folder, "u_data", score)
end
for i = 1,5 do
pillar[i].x = pillar[i].x - speed * timeDelta
if pillar[i].x < -r then
pillar[i].x = pillar[i].x + interval_x * 5
pillar[i].y = range_y[1] + math.random() * (range_y[2] - range_y[1])
pillar[i].counted = false
end
if pillar[i].x < sub.x and not pillar[i].counted then
pillar[i].counted = true
score = score + 1
end
local cy = pillar[i].y - (interval_y / 2 - r / ratio) - 0.5
local cx = pillar[i].x
set4Vtx(this, feature_3.folder, feature_3.entity[1], feature_3.clip[2*i-1], cx , cy, 2 * r, 1.0 , 0.0, 1.0, ratio, 0.0, 0.0)
cy = pillar[i].y + (interval_y / 2 - r / ratio) + 0.5
//更新实体坐标
set4Vtx(this, feature_3.folder, feature_3.entity[1], feature_3.clip[2*i], cx , cy, 2 * r, 1.0 , 0.0, 1.0, ratio, 0.0, 0.0)
end
if noseY ~= 0 then
sub.y = noseY
end
if (sub.y ~= 0 or lastY ~= 0) then
sub.a = sub.a * 0.8 + (sub.y - lastY) / timeDelta * 0.2
else
sub.a = sub.a * 0.8
end
set4Vtx(this, feature_2.folder, feature_2.entity[1], feature_2.clip[1], sub.x , sub.y, 2 * sub.r, 2 * sub.r / ratio / 1.1 , sub.a, 1.0, ratio, 0.0, 0.0)
//对所有柱子遍历做碰撞检测
for i = 1,5 do
if rectCollision(i,1) or rectCollision(i,2) or circleCollision(i,1) or circleCollision(i,2) then
gaming = false
if score <= range_s[1] then
Sticker2DV3.playClip(this, feature_0.folder, feature_0.entity[1], feature_0.clip[4], 0)
elseif score <= range_s[2] then
Sticker2DV3.playClip(this, feature_0.folder, feature_0.entity[1], feature_0.clip[3], 0)
else
Sticker2DV3.playClip(this, feature_0.folder, feature_0.entity[1], feature_0.clip[2], 0)
end
CommonFunc.setFeatureEnabled(this, feature_t.folder, true)
if score >= 10 then
realTimeFunc.initRealTime(this, feature_t.folder, true, feature_t.realTimeParams[1])
else
realTimeFunc.initRealTime(this, feature_t.folder, true, feature_t.realTimeParams[2])
end
realTimeFunc.setRealTime(this, feature_t.folder, "u_data", score)
end
end
lastY = sub.y
end
return true
end,
handleRecodeVedioEvent = function (this, eventCode)
if (init_state ~= 0) then
return true
end
if (eventCode == 1) then
timeLast = getTime(this)
timeCumu = 0
score = 0
gaming = true
pillar =
{
{
x = start_x,
y = range_y[1] + math.random() * (range_y[2] - range_y[1]),
counted = false
},
{
x = start_x + interval_x,
y = range_y[1] + math.random() * (range_y[2] - range_y[1]),
counted = false
},
{
x = start_x + interval_x * 2,
y = range_y[1] + math.random() * (range_y[2] - range_y[1]),
counted = false
},
{
x = start_x + interval_x * 3,
y = range_y[1] + math.random() * (range_y[2] - range_y[1]),
counted = false
},
{
x = start_x + interval_x * 4,
y = range_y[1] + math.random() * (range_y[2] - range_y[1]),
counted = false
},
}
sub =
{
r = 0.105,
x = 0.24,
y = 0.5,
sy = 0.0,
a = 0
}
lastY = noseY
for i = 1,10 do
Sticker2DV3.playClip(this, feature_3.folder, feature_3.entity[1], feature_3.clip[i], 0)
set4Vtx(this, feature_3.folder, feature_3.entity[1], feature_3.clip[i], -2 , -2, 0, 0 , 0.0, 0.0, ratio, 0.0, 0.0)
end
for i = 1,4 do
Sticker2DV3.stopClip(this, feature_0.folder, feature_0.entity[1], feature_0.clip[i])
end
set4Vtx(this, feature_2.folder, feature_2.entity[1], feature_2.clip[1], -2 , -2, 0, 0 , 0, 0, ratio, 0.0, 0.0)
CommonFunc.setFeatureEnabled(this, feature_t.folder, false)
end
return true
end,
} 然后有几个stcker文件,可以看到有一个是柱子的entity信息,有一个是潜水艇的entity信息,后面那个游戏失败时弹出的那个框框模型。然后每一个stcker文件夹都有两个json文件,其中主要是clip.json,里面主要包含实体的基本信息,还有transform参数。
"clipname1": {
"alphaFactor": 1.0,
"blendmode": 0,
"fps": 16,
"height": 801,
"textureIdx": {
"idx": [
0
],
"type": "image"
},
"transformParams": {
"position": {
"point0": {
"anchor": [
0.0,
0.5
],
"point": [
{
"idx": "topright",
"relationRef": 0,
"relationType": "foreground",
"weight": 0.5635420937542709
},
{
"idx": "bottomleft",
"relationRef": 0,
"relationType": "foreground",
"weight": -0.0793309886223863
}
]
},
"point1": {
"anchor": [
1.0,
0.5
],
"point": [
{
"idx": "topright",
"relationRef": 0,
"relationType": "foreground",
"weight": 0.7854868849874516
},
{
"idx": "bottomleft",
"relationRef": 0,
"relationType": "foreground",
"weight": -0.0793309886223863
}
]
}
},
"relation": {
"foreground": 1
},
"relationIndex": [
0
],
"relationRefOrder": 0,
"rotationtype": 1,
"scale": {
"scaleY": {
"factor": 1.0
}
}
},
....总结:
从effect资源可以看出,抖音底层有一个类似游戏引擎的这样的渲染框架,然后通过脚本进行控制。功能也应该是挺齐全的,可能是缩小版的游戏引擎,就是麻雀虽小,五脏俱全。
对于熟悉游戏引擎的人来说,这部分应该不难,基本都是那些
另外,如果想学习引擎这快,我的思路是多去看看一些流行的开源引擎,一开始模仿别人怎么写,然后不断的思考总结,慢慢的你就知道一个引擎应该包含哪些,以及怎么控制各个模块之间的交互。
比如我之前深入研究过OGRE,看过OSG,以及深入研究过THREEJS,同时我自己写的渲染引擎,有把这几个引擎比较好的模块模仿过来,逐渐内化成自己的引擎。
后面有机会把拆解一下抖音比较复杂的特效吧,最好找一个和AI或者AR结合的特效(挖坑2)
3. 关于音视频图形部分
这里主要会大概整理一下比较基础的几个部分,包括滤镜、美颜、特效、转场这些,因为我目前好像只做过这些基础的玩法,更加复杂的就涉及到渲染引擎,还有AI图像方面,后面会继续学习研究
3.1 滤镜篇
现在的滤镜主要还是查找表的形式包括1D/3D LUT,可能有些也会用AI去做,比如风格化迁移等
1D LUT:
调节亮度,对比度,黑白等级256 x 1,只影响Gamma曲线
RGB曲线调节256 x 3
Instagram 里面有很多1D的LUT应用,比如amaro, lomo, Hudson, Sierra.....
void main() {
vec2 uv = gl_FragCoord.st/u_resolution;
uv.y = 1.0 - uv.y;
vec4 originColor = texture2D(u_texture, uv);
vec4 texel = texture2D(u_texture, uv);
vec3 bbTexel = texture2D(u_blowoutTex, uv).rgb;
//256x1
texel.r = texture2D(u_overlayTex, vec2(bbTexel.r, texel.r)).r;
texel.g = texture2D(u_overlayTex, vec2(bbTexel.g, texel.g)).g;
texel.b = clamp(texture2D(u_overlayTex, vec2(bbTexel.b, texel.b)).b, 0.1, 0.9);
//256x3
vec4 mapped;
mapped.r = texture2D(u_mapTex, vec2(texel.r, .25)).r;
mapped.g = texture2D(u_mapTex, vec2(texel.g, .5)).g;
mapped.b = texture2D(u_mapTex, vec2(texel.b, 0.1)).b;
mapped.a = 1.0;
mapped.rgb = mix(originColor.rgb, mapped.rgb, 1.0);
gl_FragColor = mapped;
}Amaro 风格


Lomo 风格


......
3D LUT:
Lookup table : 64x64 512x512
//这没啥说的,都是很基本的
void main() {
vec2 uv = gl_FragCoord.st/u_resolution;
uv.y = 1.0 - uv.y;
lowp vec3 textureColor = texture2D(u_texture, uv).rgb;
textureColor = clamp((textureColor - vec3(u_levelBlack, u_levelBlack, u_levelBlack)) * u_levelRangeInv, 0.0, 1.0);
textureColor.r = texture2D(u_grayTexture, vec2(textureColor.r, 0.5)).r;
textureColor.g = texture2D(u_grayTexture, vec2(textureColor.g, 0.5)).g;
textureColor.b = texture2D(u_grayTexture, vec2(textureColor.b, 0.5)).b;
mediump float blueColor = textureColor.b * 15.0;
mediump vec2 quad1;
quad1.y = floor(blueColor / 4.0);
quad1.x = floor(blueColor) - (quad1.y * 4.0);
mediump vec2 quad2;
quad2.y = floor(ceil(blueColor) / 4.0);
quad2.x = ceil(blueColor) - (quad2.y * 4.0);
highp vec2 texPos1;
texPos1.x = (quad1.x * 0.25) + 0.5 / 64.0 + ((0.25 - 1.0 / 64.0) * textureColor.r);
texPos1.y = (quad1.y * 0.25) + 0.5 / 64.0 + ((0.25 - 1.0 / 64.0) * textureColor.g);
highp vec2 texPos2;
texPos2.x = (quad2.x * 0.25) + 0.5 / 64.0 + ((0.25 - 1.0 / 64.0) * textureColor.r);
texPos2.y = (quad2.y * 0.25) + 0.5 / 64.0 + ((0.25 - 1.0 / 64.0) * textureColor.g);
lowp vec4 newColor1 = texture2D(u_lookupTexture, texPos1);
lowp vec4 newColor2 = texture2D(u_lookupTexture, texPos2);
lowp vec3 newColor = mix(newColor1.rgb, newColor2.rgb, fract(blueColor));
textureColor = mix(textureColor, newColor, u_strength);
gl_FragColor = vec4(textureColor, 1.0);
}Fairytale风格


可以看到3D LUT看起来更加和谐一点,因为3D LUT 的RGB映射关系是关联在一起,1D LUT则是独立的,不过1D LUT可以节省空间,有些只需要单通道就可以搞定的,就可以用1D LUT
LUT得益于其简单的生产流程,基本设计师那边用PhotoShop调好一张查找表,这边就应用上去就OK了
相关资料:
https://affinityspotlight.com/article/1d-vs-3d-luts/
https://zhuanlan.zhihu.com/p/37147849
https://zhuanlan.zhihu.com/p/60702944
3.2 美颜篇
- 磨皮去燥
最简单的方式,就是利用各种降噪滤波器,去掉高频噪声部分
均值模糊 权重分布平均
高斯模糊 权重高斯分布
表面模糊 权重分布只跟颜色空间有关系(与肤色检测配合)
双边滤波 权重分布跟距离和颜色空间分布有关系,
中值模糊 卷积核范围内去中值
导向滤波 参考图像
vec4 BilateralFilter(vec2 uv) {
float i = uv.x;
float j = uv.y;
float sigmaSSquare = 2.0 * SigmaS * SigmaS;
float sigmaRSquare = 2.0 * SigmaR * SigmaR;
vec3 centerColor = texture2D(u_texture, uv).rgb;
float centerGray = Luminance(centerColor);
vec3 sum_up, sum_down;
for(int k = -u_radius; k <= u_radius; k++) {
for(int l = -u_radius; l <= u_radius; l++) {
vec2 uv_new = uv + vec2(k, l)/u_resolution;
vec3 curColor = texture2D(u_texture, uv_new).rgb;
float curGray = Luminance(curColor);
vec3 deltaColor = curyolor - centerColor;
float len = dot(deltaColor, deltaColor);
float exponent = -((i-k)*(i-k)+(j-l)*(j-l))/sigmaSSquare - len/sigmaRSquare;
float weight = exp(exponent);
sum_up += curColor * weight;
sum_down += weight;
}
}
vec3 color = sum_up / sum_down;
return vec4(color, 1.0);
}
vec4 SurfaceFilter(vec2 uv) {
vec3 centerColor = texture2D(u_texture, uv).rgb;
vec3 sum_up, sum_down;
for(int k = -u_radius; k <= u_radius; k++) {
for(int l = -u_radius; l <= u_radius; l++) {
vec2 uv_new = uv + vec2(k, l)/u_resolution;
vec3 curColor = texture2D(u_texture, uv_new).rgb;
vec3 weight = CalculateWeight(curColor, centerColor);
sum_up += weight * curColor;
sum_down += weight;
}
}
return vec4(sum_up / sum_down, 1.0);
}
vec4 gaussian(vec2 uv, bool horizontalPass) {
float numBlurPixelsPerSide = float(blurSize / 2);
vec2 blurMultiplyVec = 0 < horizontalPass ? vec2(1.0, 0.0) : vec2(0.0, 1.0);
//高斯函数
vec3 incrementalGaussian;
incrementalGaussian.x = 1.0 / (sqrt(2.0 * pi) * sigma);
incrementalGaussian.y = exp(-0.5 / (sigma * sigma));
incrementalGaussian.z = incrementalGaussian.y * incrementalGaussian.y;
vec4 avgValue = vec4(0.0, 0.0, 0.0, 0.0);
float coefficientSum = 0.0;
avgValue += texture2D(texture, vertTexCoord.st) * incrementalGaussian.x;
coefficientSum += incrementalGaussian.x;
incrementalGaussian.xy *= incrementalGaussian.yz;
for (float i = 1.0; i <= numBlurPixelsPerSide; i++) {
avgValue += texture2D(texture, vertTexCoord.st - i * texOffset *
blurMultiplyVec) * incrementalGaussian.x;
avgValue += texture2D(texture, vertTexCoord.st + i * texOffset *
blurMultiplyVec) * incrementalGaussian.x;
coefficientSum += 2.0 * incrementalGaussian.x;
incrementalGaussian.xy *= incrementalGaussian.yz;
}
return avgValue / coefficientSum;```
比如双边滤波的效果

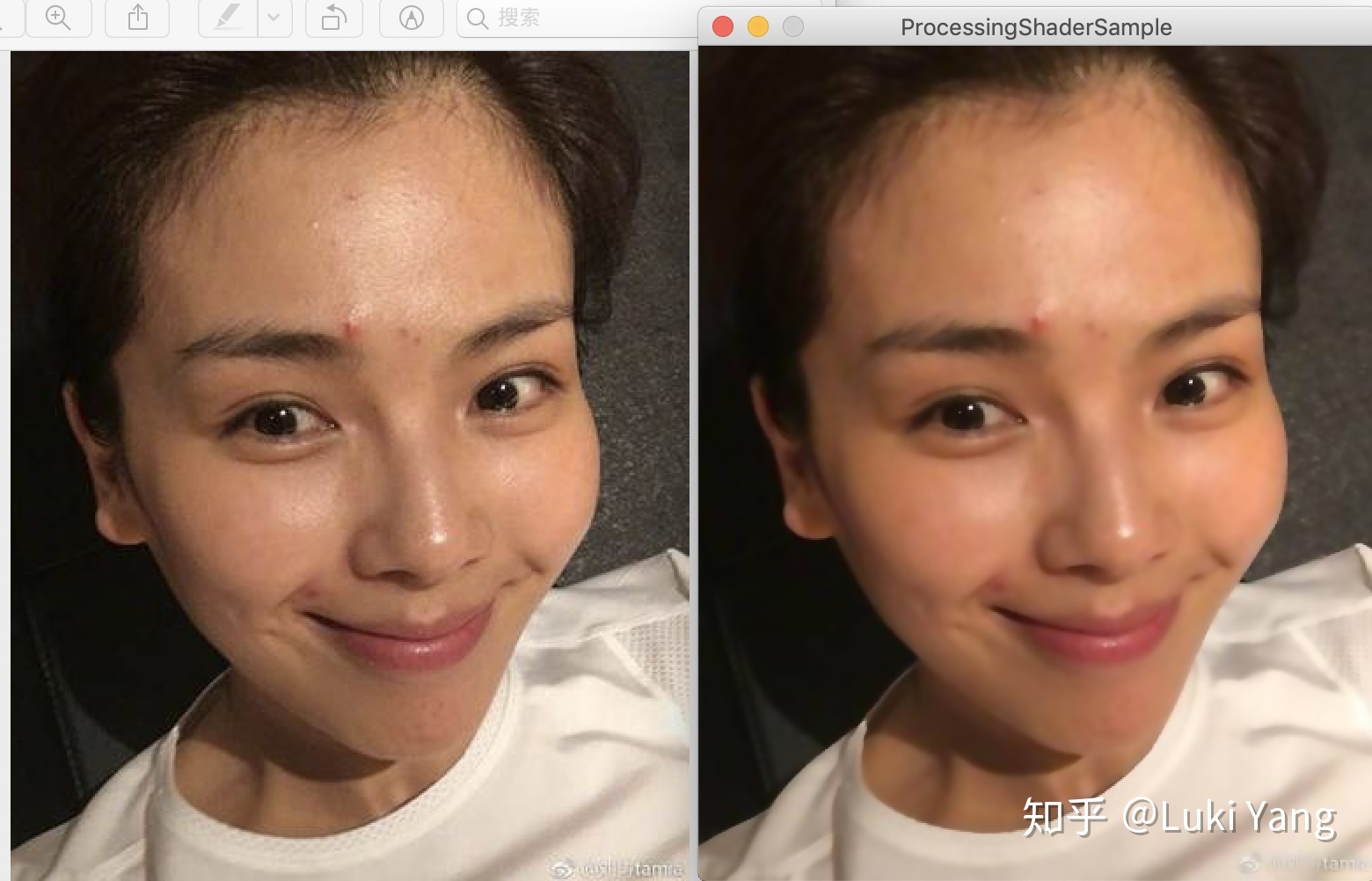
高斯效果,分开纵横两个pass处理,复杂度从WxHx(2R +1)x(2R +1) 降至 WxHx(2R + 1)


suface blur 配合肤色检测,可以看出边缘部分有点硬,


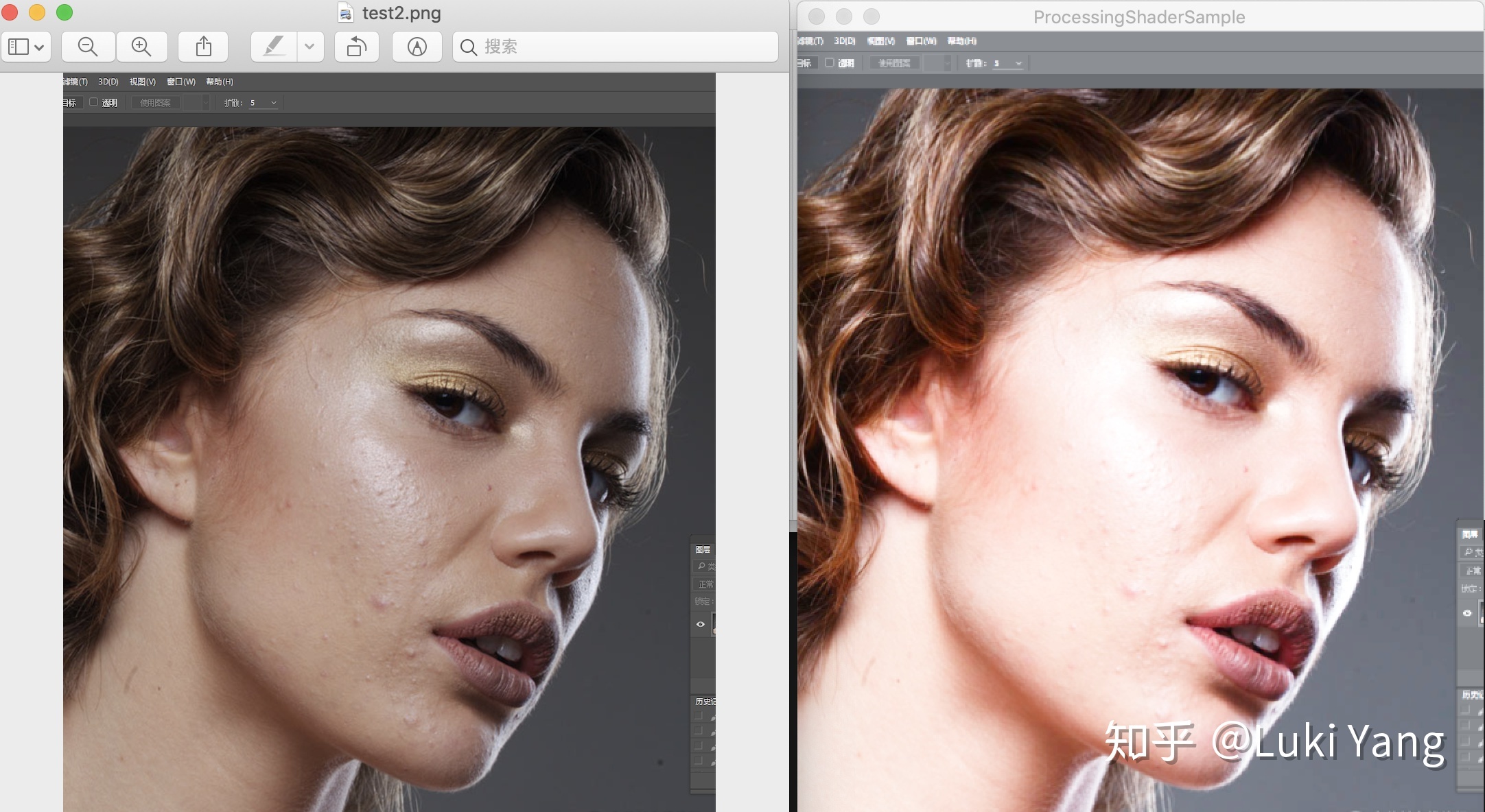
2. 美白
HighPass高亮加一点红晕

3. 美型
美型主要是需要和人脸检测结合起来,对人脸各个部位进行微调,比如:
- 廋脸,根据AI找到的固定脸型的那几个关键点,在各自方向做曲线变形处理
- 大眼,找到中心点,放大一定的半径
- 下巴,也是做曲线变形处理
类似如下的曲线变形处理
// 曲线形变处理
vec2 curveWarp(vec2 textureCoord, vec2 originPosition, vec2 targetPosition, float radius)
{
vec2 offset = vec2(0.0);
vec2 result = vec2(0.0);
vec2 direction = targetPosition - originPosition;
float infect = distance(textureCoord, originPosition)/radius;
infect = 1.0 - infect;
infect = clamp(infect, 0.0, 1.0);
offset = direction * infect;
result = textureCoord - offset;
return result;
}......
这一块主要是需要准确的关键点处理,然后就是怎么调整曲线了,可以自己注册一个Face++的FaceDetect自己玩一下,包括怎么和贴纸配合,这一块还在总结中,后续会自己研究(挖坑3)
3.3 转场篇
转场主要是涉及到两段视频之间,Shader会有两个Input,然后通过progress控制进度,我理解的转场主要包括以下这些:
- UV变换
转场很多其实都是UV变化,UV坐标围绕某个点旋转、缩放、平移
//scale center
vec2 scale_uv = vec2(0.5 + (tc.x - 0.5) / scaleU , 0.5 + (tc.y - 0.5) / scaleV );
//rotate
vec2 rotateUV(vec2 uv, float rotation, vec2 mid)
{
float ratio = (resolution.x / resolution.y);
float s = sin ( rotation );
float c = cos ( rotation );
mat2 rotationMatrix = mat2( c, -s, s, c);
vec2 coord = vec2((uv.x - mid.x) * ratio ,(uv.y -mid.y)*1.0);
vec2 scaled = rotationMatrix * coord;
return vec2(scaled.x / ratio + mid.x,scaled.y + mid.y);
}
//translate
vec2 translate_uv = vec2(0.5 + (tc.x - 0.5) / scaleU , 0.5 + (tc.y - 0.5) / scaleV );怎么控制进度就慢慢调吧
2. Blend转场
首先熟悉一下PhotoShop里面的混合模式alphe混合、滤色、加深、减淡、高亮度等等
https://zhuanlan.zhihu.com/p/23905865
然后就可以慢慢玩了
3. 模糊转场
主要也是Photoshop里面的几种模糊方式,旋转模糊、高斯模糊、均值模糊等等
需要注意一下旋转模糊,我实现过一种旋转模糊的转场,需要配合随机采样
float rand(vec2 uv){
return fract(sin(dot(uv.xy ,vec2(12.9898,78.233))) * 43758.5453);
}
vec4 rotation_blur(vec2 tc) {
angle = angle * PI_ROTATION / 180.0;
vec2 uv = tc;
float uv_random = rand(uv);
vec4 sum_color = vec4(0.0);
for(float i = 0.0; i < samples; i++) {
float percent = (i + uv_random) / samples;
float real_angle = angle + percent * strength;
real_angle = mod(real_angle, PI_ROTATION);
vec2 uv_rotation = rotateUV(uv, real_angle, center);
sum_color += INPUT(fract(uv_rotation));
}
return sum_color / samples;
}And 这里有个转场的网站,可以研究一下
3.4 特效篇
基础的特效包括:抖动、灵魂出窍、故障风、光晕、老电影、粒子特效等等
比如old film


比如glitch风格(动态的会好一点)


这些特效都不难,网上Shader到处都是,基本copy下来调调参数就行,可能也就粒子特效需要调很多细节,但如果你有图形引擎的基础,这些都很简单,到时候我可以建个仓库,share一些我自己实现的shader
一般特效的话可以先去网上找,比如shadertoy
如果找不到的话,需要自己去想怎么实现,我一般是会按如下的方式去思考:
- 善于利用各种卷积滤波器(边缘检测、模糊),有时候需要和随机采样结合
- 熟悉各种颜色空间,熟悉饱和度、锐度、亮度、色度等基础调节
- UV变换多写几个有经验了,然后理解一些曲线函数,基本都能慢慢调出来
- 可以试着看看相关论文,或者OpenCV的实现方式
简单的特效实现起来并不难,多去写,慢慢总结经验的套路,如果更深入一点可能需要图形图像和数学的知识
3.5 串联这些效果
可能大家比较熟悉的就是GPUImage了,基本都是用这个去串联这些特效、滤镜之类,关于GPUImage网上也有很多资料,这里就不具体讲了,也比较简单,内部就是一个Input一个output通过FBO串起来。这里主要想推荐大家看下movit这个框架,基本跟GPUImage类似,支持单个input和多个input,可以打断中间节点,也可以有FrameBufferCache机制,但他还有一个优化的点就是,Shader动态组装机制,熟悉游戏引擎应该都知道这个,Shader是可以在最后动态生成,他里面是通过宏define来控制,可以把一些列串联特效组装到一起,非常高效,后面可以单独讲讲这块。
只需要看下他组装shader的过程:
//xxxx
完了之后可以生成类似如下的shader:
precision highp float;
varying vec2 tc;
#define FUNCNAME eff0
uniform sampler2D eff0_tex;
vec4 FUNCNAME(vec2 tc) {
return texture2D(eff0_tex, vec2(tc.x,1.0-tc.y));
}
#undef PREFIX
#undef FUNCNAME
#define INPUT eff0
#define FUNCNAME eff1
uniform float eff1_strength;
uniform sampler2D eff1_lut;
vec4 FUNCNAME(vec2 tc) {
float strength = eff1_strength;
lowp vec4 textureColor = INPUT(tc);
mediump float blueColor = textureColor.b * 63.0;
mediump vec2 quad1; quad1.y = floor(floor(blueColor) / 8.0);
quad1.x = floor(blueColor) - (quad1.y * 8.0);
mediump vec2 quad2;
quad2.y = floor(ceil(blueColor) / 8.0);
quad2.x = ceil(blueColor) - (quad2.y * 8.0);
highp vec2 texPos1;
texPos1.x = (quad1.x * 0.125) + 0.5/512.0 + ((0.125 - 1.0/512.0) * textureColor.r);
texPos1.y = (quad1.y * 0.125) + 0.5/512.0 + ((0.125 - 1.0/512.0) * textureColor.g);
highp vec2 texPos2;
texPos2.x = (quad2.x * 0.125) + 0.5/512.0 + ((0.125 - 1.0/512.0) * textureColor.r);
texPos2.y = (quad2.y * 0.125) + 0.5/512.0 + ((0.125 - 1.0/512.0) * textureColor.g);
lowp vec4 newColor1 = texture2D(eff1_lut, texPos1);
lowp vec4 newColor2 = texture2D(eff1_lut, texPos2);
lowp vec4 newColor = mix(newColor1, newColor2, fract(blueColor));
return mix(textureColor, vec4(newColor.rgb, textureColor.w), strength);
}
#undef PREFIX
#undef FUNCNAME
#undef INPUT
#define INPUT eff1
void main()
{
gl_FragColor = INPUT(tc);
} 直接通过一个#define FUNCNAME就可以串起来,我以前写的那个渲染引擎,也是动态组装shader,跟这个有点类似,不过比这个复杂,需要更多的宏来控制,有兴趣可以去看看
Movit源码:https://git.sesse.net/?p=movit;a=summary
4. 关于音视频处理
4.1 音视频理论知识
- H264/H265编码原理,宏快怎么划分
- I、P、B帧压缩方式
- SPS/PPS 信息
- 音频的采样率
- 封装格式(MP4, FLV),MP4的Box形式存储
- YUV数据
4.2 编解码部分
音视频解码基本流程

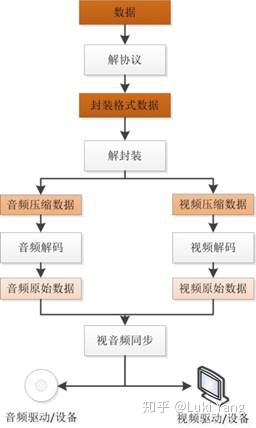
参考:
https://blog.csdn.net/leixiaohua1020/article/details/18893769
- 硬解部分(Android MediaCodec)
在低端平台更多的需要依赖硬件解码,效率会更高,Android MediaCodec

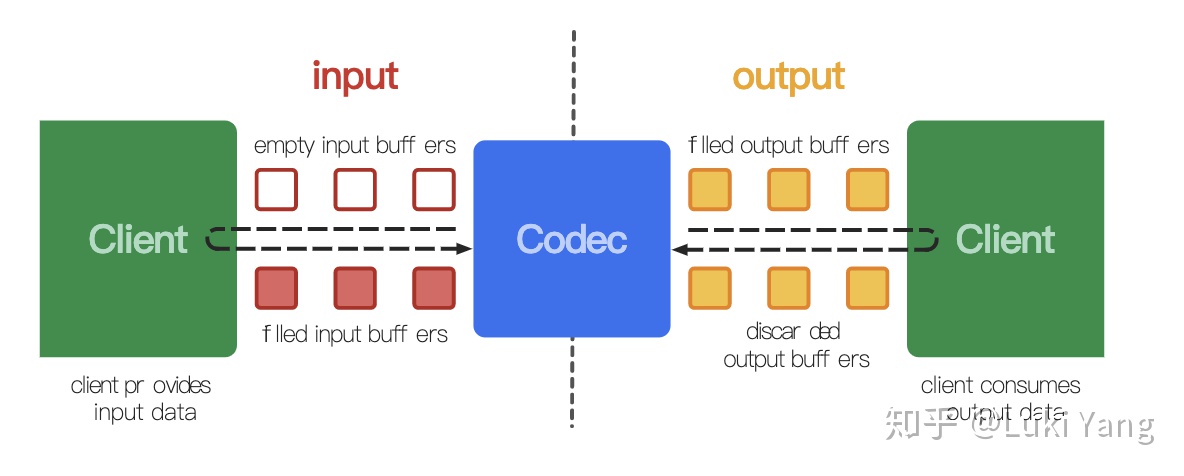
https://developer.android.com/reference/android/media/MediaCodec?hl=en
大概的代码逻辑
while (!m_sawOutputEOS) {
if (!m_sawInputEOS) {
// Feed more data to the decoder
final int inputBufIndex = m_decoder.dequeueInputBuffer(TIMEOUT_USEC);
if (inputBufIndex >= 0) {
ByteBuffer inputBuf = m_decoderInputBuffers[inputBufIndex];
// Read the sample data into the ByteBuffer. This neither
// respects nor
// updates inputBuf's position, limit, etc.
final int chunkSize = m_extractor.readSampleData(inputBuf, 0);
if (m_verbose)
Log.d(TAG, "input packet length: " + chunkSize + " time stamp: " + m_extractor.getSampleTime());
if (chunkSize < 0) {
// End of stream -- send empty frame with EOS flag set.
m_decoder.queueInputBuffer(inputBufIndex, 0, 0, 0L, MediaCodec.BUFFER_FLAG_END_OF_STREAM);
m_sawInputEOS = true;
if (m_verbose)
Log.d(TAG, "Sent input EOS");
} else {
if (m_extractor.getSampleTrackIndex() != m_videoTrackIndex) {
Log.w(TAG, "WEIRD: got sample from track " + m_extractor.getSampleTrackIndex()
+ ", expected " + m_videoTrackIndex);
}
long presentationTimeUs = m_extractor.getSampleTime();
m_decoder.queueInputBuffer(inputBufIndex, 0, chunkSize, presentationTimeUs, 0);
if (m_verbose)
Log.d(TAG,
"Submitted frame to decoder input buffer " + inputBufIndex + ", size=" + chunkSize);
m_inputBufferQueued = true;
++m_pendingInputFrameCount;
if (m_verbose)
Log.d(TAG, "Pending input frame count increased: " + m_pendingInputFrameCount);
m_extractor.advance();
m_extractorInOriginalState = false;
}
} else {
if (m_verbose)
Log.d(TAG, "Input buffer not available");
}
}
final int decoderStatus = m_decoder.dequeueOutputBuffer(m_bufferInfo, dequeueTimeoutUs);
if (decoderStatus == MediaCodec.INFO_TRY_AGAIN_LATER) {
// No output available yet
if (m_verbose)
Log.d(TAG, "No output from decoder available");
} else if (decoderStatus == MediaCodec.INFO_OUTPUT_BUFFERS_CHANGED) {
// Not important for us, since we're using Surface
if (m_verbose)
Log.d(TAG, "Decoder output buffers changed");
} else if (decoderStatus == MediaCodec.INFO_OUTPUT_FORMAT_CHANGED) {
MediaFormat newFormat = m_decoder.getOutputFormat();
if (m_verbose)
Log.d(TAG, "Decoder output format changed: " + newFormat);
} else if (decoderStatus < 0) {
Log.e(TAG, "Unexpected result from decoder.dequeueOutputBuffer: " + decoderStatus);
return ERROR_FAIL;
} else {
///....
m_decoder.releaseOutputBuffer(decoderStatus, doRender);
}
}解码过程网上到处都是,解码主要就是配合MediaExtrator,直接说一下需要注意的点:
- getOutputBuffer得到的数据格式主要是YUV420P和YUV420SP,UV通道排列不一样
- seekTo完之后要Flush
- configure如果传入surface则是直接decode到suface上,不同通过getOutputBuffer获取数据
2. 软解部分(FFMPEG)
其实现在绝大部分音视频APP编解码都是用的FFMPEG,这里门也包含了硬解MediaCodec部分,所以只需要用FFMPEG就可以做硬解和软解的切换。关于FFMPEG的学习,首推肯定是雷神的博客啦,
https://blog.csdn.net/leixiaohua1020/article/details/15811977
主要包括两个部分,首先是prepare部分,
if (avformat_open_input(&mFormatContext, path.c_str(), NULL, NULL) != 0) {
mlt_log_error(mProducer, "Could not open input file: %s", path.c_str());
goto error;
}
if (avformat_find_stream_info(mFormatContext, NULL) < 0) {
mlt_log_error(mProducer, "Could not find stream information");
goto error;
}
mVideoStreamIndex = findPreferedVideoStream();//遍历track找到视频轨
mVideoStream = mFormatContext->streams[mVideoStreamIndex];
//然后就可以得到一些列参数,width,height,fps,fromat
//如果是硬解
//根据不同的编码器,找到对应的解码器,如H264,H265等
mVideoCodec = avcodec_find_decoder_by_name("h264_mediacodec");;
//如果是软解
mVideoCodec = avcodec_find_decoder(mVideoStream->codecpar->codec_id);
//open
avcodec_open2(mVideoCodecContext, mVideoCodec, NULL)
//就可以开始解码了
解码部分
do {
if (!mPacket) {
ret = getVideoPacket();
if (ret < 0 && ret != AVERROR_EOF) {
break;
}
}
//这里面送包的时候有很多细节
int ret = avcodec_send_packet(mVideoCodecContext, flush ? NULL : mPacket);
if (ret >= 0)
freeVideoPacket();
else if (ret < 0 && ret != AVERROR_EOF && ret != AVERROR(EAGAIN)) {
break;
}
ret = avcodec_receive_frame(mVideoCodecContext, mFrame);
if (ret >= 0) {
ret = DECODER_FFMPEG_SUCCESS;
//计算pts
mCurrentPos = getTime(mFrame->pts == AV_NOPTS_VALUE ? mFrame->pkt_dts : mFrame->pts);
pts = mCurrentPos;
break;
}
++count;
} while (ret < DECODER_FFMPEG_SUCCESS && count < DECODER_TRY_ATTEMPTS);
//后面就是针对不同的格式,接入数据,
//还可以通过swscaleFrame进行转码,转成你想要的格式
//然后就是copy AVFrame里面的数据啦
关于FFMPEG有太多可以去学习的了,比如:
- 学会用ffmpeg ffprobe ffplay一些命令,真的非常强大,方便分析问题(ffprobe -i xxxx)
- 怎么去切换软解和硬码
- 熟悉API返回的状态
然后就是兼容性的问题:
由于Android平台太复杂了,厂商很多,所以会有无穷无尽的兼容性问题需要去解决,总体来说兼容性问题主要包括:
- 数据源的兼容性,YUV格式非常多样,420p/420sp是常见的,还有yuv420p10le 这种10bit,贼坑
- 硬件平台的兼容性,这里坑就更多了,MediaCodec支持程度,尤其是低端机非常需要注意
- 分辨率问题,4K/8K,高通平台的支持程度
这个后续单独去整理吧......(挖坑4)
4.3 音视频同步
视音频同步的实现方式其实有三种,分别是:
- 以音频为主时间轴作为同步源;
- 以视频为主时间轴作为同步源;
- 以外部时钟为主时间轴作为同步源;
具体用哪一种需要根据场景,比如在线视频播放器,一般会以第一种音频作为主时间轴去对齐视频帧数据,做丢帧和用当前帧处理,比如我之前写的音视频编辑SDK,因为我们有一条固定帧率的时间线,所以我们的对齐方式是以这条固定时间轴来对齐视频。
比如当前时间轴如果大于当前decode出来的帧的pts,就直接丢掉,继续找下一帧,如果当前时间轴小于decode出来的帧的pts,超过1一帧的时间就继续用上一帧渲染即可。
4.4 多视频多轨道(进阶)


视频编辑SDK肯定是需要支持多视频多轨道编辑,如何高效的管理,方便编辑和预览,这里面主要是需要一个好的Multi track的框架支撑,在这里推荐一个MLT框架,这个框架对于多视频多轨道处理真的非常强大,内部有精确的时间戳对齐逻辑,只需要关注多轨道数据直接的排列,包括每一个视频片段生产数据,其内部会帮我们做好时间戳对齐,担任也可以和很多插件配合使用,比如movit,ffmpeg等。
基本框架
+--------+ +------+ +--------+
|Producer|-->|Filter|-->|Consumer|
+--------+ +------+ +--------+具体的介绍后面单独写一篇博客整理,如下是官网介绍:
https://github.com/mltframework/mlt
5. 关于传输
这块没做过,对传输协议不太了解,只知道一些理论知识,比如RTMP的分块传输,后面有机会再补齐
5.1 RTMP
6. 分析音视频APP
在开发过程中,对于一个小白来说可能会经常遇到一筹莫展的时候,这时候要学会向同类优秀的应用学习,比如做短视频相关的可以去看抖音/快手怎么做的,做音视频剪辑相关的可以看看见剪映/快影/小影怎么做的,你可以去把他们的包pull出来,比如我在做资源的接入的时候,就对比过快手/抖音/大疆 这几家的资源,看他们的sticker怎样接入,有png序列,有MP4,有自定义GIF格式的,所以从这些APP的packge内部还是能找到一些线索,跟着这些线索再慢慢找到其内部的逻辑,就比如我上面分析抖音潜水艇那个游戏一样,当然也可以去分析其它的一些文件,给你提供思路。
1. 抖音
Package name: com.ss.android.ugc.aweme
adb pull /data/data/com.ss.android.ugc.aweme

主要是分析了一下里面的Effect资源,还有LOG信息, 后面可以有机会继续拆解一下(挖坑5)
2. 快手
Package name: com.smile.gifmaker
同样的方式
3. 大疆
Package name: dji.mimo
主要是DJI mimo,通过他们的sticker资源可以看到他们支持alpha通道视频的原理,后面有类似需求也可以拿过来用
7. 总结
现在是凌晨3点多,从周日从早上开始写到晚上3点,差不多用了将近18个小时来整理[吐血]。想想上一次博客更新差不多是两年前了,那时候是做图形渲染相关的事情,也试着自己写了一个渲染引擎,结合了不错的开源引擎,写完之后对我图形方向的理解有很大的进步,于是试着开始写了几篇博客,继续维护自己关于图形方向的研究,后面由于各种原因,没有继续在维护之前的图形引擎,自己也不在更新博客了。
今天以音视频作为新的方向,重新回来,把自己这两年的一些积累整理出来,希望能对后面的学习者有所帮助,我也会尽力去打磨好每一篇博客,今天这遍博客只是总结一个大的框架,里面有非常非常多的细节,都可单独用一篇文章去讲,比如关于Camera,音视频特效,编解码,兼容性这些,都需要花时间去一点一点研究。我也会对自己每一篇文章有严格的要求,要么不写,要写就尽量按照论文的形式把每一个点讲清楚,结合流程图和效果图,最后还需要给出Demo复现效果。
还是开头那句话,随着5G是时代的到来,音视频的应用将会更加普及,这方面的人才也会更加紧缺,同时对于这里面的技术要求也会越来越高,从现在开始就慢慢积累,完善里面的技能栈,也可以选择一个分支去深入下去,这里面有很多的方向都值得研究。也希望以这篇文章为起点,寻找一些志同道合之人,一起去探索一些音视频方向的玩法,当然还有相机这块,因为我之前一直是做相机相关的,也思考过相机有什么好的方向可以去探索。
总之,我会一直做音视频这个方向,抖音和快手在视频玩法上做到了极致,手机厂商不断的升级Camera,也越来越重视视频的采集,让手机作为拍摄工具可以拍出更加震撼的效果,还有大疆在无人机领域视角去采集的视频数据,也可以做出很多大片效果,还有Insta360在全景方向的玩法,做的也很棒,未来随着硬件设备的升级,还会出现更多有趣的玩法,比如和AR/VR结合在一起,又会有怎样的火花呢,我们拭目以待。
Blog:
http://yanglusheng.com/人生只有一次,做自己喜欢的事吧