
拿下了一个美女图片网站
来自:FreeBuf.COM,起于凡而非于凡
链接:https://www.freebuf.com/articles/web/250308.html
说明
PS:本文仅用于技术研究与讨论,严禁用于非法用途,违者后果自负

cookie
sessionStorage
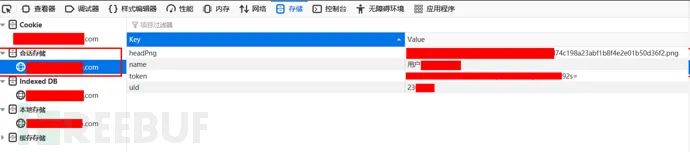
登录、权限认定
登录账户后,先判断图集加载页面怎么认定用户的权限的,看看会不会用到sessionStorage的uid或者token。
这里就要介绍下怎么使用火狐浏览器分析前端的代码了。
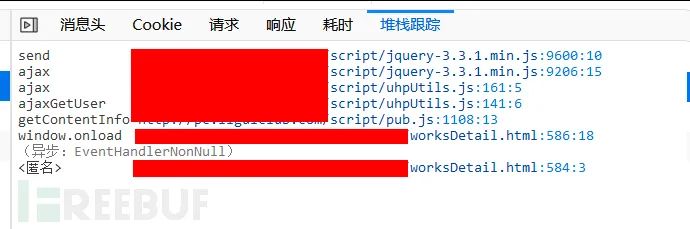
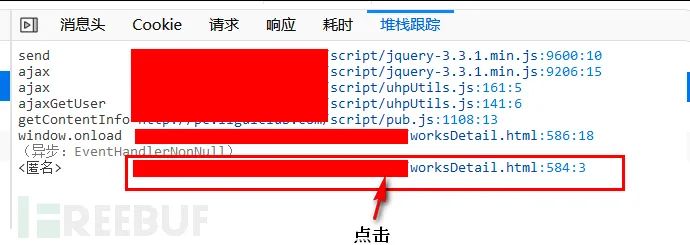
按F12打开开发者工具,然后按照图中的说明,查看加载图集页面时所发起的ajax请求:

从上图得知,一共发起了4次ajajx请求,根据相应的内容,getContentInfo接口返回了图集的数据。
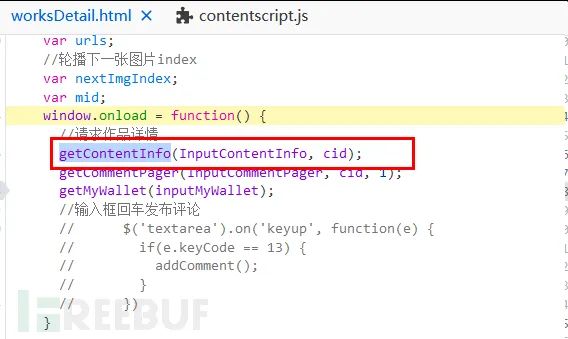
window.onload
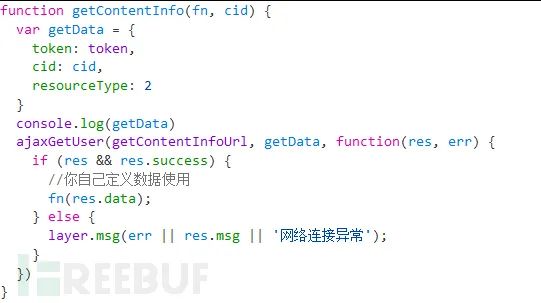
这里可以看到传入了一个object,就是getData,里面的token就是sessionStorage的token:

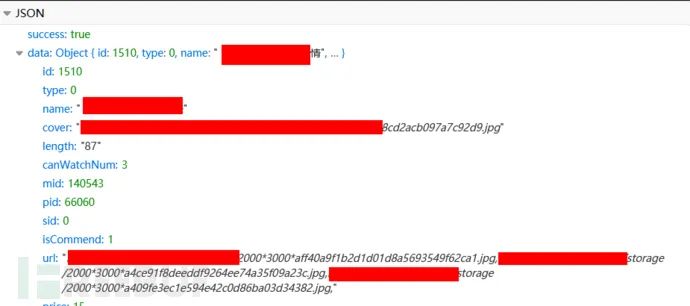
所以也返回了这部分的数据:
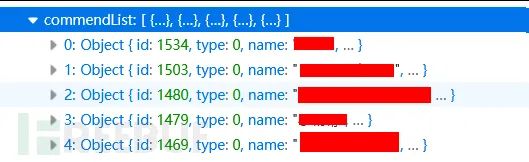
点开一看,终于发现低级错误了,url没做处理,返回了整个图集图片的url:

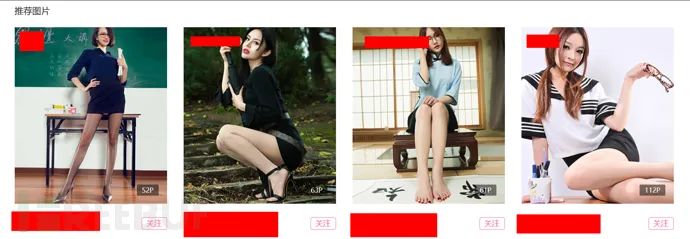
也就是说,虽然这页面的图集本身的其余图片我没法看到,但是它页面中推荐的图集的图片我全都可以看到:

注意:直接使用图片地址其实还是不能查看到图片,需要在地址后面加上一个参数:

但是这个参数每次登录后都是固定的,可以从localStorage中得到,也可以从免费可观看的图片地址中得到,意义不大。

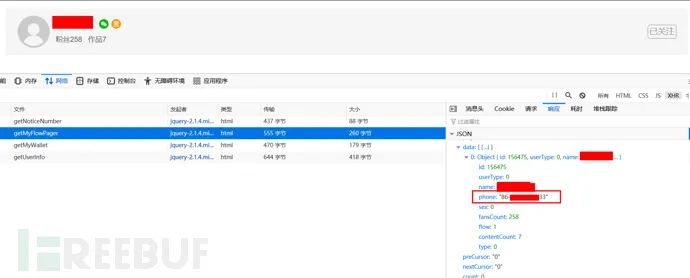
我也就随便一试,居然还真使用了弱口令,下图是登录成功后”我的作品“页面:
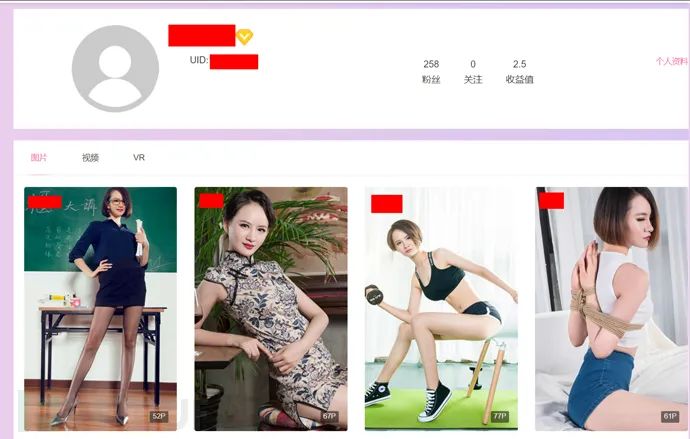
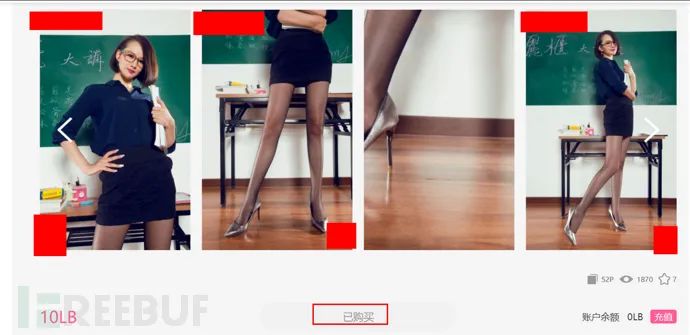
点击一个作品进去,显示已购买:
感想
-End-
评论