
图像自标记的可视化指南
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

将聚类和表示学习结合在一起,可以同时学习特征和标签。
在过去的一年中,人们提出了几种图像表示的自监督学习方法。这种方法最近的趋势是使用对比学习(SimCLR, PIRL, MoCo),已经给出了非常有前景的结果。
然而,正如我们在关于自监督学习的调查:https://amitness.com/2020/02/illustrated-selfsupervision -learning/中看到的,自我监督学习还存在许多其他的问题形式。一个有前途的方法是:
将聚类和表示学习结合在一起,可以同时学习特征和标签。
牛津大学视觉几何组(VGG)的浅野等人在ICLR 2020上发表了一篇论文self - label (SeLa)对这种方法有了新的看法,并在各种基准测试中获得了最新的结果。

最有趣的是,我们可以用这种方法在一些新的领域自动生成图像标签,然后在任何模型架构和常规监督学习方法中独立使用这些标签。自标记是一个非常实用的想法,在缺少标签数据的行业和领域非常有用。让我们来了解一下它是如何工作的。
在高层次上,自标记方法的工作原理如下:
生成标签,然后在这些标签上训练模型 从训练好的模型生成新的标签 重复以上步骤
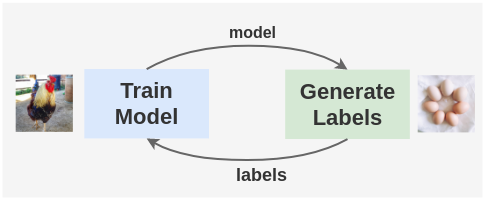
但是,在没有经过训练的模型的情况下,如何为图像生成标签呢?这听起来就像鸡和蛋的问题,如果先有鸡,它从哪里孵化出来,如果先有蛋,谁下的蛋?
解决这个问题的方法是使用一个随机初始化的网络来引导第一组图像的标签。DeepCluster的论文已经证明了这一点。
DeepCluster的作者使用一个随机初始化的AlexNet,并在ImageNet上对其进行评估。由于ImageNet数据集有1000个类,如果我们随机猜测这些类,我们将得到1/1000 = 0.1%的基线精度。但是,一个随机初始化的AlexNet在ImageNet上可以达到12%的准确率。这意味着一个随机初始化的网络的权值中存在着微弱的信号。
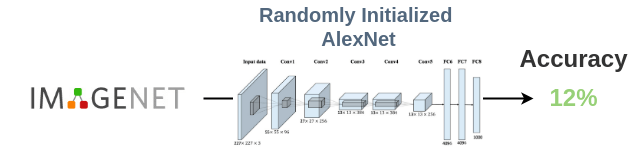
因此,我们可以使用从一个随机初始化的网络中获得的标签来启动这个过程,这个过程以后可以细化。
现在让我们了解一下 self-labelling pipeline是如何工作的。
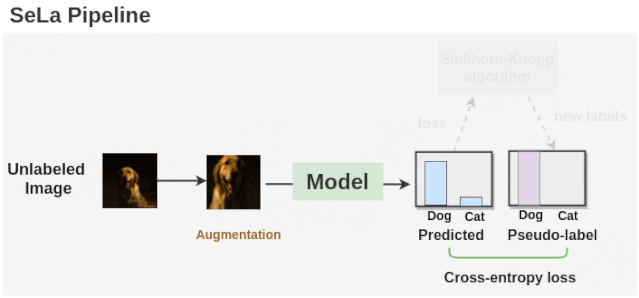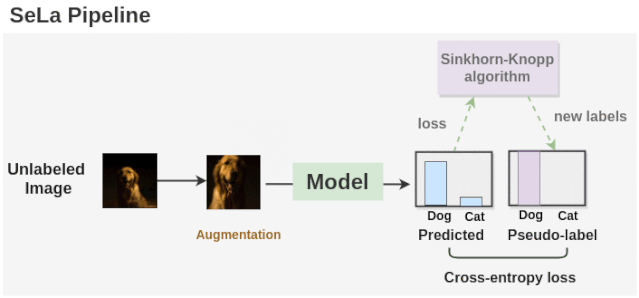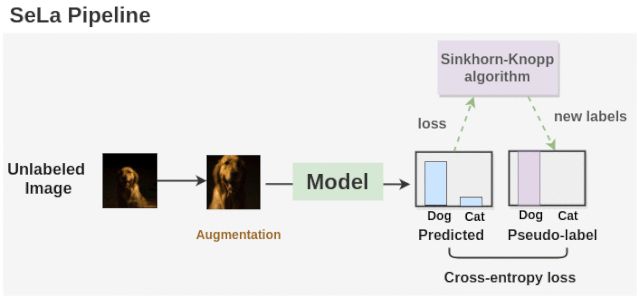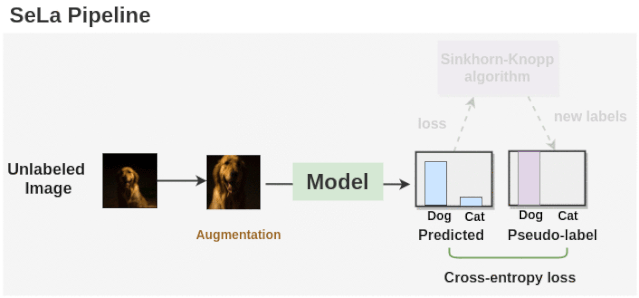
如上图所示,我们首先使用一个随机初始化的模型为增强的未标记的图像生成标签。然后利用Sinkhorn-Knopp算法对未标记的图像进行聚类,得到一组新的标签。模型再次在这些新的标签集上进行训练,并在交叉熵损失的情况下进行优化。Sinkhorn-Knopp算法在训练过程中会偶尔运行一次,以优化并获得新的标签集。这个过程重复了许多个epochs,我们就得到了最终的标签和训练好的模型。
让我们通过一个从输入数据到输出标签的整个pipeline的例子来看看这个方法是如何实际实现的:
1. 训练数据
首先,我们得到N个未标记的图像I1,…,IN,并从一些数据集中获取一些batches。在本文中,从ImageNet数据集中准备了256个batches的未标记图像。

2. 数据增强
我们对未标记的图像应用增强,使学习到的自标记函数是变换不变的。首先将图像随机裁剪为224*224大小。然后以20%的概率将图像转换为灰度。将颜色抖动应用于此图像。最后,以50%的概率水平翻转。经过变换后,将图像归一化,均值为[0.485, 0.456, 0.406],标准差为[0.229, 0.224, 0.225]。
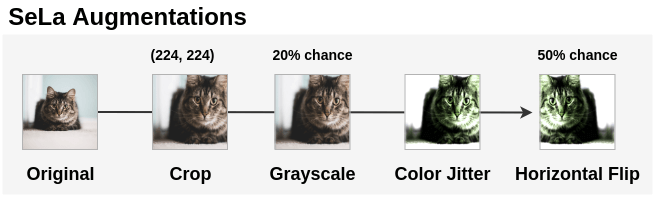
在PyTorch中可以这样实现:
import torchvision.transforms as transforms
from PIL import Image
im = Image.open('cat.png')
aug = transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomGrayscale(p=0.2),
transforms.ColorJitter(0.4, 0.4, 0.4, 0.4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
aug_im = aug(im)
3. 选择聚类(标签)的数量
然后我们需要选择我们想要分组数据的簇数(K)。默认情况下,ImageNet有1000个类,因此我们可以使用1000个簇。聚类的数量依赖于数据,可以通过使用领域知识或通过比较簇数量与模型性能来选择。这个可以表示为:
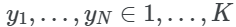
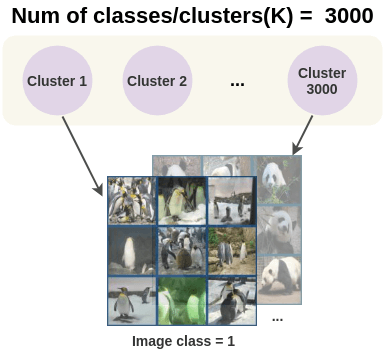
论文中对聚类的数量从1000(1k)到10000 (10k)进行了实验,发现ImageNet的性能在3000个簇时有所提高,但在使用更多簇时性能略有下降。所以论文中使用了3000个簇,结果模型也使用了3000个类。

4. 模型结构
ConvNet架构,如AlexNet或ResNet-50被用作特征提取器。这个网络用ϕ(I)表示,将图像I映射为特征向量m∈RD。
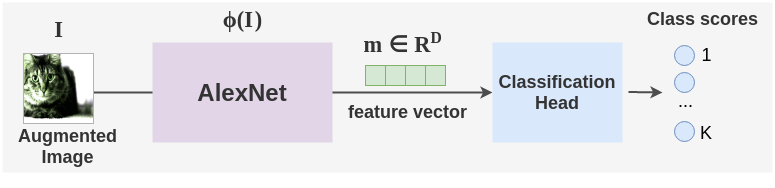
然后,使用一个简单的线性层分类头将特征向量转换为类分数。使用softmax将这些分数转换为概率。
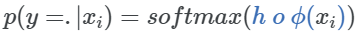
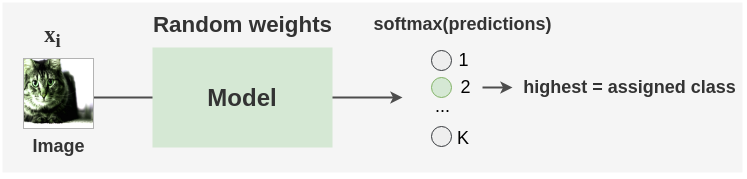
5. 初始化随机标签分配
上面的模型是用随机权重来初始化的,我们在模型中做一个前向传递来获得batch中的每个图像的类预测。假设这些预测的类作为初始标签。
6. 使用最优传输来做自标记
使用这些初始标签,我们希望找到一个更好的图像分布来做聚类。为此,本文使用了一种与深度聚类中使用的K-means聚类完全不同的新方法。作者应用运筹学中最优传输的概念来解决这一问题。
首先让我们通过一个简单的现实例子来理解最优传输问题:
假设一家公司有两个仓库A和B,每个仓库有25台笔记本电脑。公司的两个商店各需要25台笔记本电脑。你需要决定把笔记本电脑从仓库运到商店的最佳方式。
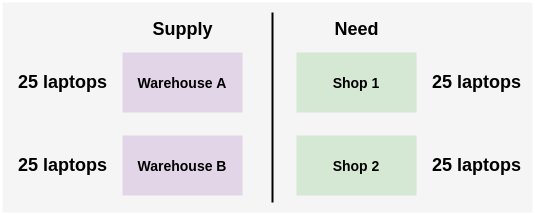
有多种可能的方法来解决这个问题。我们可以把A仓库的所有笔记本电脑分配到1号商店,把B仓库的所有笔记本电脑分配到2号商店。或者交换。或者我们可以从仓库A转移15台笔记本电脑,从仓库B转移10台。唯一的限制是,从仓库分配的笔记本电脑的数量不能超过它们当前的限制,即25台。

但是,如果我们知道每个仓库到商店的距离,那么我们可以找到一个最优的分配与最小的路径。在这里,我们可以直观地看到,由于距离A仓库较近,所以最好的分配方式是将25台笔记本电脑从B仓库送到2店,我们可以将25台笔记本电脑从A仓库送到1店。这种最优分配可以用Sinkhorn-Knopp算法找到。
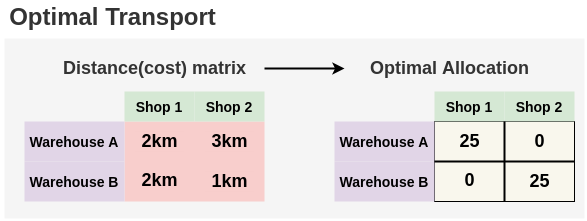
现在,我们理解了这个问题,让我们看看如何在聚类分配的情况下应用它。作者将未标记图像分配到聚类中的问题表述为一个最优传输问题:
问题:
生成一个最优矩阵Q,将N幅未标记的图像分配到K个聚类中。
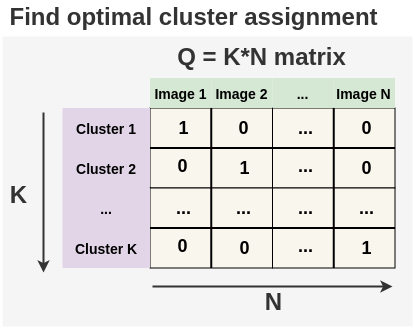
约束:
将未标记的图像平均分成K个聚类。本文将其称为均分条件。
代价矩阵:
将每幅图像分配到一个簇的代价由模型在使用这些簇作为标签进行训练时的性能给出。直观上,这意味着当我们将一幅未标记的图像分配给某个聚类时犯的错误。如果代价高,那意味着我们目前的标签分配不是理想的,所以我们应该在优化步骤中改变它。
我们利用Sinkhorn-Knopp算法的一个快速变式来求最优矩阵Q。该算法只需要进行一次矩阵向量乘法,并根据图像的数量n进行线性缩放。在本文中,使用GPU加速,可以在2分钟内在ImageNet数据集上达到收敛。Sinkhorn- knopp的算法和推导参见Sinkhorn distance论文。还有一篇由Michiel Stock写的很棒的博文解释了最佳传输:https://michielstock.github.io/OptimalTransport/)。
7. 表示学习
由于我们已经更新了标签Q,我们现在可以对图像进行模型预测,并将其与相应的分类交叉熵损失的聚类标签进行比较。该模型在一定的epochs内进行训练,随着交叉熵损失的减小,学习到的内部表征得到改善。
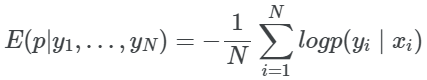
8. 聚类策略更新
在第6步优化标签策略最多一个epoch一次。作者尝试不使用任何自标记算法来做Sinkhorn-Knopp,每个epoch优化一次。最好的结果是在80的时候。
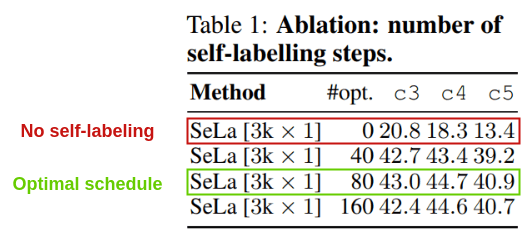
这表明,与没有自标记(只有随机初始化和增强)相比,自标记能够显著提高我们的性能。
标签迁移
通过自标记得到的图像标签可以使用标准的监督训练从头开始训练另一个网络。
在论文中,他们用AlexNet对SeLa分配的标签进行重新训练,使用90个epoch来获得相同的准确率。
他们做了另一个有趣的实验,将SeLa应用于ResNet-50得到的3000个标签用于从头开始训练AlexNet模型。他们得到48.4%的准确率,高于直接从零开始训练AlexNet得到的46.5%的准确率。这表示了标签可以在不同的网络结构中进行迁移。

作者发布了他们为ImageNet数据集生成的标签。这些可以用来从头开始训练一个监督模型。
伪标签来自ImageNet上的best AlexNet模型:http://www.robots.ox.ac.uk/~vgg/research/self-label/asset/ AlexNet -labels.csv ImageNet上best ResNet model的伪标签:http://www.robots.ox.ac.uk/~vgg/research/self-label/asset/ ResNet -labels.csv
作者还设置了一个交互式演示:http://www.robots.ox.ac.uk/~vgg/blog/self-labelling-via-simultaneous-clustering-and-representation-learning.html,查看从ImageNet找到的所有聚类。
直觉和结果
1. 小数据集: CIFAR-10/CIFAR-100/SVHN
本文在CIFAR-10、CIFAR-100和SVHN数据集上取得了击败先前最佳方法AND的最新结果。一个有趣的结果是SVHN有了很小的改进(+0.8%),作者说这是因为监督模型的baseline 96.1和AND的结果93.7之间的差异已经很小了(3%)。
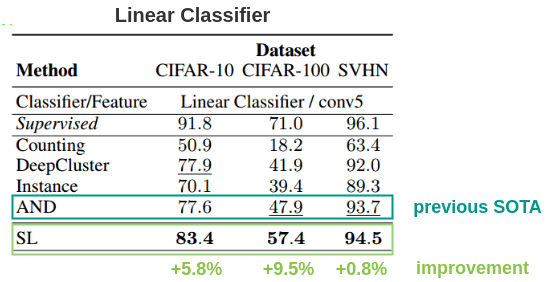
作者还使用加权KNN和128的嵌入大小评估了它,比以前的方法好2%。
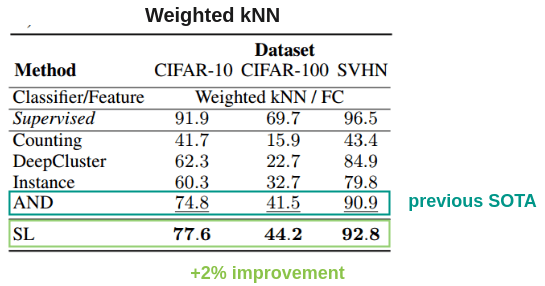
2. 如果数据集不平衡,均分假设会怎么样?
本文假设图像在类别中平均分布。因此,为了测试在非平衡数据集上训练对算法的影响,作者从CIFAR-10中准备了三个数据集:
Full:原始的CIFAR-10数据集,每个类5000幅图像 轻度不平衡:在CIFAR-10的卡车类中删除50%的图像 严重失衡:从CIFAR-10中去掉第一个类的10%,第二个类的20%等
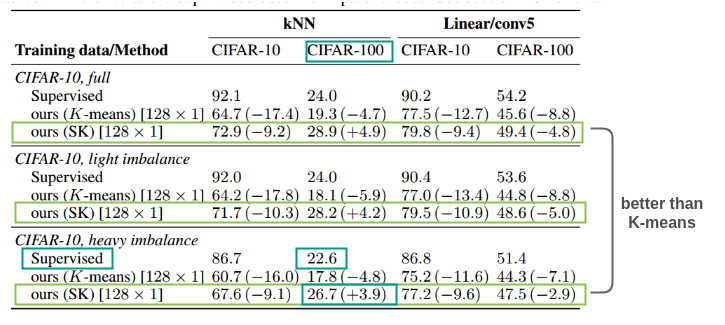
当使用线性探测和kNN分类来评估的时候,SK(Sinkhorn-Knopp)方法在三个情况下击败了K-means。在轻度不平衡的情况下,对任何方法的影响都不大。对于严重不平衡,所有方法的性能都下降,但使用k-means和自标记的自监督方法的性能下降低于有监督方法。在CIFAR-100上,自标记方法甚至优于监督方法。因此,该方法具有较强的鲁棒性,也适用于不平衡数据集。
代码实现
PyTorch的官方实现:https://github.com/yukimasano/self-label
AlexNet和Resnet-50的预训练权值:https://github.com/yukimasano/self-label#trained-models

英文原文:https://amitness.com/2020/04/illustrated-self-labelling/
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~