
Pandas vs Spark:获取指定列的N种方式
导读
本篇继续Pandas与Spark常用操作对比系列,针对常用到的获取指定列的多种实现做以对比。
注:此处的Pandas特指DataFrame数据结构,Spark特指spark.sql下的DataFrame数据结构。

无论是pandas的DataFrame还是spark.sql的DataFrame,获取指定一列是一种很常见的需求场景,获取指定列之后可以用于提取原数据的子集,也可以根据该列衍生其他列。在两个计算框架下,都支持了多种实现获取指定列的方式,但具体实现还是有一定区别的。
在pd.DataFrame数据结构中,提供了多种获取单列的方式。由于Pandas中提供了两种核心的数据结构:DataFrame和Series,其中DataFrame的任意一行和任意一列都是一个Series,所以某种意义上讲DataFrame可以看做是Series的容器或集合。因此,如果从DataFrame中单独取一列,那么得到的将是一个Series(当然,也可以将该列提取为一个只有单列的DataFrame,但本文仍以提取单列得到Series为例)。
首先生成一个普通的DataFrame为例:
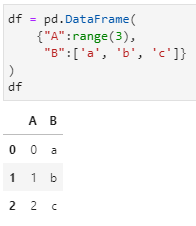
对于如上DataFrame,需要提取其中的A列,则常用的方法有如下4种:
df.A:即应用属性提取符"."的方式,但要求该列名称符合一般变量名命名规范,包括不能以数字开头,不能包含空格等特殊字符;
df['A']:即以方括号加列名的形式提取,这种方式容易理解,因为一个DataFrame本质上可以理解为Python中的一个特殊字典,其中每个列名是key,每一列的数据为value(注:这个特殊的字典允许列名重复),该种形式对列名无任何要求。当方括号内用一个列名组成的列表时,则意味着提取结果是一个DataFrame子集;
df.loc[:, 'A']:即通过定位符loc来提取,其中逗号前面用于定位目标行,此处用:即表示对行不限定;逗号后面用于定位目标列,此处用单个列名即表示提取单列,提取结果为该列对应的Series,若是用一个列名组成的列表,则表示提取多列得到一个DataFrame子集;
df.iloc[:, 0]:即通过索引定位符iloc实现,与loc类似,只不过iloc中传入的为整数索引形式,且索引从0开始;仍与loc类似,此处传入单个索引整数,若传入多个索引组成的列表,则仍然提取得到一个DataFrame子集。
上述4种方法的对应示例如下:

注:以上方法仅示例提取单列得到一个Series结果。
spark.sql中也提供了名为DataFrame的核心数据抽象,其与Pandas中DataFrame有很多相近之处,但也有许多不同,典型区别包括:Spark中的DataFrame每一列的类型为Column、行为Row,而Pandas中的DataFrame则无论是行还是列,都是一个Series;Spark中DataFrame有列名,但没有行索引,而Pandas中则既有列名也有行索引;Spark中DataFrame仅可作整行或者整列的计算,而Pandas中的DataFrame则可以执行各种粒度的计算,包括元素级、行列级乃至整个DataFrame级别。当然,本文不过多对二者的区别做以介绍,而仅枚举常用的提取特定列的方法。

scala spark构建一个示例DataFrame数据
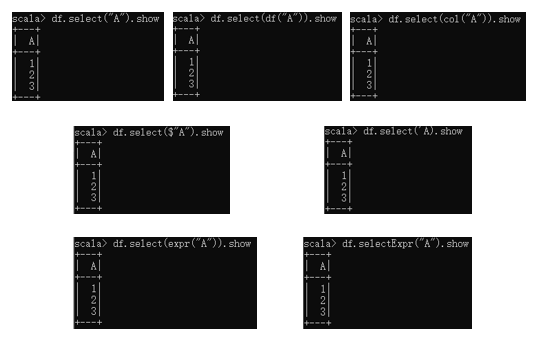
对于如上DataFrame,仍然提取A列对应的DataFrame子集,常用方法如下:
df.select("A"):即直接用select算子+列名实现;
df.select(df("A")):即通过圆括号提取符得到DataFrame中的单列Column对象,而后再用select算子得到相应的DataFrame;
df.select(col("A")):即首先通过col函数得到DataFrame中的单列Column对象,而后再用select算子得到相应的DataFrame。注意,这里的col函数需要首先从org.apache.spark.sql.functions中导入;
df.select($"A"):即通过美元符$+列名字符串隐式转换为Column类型,而后再用select算子得到相应DataFrame,这里$"A"等价于col("A")。注意,能用$隐式转换的前提是执行隐式转换导入:import spark.implicits._;
df.select('A):与用美元符$隐式转换类似,也可用单侧单引号实现隐式转换,实质上也是得到一个Column类型,即'A等价于col("A"),当然也需要首先执行隐式转换导入;
df.select(expr("A")):仍然是用一个函数expr+列名提取该列,这里expr执行了类SQL的功能,可以接受一个该列的表达式执行类SQL计算,例如此处仅用于提取A列,则直接赋予列名作为参数即可;
df.selectExpr("A"):对于上述select+expr的组合,spark.sql中提供了更为简洁的替代形式,即selectExpr,可直接接受类SQL的表达式字符串,自然也可完成单列的提取,相当于是对上一种实现方式的精简形式。
以上7种实现方式的示例如下:
本文分别列举了Pandas和Spark.sql中DataFrame数据结构提取特定列的多种实现,其中Pandas中DataFrame提取一列既可用于得到单列的Series对象,也可用于得到一个只有单列的DataFrame子集,常用的方法有4种;而Spark中提取特定一列,虽然也可得到单列的Column对象,但更多的还是应用select或selectExpr将1个或多个Column对象封装成一个DataFrame,常用的方法多达7种,在这方面似乎灵活性相较于Pandas中DataFrame而言具有更为明显的优越性。但还是那个观点,框架本身是本无高下优劣之分,只有熟练灵活运用方显高效。
最后,公布前期送书中奖读者:根据当时截图所示的3名近期分享最多的读者中,中奖读者如下:请该读者于24小时内通过公众号后台联系小编,过时无效。
相关阅读: