
Hive CTE | with as 隐藏的秘密!
CTE
Hive with as 语句
Hive with 语句默认是不把数据进行物化的,相当于视图,定义了一个SQL片段,每次使用时候可以将该定义的SQL片段拿出来再被使用,该SQL片段可以理解为一个变量,主要用途简化SQL,让SQL更简洁,替换子查询,方便定位问题。该子句紧跟在SELECT或INSERT关键字之前,可以在Hive SELECT,INSERT,CREATE TABLE AS SELECT或CREATE VIEW AS SELECT语句中使用一个或多个CTE 。
with as 也叫做子查询部分,首先定义一个sql片段,该sql片段会被整个sql语句所用到,为了让sql语句的可读性更高些,作为提供数据的部分,也常常用在union等集合操作中。
注意:hive with as不像oracle等数据库会将数据缓存到内存中,只是定义了一个SQL代码片段,方便下次使用,使代码更简洁优美!!! 其最大的好处就是适当的提高代码可读性,而且如果with子句在后面要多次使用到,这可以大大的简化SQL,但不一定提高执行效率。
在高版本的SQL中,with语句进行了物化,默认是不开启的,这个参数为
hive.optimize.cte.materialize.threshold
该参数默认情况下是-1,是关闭的,当开启(大于0),比如设置为2,则如果with..as语句被引用2次及以上时,会把with..as语句生成的table物化,从而做到with..as语句只执行一次,来提高效率。
物化实际上是先相对于视图而言的,视图创建的是一个虚拟表,只是定义了一个SQL片段,并没有实体表的创建,只是概念性的东西,那么物化就是将这种概念性的东西进行实体化,如数据进行缓存,存放在内存,数据进行落盘等,类似于计算的中间结果进行缓存或落到磁盘,这样每次计算的时候可以从该中间结果中取数,这样才可以达到一次分析,多次使用的目的。(这里我们可以类比Spark RDD的缓存概念:RDD 缓存指的是将 RDD 以缓存的形式物化到内存或磁盘的过程)
Hive中具体源码如下:
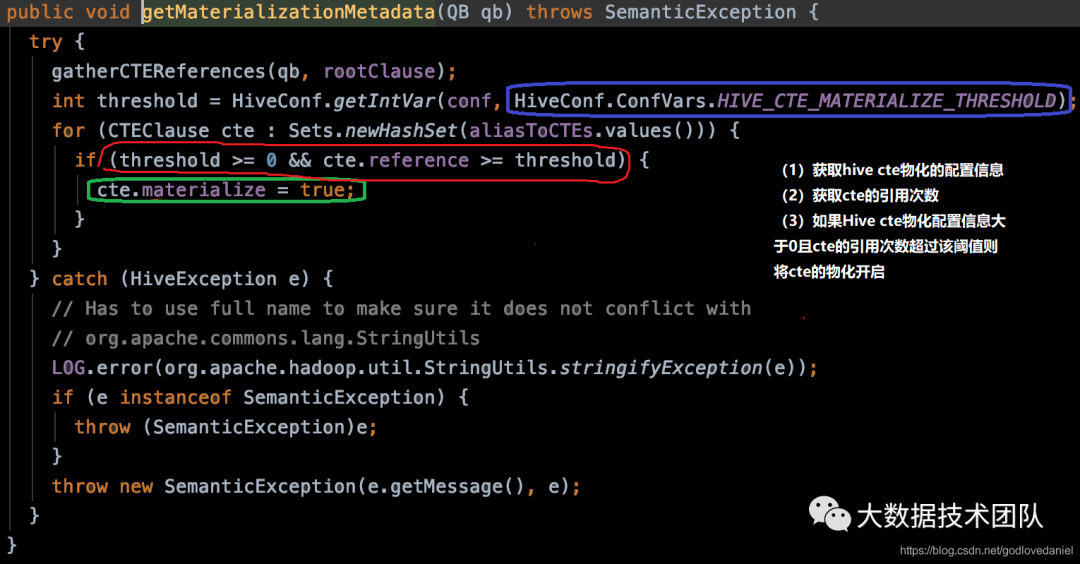
从源码看,在获取元数据时,会进行判断,判断配置参数大于0且cte的引用次数超过配置的参数时候则开启cte的物化。
1 CTE 的使用
1 命令格式
WITHcte_name AS(cte_query)[,cte_name2 AS(cte_query2),……]
参数说明
cte_name:CTE的名称,不能与当前WITH子句中的其他CTE的名称相同。查询中任何使用到cte_name标识符的地方,均指CTE。
cte_query:一个SELECT语句。它产生的结果集用于填充CTE。
2 示例
示例1:
INSERT OVERWRITE TABLE srcp PARTITION (p='abc')SELECT * FROM (SELECT a.key, b.valueFROM (SELECT * FROM src WHERE key IS NOT NULL ) aJOIN (SELECT * FROM src2 WHERE value > 0 ) bON a.key = b.key) cUNION ALLSELECT * FROM (SELECT a.key, b.valueFROM (SELECT * FROM src WHERE key IS NOT NULL ) aLEFT OUTER JOIN (SELECT * FROM src3 WHERE value > 0 ) bON a.key = b.key AND b.key IS NOT NULL)d;
顶层的UNION两侧各为一个JOIN,JOIN的左表是相同的查询。通过写子查询的方式,只能重复这段代码。
使用CTE的方式重写以上语句。
witha as (select * from src where key is not null),b as (select * from src2 where value>0),c as (select * from src3 where value>0),d as (select a.key,b.value from a join b on a.key=b.key),e as (select a.key,c.value from a left outer join c on a.key=c.key and c.key is not null)insert overwrite table srcp partition (p='abc')select * from d union all select * from e;
重写后,a对应的子查询只需写一次,便可在后面进行重用。您可以在CTE的WITH子句中指定多个子查询,像使用变量一样在整个语句中反复重用。除重用外,不必反复嵌套。
示例2:
对于一些比较复杂的计算任务,为了避免过多的JOIN,通常会先把一些需要提取的部分数据使用临时表或是CTE的形式在主要查询区块前进行提取。
临时表的作法:
CREATE TEMPORARY TABLE table_1 ASSELECTcolumnsFROM table A;CREATE TEMPORARY table_2 ASSELECTcolumnsFROM table B;SELECTtable_1.columns,table_2.columns,c.columnsFROM table C JOIN table_1JOIN table_2;
CTE的作法:
-- 注意Hive、Impala支持这种语法,低版本的MySQL不支持(高版本支持)WITH employee_by_title_count AS (SELECTt.name as job_title, COUNT(e.id) as amount_of_employeesFROM employees eJOIN job_titles t on e.job_title_id = t.idGROUP BY 1),salaries_by_title AS (SELECTname as job_title, salaryFROM job_titles)SELECT *FROM employee_by_title_count eJOIN salaries_by_title s ON s.job_title = e.job_title
可以看到TEMP TABLE和CTE WITH的用法其实非常类似,目的都是为了让你的Query更加一目了然且优雅简洁。很多人习惯将所有的Query写在单一的区块里面,用过多的JOIN或SUBQUERY,导致最后逻辑丢失且自己也搞不清楚写到哪里,适时的使用TEMP TABLE和CTE作为辅助,绝对是很加分的。
示例3:优化子查询,方便维护,代码更简洁
with cte as (SELECT gw_id,sensor_id,stddev(temp) over(PARTITION by gw_id,sensor_id) as stddev_temp,stddev(humi) over(PARTITION by gw_id,sensor_id) as stddev_humi,avg(temp) over(PARTITION by gw_id,sensor_id) as avg_temp,avg(humi) over(PARTITION by gw_id,sensor_id) as avg_humiFROM phmdwdb.dwd_iot_phm_trackcir_envwhere from_unixtime(cast(substr(msg_time,1,10) AS BIGINT),'yyyy-MM-dd') = '2020-11-20')select gw_id,sensor_id,3*stddev_temp+avg_temp as temp_std_up,3*stddev_humi+avg_humi as humi_std_up,abs(3*stddev_temp-avg_temp) as temp_std_dn,abs(3*stddev_humi-avg_humi) as temp_std_dnfrom cte
+----------------------+----------------------+--------------------+--------------------+---------------------+--------------------+--+| gw_id | sensor_id | temp_std_up | humi_std_up | temp_std_dn | temp_std_dn |+----------------------+----------------------+--------------------+--------------------+---------------------+--------------------+--+| 1263740609944641536 | 1329016193440047104 | 22.53016020309899 | 76.27771107659711 | 16.851530077439218 | 64.75383829654604 || 1263740609944641536 | 1329016193440047104 | 22.53016020309899 | 76.27771107659711 | 16.851530077439218 | 64.75383829654604 || 1263740609944641536 | 1329016193440047104 | 22.53016020309899 | 76.27771107659711 | 16.851530077439218 | 64.75383829654604 || 1263740609944641536 | 1329016193440047104 | 22.53016020309899 | 76.27771107659711 | 16.851530077439218 | 64.75383829654604 || 1263740609944641536 | 1329016193440047104 | 22.53016020309899 | 76.27771107659711 | 16.851530077439218 | 64.75383829654604 || 1263740609944641536 | 1329016193440047104 | 22.53016020309899 | 76.27771107659711 | 16.851530077439218 | 64.75383829654604 || 1263740609944641536 | 1329016193440047104 | 22.53016020309899 | 76.27771107659711 | 16.851530077439218 | 64.75383829654604 || 1263740609944641536 | 1329016193440047104 | 22.53016020309899 | 76.27771107659711 | 16.851530077439218 | 64.75383829654604 || 1263740609944641536 | 1329016193440047104 | 22.53016020309899 | 76.27771107659711 | 16.851530077439218 | 64.75383829654604 || 1263740609944641536 | 1329016193440047104 | 22.53016020309899 | 76.27771107659711 | 16.851530077439218 | 64.75383829654604 || 1263740609944641536 | 1329016193440047104 | 22.53016020309899 | 76.27771107659711 | 16.851530077439218 | 64.75383829654604 || 1263740609944641536 | 1329016193440047104 | 22.53016020309899 | 76.27771107659711 | 16.851530077439218 | 64.75383829654604 || 1263740609944641536 | 1329016193440047104 | 22.53016020309899 | 76.27771107659711 | 16.851530077439218 | 64.75383829654604 || 1263740609944641536 | 1329016193440047104 | 22.53016020309899 | 76.27771107659711 | 16.851530077439218 | 64.75383829654604 || 1263740609944641536 | 1329016193440047104 | 22.53016020309899 | 76.27771107659711 | 16.851530077439218 | 64.75383829654604 || 1263740609944641536 | 1329016193440047104 | 22.53016020309899 | 76.27771107659711 | 16.851530077439218 | 64.75383829654604 |
示例4:CTE in Views, CTAS, and Insert Statements
-- insert examplecreate table s1 like src;with q1 as ( select key, value from src where key = '5')from q1insert overwrite table s1select *;-- ctas examplecreate table s2 aswith q1 as ( select key from src where key = '4')select * from q1;-- view examplecreate view v1 aswith q1 as ( select key from src where key = '5')select * from q1;select * from v1;-- view example, name collisioncreate view v1 aswith q1 as ( select key from src where key = '5')select * from q1;with q1 as ( select key from src where key = '4')select * from v1;
示例5:CET做递归查询
#!/bin/bashinput_para="hive"hive_home='/usr/idp/current/hive-client/bin';if [ "$1" != "" ];theninput_para=$1fi;option=`echo ${input_para} | awk -F '_' '{print $1}' | sed s/[[:space:]]//g`if [ "$option" = "beeline" ];thenhive_addr=`hadoop fs -cat /phm/JTTL_ETL_COMMON/etl_process.properties | grep hive_addr | awk -F '=' '{print $2}' | sed s/[[:space:]]//g`hive_url="${hive_addr}/phmdwdb"cd $hive_homebeeline -u $hive_url \-hivevar start_day='2020-01-01' \-hivevar end_day='2025-12-31' \-hivevar timeDimTable='phmdwdb.dim_phm_date' \-f /home/centos/phm/JINI_GLOBAL_CREATETABLE/hive_dim_phm_date_query.sqlfiif [ "$option" = "hive" ];thenhive -hivevar start_day='2018-01-01' \-hivevar end_day='2025-12-31' \-hivevar timeDimTable='phmdwdb.dim_phm_date' \-f /home/centos/phm/JINI_GLOBAL_CREATETABLE/hive_dim_phm_date_query.sqlfi具体递归查询SQL如下:drop table ${timeDimTable};create table if not exists ${timeDimTable} aswith dates as (select date_add("${start_day}", a.pos) as dfrom (select posexplode(split(repeat("o", datediff("${end_day}", "${start_day}")), "o"))) a),hours as (select a.pos as hfrom (select posexplode(split(repeat("o", 23), "o"))) a)selectfrom_unixtime(unix_timestamp(cast(d as timestamp)) + (h * 3600)) as dtime, d as dday, weekofyear(d) as dweek, date_format(d, 'u') as ddayofweek, month(d) as dmonth, year(d) as dyear, h as dhourfrom datesjoin hourssort by dtime;
3 CTE作用 小结
(1)可以复用公共代码块,减少表的 读取次数,降低IO 提高性能。如优化join,优化union 语句,优化子查询。将公共语句提前到select语句之前,达到一次查询(读),多次使用,目的是减少读的次数。注意hive必须开启CTE物化的参数才起作用,如果没开启,表还是被重复读取,达不到一次查询多次使用的目的
(2)提高代码的可读性:使代码更简洁,便于维护。如将子查询抽出来以后,放到with语句,可方便定位,维护代码,代码的可读性增强。
(3)做递归查询,进行迭代计算。
———————————————
原文:https://blog.csdn.net/godlovedaniel/article/details/115480115