
Java 集合框架体系总览
集合这块知识的重要性不用多说,加上多线程妥妥的稳占面试必问霸主地主,深入了解集合框架的整体结构以及各个集合类的实现原理是非常有必要的。
由于不同的集合在实现上采用了各种不同的数据结构,导致了各个集合的性能、底层实现、使用方式上存在一定的差异,所以集合这块的知识点非常多,不过好在它的整体学习框架比较清晰。本文只笼统介绍集合框架的知识体系,帮助大家理清思路,重点集合类的详细分析之后会单独分成几篇文章。
全文脉络思维导图如下:
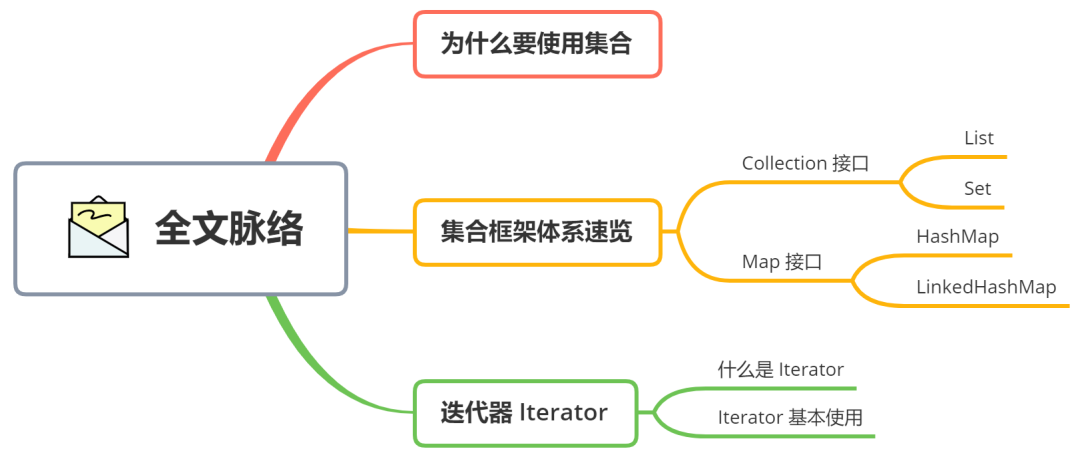
1. 为什么要使用集合
当我们在学习一个东西的时候,最好是明白为什么要使用这个东西,不要为了用而用,知其然而知其所以然。
集合,故名思议,是用来存储元素的,而数组也同样具有这个功能,那么既然出现了集合,必然是因为「数组的使用存在一定的缺陷」。
上篇文章已经简单提到过,数组一旦被定义,就无法再更改其存储大小。举个例子,假设有一个班级,现在有 50 个学生在这个班里,于是我们定义了一个能够存储 50 个学生信息的数组:
1)如果这个班里面来了 10 个转班生,由于数组的长度固定不变,那么显然这个数组的存储能力无法支持 60 个学生;再比如,这个班里面有 20 个学生退学了,那么这个数组实际上只存了 30 个学生,造成了内存空间浪费。总结来说,「由于数组一旦被定义,就无法更改其长度,所以数组无法动态的适应元素数量的变化」。
2)数组拥有 length 属性,可以通过这个属性查到数组的存储能力也就是数组的长度,但是无法通过一个属性直接获取到数组中实际存储的元素数量。
3)因为「数组在内存中采用连续空间分配的存储方式」,所以我们可以根据下标快速获的取对应的学生信息。比如我们在数组下标为 2 的位置存入了某个学生的学号 111,那显然,直接通过下标 2 就能获取学号 111。但是「如果反过来我们想要查找学号 111 的下标呢」?数组原生是做不到的,这就需要使用各种查找算法了。
4)另外,假如我们想要存储学生的姓名和家庭地址的一一对应信息,数组显然也是做不到的。
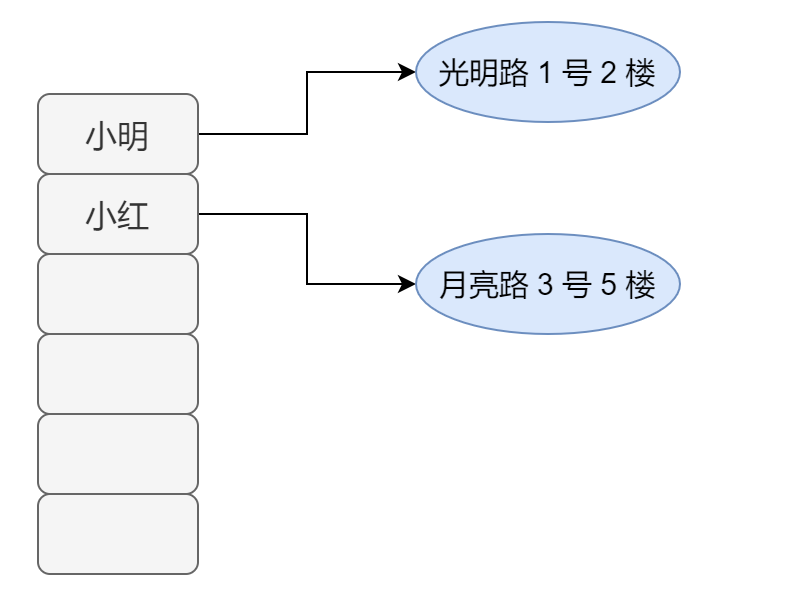
5)如果我们想在这个用来存储学生信息的数组中存储一些老师的信息,数组是无法满足这个需求的,它只能存储相同类型的元素。
为了解决这些数组在使用过程中的痛点,集合框架应用而生。简单来说,集合的主要功能就是两点:
存储不确定数量的数据(可以动态改变集合长度) 存储具有映射关系的数据 存储不同类型的数据
不过,需要注意的是,「集合只能存储引用类型(对象),如果你存储的是 int 型数据(基本类型),它会被自动装箱成 Integer 类型。而数组既可以存储基本数据类型,也可以存储引用类型」。
2. 集合框架体系速览
与现代的数据结构类库的常见情况一样,Java 集合类也将接口与实现分离,这些接口和实现类都位于 java.util 包下。按照其存储结构集合可以分为两大类:
单列集合 Collection 双列集合 Map
Collection 接口
「单列集合」 java.util.Collection:元素是孤立存在的,向集合中存储元素采用一个个元素的方式存储。

来看 Collection 接口的继承体系图:
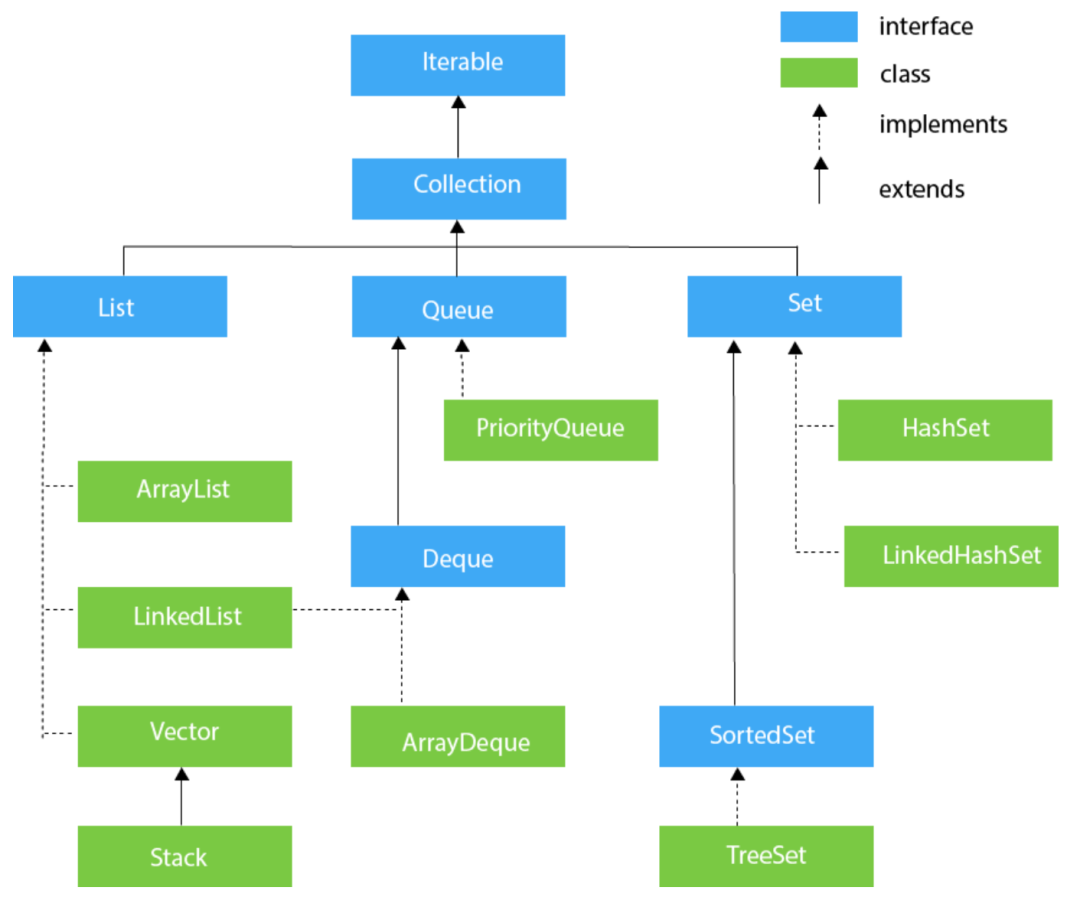
Collection 接口中定义了一些单列集合通用的方法:
public boolean add(E e); // 把给定的对象添加到当前集合中
public void clear(); // 清空集合中所有的元素
public boolean remove(E e); // 把给定的对象在当前集合中删除
public boolean contains(E e); // 判断当前集合中是否包含给定的对象
public boolean isEmpty(); // 判断当前集合是否为空
public int size(); // 返回集合中元素的个数
public Object[] toArray(); // 把集合中的元素,存储到数组中
Collection 有两个重要的子接口,分别是 List 和 Set,它们分别代表了有序集合和无序集合:
1)List 的特点是「元素有序、可重复」,这里所谓的有序意思是:「元素的存入顺序和取出顺序一致」。例如,存储元素的顺序是 11、22、33,那么我们从 List 中取出这些元素的时候也会按照 11、22、33 这个顺序。List 接口的常用实现类有:
「ArrayList」:底层数据结构是数组,线程不安全 「LinkedList」:底层数据结构是链表,线程不安全
除了包括 Collection 接口的所有方法外,List 接口而且还增加了一些根据元素索引来操作集合的特有方法:
public void add(int index, E element); // 将指定的元素,添加到该集合中的指定位置上
public E get(int index); // 返回集合中指定位置的元素
public E remove(int index); // 移除列表中指定位置的元素, 返回的是被移除的元素
public E set(int index, E element); // 用指定元素替换集合中指定位置的元素
2)Set 接口在方法签名上与 Collection 接口其实是完全一样的,只不过在方法的说明上有更严格的定义,最重要的特点是他「拒绝添加重复元素,不能通过整数索引来访问」,并且「元素无序」。所谓无序也就是元素的存入顺序和取出顺序不一致。其常用实现类有:
「HashSet」:底层基于 HashMap实现,采用HashMap来保存元素「LinkedHashSet」: LinkedHashSet是HashSet的子类,并且其底层是通过LinkedHashMap来实现的。
❝至于为什么要定义一个方法签名完全相同的接口,我的理解是为了让集合框架的结构更加清晰,将单列集合从以下两点区分开来:
可以添加重复元素(List)和不可以添加重复元素(Set) 可以通过整数索引访问(List)和不可以通过整数索引(Set) 这样当我们声明单列集合时能够更准确的继承相应的接口。
❞
Map 接口
「双列集合」 java.util.Map:元素是成对存在的。每个元素由键(key)与值(value)两部分组成,通过键可以找对所对应的值。显然这个双列集合解决了数组无法存储映射关系的痛点。另外,需要注意的是,「Map 不能包含重复的键,值可以重复;并且每个键只能对应一个值」。

来看 Map 接口的继承体系图:
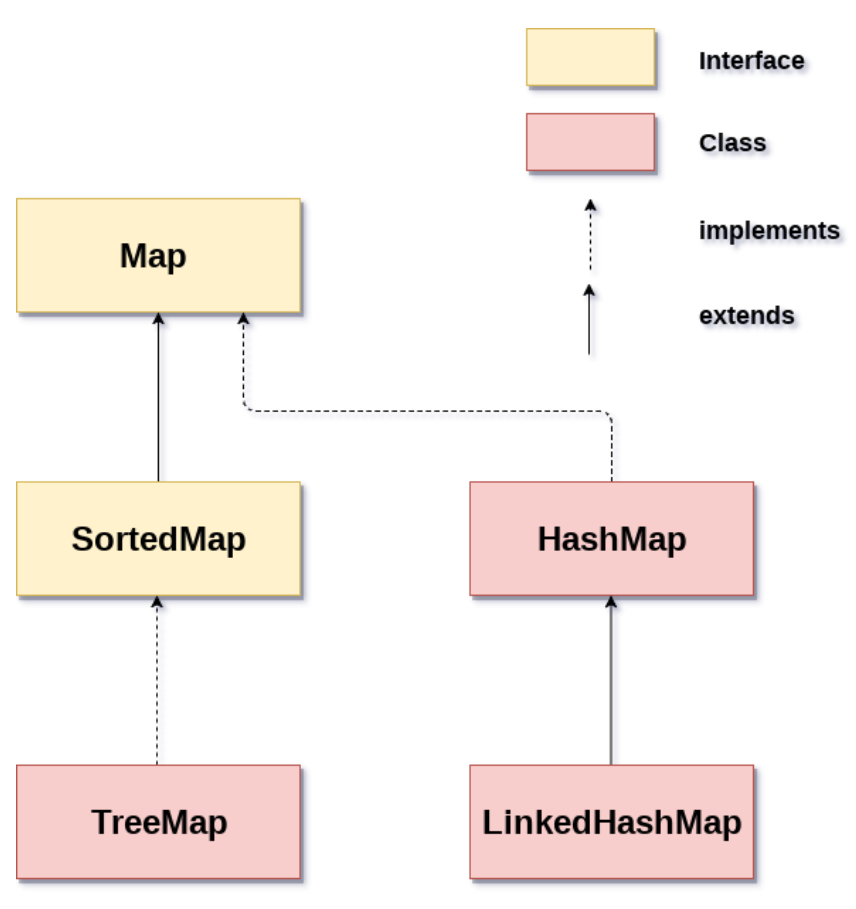
Map 接口中定义了一些双列集合通用的方法:
public V put(K key, V value); // 把指定的键与指定的值添加到 Map 集合中。
public V remove(Object key); // 把指定的键所对应的键值对元素在 Map 集合中删除,返回被删除元素的值。
public V get(Object key); // 根据指定的键,在 Map 集合中获取对应的值。
boolean containsKey(Object key); // 判断集合中是否包含指定的键。
public Set<K> keySet(); // 获取 Map 集合中所有的键,存储到 Set 集合中。
Map 有两个重要的实现类,HashMap 和 LinkedHashMap :
① 「HashMap」:可以说 HashMap 不背到滚瓜烂熟不敢去面试,这里简单说下它的底层结构,后面会开文详细讲解。JDK 1.8 之前 HashMap 底层由数组加链表实现,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的(“拉链法” 解决冲突)。JDK1.8 以后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)时,将链表转化为红黑树,以减少搜索时间(注意:将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树)。
② 「LinkedHashMap」:HashMap 的子类,可以保证元素的存取顺序一致(存进去时候的顺序是多少,取出来的顺序就是多少,不会因为 key 的大小而改变)。
LinkedHashMap 继承自 HashMap,所以它的底层仍然是基于拉链式散列结构,即由数组和链表或红黑树组成。另外,LinkedHashMap 在上面结构的基础上,增加了一条双向链表,使得上面的结构可以保持键值对的插入顺序。同时通过对链表进行相应的操作,实现了访问顺序相关逻辑。
OK,我们已经知道,Map中存放的是两种对象,一种称为 key(键),一种称为 value(值),它俩在 Map 中是一一对应关系,这一对对象又称做 Map 中的一个 「Entry」(项)。Entry 将键值对的对应关系封装成了对象,即键值对对象。Map 中也提供了获取所有 Entry 对象的方法:
public Set<Map.Entry<K,V>> entrySet(); // 获取 Map 中所有的 Entry 对象的集合。
同样的,Map 也提供了获取每一个 Entry 对象中对应键和对应值的方法,这样我们在遍历 Map 集合时,就可以从每一个键值对(Entry)对象中获取对应的键与对应的值了:
public K getKey(); // 获取某个 Entry 对象中的键。
public V getValue(); // 获取某个 Entry 对象中的值。
下面我们结合上述所学,来看看 Map 的两种遍历方式:
1)「遍历方式一:根据 key 找值方式」
获取 Map 中所有的键,由于键是唯一的,所以返回一个 Set 集合存储所有的键。方法提示:
keyset()遍历键的 Set 集合,得到每一个键。
根据键,获取键所对应的值。方法提示:
get(K key)
public static void main(String[] args) {
// 创建 Map 集合对象
HashMap<Integer, String> map = new HashMap<Integer,String>();
// 添加元素到集合
map.put(1, "小五");
map.put(2, "小红");
map.put(3, "小张");
// 获取所有的键 获取键集
Set<Integer> keys = map.keySet();
// 遍历键集 得到 每一个键
for (Integer key : keys) {
// 获取对应值
String value = map.get(key);
System.out.println(key + ":" + value);
}
}
这里面不知道大家有没有注意一个细节,keySet 方法的返回结果是 Set。Map 由于没有实现 Iterable 接口,所以不能直接使用迭代器或者 for each 循环进行遍历,但是转成 Set 之后就可以使用了。至于迭代器是啥请继续往下看。
2)「遍历方式二:键值对方式」
获取 Map 集合中,所有的键值对 (Entry) 对象,以 Set 集合形式返回。方法提示:
entrySet()。遍历包含键值对 (Entry) 对象的 Set 集合,得到每一个键值对 (Entry) 对象。
获取每个 Entry 对象中的键与值。方法提示:
getkey()、getValue()
// 获取所有的 entry 对象
Set<Entry<Integer,String>> entrySet = map.entrySet();
// 遍历得到每一个 entry 对象
for (Entry<Integer, String> entry : entrySet) {
Integer key = entry.getKey();
String value = entry.getValue();
System.out.println(key + ":" + value);
}
3. 迭代器 Iterator
什么是 Iterator
在上一章数组中我们讲过 for each 循环:
for(variable : collection) {
// todo
}
collection 这一表达式必须是一个数组或者是一个实现了 Iterable 接口的类对象。可以看到 Collection 这个接口就继承了 Itreable 接口,所以所有实现了 Collection 接口的集合都可以使用 for each 循环。
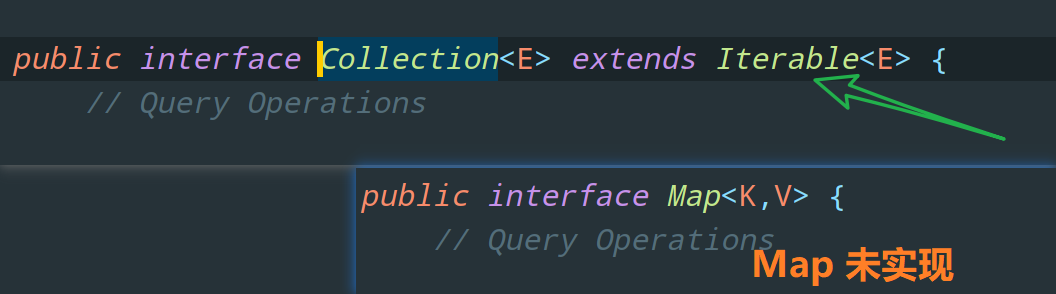
我们点进 Iterable 中看一看:
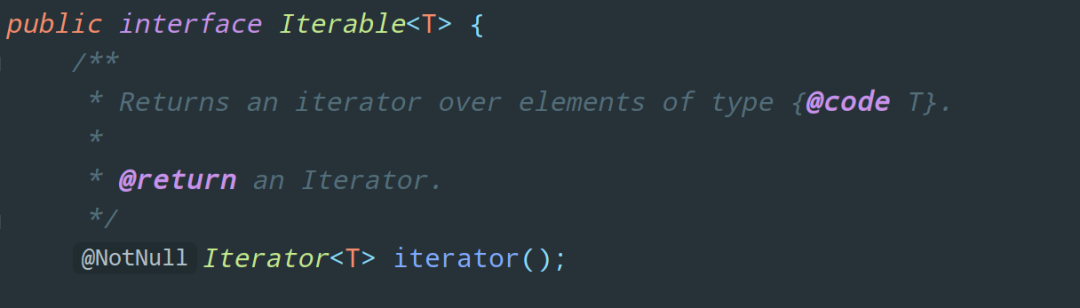
它拥有一个 iterator 方法,返回类型是 Iterator,这又是啥,我们再点进去看看:
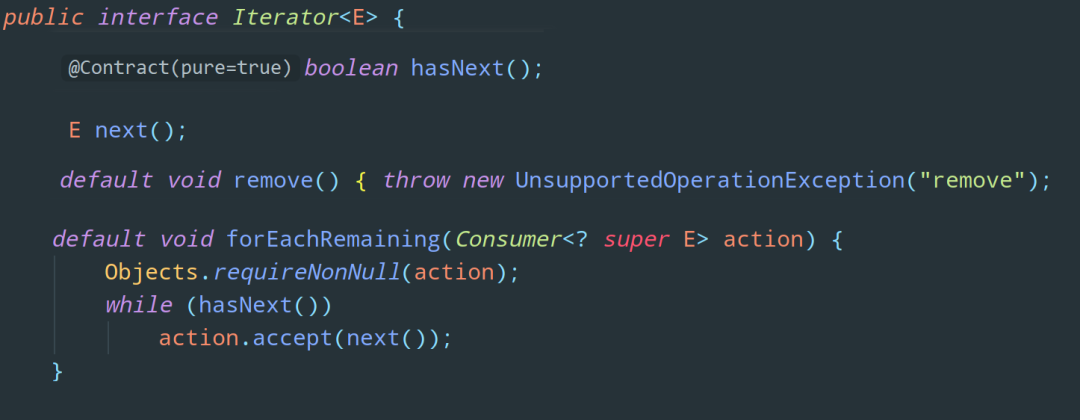
又是三个接口,不过无法再跟下去了,我们去 Collection 的实现类中看看,有没有实现 Itreator 这个接口,随便打开一个,比如 ArrayList :
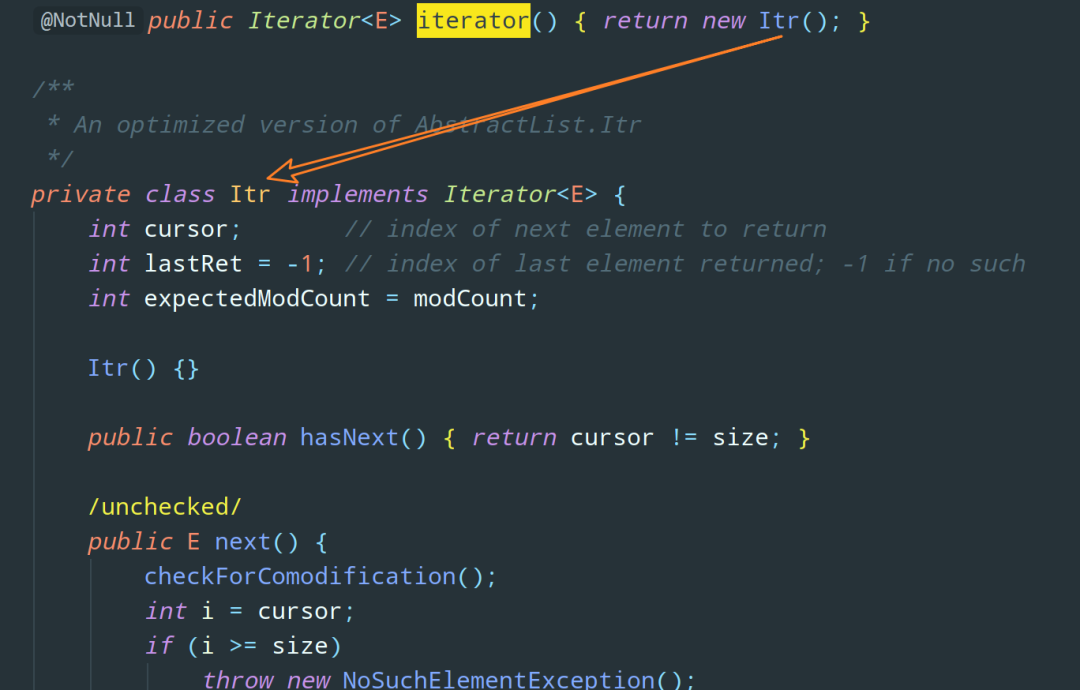
从源码可知:Iterator 接口在 ArrayList 中是以「内部类」的方式实现的。并且,Iterator 实际上就是在遍历集合。
所以总结来说:我们可以通过 Iterator 接口遍历 Collection 的元素,这个接口的具体实现是在具体的子类中,以内部类的方式实现。
❓ 这里提个问题,「为什么迭代器不封装成一个类,而是做成一个接口」?假设迭代器是一个类,这样我们就可以创建该类的对象,调用该类的方法来实现 Collection 的遍历。
但事实上,Collection 接口有很多不同的实现类,在文章开头我们就说过,这些类的底层数据结构大多是不一样的,因此,它们各自的存储方式和遍历方式也是不同的,所以我们不能用一个类来规定死遍历的方法。我们提取出遍历所需要的通用方法,封装进接口中,让 Collection 的子类根据自己自身的特性分别去实现它。
看完上面这段分析,我们来验证一下,看看 LinkedList 实现的 Itreator 接口和 ArrayList 实现的是不是不一样:
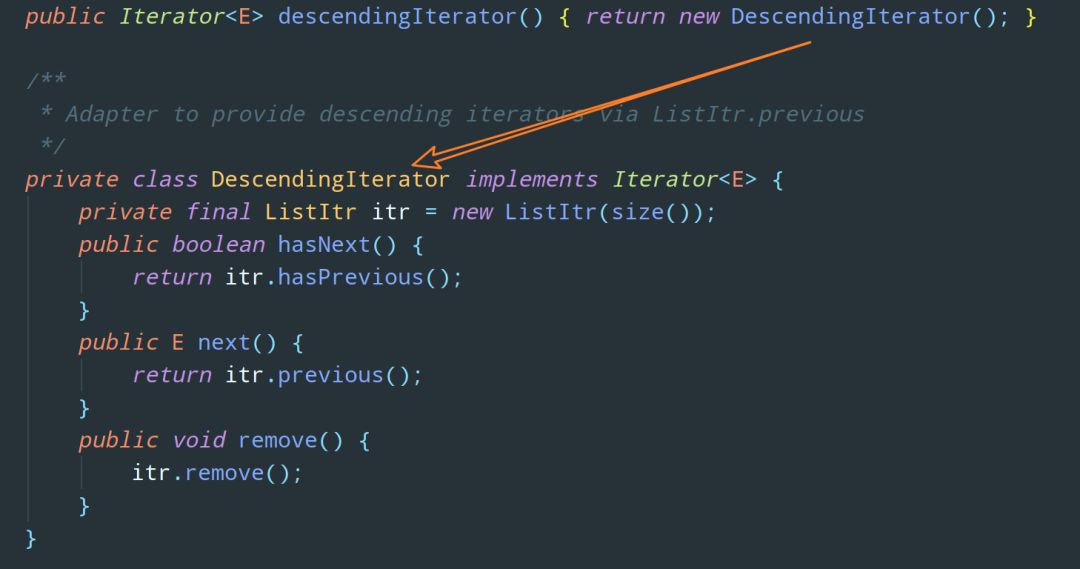
显然,这两个虽然同为 Collection 的实现类,但是它们具体实现 Itreator 接口的内部过程是不一样的。
Iterator 基本使用
OK,我们已经了解了 Iterator 是用来遍历 Collection 集合的,那么具体是怎么遍历的呢?
答:「迭代遍历」!
解释一下迭代的概念:在取元素之前先判断集合中有没有元素,如果有,就把这个元素取出来,再继续判断,如果还有就再继续取出来。一直到把集合中的所有元素全部取出。这种取出方式就称为迭代。因此Iterator 对象也被称为「迭代器」。
也就是说,想要遍历 Collection 集合,那么就要获取该集合对应的迭代器。如何获取呢?其实上文已经出现过了,Collection 实现的 Iterable 中就有这样的一个方法:iterator
再来介绍一下 Iterator 接口中的常用方法:
public E next(); // 返回迭代的下一个元素。
public boolean hasNext(); // 如果仍有元素可以迭代,则返回 true
举个例子:
public static void main(String[] args) {
Collection<String> coll = new ArrayList<String>();
// 添加元素到集合
coll.add("A");
coll.add("B");
coll.add("C");
// 获取 coll 的迭代器
Iterator<String> it = coll.iterator();
while(it.hasNext()){ // 判断是否有迭代元素
String s = it.next(); // 获取迭代出的元素
System.out.println(s);
}
}
当然,用 for each 循环可以更加简单地表示同样的循环操作:
Collection<String> coll = new ArrayList<String>();
...
for(String element : coll){
System.out.println(element);
}
References
《Java 核心技术 - 卷 1 基础知识 - 第 10 版》 Java3y - 集合Collection总览:https://juejin.cn/post/6844903587441541127#heading-1
