
SpringBoot + ShardingSphere 秒级分库分表!
Spring Boot 作为主流微服务框架,拥有成熟的社区生态。市场应用广泛,为了方便大家,整理了一个基于spring boot的常用中间件快速集成入门系列手册,涉及RPC、缓存、消息队列、分库分表、注册中心、分布式配置等常用开源组件,大概有几十篇文章,陆续会开放出来,感兴趣同学请提前关注&收藏
互联网高速发展,同时也带来的海量数据存储问题。传统关系型数据库的单库单表已经很难支撑,如何高效存储和访问这些数据,成为业内急需解决的问题。解决思路有两个方向:
NoSQL数据库,非关系型数据库,天然集成了类似分布式分片的功能,支持海量数据存储,但是不具备事务管理 分库分表,对多个单库单表资源整合,并配备资源调度模块,从而形成一个具有海量数据储存的逻辑表。
今天我们主要介绍,如何基于Springboot快速集成分库分表框架,尽量做到开箱即用
当然除了ShardingSphere之外,还有其他分库分表框架,如:Cobar,MyCat等
ShardingSphere介绍
ShardingSphere 是一套开源的分布式数据库中间件解决方案组成的生态圈,它由 3 款相互独立,却又能够混合部署配合使用的产品组成。它们均提供标准化的数据分片、分布式事务和数据库治理功能
ShardingSphere 由三个子项目组成,形成一个完整的数据库解决方案。
1、ShardingSphere-JDBC:定位为轻量级 Java 框架,在 Java 的 JDBC 层提供额外服务。它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。
适用于任何基于Java的ORM框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template或直接使用JDBC。基于任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP等。支持任意实现JDBC规范的数据库。目前支持MySQL,Oracle,SQLServer和PostgreSQL。
2、ShardingSphere-Proxy:定位为透明化的数据库代理端,提供封装了数据库二进制协议的服务端版本,用于完成对异构语言的支持。目前提供 MySQL/PostgreSQL 版本,它可以使用任何兼容 MySQL/PostgreSQL 协议的访问客户端操作数据,对 DBA 更加友好。
3、ShardingSphere-Sidecar(规划中):定位为 Kubernetes 的云原生数据库代理,以 Sidecar 的形式代理所有对数据库的访问。通过无中心、零侵入的方案提供与数据库交互的的啮合层,即 Database Mesh,又可称数据网格。
优势:
解决方案完备性,它集客户端分片、代理服务器,以及分布式数据库的核心功能于一身。
开发友好性,提供了友好的集成方式,业务开发人员只需要引入一个 JAR 包就能在业务代码中嵌入数据分片、读写分离、分布式事务、数据库治理等一系列功能。
可插拔的系统扩展性:它的很多核心功能均通过插件的形式提供,供开发者排列组合来定制属于自己的独特系统。
项目示例
首先,新建一个工程spring-boot-bulking-sharding-sphere,在pom.xml 文件中添加分库分表的 starter 依赖包
org.apache.shardingsphere
sharding-jdbc-spring-boot-starter
4.0.0-RC1
数据环境准备
分别创建两个数据库ds0、ds1,在ds0数据库中创建 user_0、user_2两张用户表
CREATE TABLE `user_0` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`user_name` varchar(128) NOT NULL DEFAULT '' COMMENT '用户名',
`age` int(11) NOT NULL COMMENT '年龄',
`address` varchar(128) COMMENT '地址',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='用户表';
CREATE TABLE `user_2` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`user_name` varchar(128) NOT NULL DEFAULT '' COMMENT '用户名',
`age` int(11) NOT NULL COMMENT '年龄',
`address` varchar(128) COMMENT '地址',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='用户表';
在ds1数据库中创建 user_1、user_3两张用户表
CREATE TABLE `user_1` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`user_name` varchar(128) NOT NULL DEFAULT '' COMMENT '用户名',
`age` int(11) NOT NULL COMMENT '年龄',
`address` varchar(128) COMMENT '地址',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='用户表';
CREATE TABLE `user_3` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`user_name` varchar(128) NOT NULL DEFAULT '' COMMENT '用户名',
`age` int(11) NOT NULL COMMENT '年龄',
`address` varchar(128) COMMENT '地址',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='用户表';
我们采用Mybatis作为ORM框架,遵循Mybatis的开发流程,首先需要定义业务实体类User,Mapper接口类文件,以及对应的sql语句的xml文件。
@Mapper
public interface UserMapper {
Long addUser(User user);
List queryAllUser();
User queryUserById(Long id);
Page querUserByPage();
}
Spring boot 框架最为闪亮的设计就是约定胜于配置,废弃了之前繁琐的xml形式定义Bean实例,将一系列框架的配置项迁移到 application.properties 中,借助 EnableAutoConfiguration自动完成装载,并实例化相应的Bean实例到 spring 容器中,IOC统一管理。
针对两个数据库初始化两个DataSource对象,这两个 DataSource 对象将组成一个 Map 并传递给ShardingDataSourceFactory 工厂类,application.properties 配置文件:
server.port=8090
application.name=spring-boot-bulking-sharding-sphere
mybatis.config-location=classpath:config/mybatis-config.xml
spring.shardingsphere.datasource.names=ds0,ds1
# 数据源
spring.shardingsphere.datasource.ds0.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds0.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds0.url=jdbc:mysql://localhost:3306/ds0?characterEncoding=utf-8
spring.shardingsphere.datasource.ds0.username=root
spring.shardingsphere.datasource.ds0.password=111111
spring.shardingsphere.datasource.ds1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds1.url=jdbc:mysql://localhost:3306/ds1?characterEncoding=utf-8
spring.shardingsphere.datasource.ds1.username=root
spring.shardingsphere.datasource.ds1.password=111111
搞定数据源后,接下来我们需要设置分库、分表策略。
# 不分表(application.properties没有为表单独配置),默认数据源策略
spring.shardingsphere.sharding.default-data-source-name=ds1
# user表的分表配置
spring.shardingsphere.sharding.tables.user.actual-data-nodes=ds0.user_$->{[0,2]},ds1.user_$->{[1,3]}
# user库策略(也可以采用默认的)
spring.shardingsphere.sharding.tables.user.database-strategy.inline.sharding-column=id
spring.shardingsphere.sharding.tables.user.database-strategy.inline.algorithm-expression=ds$->{id % 2}
# user表策略
spring.shardingsphere.sharding.tables.user.table-strategy.inline.sharding-column=id
spring.shardingsphere.sharding.tables.user.table-strategy.inline.algorithm-expression=user_$->{id % 4}
#spring.shardingsphere.sharding.tables.user.key-generator.column=id
#spring.shardingsphere.sharding.tables.user.key-generator.type=SNOWFLAKE
在 ShardingSphere 中存在一组 ShardingStrategyConfiguration,这里使用的是基于行表达式的 InlineShardingStrategyConfiguration。

InlineShardingStrategyConfiguration包含两个参数,一个是指定分片列名称的 shardingColumn,另一个是指定分片算法行表达式的 algorithmExpression。上面的示例,将基于 id 列对 2 的取模值来确定数据应该存储在哪一个数据库中
我们对user表做了分库分表,拆分成4个表,并分别归属到两个库中。分表键是id字段。
通过单元测试,插入 10条用户记录,验收下数据的插入情况~
@Test
public void addUser() {
for (long i = 1; i < 11; i++) {
User user = User.builder().id(i).userName("TomGE").age(29).address("杭州").build();
userMapper.addUser(user);
System.out.println("插入用户成功,uid=" + user.getId());
}
}
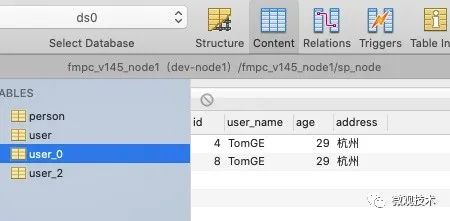
其中id=4,id=8 两条记录,插入到ds0库的user_0表中。
项目源码
https://github.com/aalansehaiyang/spring-boot-bulking
模块:spring-boot-bulking-sharding-sphere
热衷于收集高并发、系统架构、微服务、消息中间件、 RPC框架、高性能缓存、搜索、分布式数据框架、分布式协同服务、分布式配置中心、中台架构、领域驱动设计、系统监控、系统稳定性等技术知识。