
99%的Java程序员会踩的6个坑
大家好,我是3y,又跟大家见面了。
前言
作为Java程序员的你,不知道有没有踩过一些基础知识的坑。
有时候,某个bug,你查了半天,最后发现竟然是一个非常低级的错误。
有时候,某些代码,这一批数据功能正常,但换了一批数据就出现异常了。
有时候,你可能会看着某行代码目瞪口呆,心里想:这行代码为什么会出错?
今天跟大家一起聊聊99%的Java程序员踩过,或者即将踩的6个坑。
1. 用==号比较的坑
不知道你在项目中有没有见过,有些同事对Integer类型的两个参数使用==号比较是否相等?
反正我见过的,那么这种用法对吗?
我的回答是看具体场景,不能说一定对,或不对。
有些状态字段,比如:orderStatus有:-1(未下单),0(已下单),1(已支付),2(已完成),3(取消),5种状态。
这时如果用==判断是否相等:
Integer orderStatus1 = new Integer(1);
Integer orderStatus2 = new Integer(1);
System.out.println(orderStatus1 == orderStatus2);
返回结果会是true吗?
答案:是false。
有些同学可能会反驳,Integer中不是有范围是:-128-127的缓存吗?
为什么是false?
先看看Integer的构造方法:
它其实并没有用到缓存。
那么缓存是在哪里用的?
答案在valueOf方法中:
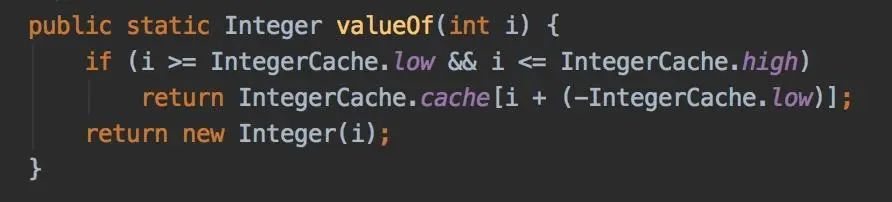
如果上面的判断改成这样:
String orderStatus1 = new String("1");
String orderStatus2 = new String("1");
System.out.println(Integer.valueOf(orderStatus1) == Integer.valueOf(orderStatus2));
返回结果会是true吗?
答案:还真是true。
我们要养成良好编码习惯,尽量少用==判断两个Integer类型数据是否相等,只有在上述非常特殊的场景下才相等。
而应该改成使用equals方法判断:
Integer orderStatus1 = new Integer(1);
Integer orderStatus2 = new Integer(1);
System.out.println(orderStatus1.equals(orderStatus2));
运行结果为true。
2. Objects.equals的坑
假设现在有这样一个需求:判断当前登录的用户,如果是我们指定的系统管理员,则发送一封邮件。系统管理员没有特殊的字段标识,他的用户id=888,在开发、测试、生产环境中该值都是一样的。
这个需求真的太容易实现了:
UserInfo userInfo = CurrentUser.getUserInfo();
if(Objects.isNull(userInfo)) {
log.info("请先登录");
return;
}
if(Objects.equals(userInfo.getId(),888L)) {
sendEmail(userInfo):
}
从当前登录用户的上下文中获取用户信息,判断一下,如果用户信息为空,则直接返回。
如果获取到的用户信息不为空,接下来判断用户id是否等于888。
如果等于888,则发送邮件。 如果不等于888,则啥事也不干。
当我们用id=888的系统管理员账号登录之后,做了相关操作,满怀期待的准备收邮件的时候,却发现收了个寂寞。
后来,发现UserInfo类是这样定义的:
@Data
public class UserInfo {
private Integer id;
private String name;
private Integer age;
private String address;
}
此时,有些小伙伴可能会说:没看出什么问题呀。
但我要说的是这个代码确实有问题。
什么问题呢?
下面我们重点看看它的equals方法:
public static boolean equals(Object a, Object b) {
return (a == b) || (a != null && a.equals(b));
}
equals方法的判断逻辑如下:
该方法先判断对象a和b的引用是否相等,如果相等则直接返回true。 如果引用不相等,则判断a是否为空,如果a为空则返回false。 如果a不为空,调用对象的equals方法进一步判断值是否相等。
这就要从Integer的equals方法说起来了。
它的equals方法具体代码如下:
public boolean equals(Object obj) {
if (obj instanceof Integer) {
return value == ((Integer)obj).intValue();
}
return false;
}
先判断参数obj是否是Integer类型,如果不是,则直接返回false。如果是Integer类型,再进一步判断int值是否相等。
而上面这个例子中b是long类型,所以Integer的equals方法直接返回了false。
也就是说,如果调用了Integer的equals方法,必须要求入参也是Integer类型,否则该方法会直接返回false。
除此之外,还有Byte、Short、Double、Float、Boolean和Character也有类似的equals方法判断逻辑。
常见的坑有:
Long类型和Integer类型比较,比如:用户id的场景。 Byte类型和Integer类型比较,比如:状态判断的场景。 Double类型和Integer类型比较,比如:金额为0的判断场景。
如果你想进一步了解Objects.equals方法的问题,可以看看我的另一篇文章《Objects.equals有坑》。
3. BigDecimal的坑
通常我们会把一些小数类型的字段(比如:金额),定义成BigDecimal,而不是Double,避免丢失精度问题。
使用Double时可能会有这种场景:
double amount1 = 0.02;
double amount2 = 0.03;
System.out.println(amount2 - amount1);
正常情况下预计amount2 - amount1应该等于0.01
但是执行结果,却为:
0.009999999999999998
实际结果小于预计结果。
Double类型的两个参数相减会转换成二进制,因为Double有效位数为16位这就会出现存储小数位数不够的情况,这种情况下就会出现误差。
常识告诉我们使用BigDecimal能避免丢失精度。
但是使用BigDecimal能避免丢失精度吗?
答案是否定的。
为什么?
BigDecimal amount1 = new BigDecimal(0.02);
BigDecimal amount2 = new BigDecimal(0.03);
System.out.println(amount2.subtract(amount1));
这个例子中定义了两个BigDecimal类型参数,使用构造函数初始化数据,然后打印两个参数相减后的值。
结果:
0.0099999999999999984734433411404097569175064563751220703125
不科学呀,为啥还是丢失精度了?
Jdk中BigDecimal的构造方法上有这样一段描述:
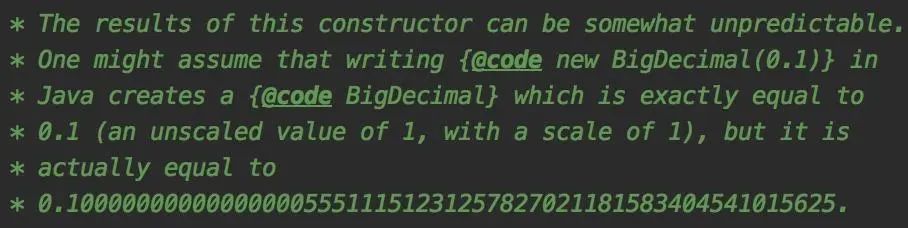
大致的意思是此构造函数的结果可能不可预测,可能会出现创建时为0.1,但实际是0.1000000000000000055511151231257827021181583404541015625的情况。
由此可见,使用BigDecimal构造函数初始化对象,也会丢失精度。
那么,如何才能不丢失精度呢?
BigDecimal amount1 = new BigDecimal(Double.toString(0.02));
BigDecimal amount2 = new BigDecimal(Double.toString(0.03));
System.out.println(amount2.subtract(amount1));
我们可以使用Double.toString方法,对double类型的小数进行转换,这样能保证精度不丢失。
其实,还有更好的办法:
BigDecimal amount1 = BigDecimal.valueOf(0.02);
BigDecimal amount2 = BigDecimal.valueOf(0.03);
System.out.println(amount2.subtract(amount1));
使用BigDecimal.valueOf方法初始化BigDecimal类型参数,也能保证精度不丢失。在新版的阿里巴巴开发手册中,也推荐使用这种方式创建BigDecimal参数。
4. Java8 filter的坑
对于Java8中的Stream用法,大家肯定再熟悉不过了。
我们通过对集合的Stream操作,可以实现:遍历集合、过滤数据、排序、判断、转换集合等等,N多功能。
这里重点说说数据的过滤。
在没有Java8之前,我们过滤数据一般是这样做的:
public List<User> filterUser(List<User> userList) {
if(CollectionUtils.isEmpty(userList)) {
return Collections.emptyList();
}
List<User> resultList = Lists.newArrayList();
for(User user: userList) {
if(user.getId() > 1000 && user.getAge() > 18) {
resultList.add(user);
}
}
return resultList;
}
通常需要另一个集合辅助完成这个功能。
但如果使用Java8的filter功能,代码会变得简洁很多,例如:
public List<User> filterUser(List<User> userList) {
if(CollectionUtils.isEmpty(userList)) {
return Collections.emptyList();
}
return userList.stream()
.filter(user -> user.getId() > 1000 && user.getAge() > 18)
.collect(Collectors.toList());
}
代码简化了很多,完美。
但如果你对过滤后的数据,做修改了:
List<User> userList = queryUser();
List<User> filterList = filterUser(userList);
for(User user: filterList) {
user.setName(user.getName() + "测试");
}
for(User user: userList) {
System.out.println(user.getName());
}
你当时可能只是想修改过滤后的数据,但实际上,你会把元素数据一同修改了。
意不意外,惊不惊喜?
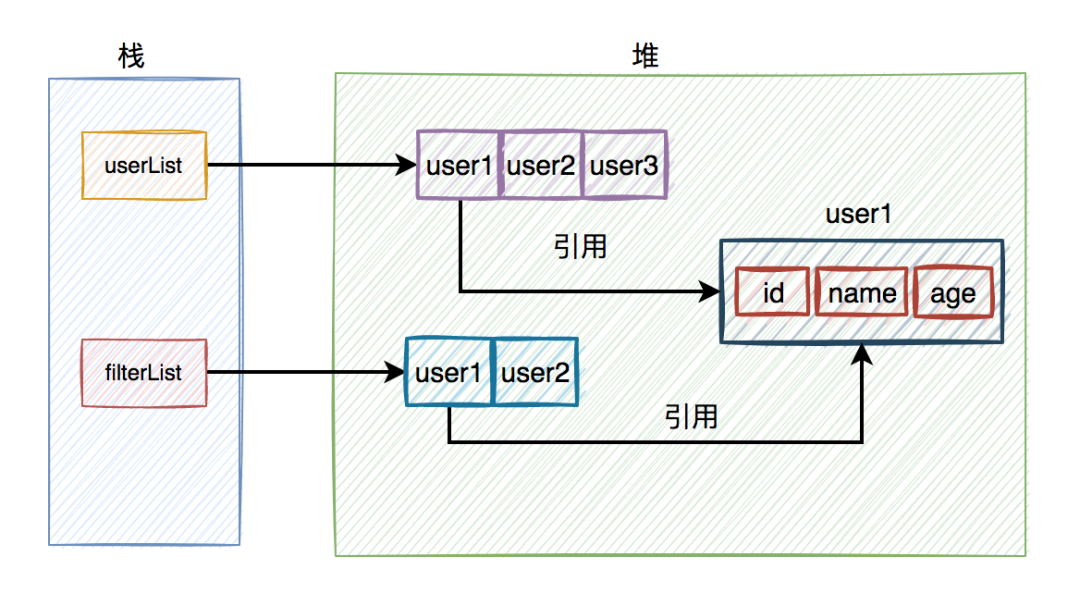
其根本原因是:过滤后的集合中,保存的是对象的引用,该引用只有一份数据。
也就是说,只要有一个地方,把该引用对象的成员变量的值,做修改了,其他地方也会同步修改。
如下图所示:
5. 自动拆箱的坑
Java5之后,提供了自动装箱和自动拆箱的功能。
自动装箱是指:JDK会把基本类型,自动变成包装类型。
比如:
Integer integer = 1;
等价于:
Integer integer = new Integer(1);
而自动拆箱是指:JDK会把包装类型,自动转换成基本类型。
例如:
Integer integer = new Integer(2);
int sum = integer + 5;
等价于:
Integer integer = new Integer(2);
int sum = integer.intValue() + 5;
但实际工作中,我们在使用自动拆箱时,往往忘记了判空,导致出现NullPointerException异常。
5.1 运算
很多时候,我们需要对传入的数据进行计算,例如:
public class Test2 {
public static void main(String[] args) {
System.out.println(add(new Integer(1), new Integer(2)));
}
private static Integer add(Integer a, Integer b) {
return a + b;
}
}
如果传入了null值:
System.out.println(add(null, new Integer(2)));
则会直接报错。
5.2 传参
有时候,我们定义的某个方法是基本类型,但实际上传入了包装类,比如:
public static void main(String[] args) {
Integer a = new Integer(1);
Integer b = null;
System.out.println(add(a, b));
}
private static Integer add(int a, int b) {
return a + b;
}
如果出现add方法报NullPointerException异常,你可能会懵逼,int类型怎么会出现空指针异常呢?
其实,这个问题出在:Integer类型的参数,其实际传入值为null,JDK字段拆箱,调用了它的intValue方法导致的问题。
6. replace的坑
很多时候我们在使用字符串时,想把字符串比如:ATYSDFA*Y中的字符A替换成字符B,第一个想到的可能是使用replace方法。
如果想把所有的A都替换成B,很显然可以用replaceAll方法,因为非常直观,光从方法名就能猜出它的用途。
那么问题来了:replace方法会替换所有匹配字符吗?
jdk的官方给出了答案。
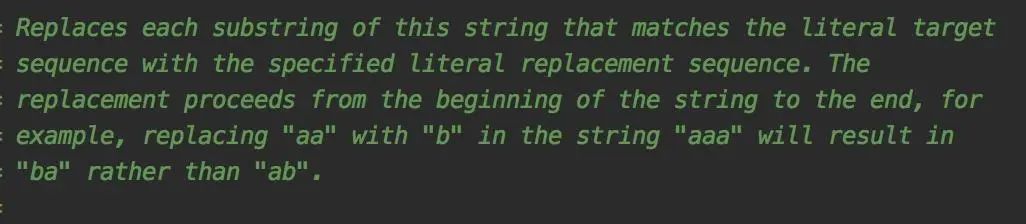
该方法会替换每一个匹配的字符串。
既然replace和replaceAll都能替换所有匹配字符,那么他们有啥区别呢?
replace有两个重载的方法。
其中一个方法的参数:char oldChar 和 char newChar,支持字符的替换。
source.replace('A', 'B')
另一个方法的参数是:CharSequence target 和 CharSequence replacement,支持字符串的替换。
source.replace("A", "B")
而replaceAll方法的参数是:String regex 和 String replacement,即基于正则表达式的替换。
例如对普通字符串进行替换:
source.replaceAll("A", "B")
使用正则表达替换(将*替换成C):
source.replaceAll("\\*", "C")
顺便说一下,将*替换成C使用replace方法也可以实现:
source.replace("*", "C")
小伙们看到看到二者的区别了没?使用replace方法无需对特殊字符进行转义。
不过,千万注意,切勿使用如下写法:
source.replace("\\*", "C")
这种写法会导致字符串无法替换。
还有个小问题,如果我只想替换第一个匹配的字符串该怎么办?
这时可以使用replaceFirst方法:
source.replaceFirst("A", "B")
说实话,这里内容都很基础,但越基础的东西,越容易大意失荆州,更容易踩坑。
最后,统计一下,这些坑一个都没踩过的同学,麻烦举个手。
最后说一句(求关注,别白嫖我)
如果这篇文章对您有所帮助,或者有所启发的话,帮忙关注一下,您的支持是我坚持写作最大的动力。
 最近我开通了
最近我开通了阅读原文可跳转至消息推送平台仓库