
StampedLock——比读写锁更快的锁
“ 写给自己看,说给别人听。你好,这是think123的第84篇原创文章”
简介
ReentrantReadWriteLock支持读写锁,StampedLock支持写锁、悲观锁读和乐观读(无锁)。
其中写锁、悲观读锁的语义和ReentrantReadWriteLock中的写锁、读锁语义一样,都是允许多个线程同时获取悲观锁读,但是只允许一个线程获取写锁,写锁和悲观读锁是互斥的。
不同的是:StampedLock 里的写锁和悲观读锁加锁成功之后,都会返回一个 stamp;然后解锁的时候,需要传入这个 stamp。
以下为官方使用例子
public class Point {
private final StampedLock sl = new StampedLock();
private double x, y;
void move(double deltaX, double deltaY) {
long stamp = sl.writeLock();
try {
x += deltaX;
y += deltaY;
} finally {
sl.unlockWrite(stamp);
}
}
double distanceFromOrigin() {
long stamp = sl.tryOptimisticRead();
double currentX = x, currentY = y;
if (!sl.validate(stamp)) {
stamp = sl.readLock();
try {
currentX = x;
currentY = y;
} finally {
sl.unlockRead(stamp);
}
}
// 如果处理业务需要保持互斥,那么就用互斥锁,如果不需要保持互斥才可以
// 用读写锁。一般来讲缓存是不需要保持互斥性的,能接受瞬间的不一致
return Math.sqrt(currentX * currentX + currentY * currentY);
}
// StampedLock 支持锁的降级(通过 tryConvertToReadLock()方法)
// 升级(通过tryConvertToWriteLock()方法)
void moveIfAtOrigin(double newX, double newY) {
long stamp = sl.readLock();
try {
while (x == 0.0 && y == 0.0) {
long ws = sl.tryConvertToWriteLock(stamp);
if (ws != 0L) {
stamp = ws;
x = newX;
y = newY;
break;
} else {
sl.unlockRead(stamp);
stamp = sl.writeLock();
}
}
} finally {
sl.unlock(stamp);
}
}
}
主要数据结构
虽然StampedLock没有使用AQS,不过它的数据结构中还是用到了CLH队列。
WNode是CLH队列的节点,其源码如下
static final class WNode {
// 前驱节点
volatile WNode prev;
// 后继节点
volatile WNode next;
// 获取读锁的列表
volatile WNode cowait;
// 线程
volatile Thread thread;
// 节点状态。0, WAITING, or CANCELLED
volatile int status;
// 读模式或者写模式。RMODE or WMODE
final int mode;
WNode(int m, WNode p) { mode = m; prev = p; }
}
StampedLock中其中重要属性如下
//CLH队列头结点
private transient volatile WNode whead;
// CLH队列尾节点
private transient volatile WNode wtail;
// 锁状态
private transient volatile long state;
// 读锁次数的额外计数器
private transient int readerOverflow;
// 读锁的位数
private static final int LG_READERS = 7;
// 计算state值常量
private static final long RUNIT = 1L;
// 写锁标志位,十进制:128 二进制:1000 0000
private static final long WBIT = 1L << LG_READERS;
// 读状态标志位。 十进制:127 二进制: 0111 1111
private static final long RBITS = WBIT - 1L;
// state状态中记录读锁快满了的值,126
private static final long RFULL = RBITS - 1L;
// 用来获取读写状态。 十进制:255 二进制:1111 1111
private static final long ABITS = RBITS | WBIT;
// -128 (1....1 1000 0000)
private static final long SBITS = ~RBITS;
// 状态state的初始值 256 二进制: 00001 0000 0000
private static final long ORIGIN = WBIT << 1;
// 锁的状态。使用state来控制当前是读锁,还是写锁
private transient volatile long state;
// 额外的读锁计数器
private transient int readerOverflow;
// state初始值为256
public StampedLock() {
state = ORIGIN;
}
看过我之前分析AQS源码的应该对这个CLH很熟悉了。同样的StampedLock也是通过这个stae变量来进行读写锁判断的。这个state承载了三个部分的内容
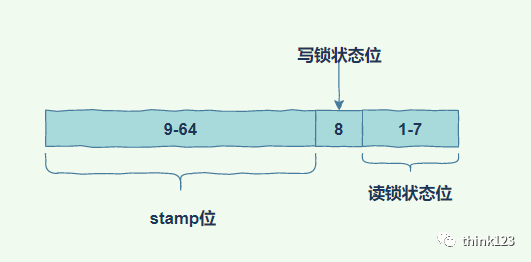
StampedLock中state是long类型,占64位,它被划为了三个部分来使用。低7位作为读锁标志位,可以由多个线程共享,每有一个线程申请读锁成功,低7位就加1。第8位是写锁位,由线程独占。
其余位是stamp位,用来记录写锁状态的变化(版本号),每使用一次写锁,stamp位就会加1。
同时如果读锁数量超过了126之后,超出的次数使用readerOverflow来进行计数。
当出现并发的情况的时候,CLH队列的排队情况是怎样的呢?
比如,线程w1获取了写锁,一直未释放。此时有4个线程分别获取读锁(获取顺序是R0-->R1-->R2-->R3),又有线程W2获取写锁,最后还有R4,R5,R6三个线程获取读锁,那么此时队列的排队情况如下
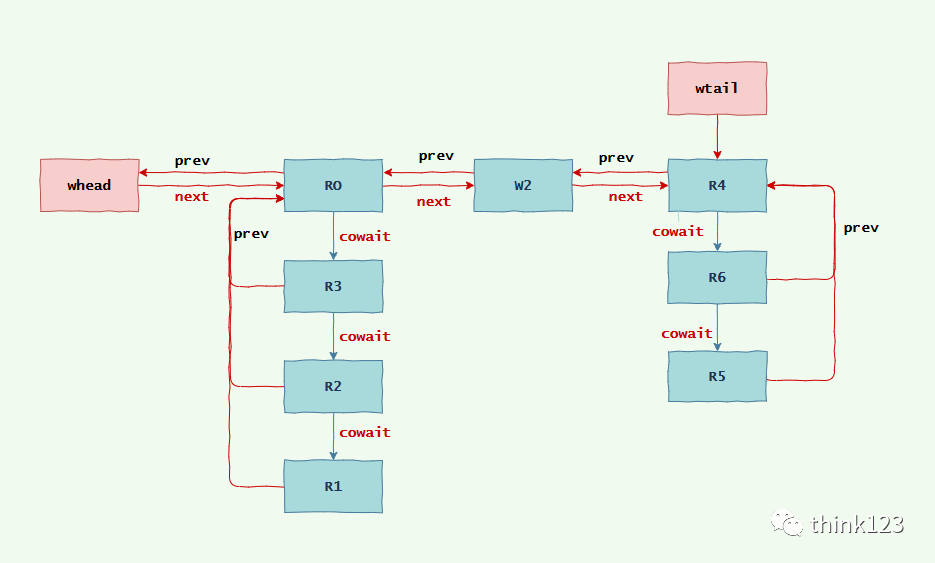
因为读锁是可以被多个线程获取的,如果同一时间有多个线程来获取读锁却获取不到时,这个时候第一个获取读锁的线程会被加入到链表中,而后面的的读线程会被加入到cowait栈中,
可以认为cowait是一条副链。
这里的cowait可以理解为协同等待,表示将这些获取读锁的线程作为一个整体来获取锁。
获取乐观读锁
public long tryOptimisticRead() {
long s;
return (((s = state) & WBIT) == 0L) ? (s & SBITS) : 0L;
}
乐观读锁逻辑比较简单,就是判断写锁是否被占用(判断state第8位的值是否为1),如果写锁被占用则返回0,否则返回stamp位。
state初始值为256(1 0000 0000)
01000 0000(WBIT)
& 10000 0000(state)
==============
00000 0000
1 0000 0000(state)
1 1000 0000(SBITS)
==============
1 0000 0000
检测乐观读锁
public boolean validate(long stamp) {
// 通过UNSafe插入内存屏障,禁止重排序
U.loadFence();
return (stamp & SBITS) == (state & SBITS);
}
返回true: 表示期间没有写锁,不关心读锁。
返回false: 表示期间有写锁发生
SBITS为-128,用二进制表示是:1111 1111 1111 1000 0000
x xxxx xxxx(stamp)
1 1000 0000
1 yyyy yyyy(state)
1 1000 0000
SBITS后7位都是0,也就是不关心读锁,我们只关心stamp位和写位。
当我们获取乐观读时,如果此时已经有了写锁,那么返回stamp值为0,此时进行验证肯定为false。
获取普通读锁
public long readLock() {
long s = state, next;
// whead == wtail时,队列为空,表示当前没有线程在排队
return ((whead == wtail && (s & ABITS) < RFULL &&
U.compareAndSwapLong(this, STATE, s, next = s + RUNIT)) ?
// acquireRead的第一个参数为false,标识不处理线程中断
next : acquireRead(false, 0L));
}
当获取读锁成功时,会将state值加1。当条件不满足时(队列不为空,CAS失败,或者读锁的个数已经大于等于126),都会进入到acquireRead()方法,这个方法主要分为两个大的for循环,代码比较长我就不贴出来了。
它的主要逻辑如下:
如果当前队列没有排队的线程,该线程是第一个准备排队的元素,就有很大机会获取到锁,所以会先自旋尝试获取到锁(自旋次数为64),如果获取到了将state值加1,如果读锁次数已经超出了126,则使用readerOverflow记录超出的读锁数目。如果未获取到锁,则进入第2步
private long tryIncReaderOverflow(long s) {
// 如果读锁的记录数等于126,
if ((s & ABITS) == RFULL) {
// 将state的值加1
// CAS之后state的后七位的值是127,state的整个值是383(1 0111 1111)。
if (U.compareAndSwapLong(this, STATE, s, s | RBITS)) {
// 将readOverflow的值加1
++readerOverflow;
state = s;
return s;
}
}
else if ((LockSupport.nextSecondarySeed() &
OVERFLOW_YIELD_RATE) == 0)
Thread.yield();
return 0L;
}
初始化入队排队节点,形成链表关系。和AQS一样的是head节点被当成哨兵节点或者正持有锁正在运行的线程(虚拟)。所以head节点的thread为null,mode的值为WMODE。这样会形成
head --> node <-- tail这样的节点关系如果又有新的线程获取读锁失败,会将新的线程加入到cowait栈中
对于不是第一个获取读锁的线程,它会先加入到cowait这个栈中,然后再通过CAS获取锁,如果获取失败就被阻塞,等待被唤醒或者由于超时中断被取消。
会对第一个获取读锁的线程进行优待,因为它前面没有在排队的线程,所以这一层还是在自旋获取锁,只是自旋次数再增加,首先会自旋1024次获得锁,如果还未获取到,在自旋2048次。
如果还未等到锁释放,就阻塞当前线程,等待被唤醒,直到获得锁或者超时中断被取消。
第1-4步属于一个大的循环,第5步骤属于另外一个大的循环。
同时当获取读锁线程被唤醒获取到锁后,它同时也会唤醒挂在它身上的cowait栈中的线程。
从分析中可以看到StampedLock中通过大量的自旋操作可以一定程度避免线程阻塞,只要线程执行操作够快,释放锁比较及时,可以说几乎不会存在阻塞。
释放读锁
释放读锁的代码比较简单,主要操作如下
首先判断stamp是否合法,如果不合法则抛出 IllegalMonitorStateException异常如果读锁个数小于126,则通过CAS将state值减去1,如果释放的是最后一个读锁,则需要唤醒队列中的节点。 如果读锁个数已经溢出了,则将readerOverflow减去1
public void unlockRead(long stamp) {
long s, m; WNode h;
// 自旋
for (;;) {
// 判断stamp是否合法
if (((s = state) & SBITS) != (stamp & SBITS) ||
(stamp & ABITS) == 0L || (m = s & ABITS) == 0L || m == WBIT)
throw new IllegalMonitorStateException();
// 读锁个数小于126
if (m < RFULL) {
if (U.compareAndSwapLong(this, STATE, s, s - RUNIT)) {
// 释放最后一个读锁时,需要唤醒下一个节点
if (m == RUNIT && (h = whead) != null && h.status != 0)
release(h);
break;
}
}
// 读锁个数饱和溢出,需要减少readerOverflow
else if (tryDecReaderOverflow(s) != 0L)
break;
}
}
获取写锁
public long writeLock() {
long s, next;
return ((((s = state) & ABITS) == 0L &&
U.compareAndSwapLong(this, STATE, s, next = s + WBIT)) ?
next : acquireWrite(false, 0L));
}
如果state中的第8位等于0并且CAS设置state值成功,则获取锁成功,否则进入到acquireWrite方法。
acquireWrite的逻辑也分为两部分,分别是两个for循环。
第一个for循环逻辑如下
for (int spins = -1;;) { // spin while enqueuing
long m, s, ns;
// 如果当前写锁标志位仍然为0,即没有其他线程获取到写锁
if ((m = (s = state) & ABITS) == 0L) {
// CAS将state的值加128,实质是将写锁状态位加1
if (U.compareAndSwapLong(this, STATE, s, ns = s + WBIT))
return ns;
}
// 其他线程获取到了写锁,则设定自旋次数为64次
else if (spins < 0)
spins = (m == WBIT && wtail == whead) ? SPINS : 0;
else if (spins > 0) {
// 随机减少自旋次数
if (LockSupport.nextSecondarySeed() >= 0)
--spins;
}
// 自旋仍未获取到写锁则执行下面的逻辑
// 初始化CLH队列(主要是whead,wtail节点)
// p指向了wtail节点
else if ((p = wtail) == null) {
WNode hd = new WNode(WMODE, null);
if (U.compareAndSwapObject(this, WHEAD, null, hd))
wtail = hd;
}
// 初始化节点
else if (node == null)
node = new WNode(WMODE, p);
// 最终形成 whead --> node <-- wtail
else if (node.prev != p)
node.prev = p;
else if (U.compareAndSwapObject(this, WTAIL, p, node)) {
p.next = node;
// 形成链表关系之后自旋结束
break;
}
}
第二个for循环代码也比较长,我就不贴出来了。它的核心逻辑如下
如果仍然只有当前线程在等待锁,则会先自旋1024次去获取写锁,如果获取失败,则在自旋2048次再次去获取。如果都获取失败,则进入第二步。
阻塞当前线程等待被唤醒
释放写锁
public void unlockWrite(long stamp) {
WNode h;
// 验证stamp是否合法
if (state != stamp || (stamp & WBIT) == 0L)
throw new IllegalMonitorStateException();
// 释放写锁,stamp位(版本号)加1
// stamp+WBIT会将state的第8位置为0,就相当于释放了写锁
state = (stamp += WBIT) == 0L ? ORIGIN : stamp;
// 如果头结点不为空,并且状态不为0,,则调用release方法唤醒下一个节点
if ((h = whead) != null && h.status != 0)
release(h);
}
private void release(WNode h) {
if (h != null) {
WNode q; Thread w;
U.compareAndSwapInt(h, WSTATUS, WAITING, 0);
// 如果头结点的下一个节点为空或者其状态为已取消
if ((q = h.next) == null || q.status == CANCELLED) {
// 从尾结点向前遍历找到可用节点
for (WNode t = wtail; t != null && t != h; t = t.prev)
if (t.status <= 0)
q = t;
}
// 唤醒q节点所在的线程
if (q != null && (w = q.thread) != null)
U.unpark(w);
}
}
释放写锁过程总结如下
将state的第8位置为0(释放写锁),并将stamp位(version)加1 唤醒下一个节点
锁的降级(tryConvertToReadLock)
tryConvertToReadLock方法可以用于锁的降级。不过并不是只有再获取读锁时才能调用该方法。
public long tryConvertToReadLock(long stamp) {
// a为锁标识,m则是最新的锁标识
long a = stamp & ABITS, m, s, next; WNode h;
// state的写锁标志位和版本号一致(有可能写锁标志位是0,即可能是读锁)
while (((s = state) & SBITS) == (stamp & SBITS)) {
// 还未添加任何锁标识
if ((m = s & ABITS) == 0L) {
if (a != 0L)
break;
// 读锁次数小于126
else if (m < RFULL) {
// 将state的值加1
if (U.compareAndSwapLong(this, STATE, s, next = s + RUNIT))
return next;
}
// 读锁次数已经超出了,使用额外字段记录
else if ((next = tryIncReaderOverflow(s)) != 0L)
return next;
}
// 当前是写锁状态
else if (m == WBIT) {
if (a != m)
break;
// 将读锁次数加1,写锁标志置为0,stamp位加1。即加129
state = next = s + (WBIT + RUNIT);
// 释放锁
if ((h = whead) != null && h.status != 0)
release(h);
return next;
}
// 已经是读锁了直接返回
else if (a != 0L && a < WBIT)
return stamp;
else
break;
}
// 转换失败
return 0L;
}
它的主要逻辑如下,如果当前线程还未加任何锁,则加上写锁并返回最新的stamp值。如果当前线程已经是写锁,则释放写锁,并更新state的值(读锁加1,写锁状态为置为0,version加1)。
如果当前线程是读锁则直接返回stamp值。如果上面条件都不满足,则转换失败。
锁的升级(tryConvertToWriteLock)
public long tryConvertToWriteLock(long stamp) {
long a = stamp & ABITS, m, s, next;
// state的写锁标志位和版本号一致(有可能写锁标志位是0,即可能是读锁)
while (((s = state) & SBITS) == (stamp & SBITS)) {
// 还未添加任何锁标识
if ((m = s & ABITS) == 0L) {
if (a != 0L)
break;
// 将写锁状态位置为0
if (U.compareAndSwapLong(this, STATE, s, next = s + WBIT))
return next;
}
// 如果当前已经是写锁状态,则直接返回
else if (m == WBIT) {
if (a != m)
break;
return stamp;
}
// 如果当前是唯一读锁,则转换为写锁
else if (m == RUNIT && a != 0L) {
if (U.compareAndSwapLong(this, STATE, s,
next = s - RUNIT + WBIT))
return next;
}
else
break;
}
return 0L;
}
锁的升级和锁的降级的逻辑类似,这里就不再读过介绍了。
总结以及注意
StampedLock没有使用AQS,而是依靠自己实现的同步状态(long state占64位)和变异的CLH队列
StampedLock使用state的低7位标识读锁数量(超出126的使用readerOverflow字段记录),第8位标识写锁,高56位记录锁的版本,每次释放/获取写锁版本号都会加1
StampedLock中读锁和读锁不阻塞,读锁写锁相互阻塞,写锁和写锁也相互阻塞
StampedLock的连续多个读锁线程,只有第一个是在CLH队列中,后面的会挂在第一个线程的cowait栈中
StampedLock唤醒第一个读线程后,读线程会唤醒它cowait栈的所有读线程(acquireRead()方法中)
StampedLock不支持公平锁,也不支持Condition
StampedLock支持锁的降级和锁的升级
StampedLock中的乐观读操作是无锁的
StampedLock中使用了大量的自旋+CAS操作,适合持有锁时间比较短的任务,持有锁时间长的话不仅会浪费CPU而且仍然会阻塞自己。
线程阻塞在 StampedLock 的 readLock() 或者 writeLock() 上时,此时调用该阻塞线程的 interrupt() 方法,会导致 CPU 飙升。所以,使用 StampedLock 一定不要调用中断操作,如果需要支持中断功能,一定使用可中断的悲观读锁 readLockInterruptibly() 和写锁 writeLockInterruptibly()