
没忍住!49 个代码优化小技巧
大家好,我是二哥呀!
工作了很多年,看过很多思考不够深入的代码,有些甚至会让我萌生这样的想法,“咦,代码怎么可以这样写啊!太糟糕了。”结果再往后看,发现原来是自己写的,哈哈哈 😁。
刚好一个读者田螺给我投稿了一篇文章,里面包含了 49 条建议,我看完后,深表佩服,所以就给大家分享一下啦,希望能给大家一些启发和帮助~~~
以下是正文。
1. 仅用来判断是否存在时,select count 比 select 具体的列,更好。
我们经常遇到类似的业务场景,如,判断某个用户userId是否是会员。
(反例): 一些小伙伴会这样实现,先从用户信息表查出用户记录,然后再去判断是否是会员:
<select id="selectUserByUserId" resultMap="BaseResultMap">
selct user_id , vip_flag from user_info where user_id =#{userId} and vip_flag ='Y';
</select>
boolean isVip (String userId){
UserInfo userInfo = userInfoDAp.selectUserByUserId(userId);
return UserInfo!=null ;
}
(正例): 针对这种业务场景,其实更好的实现,是直接select count一下或者select limit 1,如下:
<select id="countVipUserByUserId" resultType="java.lang.Integer">
selct count(1) from user_info where user_id =#{userId} and vip_flag ='Y';
</select>
boolean isVip (String userId){
int vipNum = userInfoDAp.countVipUserByUserId(userId);
return vipNum>0
}
2. 复杂的 if 逻辑条件,可以调整顺序,让程序更高效
假设业务需求是这样:如果用户是会员,并且第一次登陆时,需要发一条通知的短信。假如没有经过思考,代码很可能直接这样写了。
if(isUserVip && isFirstLogin){
sendMsgNotify();
}
假设总共有 5 个请求进来,isUserVip 通过的有 3 个请求,isFirstLogin 通过的有 1 个请求。那么以上代码,isUserVip 执行的次数为 5 次,isFirstLogin 执行的次数也是 3 次,如下:

如果调整一下 isUserVip 和 isFirstLogin 的顺序呢?
if(isFirstLogin && isUserVip ){
sendMsg();
}
isFirstLogin 执行的次数是 5 次,isUserVip 执行的次数是 1 次,如下:
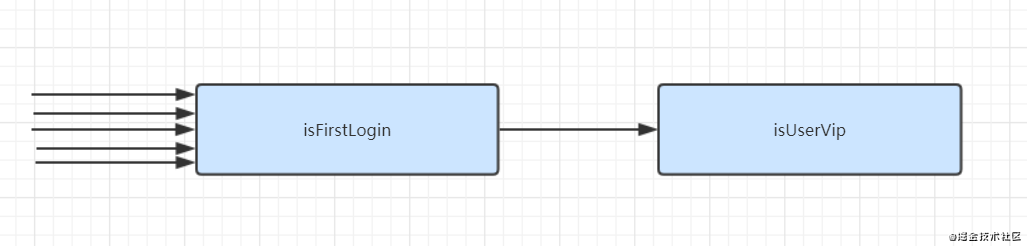
如果你的 isFirstLogin,判断逻辑只是 select count 一下数据库表,isUserVip 也是 select count 一下数据库表的话,显然,把 isFirstLogin 放在前面更高效。
3. 写查询 Sql 的时候,只查你需要用到的字段,还有通用的字段,拒绝反手的 select *
反例:
select * from user_info where user_id =#{userId};
正例:
select user_id , vip_flag from user_info where user_id =#{userId};
理由:
节省资源、减少网络开销。 可能用到覆盖索引,减少回表,提高查询效率。
4. 优化你的程序,拒绝创建不必要的对象
如果你的变量,后面的逻辑判断,一定会被赋值;或者说,只是一个字符串变量,直接初始化字符串常量就可以了,没有必要愣是要 new String().
反例:
String s = new String ("好好学习,天天向上");
正例:
String s= "好好学习,天天向上”;
5. 初始化集合时,指定容量
阿里的开发手册,也明确提到这个点:

假设你的 map 要存储的元素个数是 15 个左右,最优写法如下
//initialCapacity = 15/0.75+1=21
Map map = new HashMap(21);
又因为hashMap的容量跟2的幂有关,所以可以取32的容量
Map map = new HashMap(32);
6.catch 了异常,需要打印出具体的 exception,方便更好定位问题
反例:
try{
// do something
}catch(Exception e){
log.info("兄弟,你的程序有异常啦");
}
正例:
try{
// do something
}catch(Exception e){
log.info("兄弟,你的程序有异常啦:",e); //把exception打印出来
}
理由:
反例中,并没有把 exception 出来,到时候排查问题就不好查了啦,到底是 SQl 写错的异常还是 IO 异常,还是其他呢?所以应该把 exception 打印到日志中哦~
7. 打印日志的时候,对象没有覆盖 Object 的 toString 的方法,直接把类名打印出来了。
我们在打印日志的时候,经常想看下一个请求参数对象 request 是什么。于是很容易有类似以下这些代码:
publick Response dealWithRequest(Request request){
log.info("请求参数是:".request.toString)
}
打印结果如下:
请求参数是:local.Request@49476842
这是因为对象的 toString 方法,默认的实现是“类名@散列码的无符号十六进制”。所以你看吧,这样子打印日志就没啥意思啦,你都不知道打印的是什么内容。
所以一般对象(尤其作为传参的对象),都覆盖重写 toString()方法:
class Request {
private String age;
private String name;
@Override
public String toString() {
return "Request{" +
"age='" + age + '\'' +
", name='" + name + '\'' +
'}';
}
}
publick Response dealWithRequest(Request request){
log.info("请求参数是:".request.toString)
}
打印结果如下:
请求参数是:Request{age='26', name='兄弟'}
8. 一个方法,拒绝过长的参数列表。
假设有这么一个公有方法,形参有四个。。。
public void getUserInfo(String name,String age,String sex,String mobile){
// do something ...
}
如果现在需要多传一个 version 参数进来,并且你的公有方法是类似 dubbo 这种对外提供的接口的话,那么你的接口是不是需要兼容老版本啦?
public void getUserInfo(String name,String age,String sex,String mobile){
// do something ...
}
/**
* 新接口调这里
*/
public void getNewUserInfo(String name,String age,String sex,String mobile,String version){
// do something ...
}
所以呢,一般一个方法的参数,一般不宜过长。过长的参数列表,不仅看起来不优雅,并且接口升级时,可能还要考虑新老版本兼容。如果参数实在是多怎么办呢?可以用个 DTO 对象包装一下这些参数呢~如下:
public void getUserInfo(UserInfoParamDTO userInfoParamDTO){
// do something ...
}
class UserInfoParamDTO{
private String name;
private String age;
private String sex;
private String mobile;
}
用个 DTO 对象包装一下,即使后面有参数变动,也可以不用动对外接口了,好处杠杠的。
9. 使用缓冲流,减少 IO 操作
反例:
/**
* @desc: 复制一张图片文件
*/
public class MainTest {
public static void main(String[] args) throws FileNotFoundException {
long begin = System.currentTimeMillis();
try (FileInputStream input = new FileInputStream("C:/456.png");
FileOutputStream output = new FileOutputStream("C:/789.png")) {
byte[] bytes = new byte[1024];
int i;
while ((i = input.read(bytes)) != -1) {
output.write(bytes,0,i);
}
} catch (IOException e) {
log.error("复制文件发生异常",e);
}
log.info("常规流读写,总共耗时ms:"+(System.currentTimeMillis() - begin));
}
}
运行结果:
常规流读写,总共耗时ms:52
使用FileInputStream、FileOutputStream实现文件读写功能,是没有什么问题的。但是呢,可以使用缓冲流BufferedReader、BufferedWriter、BufferedInputStream、BufferedOutputStream等,减少 IO 次数,提高读写效率。
如果是不带缓冲的流,读取到一个字节或者字符的,就会直接输出数据了。而带缓冲的流,读取到一个字节或者字符时,先不输出,而是等达到缓冲区的最大容量,才一次性输出。
正例:
/**
* @desc: 复制一张图片文件
*/
public class MainTest {
public static void main(String[] args) throws FileNotFoundException {
long begin = System.currentTimeMillis();
try (BufferedInputStream bufferedInputStream = new BufferedInputStream(new FileInputStream("C:/456.png"));
BufferedOutputStream bufferedOutputStream = new BufferedOutputStream(new FileOutputStream("C:/789.png"))) {
byte[] bytes = new byte[1024];
int i;
while ((i = input.read(bytes)) != -1) {
output.write(bytes,0,i);
}
} catch (IOException e) {
log.error("复制文件发生异常",e);
}
log.info("总共耗时ms"+(System.currentTimeMillis() - begin));
}
}
运行结果:
缓冲流读写,总共耗时ms:12
10. 优化你的程序逻辑,比如前面已经查到的数据,在后面的方法也用到的话,是可以往下传参的,减少方法调用/查表
反例:
public Response dealRequest(Request request){
UserInfo userInfo = userInfoDao.selectUserByUserId(request.getUserId);
if(Objects.isNull(request)){
return ;
}
insertUserVip(request.getUserId);
}
private int insertUserVip(String userId){
//又查了一次
UserInfo userInfo = userInfoDao.selectUserByUserId(request.getUserId);
//插入用户vip流水
insertUserVipFlow(userInfo);
....
}
很显然,以上程序代码,已经查到 userInfo,然后又把 userId 传下去,又查多了一次。。。实际上,可以把 userInfo 传下去的,这样可以省去一次查表操作,程序更高效。
正例:
public Response dealRequest(Request request){
UserInfo userInfo = userInfoDao.selectUserByUserId(request.getUserId);
if(Objects.isNull(request)){
return ;
}
insertUserVip(userInfo);
}
private int insertUserVip(UserInfo userInfo){
//插入用户vip流水
insertUserVipFlow(userInfo);
....
}
11. 不要为了方便,直接在代码中使用 0,1 等魔法值,应该要用 enum 枚举代替。
反例:
if("0".equals(userInfo.getVipFlag)){
//非会员,提示去开通会员
tipOpenVip(userInfo);
}else if("1".equals(userInfo.getVipFlag)){
//会员,加勋章返回
addMedal(userInfo);
}
正例:
if(UserVipEnum.NOT_VIP.getCode.equals(userInfo.getVipFlag)){
//非会员,提示去开通会员
tipOpenVip(userInfo);
}else if(UserVipEnum.VIP.getCode.equals(userInfo.getVipFlag)){
//会员,加勋章返回
addMedal(userInfo);
}
public enum UserVipEnum {
VIP("1","会员"),
NOT_VIP("0","非会员"),:;
private String code;
private String desc;
UserVipEnum(String code, String desc) {
this.code = code;
this.desc = desc;
}
}
写代码的时候,不要一时兴起,就直接使用魔法值哈。使用魔法值,维护代码起来很难受的。
12. 当成员变量值不会改变时,优先定义为静态常量
反例:
public class Task {
private final long timeout = 10L;
...
}
正例:
public class Task {
private static final long TIMEOUT = 10L;
...
}
因为如果定义为 static,即类静态常量,在每个实例对象中,它只有一份副本。如果是成员变量,每个实例对象中,都各有一份副本。显然,如果这个变量不会变的话,定义为静态常量更好一些。
13. 注意检验空指针,不要轻易相信业务,说正常逻辑某个参数不可能为空。
NullPointerException 在我们日常开发中非常常见,我们代码开发过程中,一定要对空指针保持灵敏的嗅觉。
主要有这几类空指针问题:
包装类型的空指针问题 级联调用的空指针问题 Equals 方法左边的空指针问题 ConcurrentHashMap 类似容器不支持 k-v 为 null。 集合,数组直接获取元素 对象直接获取属性
反例:
public class NullPointTest {
public static void main(String[] args) {
String s = null;
if (s.equals("666")) { //s可能为空,会导致空指针问题
System.out.println("兄弟,干货满满");
}
}
}
14,捕获到的异常,不能忽略它,至少打点日志。
反例:
public static void testIgnoreException() throws Exception {
try {
// 搞事情
} catch (Exception e) {
//捕获了异常,啥事情不做,日志也不打??
}
}
正例:
public static void testIgnoreException() {
try {
// 搞事情
} catch (Exception e) {
log.error("异常了,联系开发小哥哥看看哈",e);
}
}
15. 采用 Lambda 表达式替换内部匿名类,使代码更优雅
JDK8 出现了新特性——Lambda 表达式。Lambda 表达式不仅比匿名内部类更加优雅,并且在大多数虚拟机中,都是采用 invokeDynamic 指令实现,相对于匿名内部类,效率也更高
反例:
public void sortUserInfoList(List<UserInfo> userInfoList){
userInfoList.sort(new Comparator<UserInfo>() {
@Override
public int compare(UserInfo user1, UserInfo user2) {
Long userId1 = user1.getUserId();
Long userId2 = user2.getUserId();
return userId1.compareTo(userId2);
}});
}
正例:
public void sortUserInfoList(List<UserInfo> userInfoList){
userInfoList.sort((user1, user2) -> {
Long userId1 = user1.getUserId();
Long userId2 = user2.getUserId();
return userId1.compareTo(userId2);
});
}
16. 通知类(如发邮件,有短信)的代码,建议异步处理。
假设业务流程这样:需要在用户登陆时,添加个短信通知它的粉丝。很容易想到的实现流程如下:
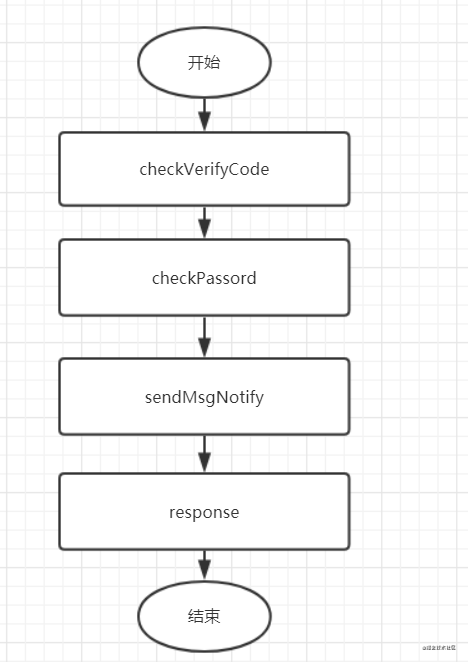
假设提供 sendMsgNotify 服务的系统挂了,或者调用 sendMsgNotify 失败了,那么用户登陆就失败了。。。
一个通知功能导致了登陆主流程不可用,明显的捡了芝麻丢西瓜。那么有没有鱼鱼熊掌兼得的方法呢?有的,给发短信接口捕获异常处理,或者另开线程异步处理,如下:
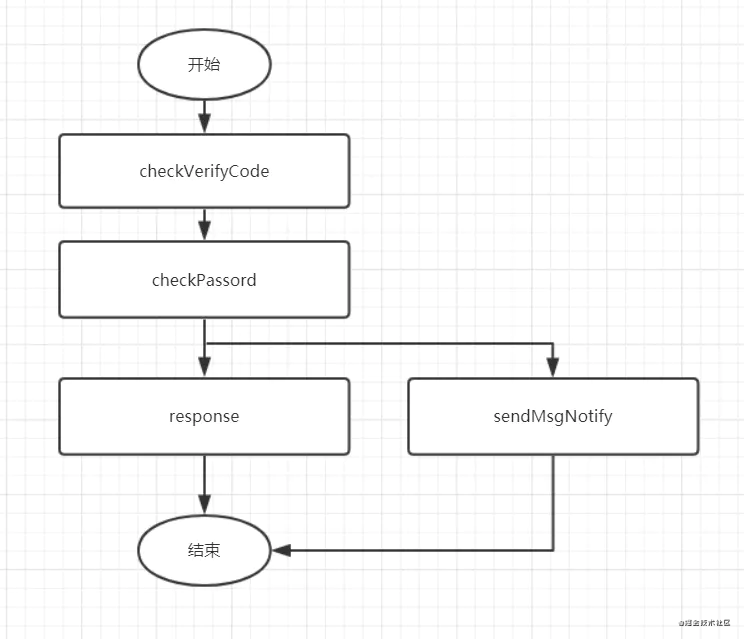
因此,添加通知类等不是非主要,可降级的接口时,应该静下心来考虑是否会影响主要流程,思考怎么处理最好。
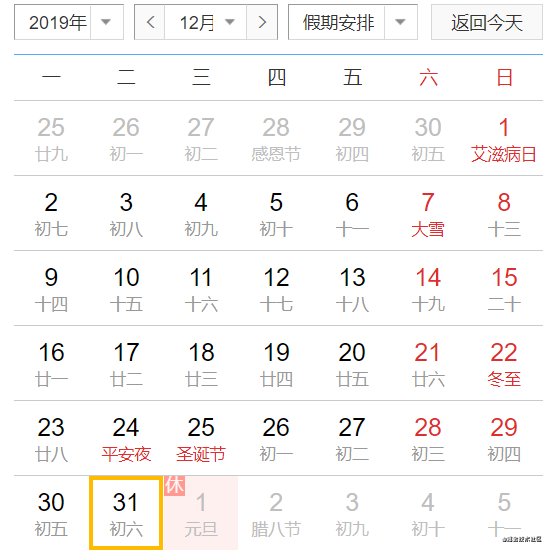
17. 处理 Java 日期时,当心 YYYY 格式设置的问题。
日常开发中,我们经常需要处理日期。我们要当时日期格式化的时候,年份是大写YYYY的坑。
Calendar calendar = Calendar.getInstance();
calendar.set(2019, Calendar.DECEMBER, 31);
Date testDate = calendar.getTime();
SimpleDateFormat dtf = new SimpleDateFormat("YYYY-MM-dd");
System.out.println("2019-12-31 转 YYYY-MM-dd 格式后 " + dtf.format(testDate));
运行结果:
2019-12-31 转 YYYY-MM-dd 格式后 2020-12-31
为什么明明是 2019 年 12 月 31 号,就转了一下格式,就变成了 2020 年 12 月 31 号了?因为 YYYY 是基于周来计算年的,它指向当天所在周属于的年份,一周从周日开始算起,周六结束,只要本周跨年,那么这一周就算下一年的了。正确姿势是使用 yyyy 格式。
18. 如果一个类确定不会被继承,不会拿来搞 AOP 骚操作,可以指定 final 修饰符,如用 final 修饰一个工具类。
正例:
public final class Tools {
public static void testFinal(){
System.out.println("工具类方法");
}
}
一个类指定了 final 修饰符,它不会被继承了,并且其所有方法都是 final 的了。Java 编译器会找机会内联所有的 final 方法,提升了 Java 运行效率。
19. static 静态变量不要依赖 spring 实例化变量,可能会导致初始化出错
之前看到项目有类似的代码。静态变量依赖于 spring 容器的 bean。
private static SmsService smsService = SpringContextUtils.getBean(SmsService.class);
这个静态的 smsService 有可能获取不到的,因为类加载顺序不是确定的,而以上的代码,静态的 smsService 初始化强制依赖 spring 容器的实例了。正确的写法可以这样,如下:
private static SmsService smsService =null;
//使用到的时候采取获取
public static SmsService getSmsService(){
if(smsService==null){
smsService = SpringContextUtils.getBean(SmsService.class);
}
return smsService;
}
20. 与类成员变量无关的方法,应当声明成静态方法
有些方法,与实例成员变量无关,就可以声明为静态方法。这一点,工具类用得很多。反例如下:
/**
* BigDecimal的工具类
*/
public class BigDecimalUtils {
public BigDecimal ifNullSetZERO(BigDecimal in) {
return in != null ? in : BigDecimal.ZERO;
}
public BigDecimal sum(BigDecimal ...in){
BigDecimal result = BigDecimal.ZERO;
for (int i = 0; i < in.length; i++){
result = result.add(ifNullSetZERO(in[i]));
}
return result;
}
因为 BigDecimalUtils 工具类的方法都没有 static 修饰,所以,你要使用的时候,每次都要 new 一下啦,那不就耗资源去反复创建对象了嘛!!
BigDecimalUtils bigDecimalUtils = new BigDecimalUtils();
bigDecimalUtils.sum(a,b);
所以可以声明成静态变量,使用的时候,直接类名.方法调用即可,正例如下:
/**
* BigDecimal的工具类
*/
public class BigDecimalUtils {
public static BigDecimal ifNullSetZERO(BigDecimal in) {
return in != null ? in : BigDecimal.ZERO;
}
public static BigDecimal sum(BigDecimal ...in){
BigDecimal result = BigDecimal.ZERO;
for (int i = 0; i < in.length; i++){
result = result.add(ifNullSetZERO(in[i]));
}
return result;
}
21. 不要用一个 Exception 捕捉所有可能的异常。
反例:
public void test(){
try{
//⋯抛出 IOException 的代码调用
//⋯抛出 SQLException 的代码调用
}catch(Exception e){
//用基类 Exception 捕捉的所有可能的异常,如果多个层次都这样捕捉,会丢失原始异常的有效信息哦
log.info(“Exception in test,exception:{}”, e);
}
}
正例:
public void test(){
try{
//⋯抛出 IOException 的代码调用
//⋯抛出 SQLException 的代码调用
}catch(IOException e){
//仅仅捕捉 IOException
log.info(“IOException in test,exception:{}”, e);
}catch(SQLException e){
//仅仅捕捉 SQLException
log.info(“SQLException in test,exception:{}”, e);
}
}
22. 函数不要过度封装,言简意赅即可。
反例:
// 函数封装
public static boolean isUserVip(Boolean isVip) {
return Boolean.TRUE.equals(isVip);
}
// 使用代码
boolean isVip = isVip(user.getUserVip());
正例:
boolean isVip = Boolean.TRUE.equals(user.getUserVip());
函数不要过度封装,把意思表达清楚即可。并且,方法调用会引起入栈和出栈,导致消耗更多的 CPU 和内存,过度封装,会损耗性能的!
23. 如果变量的初值一定会被覆盖,就没有必要给变量赋初值。
反例:
List<UserInfo> userList = new ArrayList<>();
if (isAll) {
userList = userInfoDAO.queryAll();
} else {
userList = userInfoDAO.queryActive();
}
正例:
List<UserInfo> userList ;
if (isAll) {
userList = userInfoDAO.queryAll();
} else {
userList = userInfoDAO.queryActive();
}
24.金额数值计算要使用 BigDecimal
看下这个浮点数计算的例子吧:
public class DoubleTest {
public static void main(String[] args) {
System.out.println(0.1+0.2);
System.out.println(1.0-0.8);
System.out.println(4.015*100);
System.out.println(123.3/100);
double amount1 = 3.15;
double amount2 = 2.10;
if (amount1 - amount2 == 1.05){
System.out.println("OK");
}
}
}
运行结果:
0.30000000000000004
0.19999999999999996
401.49999999999994
1.2329999999999999
因为计算机是以二进制存储数值的,对于浮点数也是。对于计算机而言,0.1 无法精确表达,这就是为什么浮点数会导致精确度缺失的。因此,金额计算,一般都是用 BigDecimal 类型
System.out.println(new BigDecimal(0.1).add(new BigDecimal(0.2)));
//output:
0.3000000000000000166533453693773481063544750213623046875
其实,使用 BigDecimal 表示和计算浮点数,必须使用字符串的构造方法来初始化 BigDecimal,并且,还要关注 BigDecimal 的几位小数点,它有八种舍入模式等
25. 注意 Arrays.asList 的几个坑
基本类型不能作为 Arrays.asList 方法的参数,否则会被当做一个参数。
public class ArrayAsListTest {
public static void main(String[] args) {
int[] array = {1, 2, 3};
List list = Arrays.asList(array);
System.out.println(list.size());
}
}
//运行结果
1
Arrays.asList 返回的 List 不支持增删操作。
public class ArrayAsListTest {
public static void main(String[] args) {
String[] array = {"1", "2", "3"};
List list = Arrays.asList(array);
list.add("5");
System.out.println(list.size());
}
}
// 运行结果
Exception in thread "main" java.lang.UnsupportedOperationException
at java.util.AbstractList.add(AbstractList.java:148)
at java.util.AbstractList.add(AbstractList.java:108)
at object.ArrayAsListTest.main(ArrayAsListTest.java:11)
Arrays.asList 返回的 List 并不是我们期望的 java.util.ArrayList,而是 Arrays 的内部类 ArrayList。内部类的 ArrayList 没有实现 add 方法,而是父类的 add 方法的实现,是会抛出异常的呢。
使用 Arrays.asList 的时候,对原始数组的修改会影响到我们获得的那个 List
public class ArrayAsListTest {
public static void main(String[] args) {
String[] arr = {"1", "2", "3"};
List list = Arrays.asList(arr);
arr[1] = "4";
System.out.println("原始数组"+Arrays.toString(arr));
System.out.println("list数组" + list);
}
}
//运行结果
原始数组[1, 4, 3]
list数组[1, 4, 3]
26. 及时关闭 IO 资源流
大家应该都有过这样的经历,windows 系统桌面如果打开太多文件或者系统软件,就会觉得电脑很卡。当然,我们 linux 服务器也一样,平时操作文件,或者数据库连接,IO 资源流如果没关闭,那么这个 IO 资源就会被它占着,这样别人就没有办法用了,这就造成资源浪费。
所以使用完 IO 流,记得关闭哈。可以使用 try-with-resource 关闭的:
try (FileInputStream inputStream = new FileInputStream(new File("jay.txt")) {
// use resources
} catch (FileNotFoundException e) {
log.error(e);
} catch (IOException e) {
log.error(e);
}
27. 尽量在方法内定义基本类型的临时变量
对于方法来说,基本类型的参数以及临时变量,都是保存在栈中的,访问速度比较快;对象类型的参数,以及临时变量的引用都保存在栈中,但对象保存在堆中,访问速度较慢。 任何类型的成员变量都保存在堆(Heap)中,访问速度较慢。
public class AccumulatorUtil {
private double result = 0.0D;
//反例
public void addAllOne( double[] values) {
for(double value : values) {
result += value;
}
}
//正例,先在方法内声明一个局部临时变量,累加完后,再赋值给方法外的成员变量
public void addAll1Two(double[] values) {
double sum = 0.0D;
for(double value : values) {
sum += value;
}
result += sum;
}
}
28. 如果数据库一次查询的数量过多,建议分页处理。
如果你的 Sql 一次性查出来的数据量比较多,建议分页处理。
反例:
select user_id,name,age from user_info ;
正例:
select user_id,name,age from user_info limit #{offset},#{pageSize};
如果偏移量特别大的时候,查询效率就变得低下。可以这样优化:
//方案一 :返回上次查询的最大记录(偏移量)
select id,name from user_info where id>10000 limit #{pageSize}.
//方案二:order by + 索引
select id,name from user_info order by id limit #{offset},#{pageSize}
//方案三:在业务允许的情况下限制页数:
29. 尽量减少对变量的重复计算
一般我们写代码的时候,会以以下的方式实现遍历:
for (int i = 0; i < list.size; i++){
}
如果 list 数据量比较小那还好。如果 list 比较大时,可以优化成这样:
for (int i = 0, int length = list.size; i < length; i++){
}
理由:
对方法的调用,即使是只有一个语句,也是有有消耗的,比如创建栈帧。如果 list 比较大时,多次调用 list.size 也是会有资源消耗的。
30. 修改对外老接口的时候,思考接口的兼容性。
很多 bug 都是因为修改了对外老接口,但是却不做兼容导致的。关键这个问题多数是比较严重的,可能直接导致系统发版失败的。新手程序员很容易就犯这个错误了哦~
所以,如果你的需求是在原来接口上修改,,尤其这个接口是对外提供服务的话,一定要考虑接口兼容。举个例子吧,比如 dubbo 接口,原本是只接收 A,B 参数,现在你加了一个参数 C,就可以考虑这样处理。
//老接口
void oldService(A,B);{
//兼容新接口,传个null代替C
newService(A,B,null);
}
//新接口,暂时不能删掉老接口,需要做兼容。
void newService(A,B,C);
31 代码采取措施避免运行时错误(如数组边界溢出,被零除等)
日常开发中,我们需要采取措施规避数组边界溢出,被零整除,空指针等运行时错误。
类似代码比较常见:
String name = list.get(1).getName(); //list可能越界,因为不一定有2个元素哈
所以,应该采取措施,预防一下数组边界溢出,正例:
if(CollectionsUtil.isNotEmpty(list)&& list.size()>1){
String name = list.get(1).getName();
}
32. 注意 ArrayList.toArray() 强转的坑
public class ArrayListTest {
public static void main(String[] args) {
List<String> list = new ArrayList<String>(1);
list.add("兄弟");
String[] array21 = (String[])list.toArray();//类型转换异常
}
}
因为返回的是 Object 类型,Object 类型数组强转 String 数组,会发生 ClassCastException。解决方案是,使用 toArray()重载方法 toArray(T[] a)
String[] array1 = list.toArray(new String[0]);//可以正常运行
33. 尽量不在循环里远程调用、或者数据库操作,优先考虑批量进行。
远程操作或者数据库操作都是比较耗网络、IO 资源的,所以尽量不在循环里远程调用、不在循环里操作数据库,能批量一次性查回来尽量不要循环多次去查。(但是呢,也不要一次性查太多数据哈,要分批 500 一次酱紫)
正例:
remoteBatchQuery(param);
反例:
for(int i=0;i<n;i++){
remoteSingleQuery(param)
}
34. 写完代码,脑洞一下多线程执行会怎样,注意并发一致性问题
我们经常见的一些业务场景,就是先查下有没有记录,再进行对应的操作(比如修改)。但是呢,(查询+修改)合在一起不是原子操作哦,脑洞下多线程,就会发现有问题了,
反例:
if(isAvailable(ticketId){ //非原子操作
1、给现金增加操作
2、deleteTicketById(ticketId)
}else{
return "没有可用现金券";
}
为了更容易理解它,看这个流程图吧:
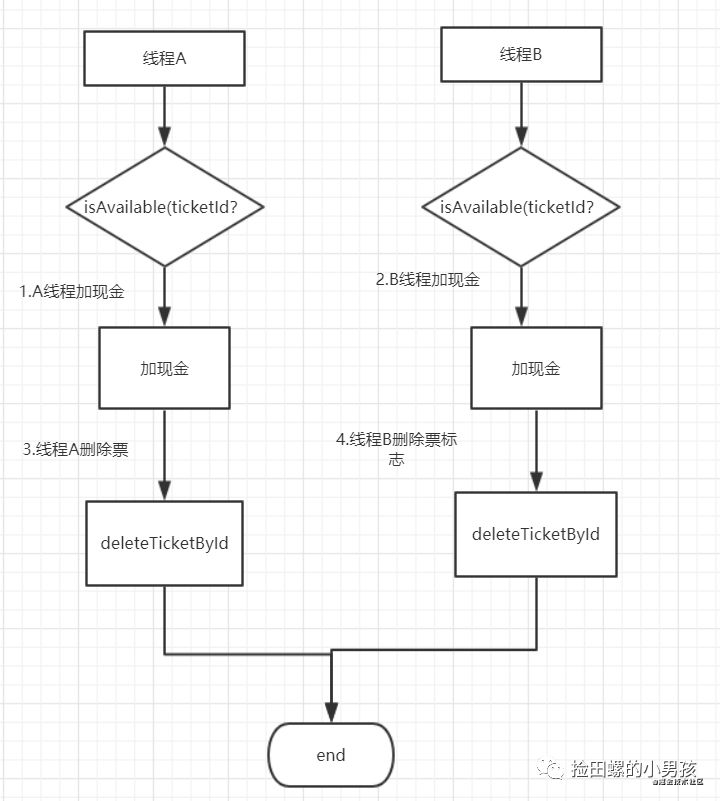
1.线程 A 加现金 2.线程 B 加现金 3.线程 A 删除票标志 4.线程 B 删除票标志
显然这样存在并发问题,正例应该利用数据库删除操作的原子性,如下:
if(deleteAvailableTicketById(ticketId) == 1){ //原子操作
1、给现金增加操作
}else{
return “没有可用现金券”
}
35 多线程异步优先考虑恰当的线程池,而不是 new thread,同时考虑线程池是否隔离
为什么优先使用线程池?使用线程池有这几点好处呀
它帮我们管理线程,避免增加创建线程和销毁线程的资源损耗。 提高响应速度。 重复利用。
同时呢,尽量不要所有业务都共用一个线程池,需要考虑线程池隔离。就是不同的关键业务,分配不同的线程池,然后线程池参数也要考虑恰当哈。
36,直接大文件或者一次性从数据库读取太多数据到内存,可能导致 OOM 问题
如果一次性把大文件或者数据库太多数据达到内存,是会导致 OOM 的。所以,为什么查询 DB 数据库,一般都建议分批。
读取文件的话,一般文件不会太大,才使用 Files.readAllLines()。为什么呢?因为它是直接把文件都读到内存的,预估下不会 OOM 才使用这个吧,可以看下它的源码:
public static List<String> readAllLines(Path path, Charset cs) throws IOException {
try (BufferedReader reader = newBufferedReader(path, cs)) {
List<String> result = new ArrayList<>();
for (;;) {
String line = reader.readLine();
if (line == null)
break;
result.add(line);
}
return result;
}
}
如果是太大的文件,可以使用 Files.line()按需读取,当读取完文件的时候,需要关闭资源流的哈。
37. 调用第三方接口,需要考虑异常处理,安全性,超时重试这几个点。
日常开发中,经常需要调用第三方服务,或者分布式远程服务的的话,需要考虑:
异常处理(比如,你调别人的接口,如果异常了,怎么处理,是重试还是当做失败) 超时(没法预估对方接口一般多久返回,一般设置个超时断开时间,以保护你的接口) 重试次数(你的接口调失败,需不需要重试,需要站在业务上角度思考这个问题)
简单一个例子,你一个 http 请求调别人的服务,需要考虑设置 connect-time,和 retry 次数。
38 不要使用循环拷贝集合,尽量使用 JDK 提供的方法拷贝集合
JDK 提供原生 API 方法,可以直接指定集合的容量,避免多次扩容损耗性能。 这些方法的底层调用 System.arraycopy 方法实现,进行数据的批量拷贝效率更高。
反例:
public List<UserInfo> copyMergeList(List<UserInfo> user1List, List<UserInfo> user2List) {
List<UserInfo> userList = new ArrayList<>(user1List.size() + user2List.size());
for (UserInfo user : user1List) {
userList.add(user);
}
for (UserInfo user : user2List) {
userList.add(user);
}
return user1List;
}
正例:
public List<UserInfo> copyMergeList(List<UserInfo> user1List, List<UserInfo> user2List) {
List<UserInfo> userList = new ArrayList<>(user1List.size() + user2List.size());
userList.addAll(user1List);
userList.addAll(user2List);
return user1List;
}
39. 对于复杂的代码逻辑,添加清楚的注释
写代码的时候,是没有必要写太多的注释的,好的方法变量命名就是最好的注释。但是,如果是业务逻辑很复杂的代码,真的非常有必要写清楚注释。清楚的注释,更有利于后面的维护。
40. 多线程情况下,考虑线性安全问题
在高并发情况下,HashMap 可能会出现死循环。因为它是非线性安全的,可以考虑使用 ConcurrentHashMap。所以这个也尽量养成习惯,不要上来反手就是一个 new HashMap();
Hashmap、Arraylist、LinkedList、TreeMap 等都是线性不安全的; Vector、Hashtable、ConcurrentHashMap 等都是线性安全的
41. 使用 spring 事务功能时,注意这几个事务未生效的坑
日常业务开发中,我们经常跟事务打交道,事务失效主要有以下几个场景:
底层数据库引擎不支持事务 在非 public 修饰的方法使用 rollbackFor 属性设置错误 本类方法直接调用 异常被 try...catch 吃了,导致事务失效。
反例:
public class TransactionTest{
public void A(){
//插入一条数据
//调用方法B (本地的类调用,事务失效了)
B();
}
@Transactional
public void B(){
//插入数据
}
}
注解的事务方法给本类方法直接调用,事务失效
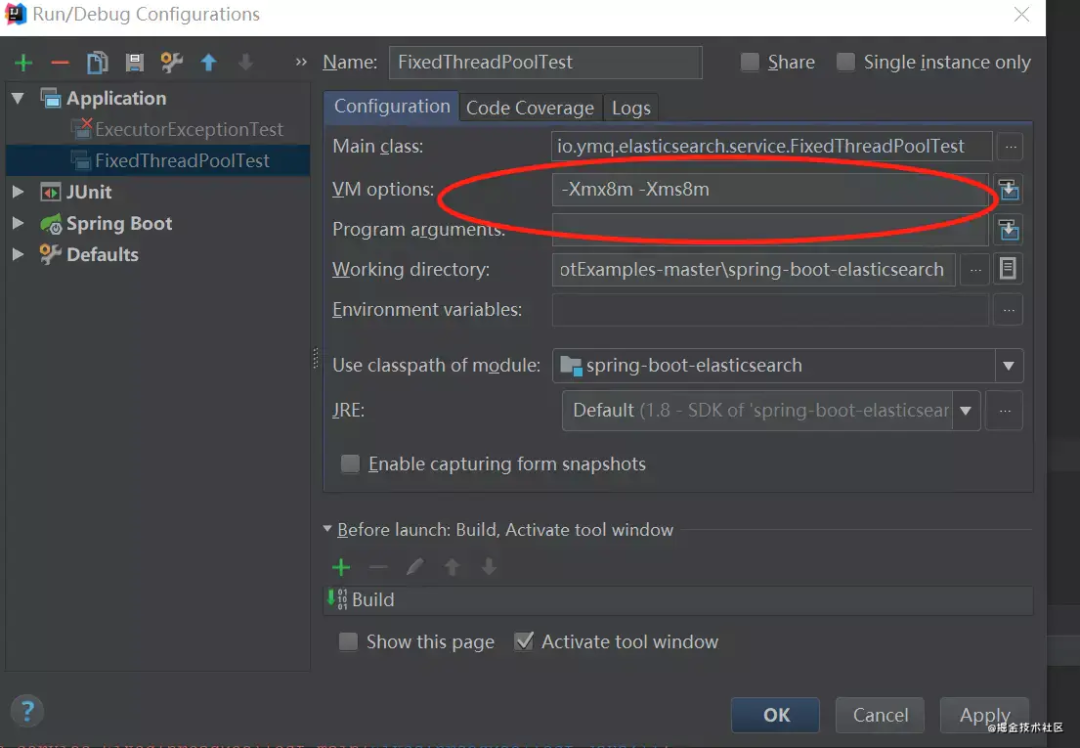
42. 使用 Executors 声明线程池,newFixedThreadPool 的 OOM 问题
ExecutorService executor = Executors.newFixedThreadPool(10);
for (int i = 0; i < Integer.MAX_VALUE; i++) {
executor.execute(() -> {
try {
Thread.sleep(10000);
} catch (InterruptedException e) {
//do nothing
}
});
}
IDE 指定 JVM 参数:-Xmx8m -Xms8m :
运行结果:
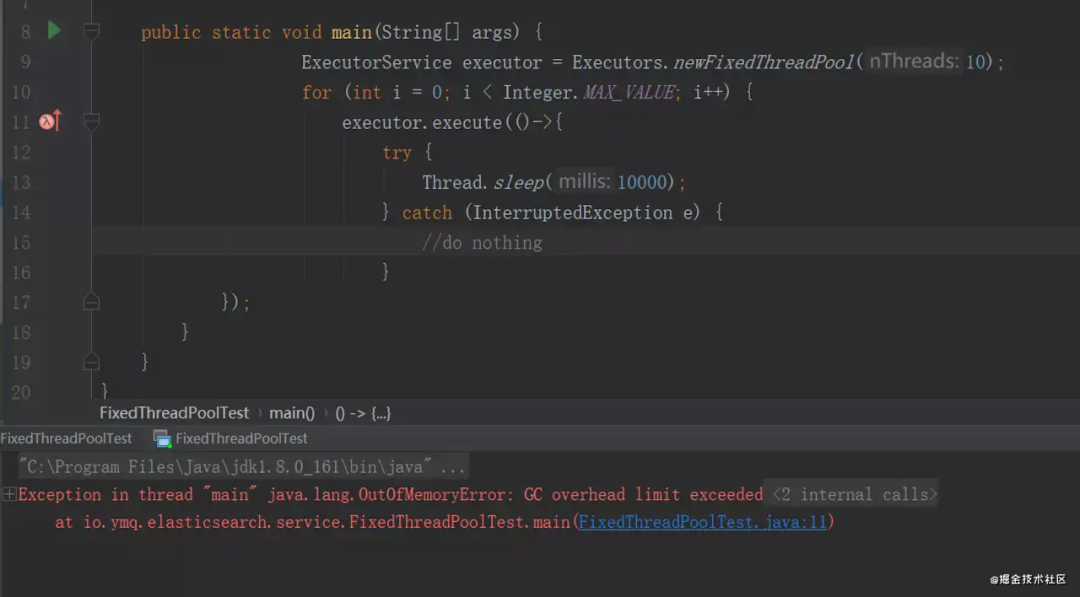
我们看下源码,其实 newFixedThreadPool 使用的是无界队列!
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
public class LinkedBlockingQueue<E> extends AbstractQueue<E>
implements BlockingQueue<E>, java.io.Serializable {
...
/**
* Creates a {@code LinkedBlockingQueue} with a capacity of
* {@link Integer#MAX_VALUE}.
*/
public LinkedBlockingQueue() {
this(Integer.MAX_VALUE);
}
...
}
newFixedThreadPool 线程池的核心线程数是固定的,它使用了近乎于无界的 LinkedBlockingQueue 阻塞队列。当核心线程用完后,任务会入队到阻塞队列,如果任务执行的时间比较长,没有释放,会导致越来越多的任务堆积到阻塞队列,最后导致机器的内存使用不停的飙升,造成 JVM OOM。
43. catch 住异常后,尽量不要使用 e.printStackTrace(),而是使用 log 打印。
反例:
try{
// do what you want
}catch(Exception e){
e.printStackTrace();
}
正例:
try{
// do what you want
}catch(Exception e){
log.info("你的程序有异常啦",e);
}
44. 接口需要考虑幂等性
接口是需要考虑幂等性的,尤其抢红包、转账这些重要接口。最直观的业务场景,就是用户连着点两次,你的接口有没有 hold 住。
一般幂等技术方案有这几种:
查询操作 唯一索引 token 机制,防止重复提交 数据库的 delete/update 操作 乐观锁 悲观锁 Redis、zookeeper 分布式锁(以前抢红包需求,用了 Redis 分布式锁) 状态机幂等
45. 对于行数比较多的函数,建议划分小函数,增强可读性。
反例:
public class Test {
private String name;
private Vector<Order> orders = new Vector<Order>();
public void printOwing() {
//print banner
System.out.println("****************");
System.out.println("*****customer Owes *****");
System.out.println("****************");
//calculate totalAmount
Enumeration env = orders.elements();
double totalAmount = 0.0;
while (env.hasMoreElements()) {
Order order = (Order) env.nextElement();
totalAmount += order.getAmout();
}
//print details
System.out.println("name:" + name);
System.out.println("amount:" + totalAmount);
}
}
正例:
public class Test {
private String name;
private Vector<Order> orders = new Vector<Order>();
public void printOwing() {
//print banner
printBanner();
//calculate totalAmount
double totalAmount = getTotalAmount();
//print details
printDetail(totalAmount);
}
void printBanner(){
System.out.println("****************");
System.out.println("*****customer Owes *****");
System.out.println("****************");
}
double getTotalAmount(){
Enumeration env = orders.elements();
double totalAmount = 0.0;
while (env.hasMoreElements()) {
Order order = (Order) env.nextElement();
totalAmount += order.getAmout();
}
return totalAmount;
}
void printDetail(double totalAmount){
System.out.println("name:" + name);
System.out.println("amount:" + totalAmount);
}
}
一个过于冗长的函数或者一段需要注释才能让人理解用途的代码,可以考虑把它切分成一个功能明确的函数单元,并定义清晰简短的函数名,这样会让代码变得更加优雅。
46. 你的关键业务代码,一般建议搞点日志保驾护航。
关键业务代码无论身处何地,都应该有足够的日志保驾护航。
比如:你实现转账业务,转个几百万,然后转失败了,接着客户投诉,然后你还没有打印到日志,想想那种水深火热的困境下,你却毫无办法。。。
那么,你的转账业务都需要那些日志信息呢?至少,方法调用前,入参需要打印需要吧,接口调用后,需要捕获一下异常吧,同时打印异常相关日志吧,如下:
public void transfer(TransferDTO transferDTO){
log.info("invoke tranfer begin");
//打印入参
log.info("invoke tranfer,paramters:{}",transferDTO);
try {
res= transferService.transfer(transferDTO);
}catch(Exception e){
log.error("transfer fail,cifno:{},account:{}",transferDTO.getCifno(),
transferDTO.getaccount())
log.error("transfer fail,exception:{}",e);
}
log.info("invoke tranfer end");
}
除了打印足够的日志,我们还需要注意一点是,日志级别别混淆使用,别本该打印 info 的日志,你却打印成 error 级别,告警半夜三更催你起来排查问题就不好了。
49. 某些可变因素,如红包皮肤等等,做成配置化是否会更好呢。
假如产品提了个红包需求,圣诞节的时候,红包皮肤为圣诞节相关的,春节的时候,红包皮肤等。
反例:
if(duringChristmas){
img = redPacketChristmasSkin;
}else if(duringSpringFestival){
img = redSpringFestivalSkin;
}
如果到了元宵节的时候,运营小姐姐突然又有想法,红包皮肤换成灯笼相关的,这时候,是不是要去修改代码了,重新发布了?从一开始,实现一张红包皮肤的配置表,将红包皮肤做成配置化呢?更换红包皮肤,只需修改一下表数据就好了。
48. 直接迭代需要使用的集合,无须在额外操作
直接迭代需要使用的集合,无需通过其它操作获取数据,比较典型就是 Map 的迭代遍历:
反例:
Map<Long, UserDO> userMap = ...;
for (Long userId : userMap.keySet()) {
UserDO user = userMap.get(userId);
...
}
正例:
Map<Long, UserDO> userMap = ...;
for (Map.Entry<Long, UserDO> userEntry : userMap.entrySet()) {
Long userId = userEntry.getKey();
UserDO user = userEntry.getValue();
...
}
49. 策略模式+工厂方法优化冗余的 if else
反例:
String medalType = "guest";
if ("guest".equals(medalType)) {
System.out.println("嘉宾勋章");
} else if ("vip".equals(medalType)) {
System.out.println("会员勋章");
} else if ("guard".equals(medalType)) {
System.out.println("展示守护勋章");
}
...
首先,我们把每个条件逻辑代码块,抽象成一个公共的接口,我们根据每个逻辑条件,定义相对应的策略实现类,可得以下代码:
//勋章接口
public interface IMedalService {
void showMedal();
}
//守护勋章策略实现类
public class GuardMedalServiceImpl implements IMedalService {
@Override
public void showMedal() {
System.out.println("展示守护勋章");
}
}
//嘉宾勋章策略实现类
public class GuestMedalServiceImpl implements IMedalService {
@Override
public void showMedal() {
System.out.println("嘉宾勋章");
}
}
//VIP勋章策略实现类
public class VipMedalServiceImpl implements IMedalService {
@Override
public void showMedal() {
System.out.println("会员勋章");
}
}
接下来,我们再定义策略工厂类,用来管理这些勋章实现策略类,如下:
//勋章服务工产类
public class MedalServicesFactory {
private static final Map<String, IMedalService> map = new HashMap<>();
static {
map.put("guard", new GuardMedalServiceImpl());
map.put("vip", new VipMedalServiceImpl());
map.put("guest", new GuestMedalServiceImpl());
}
public static IMedalService getMedalService(String medalType) {
return map.get(medalType);
}
}
优化后,正例如下:
ublic class Test {
public static void main(String[] args) {
String medalType = "guest";
IMedalService medalService = MedalServicesFactory.getMedalService(medalType);
medalService.showMedal();
}
}
分享的最后,二哥多说两句。
平常工作的时候,一定要注意,多写优雅的代码,不要将就,哪怕开发进度很紧张,也不要将就,因为一旦将就,可能就隐藏了 bug 在里面。修改 bug 的时间可能就远远超出了你写代码花费的时间,很不划算的。
优雅的姿势久了,你也会发现自己越来越优秀了。
尤其是当你的代码在 review 的时候,领导发现,“咦,小伙子写的代码竟然超出了我的预期,学到了~”那不得了了,领导对你的印象肯定好到爆,绩效分多给点,那就爽歪歪了,对吧?
我是二哥,下期见~