
MySQL索引的分类、何时使用、何时不使用、何时失效?
作者:绕远的偶人
blog.csdn.net/weixin_39420024/article/details/80040549
1、分类
MySQL索引分为普通索引、唯一索引、主键索引、组合索引、全文索引。索引不会包含有null值的列,索引项可以为null(唯一索引、组合索引等),但是只要列中有null值就不会被包含在索引中。
(1)普通索引: create index index_name on table(column);
或者创建表时指定,create table(..., index index_name column);
(2)唯一索引: 类似普通索引,索引列的值必须唯一(可以为空,这点和主键索引不同)
create unique index index_name on table(column);或者创建表时指定unique index_name column
(3)主键索引: 特殊的唯一索引,不允许为空,只能有一个,一般是在建表时指定primary key(column)
(4)组合索引: 在多个字段上创建索引,遵循最左前缀原则。alter table t add index index_name(a,b,c);
(5)全文索引: 主要用来查找文本中的关键字,不是直接与索引中的值相比较,像是一个搜索引擎,配合match against使用,现在只有char,varchar,text上可以创建全文索引。
在数据量较大时,先将数据放在一张没有全文索引的表里,然后再利用create index创建全文索引,比先生成全文索引再插入数据快很多。
2、何时使用索引
MySQL每次查询只使用一个索引。与其说是“数据库查询只能用到一个索引”,倒不如说,和全表扫描比起来,去分析两个索引B+树更加耗费时间。所以where A=a and B=b这种查询使用(A,B)的组合索引最佳,B+树根据(A,B)来排序。
主键,unique字段; 和其他表做连接的字段需要加索引; 在where里使用>,≥,=,<,≤,is null和between等字段; 使用不以通配符开始的like,where A like 'China%'; 聚集函数MIN(),MAX()中的字段; order by和group by字段;
3、何时不使用索引
表记录太少; 数据重复且分布平均的字段(只有很少数据值的列); 经常插入、删除、修改的表要减少索引; text,image等类型不应该建立索引,这些列的数据量大(假如text前10个字符唯一,也可以对text前10个字符建立索引); MySQL能估计出全表扫描比使用索引更快时,不使用索引;
4、索引何时失效
组合索引未使用最左前缀,例如组合索引(A,B),where B=b不会使用索引; like未使用最左前缀,where A like '%China'; 搜索一个索引而在另一个索引上做order by,where A=a order by B,只使用A上的索引,因为查询只使用一个索引 ; or会使索引失效。如果查询字段相同,也可以使用索引。例如where A=a1 or A=a2(生效),where A=a or B=b(失效) 如果列类型是字符串,要使用引号。例如where A='China',否则索引失效(会进行类型转换); 在索引列上的操作,函数(upper()等)、or、!=(<>)、not in等;
5、explain语句
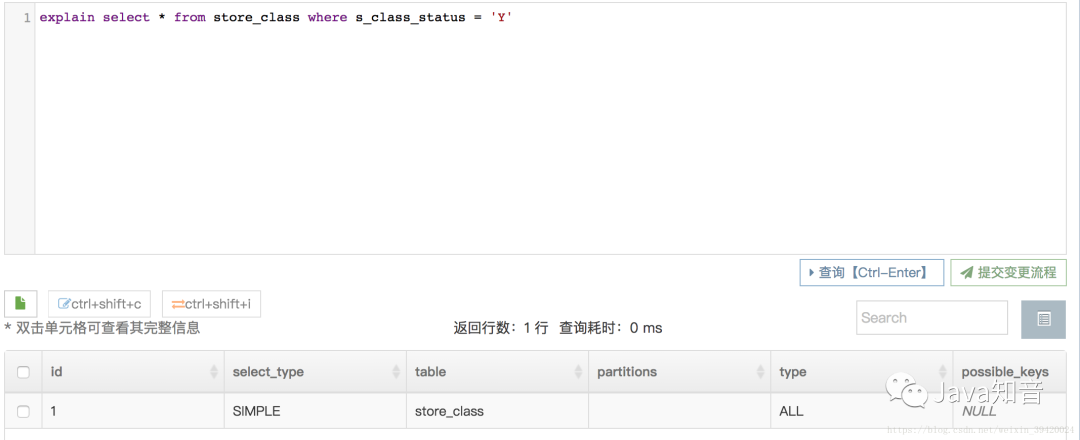
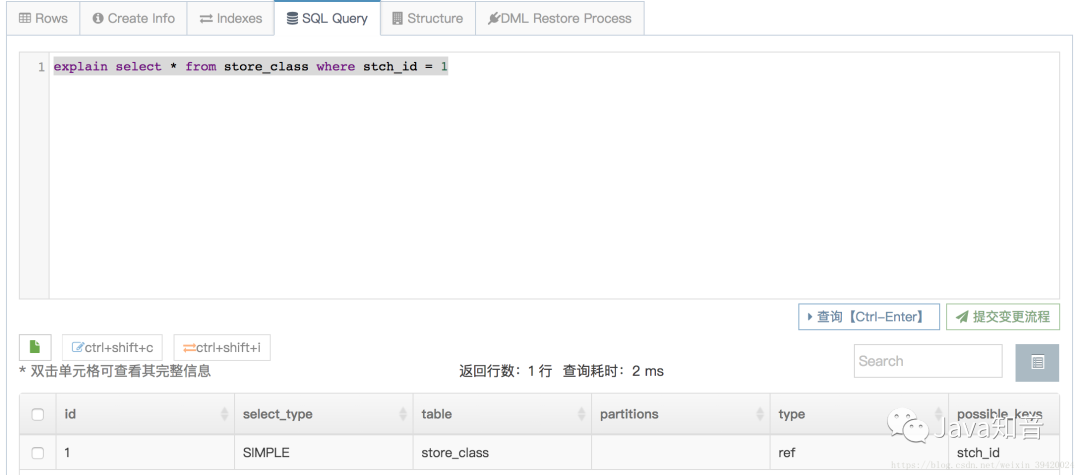
type字段为All,未使用索引;为ref,使用索引
ALL: 全表扫描 index: 索引全扫描 range: 索引范围扫描,常用语<,<=,>=,between等操作 ref: 使用非唯一索引扫描或唯一索引前缀扫描,返回单条记录,常出现在关联查询中 eq_ref: 类似ref,区别在于使用的是唯一索引,使用主键的关联查询 const/system: 单条记录,系统会把匹配行中的其他列作为常数处理,如主键或唯一索引查询 null: MySQL不访问任何表或索引,直接返回结果
还有key字段表示用到的索引,没有用到为null