
STDC升级 | STDC-MA 更轻更快更准,超越 STDC 与 BiSeNetv2


语义分割广泛应用于自动驾驶和智能交通,其对空间和语义信息的要求很高。在这里提出了
STDC-MA来满足这些需求。首先,STDC-MA采用了STDC-Seg结构,以确保结构轻巧高效。随后,应用特征对齐模块(FAM)来理解高层特征和低层特征之间的偏移,解决高层特征图上与上采样相关的像素偏移问题。
STDC-MA实现了高级特征和低级特征之间的有效融合。采用分层多尺度注意力机制从一张图像的两个不同输入尺寸中揭示注意力区域之间的关系。通过这种关系,将受关注的区域整合到分割结果中,从而减少输入图像的未关注的区域,提高多尺度特征的有效利用。
STDC-MA保持了STDC-Seg网络的分割速度,同时提高了小物体的分割精度。STDC-MA在Cityscapes的验证集上进行了验证。STDC-MA的分割结果在0.5× scale的输入下达到了76.81%的mIOU,比STDC-Seg高3.61%。
1简介
语义分割是一种经典的计算机视觉任务,广泛应用于自动驾驶、视频监控、机器人感知等领域。与目标检测不同,语义分割旨在实现像素级分类。当应用于包括自动驾驶在内的关键领域时,它可以提供目标的详细轮廓和类别信息。智能城市和智能交通中的交通行为分析可以通过语义信息变得更加合理。尽管语义分割方法得到了高度发展,但在现实需求中实现速度和准确性还需要很多改进。
上述目标主要实现如下:
裁剪或调整输入图像的大小,以降低图像分割的计算成本。但是,这种方法可能会带来空间信息的丢失。 通过减少语义分割的通道数来提高模型推理的速度,从而依次降低模型的空间容量; 为了追求紧凑的框架,可能会放弃部分下采样层,但是这会降低模型的感受野,不足以覆盖大物体。
研究人员开发了一种 U-Shape 网络结构来弥补空间细节的损失,从而逐渐改善空间信息。通过融合Backbone网络的层次特征来填补缺失的细节。但是,这种方法有2个缺点:
完整的 U-Shape结构增加了模型的计算量,因为它引入了高分辨率的特征图进行额外的计算。通过简单的上采样和融合恢复语义分割模型中裁剪的空间信息的挑战。
因此,U-Shape结构并不是最优方案,需要寻找更轻巧、更高效的结构。
实时语义分割任务对丰富的空间信息和多尺度语义信息有很高的要求。BiSeNet采用双流结构代替U-Shape结构,分别对空间特征和语义信息进行编码,并产生出色的分割效果。但BiseNet独立的语义编码分支计算耗时。此外,来自 BiseNet 语义分支中其他任务(包括图像分类)的预训练模型在语义分割任务中效率低下。
在 STDC-Seg(Short-Term Dense Concatenate Segmentation)网络中,设计了一个轻量级的 STDC Backbone来提取特征。它消除了分支上的特征冗余,并利用来自GT的边缘细节信息来指导空间特征学习。STDC-Seg网络在精度和速度上都取得了令人满意的结果;但是它没有考虑不同尺度图像对网络的影响。
之前的一项研究发现,在同一个网络中,不同尺度的图像分割结果不同。小物体的分割精度在小尺度图像中较低,但在大尺度图像中可以取得优异的效果。另一方面,大物体(尤其是背景)的分割效果在大尺度图像中较差,但在小尺度图像中可以很好地区分。因此,将分层多尺度注意力机制集成到STDC-Seg网络中,以允许模型通过Attention学习不同尺度之间的区域关系。模型结合分层多尺度注意力机制计算不同尺度的图像,学习不同尺度的高质量特征。
同时,STDC-Seg不考虑ARM模块中特征聚合时的特征对齐问题。局部特征图的像素与上采样特征图的像素之间的直接关系导致上下文不一致,进一步降低了预测中的分类精度。为了解决这个问题,本文在STDC-Seg网络中集成了一个特征对齐模块(FAM)。
STDC-MA Backbone是基于STDC-Seg的STDC2 Backbone网络。STDC-MA将分层多尺度注意力集成到STDC-Seg中。将一张图像的不同尺度的图像的注意力区域整合到STDC-MA网络的分割结果中。这种方法提高了多尺度特征的有效应用,解决了部分区域的粗分割问题。同时,采用了特征对齐模块(FAM)和特征选择模块(FSM)来替换原来的ARM模块。这个策略不仅解决了与高级特征上采样相关的像素偏移问题,并且实现了高层特征和低层特征的有效融合。因此,分割结果在小物体上变得更加准确。
使用 Cityscapes 的验证数据集测试了模型的准确性。在0.5×尺度的输入下,STDC-MA的分割结果达到了76.81% 的mIOU,比STDC-Seg高 3.61%。
2本文方法
2.1 具有多尺度注意力和对齐网络的Short-Term密集连接
STDC-MA将特征对齐模块和分层多尺度注意力机制应用于 STDC-Seg 网络,并设计了一个具有多尺度注意力和对齐(STDC-MA)网络的Short-Term密集连接。
特征对齐模块学习高级和低级特征之间的偏移,并引入一个特征选择模块来生成具有丰富空间信息的低级特征图。该方法将偏移量与增强的低级特征相结合。解决了高低级特征融合过程中的像素偏移问题,充分利用了高低级图像特征。分层多尺度注意力机制从一张图像的2个不同输入大小中学习注意力区域的关系,以复合来自不同感受野的注意力。这种方法减少了输入图像的非关注区域,充分利用多尺度特征来解决粗糙的Mask边缘问题。STDC-MA网络结构如图1所示。
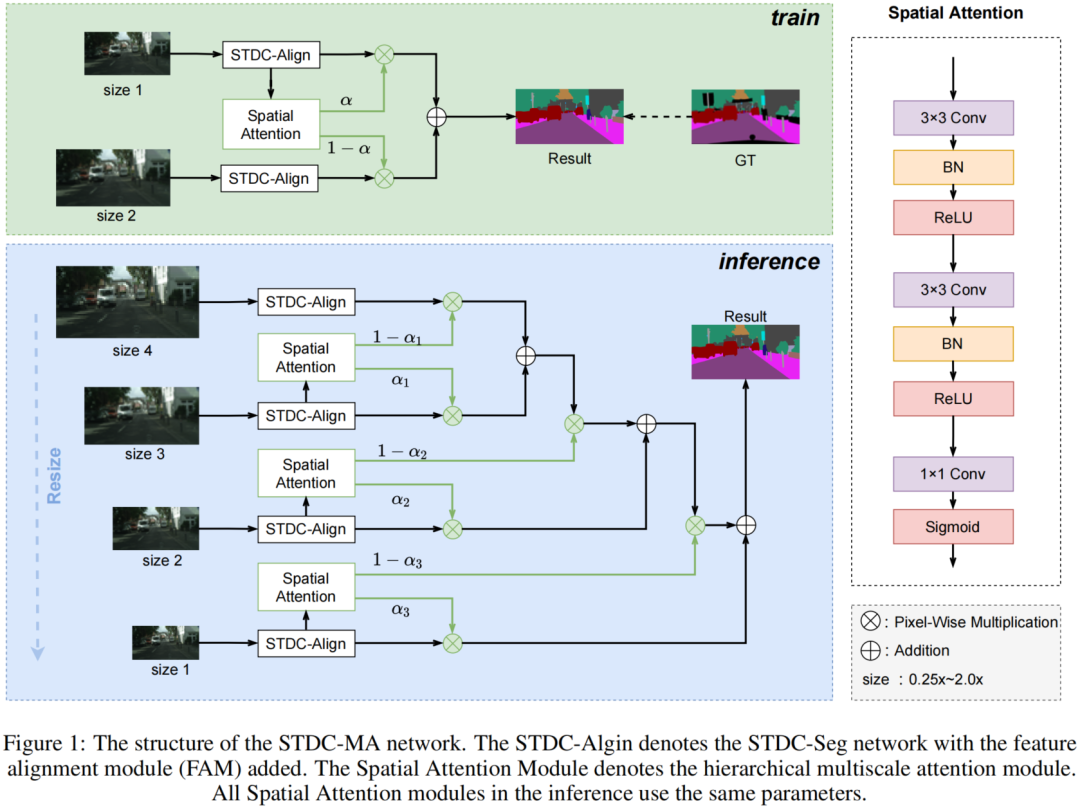
网络在训练时一次学习1.0×和0.5×这2个尺度之间的分层多尺度注意力。在推理中,根据不同尺度的输入图像的数量使用分层多尺度注意力融合。分层多尺度注意力模块如图1所示。在实践中,类似的分层多尺度注意力模块使用相同的参数。与不同尺度的分离注意力相比,这种设计显著减少了参数。
2.2 分层多尺度注意力
对分层多尺度注意力的研究表明,即使输入来自同一图像,不同尺度输入的输出Mask也不同。不同尺度的图像包含不同的空间信息。
例如,大尺度图像具有详细的空间信息,语义特征的提取也具有挑战性。因此,在大尺度输入图像的分割结果中,小物体被准确分割,而大物体被粗略的分割。另一方面,小尺度图像的空间信息比较粗糙,语义特征也更容易提取。因此,在小尺度输入图像的分割结果中,大物体被准确分割,而小物体则被粗分割。
充分利用不同的尺度来细化分割网络的输出是有问题的。因此,分层多尺度注意力提出学习一张图像不同尺度的注意力区域之间的关系,以整合不同感受野中的注意力区域。该方法减少了输入图像的未关注区域,提高了网络对小物体的分割精度。
DeepLab中的ASPP利用空洞卷积来创建更密集的特征聚合。尽管在这些设计中获得了更大的感受野,但并没有清楚地识别出不同尺度对应的不同感兴趣区域。分层多尺度注意力不同于以前的注意力机制专注于单个特征图。分层多尺度注意力可以学习任意2个输入尺度之间的关系,有效减少过度注意力机制计算的消耗。
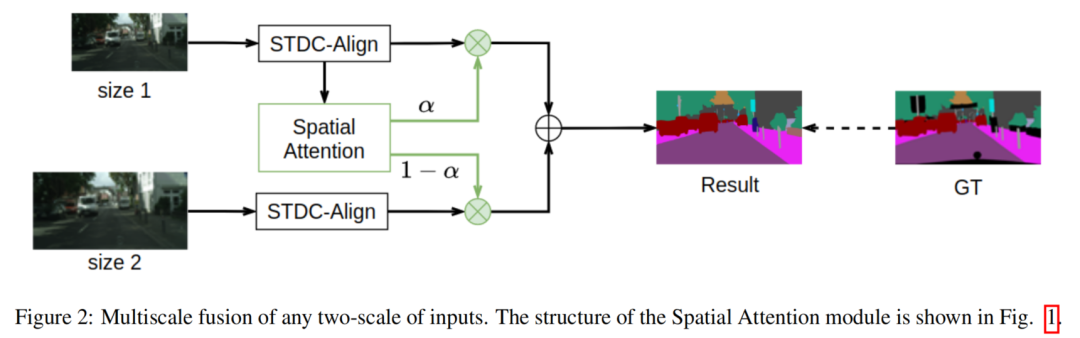
令表示具有不同N尺度的图像的集合。表示图像的第i个尺度,的尺度小于。分层多尺度注意力模块的融合涉及到任何高层特征图和对应的低层特征图之间的一系列融合(图2)。和的特征融合定义为:
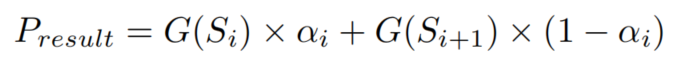
其中表示和融合后的输出。G(·)表示分割网络;表示和之间的分层多尺度注意力。
将分层多尺度注意力集成到STDC-Align网络中,确定不同尺度之间的特征关系,指导提取不同的感兴趣区域以细化分割Mask。在这里提出了最终的语义分割模型STDC-MA提高了小物体的分割精度。
2.3 Short-Term密集连接对齐网络
短期密集连接网络(STDC-Seg)遵循 BiseNetV1 的双流设计结构。它采用 STDC 作为主干来提取语义和空间特征,建立高效和轻量级的设计。STDC-Seg的ARM模块是一个特征聚合模块,不考虑不同特征图之间的特征聚合过程中的像素偏移问题,通过一个实用的特征对齐模块来解决。在 SegNet 中,编码器采用最大池化的位置来增强上采样。值得注意的是,像素偏移的问题得到了解决,但是最大池化后图像中的部分特征信息丢失了,无法通过上采样进行补偿。
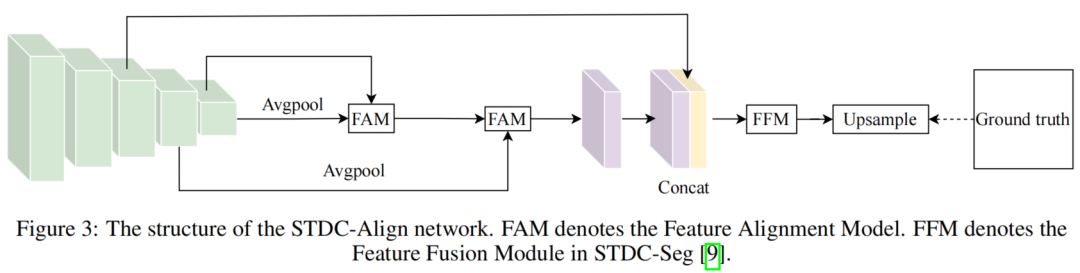
在Feature Alignment Module(FAM)中,应用了特征选择模块(FSM)来增强低层特征图丰富的空间信息,保证最终的对齐结果尽可能接近GT。为了解决像素错位问题,采用可变形卷积(DCN)来学习2个特征图之间的特征偏移。然后模型使用偏移量来指导特征对齐的过程。FAM模块实现了与STDC-Seg网络中的ARM聚合模块相同的特征图融合效果。此外,FAM模块的参数比ARM模块低1.3M。通过这种方式,将ARM聚合模块替换为特征对齐模块(FAM),并提出了一个STDC-Align网络,其结构如图3所示。
2.4 特征对齐和特征选择模块
1、特征选择模块

特征选择模块(FSM)利用通道注意力(对应于图4的上分支)来增强低级特征中的空间信息。这个过程定义为:
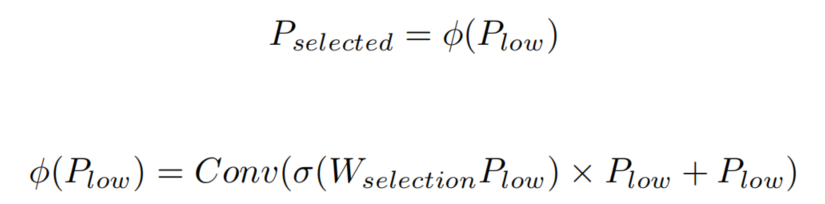
其中表示特征选择后的特征图;表示低层特征图;φ(·)表示FSM对应的特征选择过程,依次选择当前特征图的特征;Conv表示1×1卷积;σ(·)表示sigmoid函数;表示可学习的参数。在实现中,将学习到的参数和构造成channel attention,实现特征选择模块的选择功能。特征选择模块的结构如图4所示。
2、特征对齐模块
特征对齐模块(FAM)采用可变形卷积(DCN)来学习高级特征图和FSM派生的特征图之间的偏移。该方法利用偏移量来实现和高级特征图之间的特征对齐和融合。对齐的特征图由表示。这个过程定义为:
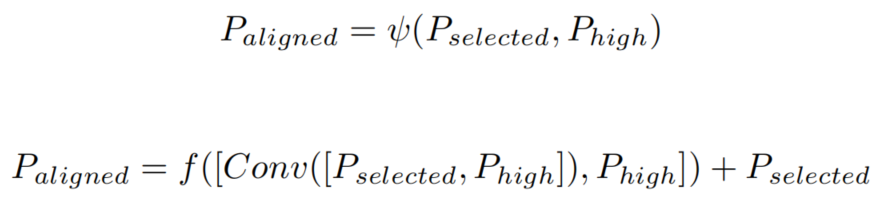
其中表示对齐的特征图;f(·)表示可变形卷积(对应图5中的DCN);Conv表示1×1卷积;[·,·]表示2个特征图的通道concat。
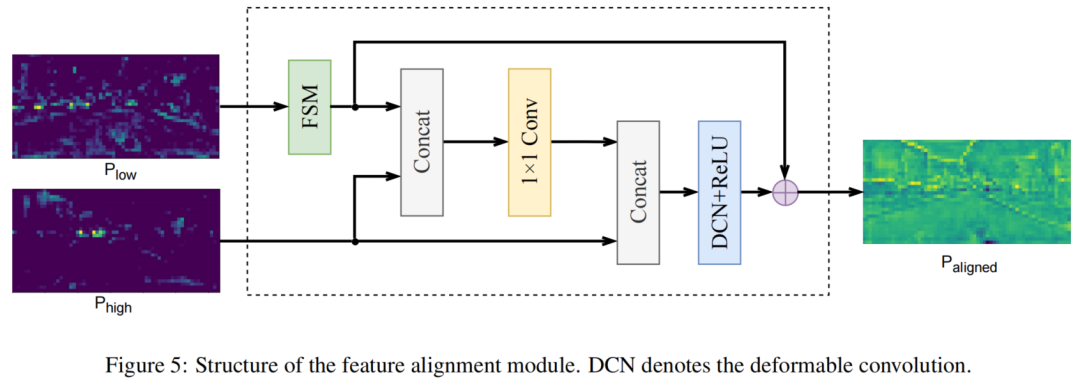
在实现特征对齐模块时,将高层特征图上采样到与特征选择模块选择的特征图在concat前的大小相同。同时,采用可变形卷积计算concat结果,以实现特征对齐的效果。最后,选择的特征图和对齐的特征图按像素相加。特征对齐模块的结构如图5所示。
3实验
3.1 消融实验
1、特征对齐模块的影响
目前的研究发现,STDC-Seg网络中的ARM模块是不同特征图之间的特征聚合模块。值得注意的是,因为这个模块不考虑特征对齐,所以它被特征对齐模块(FAM)取代。分析表明,在0.5×的输入尺度下STDC-Align网络实现了73.57%mIOU,比STDC-Seg高0.37%。此外,STDC-Align网络的参数为21.0M,比STDC-Seg的参数少1.3M。
2、分层多尺度注意力的影响
这里,在STDC-Seg网络中采用了分层多尺度注意力机制,认为该方法可以识别不同尺度之间的不同兴趣部分,实现优势互补。(0.5×和1.0×)尺度图像用作训练的输入,以学习2个不同尺度之间的注意力关系。随后,在Cityscapes验证数据集上测试不同尺度组合的结果(尺度可以在[0.25×,0.5×,1.0×,1.5×,2.0×]中选择)。

3.2 SOTA对比
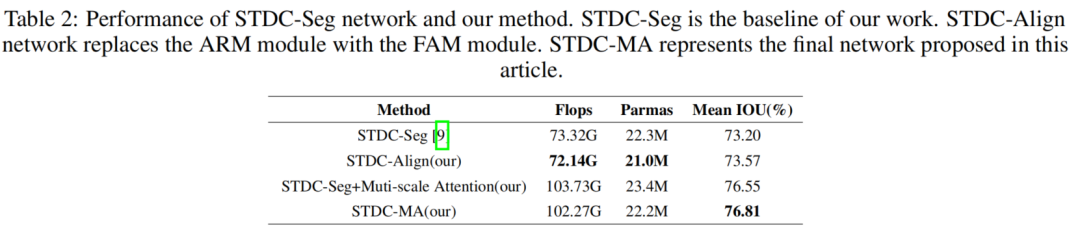
STDC-MA 网络的分割结果在 mIOU 中取得了更高的性能,证明了方法是有效的。表2显示了网络的性能指标。与STDC-Seg网络的结构相比,STDC-MA网络的结构增加了分层多尺度注意力机制,并采用了特征对齐模块代替ARM模块,减少0.1M参数,增加3.61% mIOU。
3.3 可视化对比

STDC-MA网络的输出如图6所示。STDC-MA方法在小物体上更平滑、更准确。在第一行中,STDC-MA获得了比STDC-Seg网络更准确的路灯Mask。在第二排和第三排,STDC-Seg错误地预测了栏杆。在第4行和第5行,STDC-MA在预测行人方面表现出更平滑的结果,很接近于GT,并且优于STDC-Seg网络。
4参考
[1].STDC-MA NETWORK FOR SEMANTIC SEGMENTATION
5推荐阅读
分割冠军 | 超越Swin v2、PvT v2等模型,ViT-Adaptiver实现ADE20K冠军60.5mIoU
DAFormer | 使用Transformer进行语义分割无监督域自适应的开篇之作
即插即用 | 英伟达提出FAN,鲁棒性和高效性超越ConvNeXt、Swin
长按扫描下方二维码添加小助手。
可以一起讨论遇到的问题
声明:转载请说明出处
扫描下方二维码关注【集智书童】公众号,获取更多实践项目源码和论文解读,非常期待你我的相遇,让我们以梦为马,砥砺前行!
