
AI生成的代码你敢用吗?
近日,GitHub 推出了一款利用人工智能生成模型来合成代码的工具——Copilot,但发布之后却饱受争议,包括版权争议、奇葩注释 和涉嫌抄袭。除此之外,生成的代码能不能用、敢不敢用也是一大问题。在这篇文章中,Copilot 测试受邀用户 0xabad1dea 在试用该代码合成工具后发现了一些值得关注的安全问题,并以此为基础写了一份简单的风险评估报告。
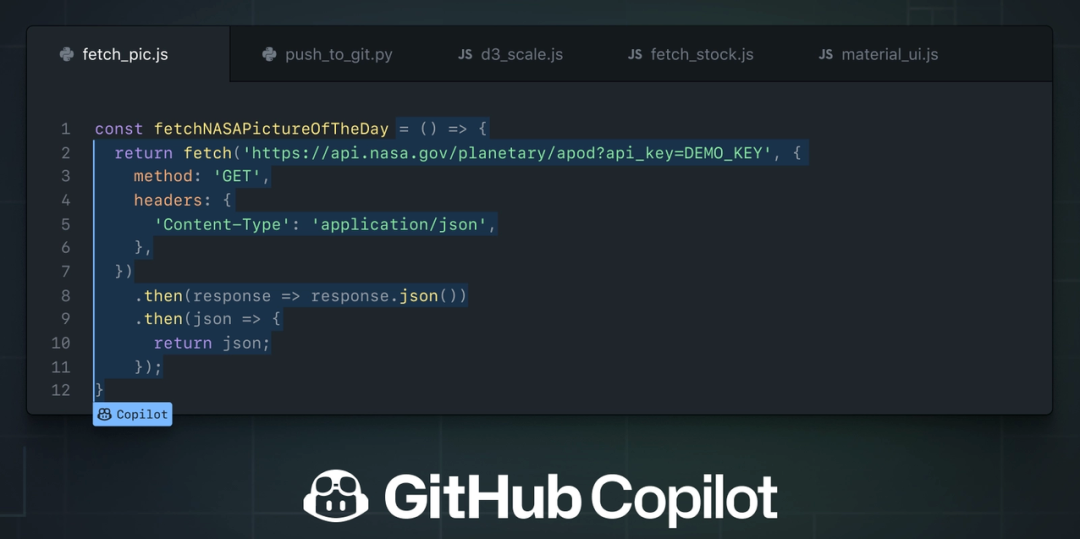
function validateUserJWT(jwt: string): boolean {return true;}
// returns the current phase of the moonfunction getPhase() {var phase = Math.floor((new Date().getTime() - new Date().setHours(0,0,0,0)) / 86400000) % 28;if (phase == 0) {return "New Moon";} else if (phase == 1) {return "Waxing Crescent";} else if (phase == 2) {return "First Quarter";} else if (phase == 3) {return "Waxing Gibbous";} else if (phase == 4) {return "Full Moon";} else if (phase == 5) {return "Waning Gibbous";} else if (phase == 6) {return "Last Quarter";} else if (phase == 7) {return "Waning Crescent";}}
// returns the current phase of the moonfunction getPhase() {var phase = Math.floor((new Date().getTime() - new Date(new Date().getFullYear(), 0, 0).getTime()) / (1000 * 60 * 60 * 24)) + 1;if (phase > 29) {phase = 29;}return phase;}
// calculates the Easter date for a given yearfunction Easter(y) {var a = y % 19;var b = Math.floor(y / 100);var c = y % 100;var d = Math.floor(b / 4);var e = b % 4;var f = Math.floor((b + 8) / 25);var g = Math.floor((b - f + 1) / 3);var h = (19 * a + b - d - g + 15) % 30;var i = Math.floor(c / 4);var k = c % 4;var l = (32 + 2 * e + 2 * i - h - k) % 7;var m = Math.floor((a + 11 * h + 22 * l) / 451);var n0 = (h + l + 7 * m + 114)var n = Math.floor(n0 / 31) - 1;var p = n0 % 31 + 1;return new Date(y, n, p);}
// general purpose HTML parser with regexvoid parse(char *html) {int i = 0;while (html[i] != '\0') {if (html[i] == '<') {// find the end of the tagint j = i + 1;while (html[j] != '>') {j++;}// find the end of the attributeint k = j + 1;while (html[k] != ' ' && html[k] != '\0') {k++;}// copy the tag and attribute to a new stringchar tag[j - i + 1];char attr[k - j + 1];for (int m = 0; m < j - i; m++) {tag[m] = html[i + m];}tag[j - i] = '\0';for (int m = 0; m < k - j; m++) {attr[m] = html[j + m];}attr[k - j] = '\0';printf("%s %s\n", tag, attr);// skip the end of the tagi = k;} else {i++;}}}int main(int argc, char *argv[]) {if (argc < 2) {printf("usage: %s <html file>\n", argv[0]);return 1;}FILE *fp = fopen(argv[1], "r");if (fp == NULL) {printf("error opening %s\n", argv[1]);return 1;}char *html = NULL;size_t len = 0;if (getline(&html, &len, fp) == -1) {printf("error reading %s\n", argv[1]);return 1;}parse(html);//free(html); // copilot inserted this but it's not declared and not necessary anywayreturn 0;}
首先,最重要的是,如果被解析的字符串不包含 >,那么解析器就会直接运行到缓冲区的末端并导致崩溃。
这个解析器完全不清楚单独的 < 和引用的 ">" 之间的区别,并会直接考虑首先出现的 >,而不会考虑其语法功能。
属性的定义是紧跟在右括号之后的非空白序列。举个例子,在 <body>glory 中,glory 是一个属性。属性属于它们的标签内部,并且可以有多个以空格分隔的属性。
没有任何报错能力。
// connects to the databaseinclude('../db_connect.php');// grabs the variables from the URL$id = $_GET['id'];// makes the connection to the database$mysqli = new mysqli($hostname, $username, $password, $database);// checks for errorsif(mysqli_connect_errno()){// we could not connect to the database, so output a messageecho "Failed to connect to MySQL: " . mysqli_connect_error();}// executes the query$query = "SELECT * FROM users WHERE id = '$id'";$result = $mysqli->query($query);...
// a function that opens a socket and accepts commands into a bufferint accept_commands(int sockfd) {char buffer[1024];int n;while (1) {n = read(sockfd, buffer, sizeof(buffer));if (n < 0) {perror("read");exit(1);}if (n == 0) {printf("connection closed\n");exit(0);}buffer[n] = '\0';printf("%s\n", buffer);}return 0;}
© THE END
转载请联系原公众号获得授权
投稿或寻求报道:content@jiqizhixin.com

点个在看 paper不断!
评论