
看完即可上手 MyBatis-Plus
早期文章
MyBatis 是当前 Java 项目中使用非常常用的持久层框架,而 MyBatis-Plus 是 MyBatis 非常好的伴侣。MyBatis-Plus 的官网是 https://mp.baomidou.com/ 。其官网对于 MyBatis-Plus 的简介如下:
MyBatis-Plus (opens new window)(简称 MP)是一个 MyBatis (opens new window)的增强工具,在 MyBatis 的基础上只做增强不做改变,为简化开发、提高效率而生。
在 MP 的官网给出了非常有意思的愿景,如下:
愿景
我们的愿景是成为 MyBatis 最好的搭档,就像 魂斗罗 中的 1P、2P,基友搭配,效率翻倍。
官网还有一个非常有趣的配图,配图如下:

MP 的特性如下思维导图:(该思维导图通过 MP 的官网进行整理)
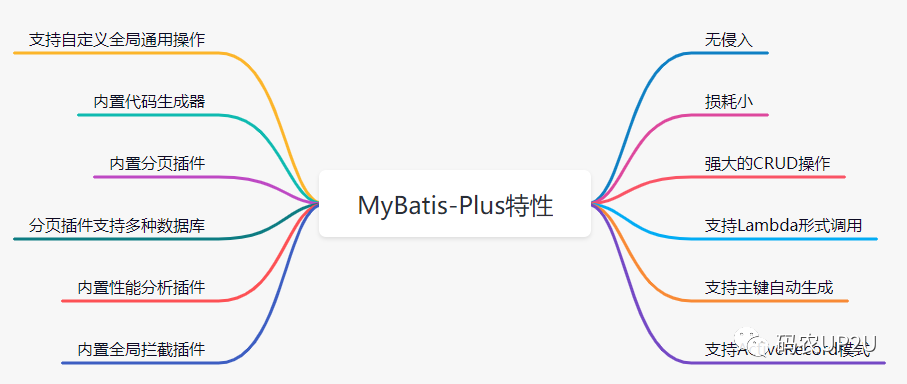
本文整理了一些 MP 中经常会用到的用法。
一、引入 MyBatis-Plus 的依赖
首先创建一个 SpringBoot 的项目,然后引入其依赖,依赖如下:
<!--mybatis-plus--><dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>3.4.3.2</version></dependency><!--mysql依赖--><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId></dependency><!--lombok用来简化实体类--><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency>
这里,引入了 MyBatis-Plus、MySQL 和 Lombok 几个依赖。MyBatis-Plus 是 MP 的依赖,mysql 是对 MySQL 数据库支持的依赖, Lombok 是用来简化开发的相关依赖。
前面提到 MP 是 MyBatis 的增强插件,我们通过 jar 包的依赖可以看出,具体如下:
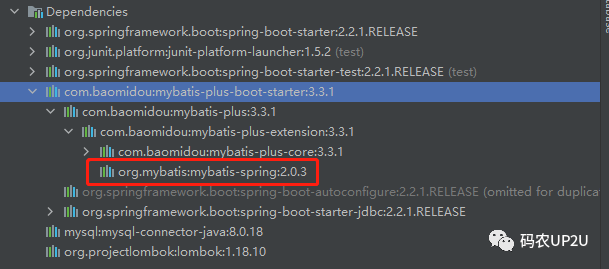
二、快速开始
在 MP 的文档当中的 “快速开始” 下提供了测试用的 表结构 和 数据,代码如下:
DROP TABLE IF EXISTS user;CREATE TABLE user(id BIGINT(20) NOT NULL COMMENT '主键ID',name VARCHAR(30) NULL DEFAULT NULL COMMENT '姓名',age INT(11) NULL DEFAULT NULL COMMENT '年龄',email VARCHAR(50) NULL DEFAULT NULL COMMENT '邮箱',PRIMARY KEY (id));DELETE FROM user;INSERT INTO user (id, name, age, email) VALUES(1, 'Jone', 18, 'test1@baomidou.com'),(2, 'Jack', 20, 'test2@baomidou.com'),(3, 'Tom', 28, 'test3@baomidou.com'),(4, 'Sandy', 21, 'test4@baomidou.com'),(5, 'Billie', 24, 'test5@baomidou.com');
在 MP 的官网中,上面的表是建立在 H2 这个内存库中的,而我们这里使用的是 MySQL 数据库。
我们创建一个 User 表对应的实体类 User.java,代码如下:
public class User {private Long id;private String name;private Integer age;private String email;}
接着,创建一个 User 实体类的对应的 Mapper,代码如下:
public interface UserMapper extends BaseMapper<User> {}
我本人喜欢使用 @Mapper 注解。
三、配置数据库连接
在 application.yml 中配置数据库的连接,配置如下:
spring:datasource:: com.mysql.cj.jdbc.Driverurl: jdbc:mysql://localhost:3306/mybatis_plus?serverTimezone=GMT%2B8&characterEncoding=utf8username: rootpassword::configuration:: org.apache.ibatis.logging.stdout.StdOutImpl
四、MP 的常用用法
上面就完成了准备的工作,接下来在测试类中,来介绍 MP 的常用用法
1. Select 的用法
在 MP 的官网中给出了关于 select 查询的相关方法列表,列表如下:
// 根据 ID 查询T selectById(Serializable id);// 根据 entity 条件,查询一条记录T selectOne( Wrapper<T> queryWrapper);// 查询(根据ID 批量查询)List<T> selectBatchIds( Collection<? extends Serializable> idList);// 根据 entity 条件,查询全部记录List<T> selectList( Wrapper<T> queryWrapper);// 查询(根据 columnMap 条件)List<T> selectByMap( Map<String, Object> columnMap);// 根据 Wrapper 条件,查询全部记录List<Map<String, Object>> selectMaps( Wrapper<T> queryWrapper);// 根据 Wrapper 条件,查询全部记录。注意:只返回第一个字段的值List<Object> selectObjs( Wrapper<T> queryWrapper);// 根据 entity 条件,查询全部记录(并翻页)IPage<T> selectPage(IPage<T> page, Wrapper<T> queryWrapper);// 根据 Wrapper 条件,查询全部记录(并翻页)IPage<Map<String, Object>> selectMapsPage(IPage<T> page, Wrapper<T> queryWrapper);// 根据 Wrapper 条件,查询总记录数Integer selectCount( Wrapper<T> queryWrapper);
这里先来介绍相对最简单的用法,selectList 方法的用法,代码如下:
void selectList(){List<User> users = userMapper.selectList(null);users.forEach(System.out::println);}
通过上面的代码,就查询出了 user 表中的全部记录,查看 console 中的输出日志,代码如下:
==> Preparing: SELECT id,name,age,email FROM user==> Parameters:<== Columns: id, name, age, email<== Row: 2, Jack, 20, test2@baomidou.com<== Row: 3, Tom, 28, test3@baomidou.com<== Row: 4, Sandy, 21, test4@baomidou.com<== Row: 5, Billie, 24, test5@baomidou.com<== Row: 1429818474686480386, ??, 20, test@qq.com<== Row: 1429819050690265090, 李斯, 20, test@qq.com<== Row: 1429824642158870530, 张三, 20, test@qq.com<== Row: 1429824869062291457, 周星星, 20, test@qq.com<== Row: 1430549049609277442, 周星星, 20, test@qq.com<== Row: 1431465861985271810, 王五, 20, test@qq.com<== Total: 10
在 select 方法中有一个 Wrapper 的条件构造器,它提供了各种复杂的查询方法,比如常用的有 eq、in、like、between 等。这里给出几个例子,首先是关于 eq 的使用方法,代码如下:
@Testvoid testSelectEq(){QueryWrapper<User> userQueryWrapper = new QueryWrapper<>();userQueryWrapper.eq("name", "tom");List<User> users = userMapper.selectList(userQueryWrapper);users.forEach(System.out::println);}
上面的代码是查询 name 字段为 tom 的记录。在来查看关于 like 的用法,代码如下:
void testSelectLike(){QueryWrapper<User> userQueryWrapper = new QueryWrapper<>();userQueryWrapper.like("name", "t");List<User> users = userMapper.selectList(userQueryWrapper);users.forEach(System.out::println);}
上面的代码是查询 name 字段中包含 t 字符的记录,其 SQL 语句如下:
SELECT id,name,age,email FROM user WHERE name LIKE '%t%' MyBatis-Plus 为我们提供了 likeLeft 和 likeRight 的方法,表示其中的 % 在字符串的左侧或右侧。接着再来演示关于 between 的用法,代码如下:
void testSelectBetween(){QueryWrapper<User> userQueryWrapper = new QueryWrapper<>();userQueryWrapper.between("age", 21, 24);List<User> users = userMapper.selectList(userQueryWrapper);users.forEach(System.out::println);}
上面的代码是查询 age 字段在 21 到 24 范围之内的。接着再介绍关于 order 的用法,代码如下:
void testSelectOrder(){QueryWrapper<User> userQueryWrapper = new QueryWrapper<>();userQueryWrapper.orderByDesc("id");List<User> users = userMapper.selectList(userQueryWrapper);users.forEach(System.out::println);}
上面的代码是以 id 的倒序来进行查询显示,代码类似于 order by id desc 这样的形式。接着介绍一下如何使用 limit 来进行限制返回记录的条数,代码如下:
void testSelectLimit(){QueryWrapper<User> userQueryWrapper = new QueryWrapper<>();userQueryWrapper.last("limit 2");List<User> users = userMapper.selectList(userQueryWrapper);users.forEach(System.out::println);}
在 MP 的 QueryWrapper 中并没有提供 limit 方法,而是使用 last 方法。
上面整理的是关于 selectList 和 QueryWrapper 构造器的内容,对于查询而言,这两种方法用的较多。在 select 中除了可以传入 QueryWrapper 外,还可以传入 Map,只是方法不再使用 selectList,而是改用 selectByMap。这里就不再进行演示。
在项目中,除了会用到条件查询外,更多的是使用 ID 进行查询,这里介绍两个关于查询 ID 的方法,分别是 selectById 和 selectBatchIds 两个方法。演示代码分别如下:
/*** 1个ID的批量查询*/@Testvoid testSelectId(){User user = userMapper.selectById(1L);System.out.println(user);}/*** 多个ID的批量查询*/@Testvoid testSelectBatchIds(){List<User> users = userMapper.selectBatchIds(Arrays.asList(1, 2, 3));System.out.println(users);users.forEach(System.out::println);}
上面的代码使用 selectById 查询了 ID 为 1 的记录,使用 selectBatchIds 查询了 ID 为 1、2、3 的记录。
2. 分页查询
除了上面的查询外,通常我们在查询时会使用分页,分页功能是 MP 的一个插件功能,首先要配置插件,配置代码如下:
public class MpConfig {/*** 分页插件*/public MybatisPlusInterceptor mybatisPlusInterceptor() {MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL));return interceptor;}}
进行配置,就可以进行分页查询,代码如下:
/*** 分页查询*/void testSelectPage(){Page<User> page = new Page<>(1, 3);Page<User> userPage = userMapper.selectPage(page, null);// 返回对象得到分页所有数据// 总页数long pages = userPage.getPages();// 当前页long current = userPage.getCurrent();// 查询数据集合List<User> records = userPage.getRecords();// 表中的总记录数long total = userPage.getTotal();// 是否有下一页boolean hasNext = userPage.hasNext();// 是否有上一页boolean hasPrevious = userPage.hasPrevious();records.forEach(System.out::println);System.out.println("总页数" + pages);System.out.println("当前页" + current);System.out.println("表中的总记录数" + total);System.out.println("是否有下一页" + hasNext);System.out.println("是否有上一页" + hasPrevious);}
上面就是关于分页的代码,输出结果如下:
==> Preparing: SELECT COUNT(*) FROM user==> Parameters:<== Columns: COUNT(*)<== Row: 5<== Total: 1==> Preparing: SELECT id,name,age,email FROM user LIMIT ?==> Parameters: 3(Long)<== Columns: id, name, age, email<== Row: 1, Jone, 18, test1@baomidou.com<== Row: 2, Jack, 20, test2@baomidou.com<== Row: 3, Tom, 28, test3@baomidou.com<== Total: 3Closing non transactional SqlSession [org.apache.ibatis.session.defaults.DefaultSqlSession@2f651f93]User(id=1, name=Jone, age=18, email=test1@baomidou.com)User(id=2, name=Jack, age=20, email=test2@baomidou.com)User(id=3, name=Tom, age=28, email=test3@baomidou.com)总页数2当前页1表中的总记录数5是否有下一页true是否有上一页false
3. 插入记录
关于插入相关一共有三方面的内容,分别是插入数据、主键生成和自动填充。
先来进行一次简单的数据插入,代码如下:
/*** 添加*/@Testvoid testInsert(){User user = new User();user.setName("张三");user.setAge(20);user.setEmail("test@qq.com");int insert = userMapper.insert(user);System.out.println(insert);}
通过 insert 方法就可以将创建的实体类插入,我们来看一下插入时的 SQL 语句,代码如下:
==> Preparing: INSERT INTO user ( id, name, age, email ) VALUES ( ?, ?, ?, ? )==> Parameters: 1431985765138706433(Long), 张三(String), 20(Integer), test.com(String)<== Updates: 1
可以看到,插入时的 ID 非常的长,因为 MP 默认生成的 ID 使用了雪花算法。
这里,就引出了关于主键生成的内容。我们如何不使用雪花算法呢。我们的在建表的时候并没有给 id 设置 auto_increment,我们给 id 添加 auto_increment,然后修改实体类,在 id 属性上添加 @TableId(type = IdType.AUTO) 来改变生成 ID 的算法。修改上面的代码,如下:
/*** 添加*/@Testvoid testInsert(){User user = new User();user.setName("李斯");user.setAge(20);user.setEmail("test@qq.com");int insert = userMapper.insert(user);System.out.println(insert);}
执行上面的代码,观察 SQL 的输出,代码如下:
==> Preparing: INSERT INTO user ( name, age, email ) VALUES ( ?, ?, ? )==> Parameters: 李斯(String), 20(Integer), test.com(String)<== Updates: 1
可以看到上面的 SQL 语句中,在 insert 时并没有在显示的插入 id 了,打开数据库观察 id 的值,它是在上一条记录的 id 值上做了加 1 的操作。
最后一个点是在表设计时应该有三个必备的字段,分别是 id、create_time 和 update_time,这个可以查看阿里的《Java 开发手册》,具体如下:
【强制】表必备三字段:id, create_time, update_time。
说明:其中 id 必为主键,类型为 bigint unsigned、单表时自增、步长为 1。create_time, update_time
的类型均为 datetime 类型,前者现在时表示主动式创建,后者过去分词表示被动式更新。
那么,我们需要在 User 表中添加 create_time 和 update_time 两个字段,那么这两个字段可以在数据库中设置默认值,在做 insert 操作时给 create_time 和 update_time 赋值为当前时间,在做 update 操作时给 update_time 赋值为当前时间。
虽然这样的方式可以,但是这样的作法并不推荐,推荐的做法是使用程序去控制,而不是数据库去控制。但是在每次进行插入的时候,都要手动给 create_time 和 update_time 进行赋值又显麻烦。MP 为我们提供了自动填充的功能,正好为我们解决了该问题。
首先来修改 User 的实体类,修改后如下:
public class User {(type = IdType.AUTO)private Long id;private String name;private Integer age;private String email;(fill = FieldFill.INSERT)private Date createTime;(fill = FieldFill.INSERT_UPDATE)private Date updateTime;}
自动填充的需要创建一个实现了 MetaObjectHandler 接口的类,我们创建的类如下:
public class MyMpMetaObjectHandler implements MetaObjectHandler {public void insertFill(MetaObject metaObject) {this.setFieldValByName("createTime", new Date(), metaObject);this.setFieldValByName("updateTime", new Date(), metaObject);}public void updateFill(MetaObject metaObject) {this.setFieldValByName("updateTime", new Date(), metaObject);}}
实现 MetaObjectHandler 需要具体实现其中的两个接口,分别是 insertFill 和 updateFill,它们分别是 插入时填充 和 修改时填充。我们再次修改我们的 testInsert 测试方法来进行测试,观察 SQL 输出如下:
==> Preparing: INSERT INTO user ( name, age, email, create_time, update_time ) VALUES ( ?, ?, ?, ?, ? )==> Parameters: 赵高(String), 20(Integer), test.com(String), 2021-08-29 22:48:00.132(Timestamp), 2021-08-29 22:48:00.132(Timestamp)<== Updates: 1
在修改代码时我将 name 设置为了 赵高,其余的并没有进行修改,而在 SQL 的输出中可以看到 MP 为我们自动填充了 create_time 和 update_time 两个字段。
4. 更新记录
在更新记录时,也有两个知识点,第一个是使用 MP 的 updateById 方法来对记录进行更新,另外一个问题是通过 版本号(在 MP 中称为 乐观锁) 解决 ABA 的问题。
首先来使用 updateById 进行更新,我们将数据表中 id 为 1 的 age 设置为 59 岁,代码如下:
/*** 修改*/@Testvoid testUpdate(){User user = new User();user.setId(1L);user.setAge(59);int i = userMapper.updateById(user);// 影响行数System.out.println(i);}
在数据表中进行查看,id 为 1 记录的 age 变成了 59。
在某些情况下可能存在多个人同时操作一条记录,也可能一个人对同一条数据进行两次修改请求,因为某些情况第一个请求失败,而第二个请求成功了,失败的第一个请求再次重试时将第二个请求的修改覆盖掉了。这样是就有问题了。通常情况下,可以增加一个版本号,每次更新时比对一下版本号,如果版本号一样则更新(更新相关数据的同时,将版本号也自动增加),如果版本号不一致则不更新。在 MP 中称为 乐观锁。
其实这点在阿里的《Java 开发手册》中也有提到,如下所示:
【强制】并发修改同一记录时,避免更新丢失,需要加锁。要么在应用层加锁,要么在缓存加
锁,要么在数据库层使用乐观锁,使用 version 作为更新依据。
使用乐观锁需要在表中增加一个版本号,比如 version,类型为 int,然后 version 的默认值给一个 1,当然也可以使用 insertFill 自动填充为 version 赋值为 1。然后修改实体类,修改后的实体类代码如下:
public class User {private Long id;private String name;private Integer age;private String email;private Date createTime;private Date updateTime;private Integer version;}
然后增加乐观锁插件的配置,乐观锁的配置和分页的配置在同一位置,代码如下:
public MybatisPlusInterceptor mybatisPlusInterceptor() {MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL));interceptor.addInnerInterceptor(new OptimisticLockerInnerInterceptor());return interceptor;}
在修改记录前,需要先对记录进行查询,然后再进行修改,这点在阿里的《Java 开发手册》中也有提到,如下:
【强制】数据订正(特别是删除或修改记录操作)时,要先 select,避免出现误删除,确认无
误才能执行更新语句。
我们先来插入一条记录,让 version 有值之后进行测试。插入记录如下:
==> Preparing: INSERT INTO user ( name, age, email, create_time, update_time, version ) VALUES ( ?, ?, ?, ?, ?, ? )==> Parameters: 秦始皇(String), 20(Integer), test.com(String), 2021-08-29 23:16:03.012(Timestamp), 2021-08-29 23:16:03.012(Timestamp), 1(Integer)<== Updates: 1
这里插入了一个 秦始皇,查看数据库中的数据,如下图:

这里,我们来模拟一下 version 的使用,我们修改 秦始皇 的年龄,代码如下:
/*** 测试乐观锁*/@Testvoid testUpdateVersion(){// 根据ID进行查询User user = userMapper.selectById(1431985765138706436L);User user1 = userMapper.selectById(1431985765138706436L);// 修改user.setAge(1000);user1.setAge(2000);// 不需要手动setVersion(user.getVersion() + 1);userMapper.updateById(user);userMapper.updateById(user1);}
我们来看一下 SQL 的输出,代码如下:
==> Preparing: SELECT id,name,age,email,create_time,update_time,version FROM user WHERE id=?==> Parameters: 1431985765138706436(Long)<== Columns: id, name, age, email, create_time, update_time, version<== Row: 1431985765138706436, 秦始皇, 20, test@qq.com, 2021-08-29 23:16:03, 2021-08-29 23:16:03, 1<== Total: 1==> Preparing: SELECT id,name,age,email,create_time,update_time,version FROM user WHERE id=?==> Parameters: 1431985765138706436(Long)<== Columns: id, name, age, email, create_time, update_time, version<== Row: 1431985765138706436, 秦始皇, 20, test@qq.com, 2021-08-29 23:16:03, 2021-08-29 23:16:03, 1<== Total: 1==> Preparing: UPDATE user SET name=?, age=?, email=?, create_time=?, update_time=?, version=? WHERE id=? AND version=?==> Parameters: 秦始皇(String), 1000(Integer), test@qq.com(String), 2021-08-29 23:16:03.0(Timestamp), 2021-08-29 23:19:17.954(Timestamp), 2(Integer), 1431985765138706436(Long), 1(Integer)<== Updates: 1==> Preparing: UPDATE user SET name=?, age=?, email=?, create_time=?, update_time=?, version=? WHERE id=? AND version=?==> Parameters: 秦始皇(String), 2000(Integer), test@qq.com(String), 2021-08-29 23:16:03.0(Timestamp), 2021-08-29 23:19:17.983(Timestamp), 2(Integer), 1431985765138706436(Long), 1(Integer)<== Updates: 0
代码中查询了两次,第一次设置秦始皇的年龄为 1000,后来第二个人设置秦始皇的年龄为 2000,但是在第一次 updateById 后 version 的版本后被修改了,因此第二次 updateById 时发现版本号被改变了,那么就不再更新了。
5. 删除记录
删除操作通常分为物理删除和逻辑删除,物理删除表示记录被直接删掉了,而逻辑删除则表示记录被做了删除标记,实际还是存在的。
先来看看物理删除,代码如下:
/*** 物理删除*/@Testvoid testDelete(){int i = userMapper.deleteById(1431985765138706436L);System.out.println(i);}
这里通过 deleteById 将指定 id 的记录进行了删除。来看一下 SQL 语句,代码如下:
==> Preparing: DELETE FROM user WHERE id=?==> Parameters: 1431985765138706436(Long)<== Updates: 1
接着,我们来进行逻辑删除,逻辑删除同样需要在数据表中增加一个标志位,比如 deleted,在 MP 中,默认 0 为未删除,1 为已删除。这里我们在添加字段时给一个默认值为 0,同样也可以使用 insertFill 自动填充时赋值为 0。
添加字段后,修改实体类,修改后的实体类如下:
public class User {private Long id;private String name;private Integer age;private String email;private Date createTime;private Date updateTime;private Integer version;private Integer deleted;}
然后写逻辑删除的代码,代码如下:
/*** 逻辑删除*/@Testvoid testDeleteLogic(){int i = userMapper.deleteById(1431985765138706435L);System.out.println(i);}
看起来和物理删除的代码相同,但是观察 SQL 语句的输出,代码如下:
==> Preparing: UPDATE user SET deleted=1 WHERE id=? AND deleted=0==> Parameters: 1431985765138706435(Long)<== Updates: 1
可以看到,逻辑删除实际上是对 deleted 字段的 update 操作。然后,我们执行最上面的查询操作(即:selectList 方法),查看执行的 SQL 输出,代码如下:
==> Preparing: SELECT id,name,age,email,create_time,update_time,version,deleted FROM user WHERE deleted=0 可以看到,在我们使用了逻辑删除后,调用 MP 的查询方法时,会默认的在 SQL 语句中加入 deleted = 0 的条件。
五、总结
本篇内容整理了 MyBatis-Plus 的常用用法,其中涉及到了 自动填充、分页、乐观锁 和 逻辑删除 的内容。期间还涉及到了阿里的《Java 开发手册》中的内容。想必这些内容也都是实际项目中经常用到的功能,希望可以对大家有所帮助。觉得有用就点个“在看”吧!!
更多文章