
Python 函数式编程,看这一篇就够了!


def foo():
print("foo")bar = foo
bar()
#will print "foo" to the consoleclass Greeter:
def __init__(self, greeting):
self.greeting = greeting
def __call__(self, name):
return self.greeting + " " + namemorning = Greeter("good morning") #creates the callable object
morning("john") # calling the object
#prints "good morning john" to the consolecallable(morning) #true
callable(145) #false. int is not callable. # store in dictionary
mapping = {
0 : foo,
1 : bar
}
x = input() #get integer value from user
mapping[x]() #call the func returned by dictionary access「高阶函数允许我们对动作执行抽象,而不只是抽象数值。」
def iterate(list_of_items):
for item in list_of_items:
print(item)
看起来很酷吧,但这只不过是一级抽象而已。如果我们想在对列表执行迭代时进行打印以外的其他操作要怎么做呢?
def iterate_custom(list_of_items, custom_func):
for item in list_of_items:
custom_func(item)def add(x, y):
return x + y
def sub(x, y):
return x - y
def mult(x, y):
return x * y
def calculator(opcode):
if opcode == 1:
return add
elif opcode == 2:
return sub
else:
return mult
my_calc = calculator(2) #my calc is a subtractor
my_calc(5, 4) #returns 5 - 4 = 1
my_calc = calculator(9) #my calc is now a multiplier
my_calc(5, 4) #returns 5 x 4 = 20.
嵌套函数
def fib(n):
def fib_helper(fk1, fk, k):
if n == k:
return fk
else:
return fib_helper(fk, fk1+fk, k+1)
if n <= 1:
return n
else:
return fib_helper(0, 1, 1)
将该计算从函数主体移到函数参数,这具备非常强大的力量。因为它减少了递归方法中可能出现的冗余计算。
mult = lambda x, y: x * y
mult(1, 2) #returns 2
该 mult 函数的行为与使用传统 def 关键字定义函数的行为相同。
(lambda x, y: x * y)(9, 10) #returns 90import collections
pre_fill = collections.defaultdict(lambda: (0, 0))
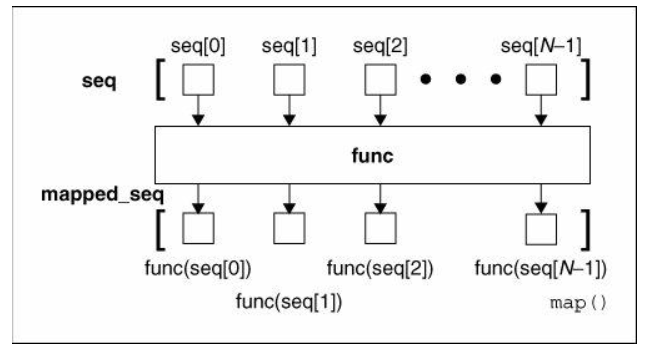
#all dictionary keys and values are set to 0def multiply_by_four(x):
return x * 4
scores = [3, 6, 8, 3, 5, 7]
modified_scores = list(map(multiply_by_four, scores))
#modified scores is now [12, 24, 32, 12, 20, 28]
在 Python 3 中,map 函数返回的 map 对象可被类型转换为 list,以方便使用。现在,我们无需显式地定义 multiply_by_four 函数,而是定义 lambda 表达式:
modified_scores = list(map(lambda x: 4 * x, scores))even_scores = list(filter(lambda x: True if (x % 2 == 0) else False, scores))
#even_scores = [6, 8]sum_scores = reduce((lambda x, y: x + y), scores)
#sum_scores = 32Best Practices for Using Functional Programming in Python:https://kite.com/blog/python/functional-programming/
Functional Programming Tutorials and Notes:https://www.hackerearth.com/zh/practice/python/functional-programming/functional-programming-1/tutorial/
原文链接:https://medium.com/better-programming/introduction-to-functional-programming-in-python-3d26cd9cbfd7
END
推荐阅读
吴恩达deeplearining.ai的经典总结资料
Ps:从小程序直接获取下载
评论