
stack vs heap:栈区分配内存快还是堆区分配内存快 ?
后台有读者问到底是从栈上分配内存快还是从堆上分配内存快,这是个比较基础的问题,今天就来聊一聊。
栈区的内存申请与释放
毫无疑问,显然从栈上分配内存更快,因为从栈上分配内存仅仅就是栈指针的移动而已,这是什么意思呢?什么叫做“栈指针的移动”?以x86平台为例,在栈上分配内存是怎样实现的呢?很简单,就一行指令:
sub $0x40,%rsp
这行代码就叫做“栈指针的移动”,其本质就是这张图:
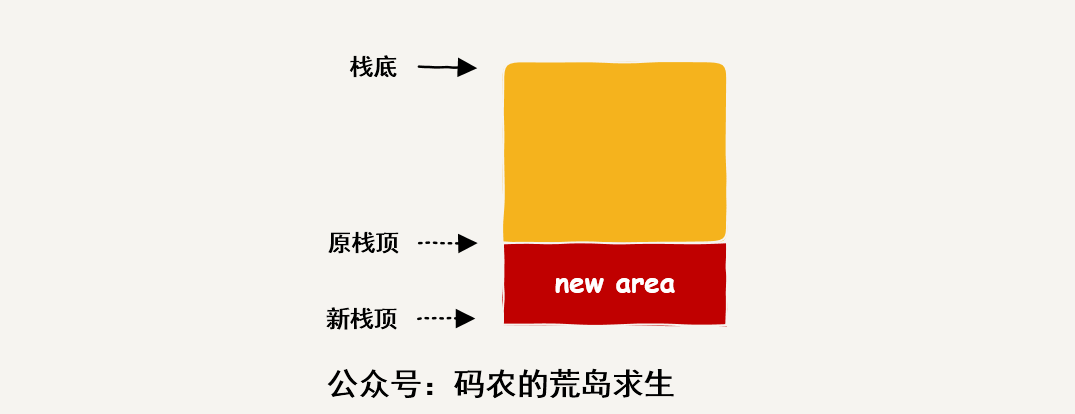
很简单,寄存器esp中保存的是当前栈的栈顶地址,由于栈的增长方向是从高地址到低地址,因此增大栈时需要将栈指针向下移动,即sub指令的作用,这条指令将栈顶指针向下移动了64字节(0x40),因此可以说在栈上分配了64字节。
可以看到,在栈上分配内存其实非常非常简单,简单到就只有一条机器指令。
而栈区的内存释放也非常简单,也是只需要一条机器指令:
leave
leave指令的作用是将栈基址赋值给esp,这样栈指针指向上一个栈帧的栈顶,然后pop出ebp,这样ebp就指向上一个栈帧的栈底:
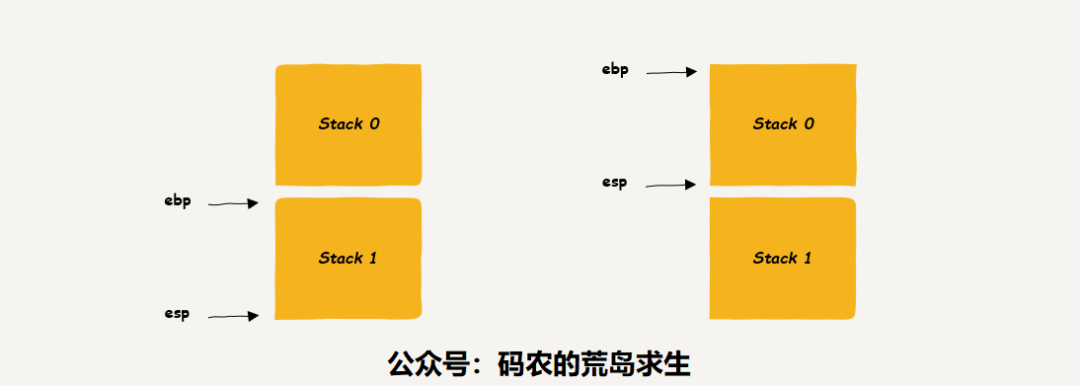
看到了吧,执行完leave指令后ebp以及esp就指向上一个栈帧了,这就相当于栈帧的弹出,pop,这样stack 1占用的内存就无效了,没有任何用处了,显然这就是我们常说的内存回收,因此简单的一条leave指令就可以回收掉栈区中的内存。
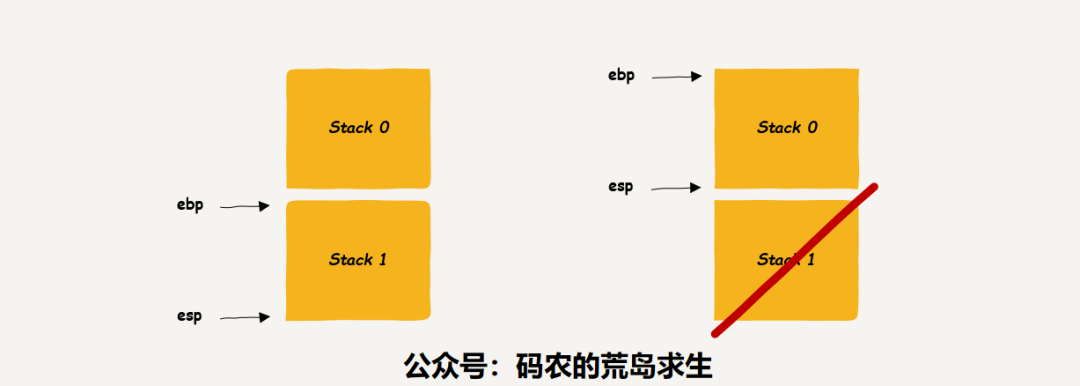
接下来我们看到堆区的内存申请与释放。
堆区的内存申请与释放
与栈区分配内存相对的是堆内存分配,堆区分配内存有多复杂呢?
在堆区上申请与释放内存是一个相对复杂的过程,因为堆本身是需要程序员(内存分配器实现者)自己管理的,而栈是编译器来维护的,堆区的维护同样涉及内存的分配与释放,但这里的内存分配与释放显然不会像栈区那样简单,一句话,这里是按需进行内存的分配与释放,本质在于堆区中每一块被分配出去的内存其生命周期都不一样,这是由程序员决定的,我倾向于把内存动态分配释放想象成去停车场找停车位。
这显然会让问题复杂起来,我们必须小心的维护哪些内存是已经分配出去的以及哪些是空闲的、该怎样找到一块空闲的内存、该怎样回收程序员不需要的内存块、同时还不能有严重的内存碎片问题,栈区分配释放内存都无需关心这些问题,于此同时当堆区内存空间不足时还需要扩大堆区等等,这些都使得在堆区申请内存要比在栈区分配内存复杂的多。
说了这么多,那么在堆区上申请内存要比在栈上申请内存慢多少呢?
接下来我们写段代码实验一下。
show me the code
void test_on_stack() {
int a = 10;
}
void test_on_heap() {
int* a = (int*)malloc(sizeof(int));
*a = 10;
free(a);
}
void test() {
auto begin = GetTimeStampInUs();
for (int i = 0; i < 100000000; ++i) {
test_on_stack();
}
cout<<"test on stack "<<((GetTimeStampInUs() - begin) / 1000000.0)<
begin = GetTimeStampInUs();
for (int i = 0; i < 100000000; ++i) {
test_on_heap();
}
cout<<"test on heap "<<((GetTimeStampInUs() - begin) / 1000000.0)<}
这段代码非常简单,这里有两个函数:
test_on_stack函数中定义一个局部变量,这就是从栈上申请一个整数大小的内存空间 test_on_heap函数从堆上申请一个整数大小的内存空间
然后我们在测试函数中分别调用这两个函数,每一个调用1亿次,记录下需要运行的时间,得到的测试结果为:
test on stack 0.191008
test on heap 20.0215
可以看到,在栈上总耗时只有大概0.2s,而在堆上分配的耗时为20s,相差百倍。
值得注意的是,这里在编译程序时没有开启编译优化,开启编译优化后的耗时是这样的:
test on stack 0.033521
test on heap 0.039294
可以看到,相差无几,可这是为什么呢?显然从常理推断在栈上分配要更快一些,问题会出在哪里呢?
既然我们开启了编译优化,那是不是优化后的代码运行的更快了呢,我们来看下编译优化后生成的指令都有啥:
test_on_stackv:
400f85: 55 push %rbp
400f86: 48 89 e5 mov %rsp,%rbp
400f89: 5d pop %rbp
400f8a: c3 retq
test_on_heapv:
400f8b: 55 push %rbp
400f8c: 48 89 e5 mov %rsp,%rbp
400f8f: 5d pop %rbp
400f90: c3 retq
啊哈,编译器实在是太聪明了,它显然注意到这两个函数中的代码实际上啥也没干,即使我们还专门为变量a赋值为了10,但后续我们根本就没有用到变量a,因此编译器给我们生成了一个空函数,上面这些机器指令实际上对应一个空函数。
小风哥反复在这里添加代码都没有骗过编译器,我试图加大变量a赋值的复杂度,编译器依然很聪明的生成了一个空函数,反正我是没有试出来,可见现代编译器是足够智能的,生成的机器指令效率很高,关于该怎样写出一个更好的benchmark,从而让我们可以看到在开启编译优化的情况下这两种内存分配方式的对比,欢迎任何对此有心得或者对编译优化有心得的同学留言。
最后让我们来看看这两种内存分配方式的定位。
栈内存与堆内存的差异
首先我们必须意识到,栈是一种先进后出的结构,栈区会随着函数调用层级的增加而增大,而随着函数调用完成而减少,因此栈是无需任何“管理”的;与此同时由于栈的这种性质,在栈上申请的内存其生命周期是和函数绑定在一起,当函数调用完成后其占用的栈帧内存将无效,且栈的大小是有限的,你不能在栈上申请过多内存,就像这样一段C代码:
void test() {
int b[10000000];
b[1000000] = 10;
}
这段代码运行起来后会core掉,原因就在于栈区大小是非常有限的,在栈上分配一大块数据会让栈撑爆掉,这就是所谓的Stack Overflow:
额。。。不好意思,图放错了,应该是这个Stack Overflow:

不好意思,又放错了,总之你懂得。
而堆则不同,在堆上分配的内存其生命周期是受程序员控制的,程序员决定什么时候申请内存,什么时候释放内存,因此堆是必须被管理起来的,堆区是一片很广阔的区域,堆区空间不足时会向操作系统请求扩大堆区从而获得更多地址空间。
当然,堆区在给程序员更大灵活性的同时需要程序员确保内存在不被使用时释放掉,否则会内存泄漏,在栈上申请内存则不存这个问题。
总结
栈区是自动管理的,堆区是手动管理的,显然在栈区上分配内存要比在堆区上更快,当在栈区上申请的内存使用场景有限,程序员申请内存时还要更多的依靠堆区,但是在栈区申请的内存满足要求的情况我个人更倾向于使用栈区内存。
希望这篇文章对大家理解堆区栈区有所帮助。