如何使用 Kubernetes 监测定位慢调用
大家好,我是阿里云的李煌东。今天我为大家分享 Kubernetes 监测公开课第四节,如何使用 Kubernetes 监测定位慢调用。今天的课程主要分为三大部分,首先我会介绍一下慢调用的危害以及常见的原因;其次我会介绍慢调用的分析方法以及最佳实践;最后通过几个案例来去演示一下慢调用的分析过程。
慢调用危害及常见原因
Cloud Native
前端业务维度:首先慢调用可能会引起前端加载慢的问题,前端加载慢可能会进一步导致应用卸载率高,进而影响品牌的口碑。
项目交付的维度:由于接口慢导致达不到 SLO,进而导致项目延期。
业务架构稳定性:当接口调用慢时,非常容易引起超时,当其他业务服务都依赖这个接口,那么就会引发大量重试,进而导致资源耗尽,最终导致部分服务或者整个服务不可用的雪崩的现象。
第一个是资源使用率过高问题,比如说 CPU 内存、磁盘、网卡等等。当这些使用率过高的时候,非常容易引起服务慢。
第二个是代码设计的问题,通常来说如果 SQL 它关联了很多表,做了很多表,那么会非常影响 SQL 执行的性能。
第三个是依赖问题,服务自身没有问题,但调用下游服务时下游返回慢,自身服务处于等待状态,也会导致服务慢调用的情况。
第四个是设计问题,比如说海量数据的表非常大,亿级别数据查询没有分库分表,那么就会非常容易引起慢查询。类似的情况还有耗时的操作没有做缓存。
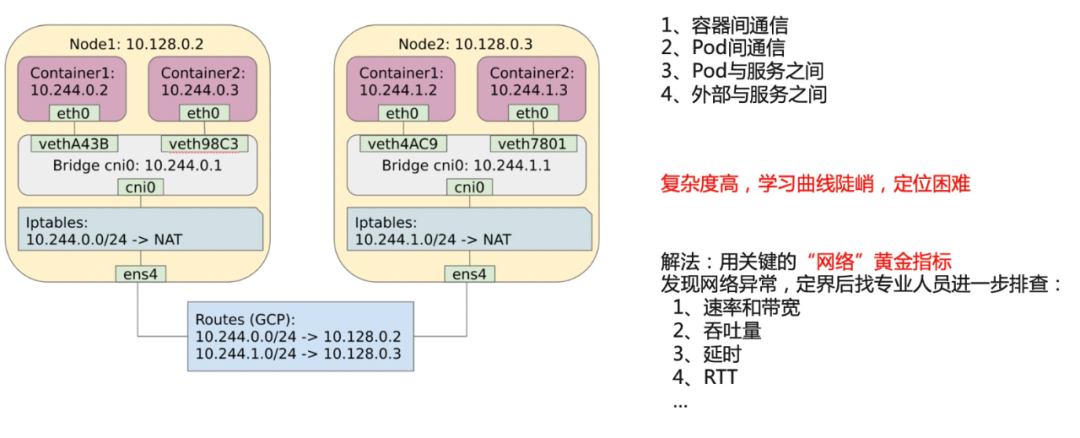
第五个是网络方面问题,比如说跨洲调用,跨洲调用是物理距离太大了,导致往返时间比较长,进而导致慢调用。或者两点之间的网络性能可能比较差。比如说有丢包重传率,重传率高的问题。

延时--用来描述系统执行请求花费的时间。常见指标包括平均响应时间,P90/P95/P99 这些分位数,这些指标能够很好的表征这个系统对外响应的快还是慢,是比较直观的。
流量--用来表征服务繁忙程度,典型的指标有 QPS、TPS。
错误--也就是我们常见的类似于协议里 HTTP 协议里面的 500、400 这些,通常如果错误很多的话,说明可能已经出现问题了。
饱和度--就是资源水位,通常来说接近饱和的服务比较容易出现问题,比如说磁盘满了,导致日志没办法写入,进而导致服务响应。典型的那些资源有 CPU、 内存、磁盘、队列长度、连接数等等。
慢调用最佳实践
Cloud Native
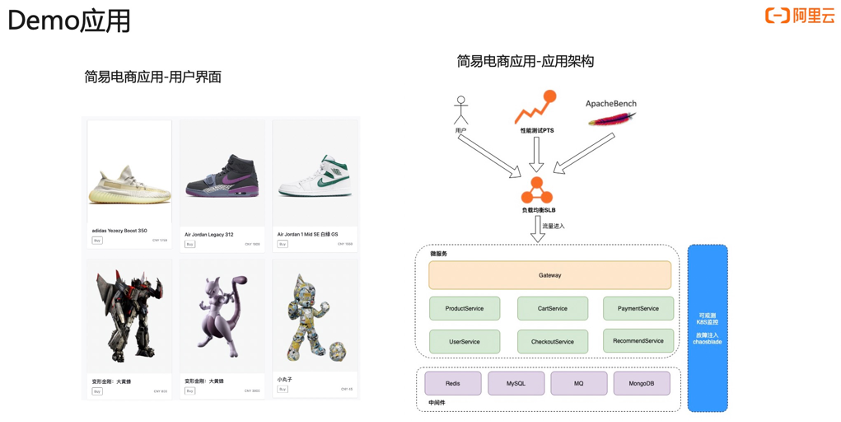
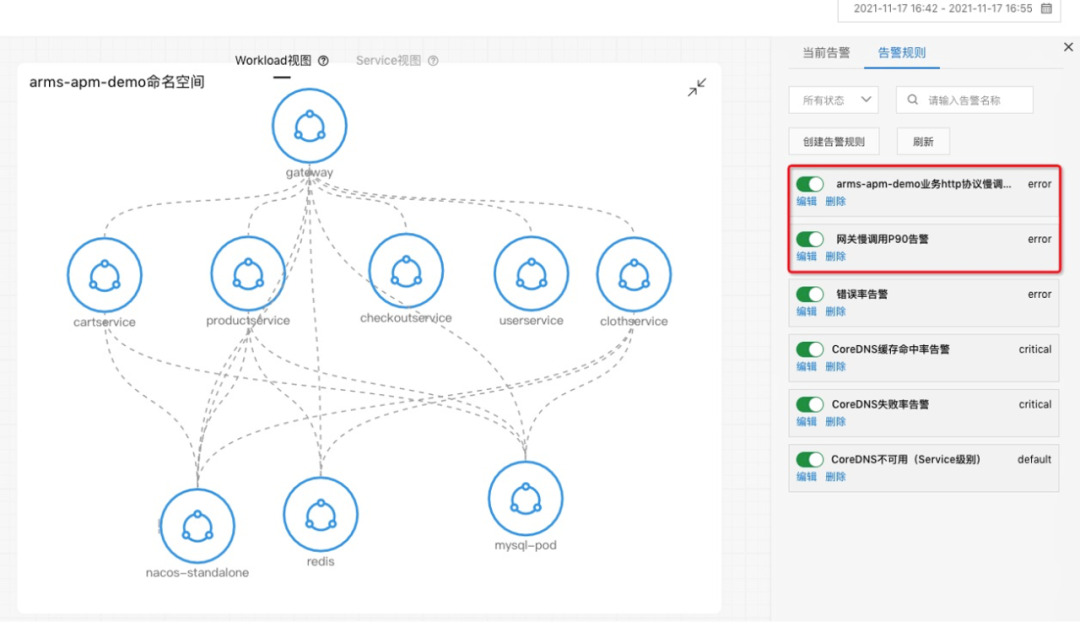
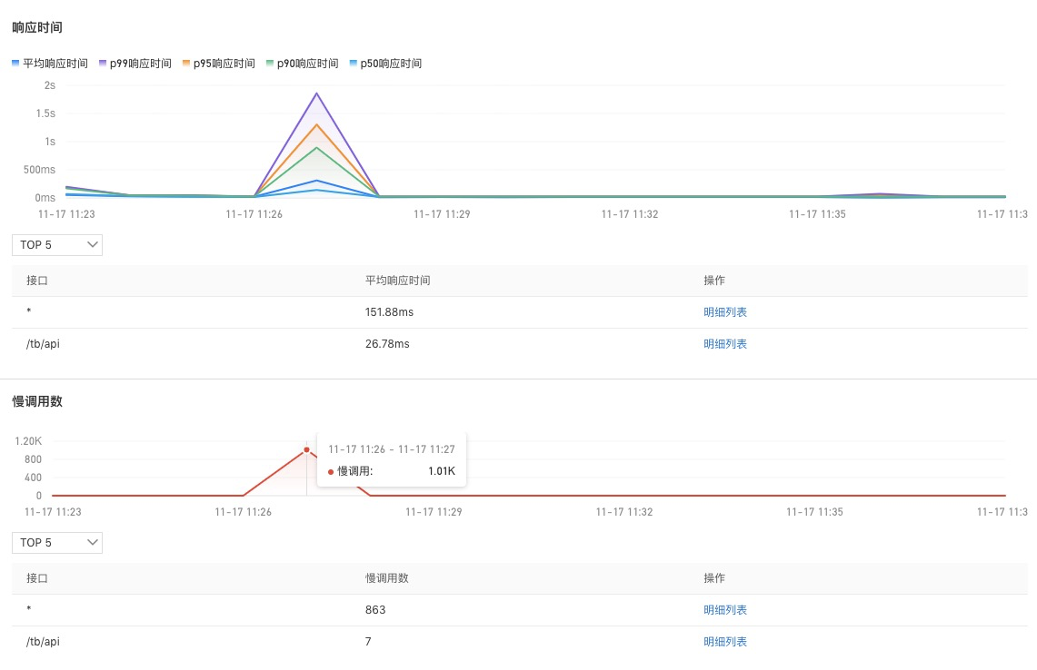

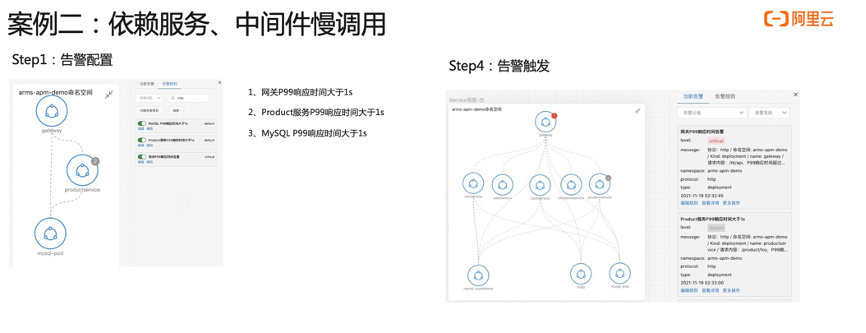
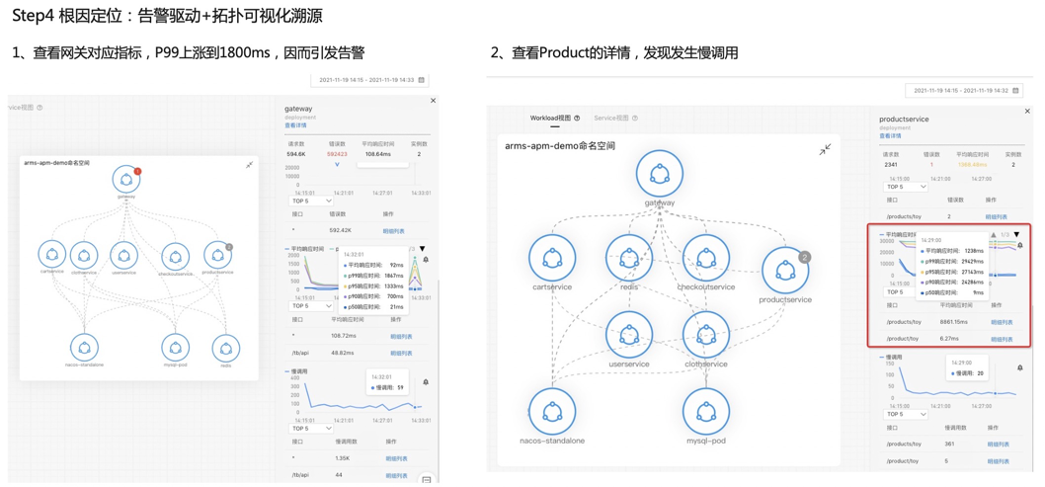
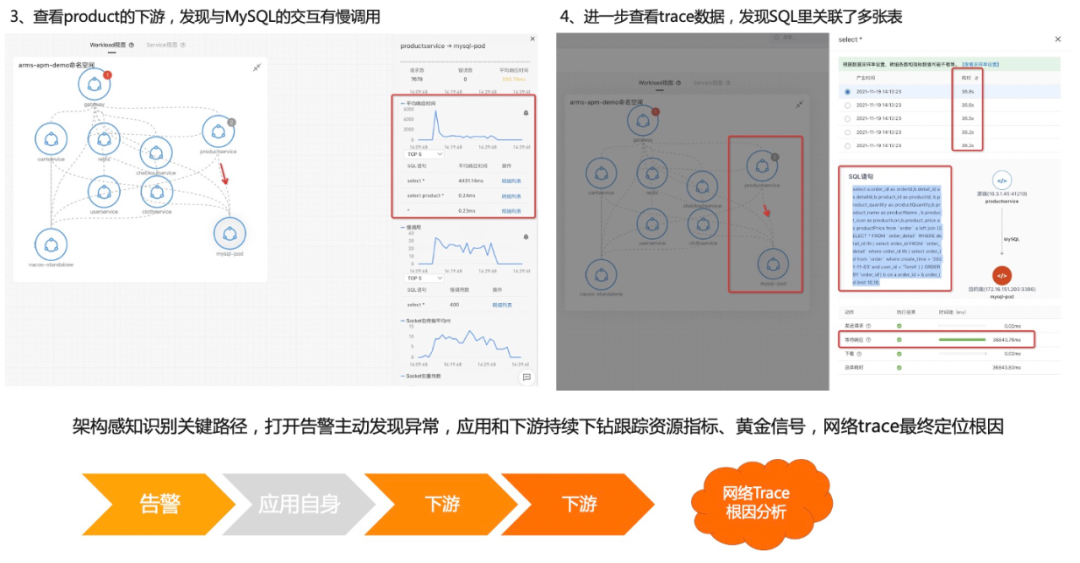
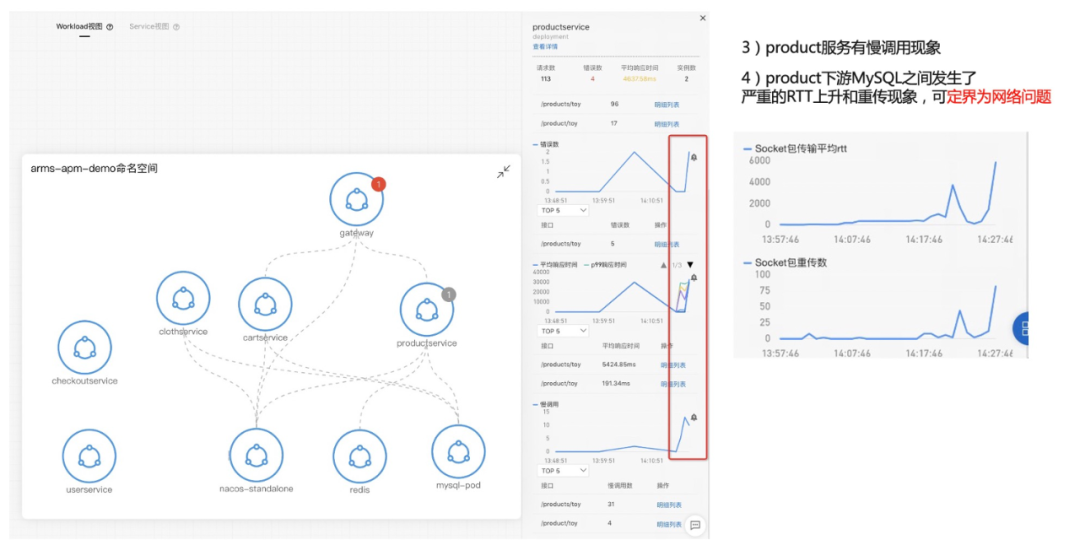
接下来我们看第二个案例。首先介绍一下准备工作,左边这边图我们可以看到网关进来掉了两个下游服务,一个是 MySQL ,一个是 ProductService,所以在网关上直接配置一个大于一秒的告警,平均响应时间 P99 大于一秒的告警。第二步我们看这个 Product 也是在关键链路上面,我给它配一个 P99 大于一秒的告警,第三个是 MySQL ,也配一个大于一秒的告警,配完之后,我会在 Product 这个服务上面去注入一个 MySQL 慢查询的故障,大概等到两分钟之后,我们就可以看到陆续告警就触发出来了,网关跟 Product 上面都有一个红点跟一个灰色的点,这一点其实就是报出来的故障,报出的告警事件,Kubernetes 监测会把这个告警事件通过命名空间应用自动的 match 到这个节点上面,所以能够一眼的看出哪些服务、哪些应用是异常的,这样能够快速定位出问题所在。我们现在收到告警了之后,下一步去进行一个根因定位。