
Python实用小工具之文件内容替换
咪哥杂谈
本篇阅读时间约为 6 分钟。
1
前言
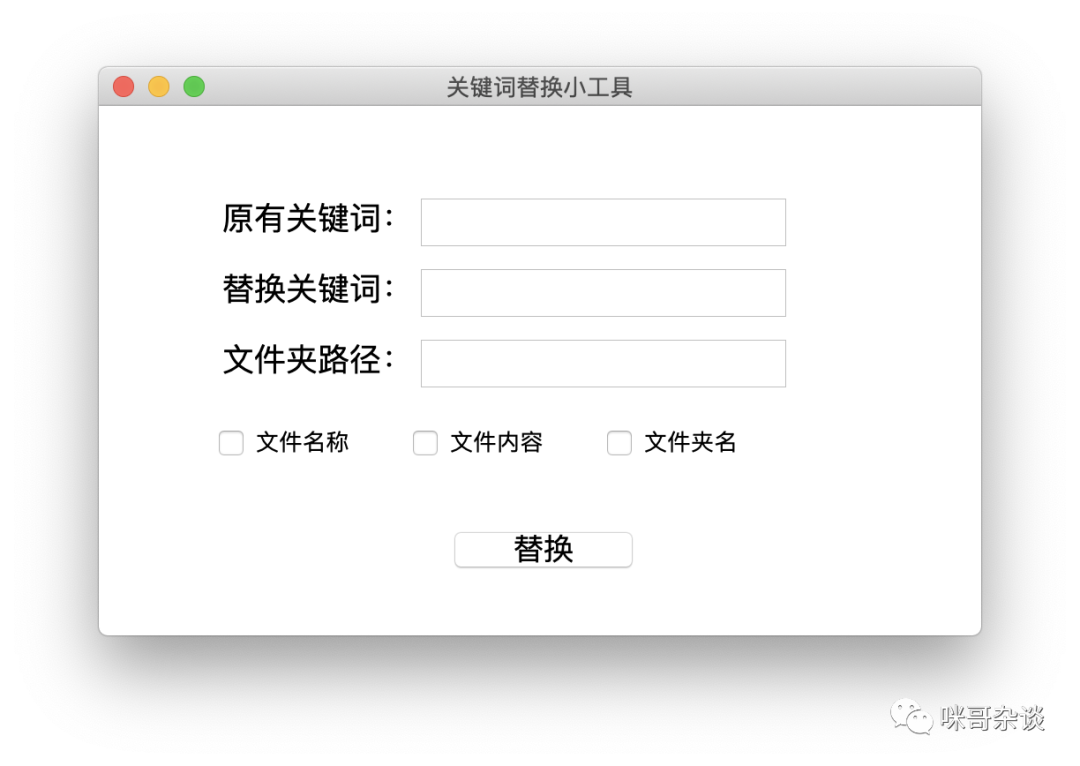
上周用 Python 帮同学写了一个文件以及文件内容替换的小工具,原本是没有界面的,纯属编码,后来为了做成小工具,特意加上了界面。
今天上来给大家分享一下,有需要可以自取。
关于代码部分,我会在这篇文章里将我遇到的难点写出来,后续如果有同学遇到相同的问题,可以有个参考。
废话不多说,我录了一段视频,感兴趣的同学可以看下演示。
2
视频演示
3
用到的技术
用到的库有三种,分别是:
tkinter (画界面自带的Python库)
os (Python自带的系统库)
chardet (识别文件编码用的第三方库)
4
遇到的难点
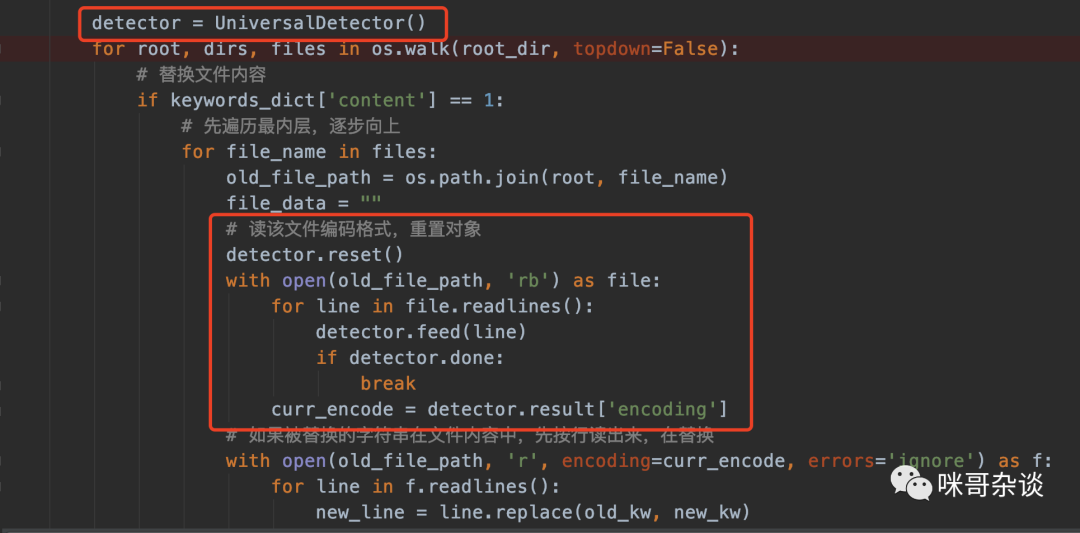
Python读取文件内容的时候,会经常遇到编码不一致导致内容报错,此处便是整个小程序最大的难点。
有没有办法能解决不同文件,编码自动识别的方法?那就是上面提到的 chardet(编码甄别)可以这么实现:
# 读该文件编码格式with open(old_file_path, 'rb') as file:curr_encode = chardet.detect(file.read())['encoding']# 如果被替换的字符串在文件内容中,先按行读出来,在替换with open(old_file_path, 'r', encoding=curr_encode, errors='ignore') as f:for line in f.readlines():........
通过这种形式读取到文件内容,自动识别编码。
所以在所有处理大数据文件的时候,有一种做法叫 "分而治之" 。
我们可以通过分块的形式,逐行去"喂给" detector 进行编码识别处理。当 detector 识别到的数据达到一定程度时,detector.done会返回 True,此时就可以获取该文件的编码格式了。
如图(具体可以去看源码):
5
结语
关于这个小工具,原本我是想打成 exe 文件和 dmg 文件提供给大家的。
但那天试了一下才知道,pyinstaller 的库是根据电脑系统进行编译的,比如你的系统是 windows ,它自动打包应用出来的就是 exe,要是 mac os,打包出来的就是 unix 底层的执行文件。
所以这里就不直接提供你们成型的工具了,如果你有需要,可以后台回复 【替换】关键词,获取源码,之后你们在自己去打包吧。
不会打包的,可以参考下之前写的这篇文章。
好啦,本期视频就到这里,如果你有什么问题或者想讨论的,欢迎评论区留言探讨!期待你的留言呐!
评论