
分布式缓存的选择
AI全套:Python3+TensorFlow打造人脸识别智能小程序
最新人工智能资料-Google工程师亲授 Tensorflow-入门到进阶
黑马头条项目 - Java Springboot2.0(视频、资料、代码和讲义)14天完整版
来源:llc687.top/109.html 如今,缓存系统的应用非常广泛,能够用来提高并发数、数据吞吐量,提高快速响应能力。那么当数据量达到一定程序,单机环境可能就显得有些力不从心了,就需要一个分布式缓存系统。
1. 缓存系统的选择
图1-1
如上图所示,首先缓存大致可以分为四大类。
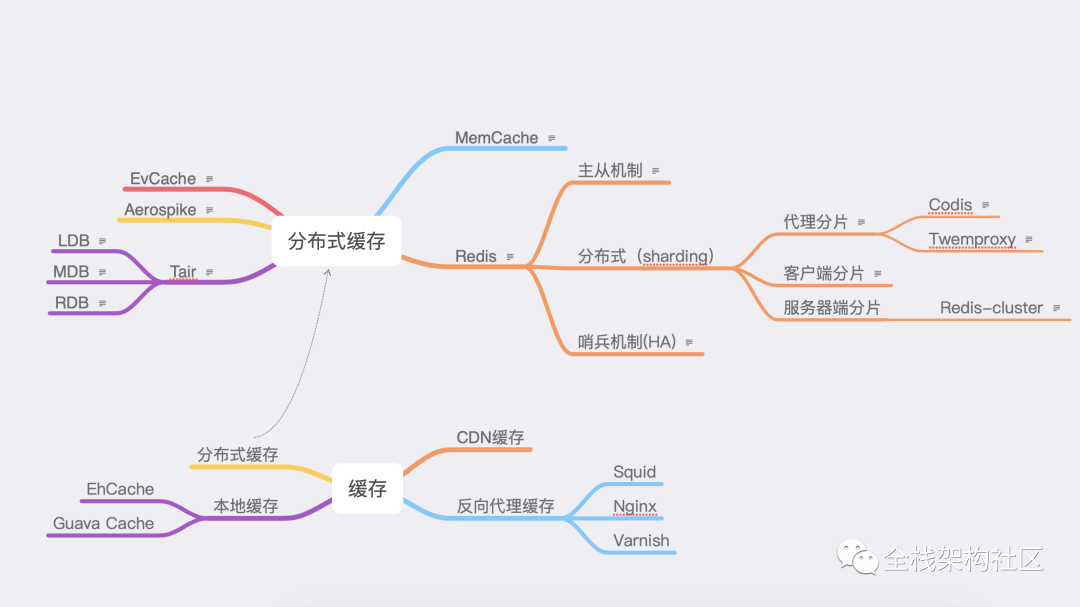
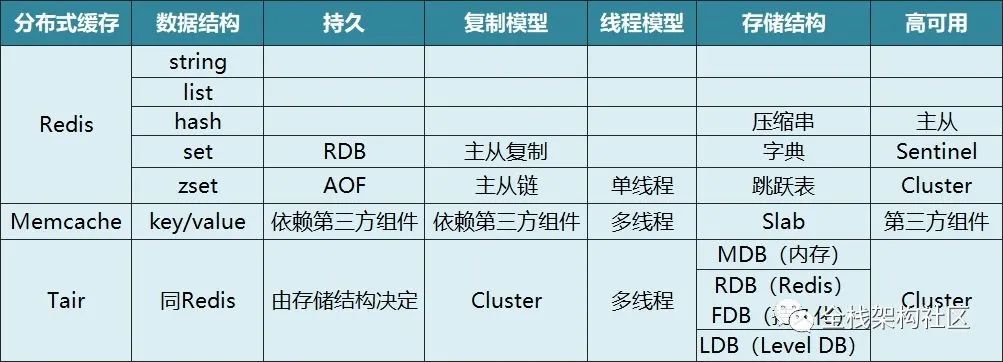
EvCache和Aerospike使用场景不是那么通用和广泛。Tair:阿里开源,跨机房、性能随结点添加线性上升、适用大数据量。Tair还有三种引擎 LDB: 基于google levelDB,支持kv和类hashmap结构,性能稍低,持久化可靠性最高。 MDB: 基于memcache,支持kv和类hashMap,性能最优,不支持持久化存储。 RDB: 基于Redis. Memcache: 不支持数据同步、分布式支持较差。 Redis: 社区活跃、使用最多。
综上所述,在一般情况下,考虑到适用性和稳定性,Redis 是搭建缓存系统的最优选择。以下将基于 Redis 介绍。
2. Redis集群缓存方案
如顶部图所示,列出了Redis的集群高可用的方案,基本可以分为三种。
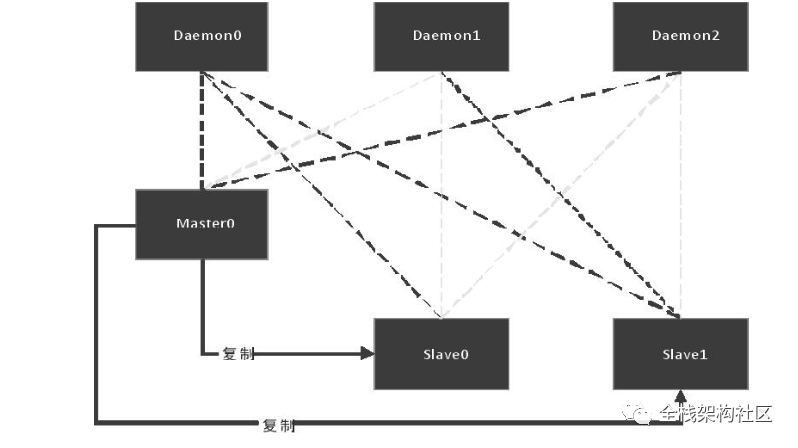
主从机制
常见的集群的架构,搭建简单,主要实现读写分离和备份,可以由 Master 负责读写,Slave 负责备份。但存在故障恢复复杂、水平拓展难、写能力受限等问题。结构图如下:

哨兵机制
"分布式"
到这里其实以上两种机制其实只能算作“集群”,并非严格意义上的“分布式”。接着来看看分布式方案。
集群强调高可用,分布式又强调协作。
3. Redis分布式缓存方案
任何分布式存储系统,首先面临的就是 sharding(分片)问题,如顶部图1-1所示可分为三种方式。
客户端分片
顾名思义,将数据分片的路由功能交给客户端,但这是一种静态分片,维护性差。基本而言是不予考虑的。
代理分片
通过代理分发到具体的redis实例。有两个常用解决方案。
Twemproxy
Twitter开源,轻量级,但不再维护,也无法平滑地扩容/缩容,运维也不是很友好,性能一般。Codis
豌豆荚开源,支持水平拓展,运维平台完善,性能较 Twemproxy 快。Codis在国内使用较多,同时代理分片的思路也有很多公司在此基础开发了自己的二次方案。不过Codis也不再维护。
其实,这两种代理分片的方案,都是在 Redis 官方未推出良好的分布式方案时的策略,在官方更新后都不再维护。
服务器端分片
这就要谈到 Redis 官方的方案 Redis-cluster 。
在 Redis3.0 之前是没有较好的分布式方案的,这也是第三方方案出现的原因。3.0 开始,官方推出了去中心化的分布式方案。集群中包含16384个散列槽,每个节点负责其中一部分。
先看下拓扑图:

每个节点打开两个TCP连接,一个负责给客户端提供服务,一个负责节点间通信。
此刻要说说 CAP了 :Consistency(一致性)、Availability(可用性)、Partition tolerance(分区容错性) 。对分布式系统而言,CAP 必须牺牲一者。Redis Cluster 的设计目标主要是高性能、高可用和高扩展, 只好抛弃一部分数据一致性.
数据一致性:由于Redis Cluster 使用异步复制, 在某些情况下如Master宕机但未同步至Slave, 可能会丢失写入。在绝对需要时支持同步写入的时候, 可通过 WAIT 命令实现, 可使得丢失写入的可能性大大降低。
可用性:当集群中一部分节点故障后, 集群整体能响应客户端读写请求。
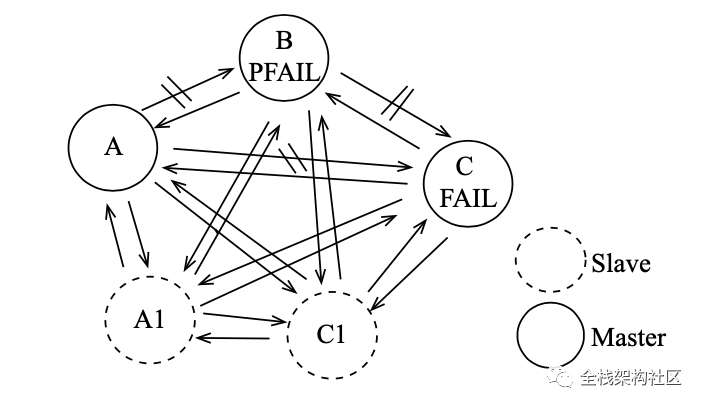
节点间定时互 ping , 当超过一半Master 判定某节点失败,则标为 FAIL, 会向集群广播节点下线的消息。如下线节点是带有槽的主节点,则要从它的从节点选出一个替换。
高性能和拓展:操作某个 key时,不会先找到节点再处理,而是直接直接重定向到该节点, 同时相较代理分片也少了 proxy 的连接损耗。
但是在进行
multiple key操作时需要keys位于同一个slot上,需要使用hash tags,使用{}强制将某些key映射到每个slot,以便进行multiple。在拓展方面,Redis Cluster 最大支持线性拓展1000个节点,将新节点加入集群后可以通过命令指定和平均的从已有节点分配slot。
3. 缓存常见问题
以上介绍了简单介绍了常见缓存系统,并具体列出了基于Redis的集群方案。下面谈一谈缓存系统常见的问题。
搜索公众号互联网架构师,后台回复“2T”,获取一份惊喜礼包。
如下图所示,列出七个常见问题。
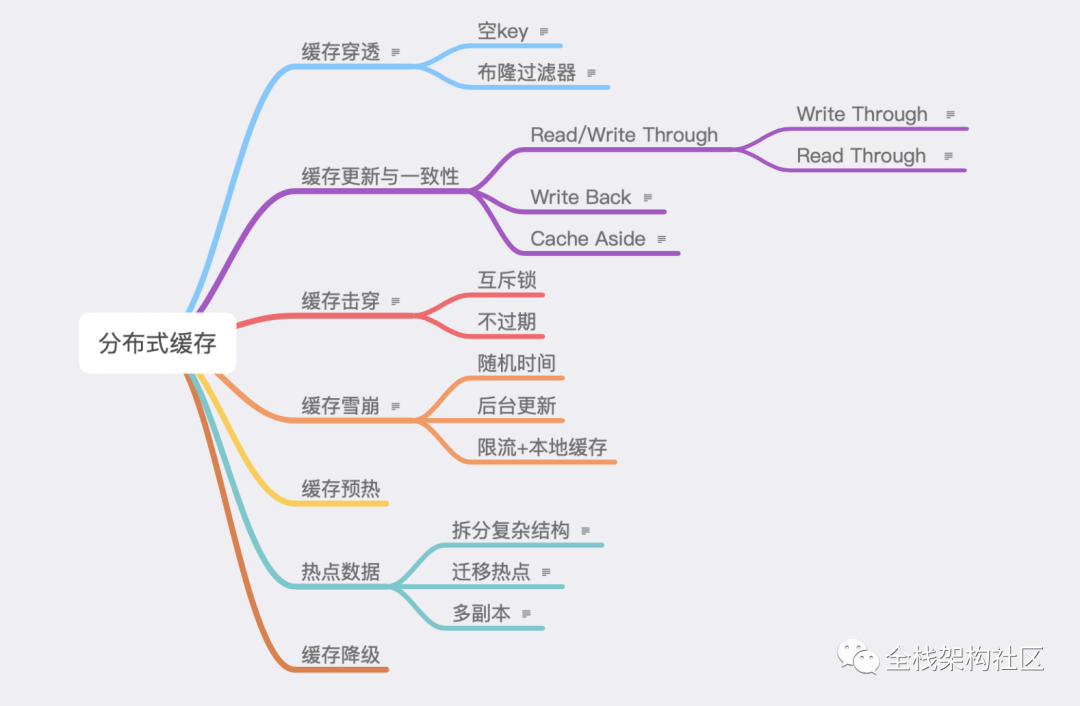
3.1. 缓存穿透
空 key:指对于不存在的数据也将 key 存空值入缓存系统,这样下次访问也会得到返回。但只适用于空数据key有限、key 重复请求概率高,如果量大且不重复,就会造成很多无用 key 的创建。 布隆过滤器:布隆过滤器是一个很长的二进制向量和一系列随机映射函数。可用于检索一个元素是否在一个集合中加一层对空值的过滤器,空间和时间效率都很高。但由于 hash 产生的碰撞可能存在误判,以及因不存储 key 导致的无法删除。适用于空数据key各不同、重复请求概率低。
3.2. 缓存击穿
缓存击穿实际是缓存雪崩的一个特例。指当某些热点key过期时,就会有大量的请求击穿到DB。
3.3. 缓存雪崩
同一时刻大量缓存失效(故障), 请求到了DB。
随机时间:在设置过期时间时,可以在基础时间上 + 一个随机的时间,等于实现了分批过期。
后台更新:将更新失效的工作交给后台定时线程。
限流+本地缓存:如 ehcache本地缓存 + Hystrix限流。
双缓存:类似于设置
主从缓存,从key不过期。
3.4. 缓存更新与一致性
如果保证数据一致性。列出四种更新策略:
Cache Aside:最常用的。失效时回源取数据,更新;命中时,返回缓存数据;更新时先数据源更新,再跟你更新缓存。
Write Back:更新数据时,只更新缓存,不更新数据源。缓存异步批量更新数据库
Read/Write Through
Write Through :当有数据更新时,如未命中缓存,直接更新数据库,并返回。如命中缓存,则更新缓存,再由 Cache 自己更新数据库。
Read Through :更新数据源由缓存系统操作,读取数据时如缓存失效,则取回源数据更新缓存。
3.5. 热点数据
对于热点数据的处理方法。
拆分复杂结构:如二级数据结构,进行拆分,这样热点key就被拆为若干个的 key 分布到不同节点。
迁移热点:对于Redis Cluster 而言可以将热点 key 所在的 slot 单独迁移到一个节点,降低其他节点压力。
多副本:复制多份缓存副本,将请求分散到多个节点上,减轻单台缓存服务器压力,适合多读少写。
3.6. 缓存预热
指可以将某些的缓存数据提前加载到缓存系统。提前避免在如热点数据大量请求到库。
3.7. 缓存降级
指当访问量剧增、服务出现问题或非核心服务影响到核心流程的性能时,仍需保证主服务可用。可根据一些关键数据自动降级,也可配置开关人工降级。
4. Redis Cluster使用
对于Redis Cluster环境的搭建和基础使用非常简单。
无论基于何种方式,只要搭建好n台 redis 服务并保证各服务间可以互相通讯后,任意进入一个redis 服务键入:
redis-cli --cluster create IP1:port1 IP2:port2 IP3:port3 IP4:port4 IP5:port5 IP6:port6 ... --cluster-replicas 1
即可。之后可以使用 cluster node 和cluster info查看集群、节点信息。
而对于广大 JAVA 服务器端开发,Spring Data Redis 从1.7起即支持Redis Cluster,只需配置Master节点地址(和密码)。
spring.redis.cluster.nodes=ip1:port1,ip2:port2,ip3:port3
加入依赖
compile("org.springframework.boot:spring-boot-starter-data-redis")
即可通过 RedisTemplate 使用。
5. 总结
本文从缓存系统的选择出发,基于 Redis 介绍了几种集群方案并重点说明了 Redis Cluster 方案。之后列出缓存系统常见问题及常见解决方案,最后对使用做了简单说明。
当然,如何去落地,如何解决这些问题还需要根据实际场景具体分析和处理。
参考资源
Redis Cluster Specification
深入理解分布式系统中的缓存架构
缓存更新的套路
[一种高效的Redis Cluster的分布式缓存系统[J].计算机系统应用,2018,27(10):91-98.]
全栈架构社区交流群
「全栈架构社区」建立了读者架构师交流群,大家可以添加小编微信进行加群。欢迎有想法、乐于分享的朋友们一起交流学习。
看完本文有收获?请转发分享给更多人
往期资源: