
【Redis】Redis中的小特性大作用
Pipeline
Pipeline介绍
客户端发送一条命令,Redis服务端执行这条命令的整个过程如下:
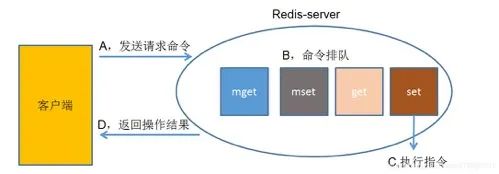
如上图所示,Redis客户端执行一条命令分为以下几个部分:
1. 发送命令
2. 命令排队
3. 执行命令
4. 返回结果
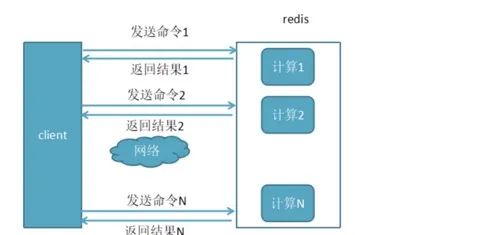
那么客户端执行一条命令的时间 = RTT(对应1和4)+ 排队时间 + 命令执行时间;对于Redis这种内存操作的系统来说,命令的执行时间和排队时间可能就是那么几十微秒,而RTT时间和客户端与服务端的距离有关,如果客户端和服务器处于不同城市,RTT时间可能高达10毫秒级别,可以看出,如果能够将多个命令打包成一条请求执行,相当于原来需要多次RTT时间,现在只需要一次RTT时间,大大提升了性能。
• 未使用pipeline执行N条命令 执行N条命令花费时间:N*RTT + N *(命令执行时 + 排队时间)
• 使用了pipeline执行N条命令 执行N条命令花费时间:1*RTT + N *(命令执行时 + 排队时间)
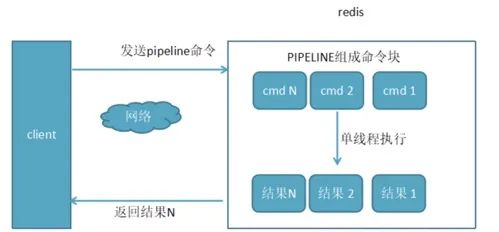
为了直观上感觉pipeline效率的提高,我们可以测试一把,但是需要注意的是pipeline功能在命令行中没有,但是各个语言版的client中都有相应的实现,这里我们使用java来使用pipeline功能。
import redis.clients.jedis.Jedis;
import redis.clients.jedis.Pipeline;
public class PipelineDemo {
public static void main(String[] args) {
Jedis redis = new Jedis("127.0.0.1", 6379);
redis.select(0);//使用第0个库
redis.flushDB();//清空第0个库所有数据
long start = System.currentTimeMillis();
for (int i = 0; i < 100000; i++) {
redis.set("key_" + i, i+ ""); //循环执行10000条数据插入redis
}
long end = System.currentTimeMillis();
System.out.println("正常插入" + redis.dbSize() + "数据, 花费时间:" + (end - start) + " ms");
redis.flushDB();//清空第0个库所有数据
long startPipe = System.currentTimeMillis();
Pipeline pipe = redis.pipelined();
for (int i = 0; i < 100000; i++) {
pipe.set
("key_" + i, i+ ""); //将命令封装到PIPE对象,此时并未执行,还停留在客户端
}
pipe.sync();
//将封装后的PIPE一次性发给redis
long endPipe = System.currentTimeMillis();
System.out.println("使用Pipleline插入" + redis.dbSize() + "数据, 花费时间:" + (endPipe- startPipe) + " ms");
}
}
***************执行结果***************
正常插入100000数据, 花费时间:4154 ms
使用Pipleline插入100000数据, 花费时间:420 ms
可以看出,同样是设置10000个键,普通的set命令执行10000次需要4154 ms, 而使用Pipleline只需要420ms,差不多提升了10倍的性能。
使用场景
Pipeline虽然好用,但也不是什么场景下都适合使用Pipeline技术。
有些系统可能对可靠性要求很高,每次操作都需要立马知道这次操作是否成功,是否数据已经写进redis了,那这种场景就不适合。
而有的系统,可能是批量的将数据写入redis,允许一定比例的写入失败,那么这种场景就可以使用了,比如10000条一下进入redis,可能失败了2条无所谓,后期有补偿机制就行了
Pipeline虽然好用,但是每次Pipeline组装的命令个数不能没有节制,否则一次组装Pipeline数据量过大,一方面会增加客户端的等待时间,另一方面会造成一定的网络阻塞,可以将一次包含大量命令的Pipeline拆分成多次较小的Pipeline来完成
Bitmap
Bitmap介绍
Bitmap并不是一种新的数据结构,其本质上就是字符串对应的ASCII编码组成的bit数组,比如"bi"对应的ASCII码分别是98、105,其在底层存储为:
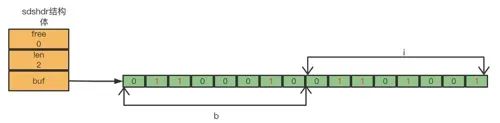
因此Bitmap 看成是一个 bit 为单位的数组,数组的每个单元只能存储 0 或者 1,数组的下标在 Bitmap 中叫做 offset 偏移量。Redis中的Bitmap提供了位操作,极大地
节省存储空间
。
Bitmap操作
Redis主要提供了4个Bitmap 的操作命令,如下:
//设置key的第offset位(从0开始计数)值
SETBIT <key> <offset> <value>
//获取 key 的 value 在 offset 处的 bit 位的值,当 key 不存在时,返回 0。
GETBIT <key> <offset>
//获取Bitmap指定范围值为1的个数
BITCOUNT [start] [end]
//OP取值:and(交集)or(并集)not(非)xor(异或)
BITOP OP destkey key[key ....]
使用场景
这里列出一个Bitmap常用的使用场景,根据前面介绍的命令进行实操如下:
判断用户登录状态;
某个网站有50个用户,想要统计某天访问的用户数(UV,同一用户一天访问多次算作一次),假设2022-09-06这天,id为0, 3, 5的用户登录过网站,具体操作如下:
也可以很方便获取某个用户有没有在这一天登录过网站:
统计连续登录的用户
接着上面的示例,2022-09-07这天有3, 5, 8三个用户登录,2022-09-08这天有3, 5, 9三个用户的登录,现在来统计6号到8号连续3天都登录的用户有多少:
可以看出有2个用户连续三天都登录了。
还有其它很多场景都可以用到Bitmap,比如ip 是否是黑名单、以及签到打卡统计等场景。
HyperLogLog
HyperLogLog介绍
要介绍HyperLogLog,首先需要了解一个概念:什么是基数?涉及到数学的概念一般都挺难理解的,这里还是举个例子:有一个数据集 {1, 2, 5, 7, 2, 7, 8}, 那么这个数据集的基数集为 {1, 2, 5 ,7, 8}, 基数(不重复元素的个数)为5。通过例子显而易见,所谓基数,就是在一批数据集中,不重复元素的个数。
HyperLogLog 就是一种基数估算算法,既然是估算算法,那么肯定是允许有一定范围的误差。
需要注意的是HyperLogLog并不是一种数据结构,而是一种算法,本文我们只介绍其使用场景和使用方法,具体实现我们不去细挖。
Redis Hyperloglog 操作
Redis提供了3个Hyperloglog 的操作命令
//添加操作
pfadd key elment1 elment2....
//统计操作
pfcount key1 key2...
//统计操作
pfmerge destkey key1 key2...
还是用统计UV的案例来演示这几个命令。
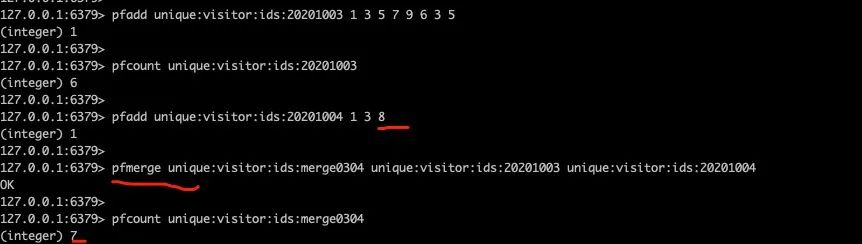
某个网站在2020年10月3号id为1、3、5、6、7、9的用户访问了,其中id为3和5的用户访问了2次(计算Uv只能算一次),使用Hyperloglog 命令如下:
 2020年10月4号id为1、3、8的用户访问了该网站,现在需要计算3号和4号访问网站的用户(同一用户不同天访问也算一次访问):
2020年10月4号id为1、3、8的用户访问了该网站,现在需要计算3号和4号访问网站的用户(同一用户不同天访问也算一次访问):
使用场景
举个栗子:假如我要统计网页的UV(浏览用户数量,一天内同一个用户多次访问只能算一次),传统的解决方案是使用set来保存用户id,然后统计set中的元素数量来获取页面UV。但这种方案的缺点是一旦用户数量大起来就需要消耗大量的空间来存储用户id。我们的目的是统计用户数量而不是保存用户,很显然这是个吃力不讨好的方案!
而使用Redis的HyperLogLog最多需要12k内存就可以满足我们的需求,尽管其有大概0.81%的错误率,但是对于统计UV这种不需要很精确数据的业务场景来说是可以容忍的。
GEO
GEO介绍
Redis 3.2 版本新增了geo相关命令,用于存储和操作地理位置信息。提供的命令包括添加、计算位置之间距离、根据中心点坐标和距离范围来查询地理位置集合等,
Redis GEO 操作
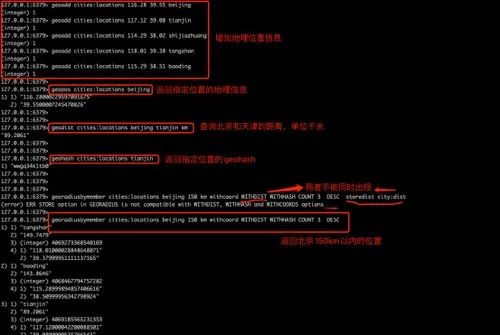
//添加member地理位置操作
geoadd key longitude latitude member
//获取两个地理位置的距离,[unit]表示单位:
// m: 米 km: 千米 mi:英里 ft:尺
geodist key member1 member2 ... [unit]
//可以获取地理位置的坐标,
geopos key member1 member2 ...
//获取元素的经纬度编码字符串
geohash key member1 member2 ...
//根据坐标点查找附近位置的元素
//withcoord:返回结果中包含经纬度 withdist:返回结果中包含离指定点位置距离
//withhash:返回结果中包含geohash COUNT count:指定返回结果的数量
//asc|desc:按照离指定位置距排序方式
//storedist key:将返回结离指定位置距离保存到指定键key,该选项不能和withdist选项同时出现
georadis key longitude latitude unit [withcoord] [withdist] [withhash] [COUNT count] [asc|desc] [storedist key]
georadiusbymember key member unit [withcoord] [withdist] [withhash] [COUNT count] [asc|desc] [storedist key]
下面是我国五个城市的经纬度表:
针对这几个地方,练习Redis的GEO 操作
使用场景
我想大家应该都使用软件搜索过附近的人、附近的店等等,这种都离不开基于位置服务(Location-Based Service,LBS)的应用。此类应用都是基于经纬度来查询附近的目标,Redis GEO就适用于此类场景。
本文示例环境:
Redis版本:4.0.10
操作系统:macOs 12.1
JDK版本:12.0.1
maven版本: 3.8.4
— 完 —
欢迎关注原创技术号↓
↓↓
原创不易,如有帮助,辛苦点赞和在看