
为什么 ElasticSearch 比 MySQL 更适合复杂条件搜索
熟悉 MySQL 的同学一定都知道,MySQL 对于复杂条件查询的支持并不好。MySQL 最多使用一个条件涉及的索引来过滤,然后剩余的条件只能在遍历行过程中进行内存过滤,对这个过程不了解的同学可以先行阅读一下《MySQL复杂where条件分析》。
上述这种处理复杂条件查询的方式因为只能通过一个索引进行过滤,所以需要进行大量的 I/O 操作来读取行数据,并消耗 CPU 进行内存过滤,导致查询性能的下降。
而 ElasticSearch 因其特性,十分适合进行复杂条件查询,是业界主流的复杂条件查询场景解决方案,广泛应用于订单和日志查询等场景。
下面我们就一起来看一下,为什么 ElasticSearch 适合进行复杂条件查询。
ElasticSearch 简介
Elasticsearch 是开源的实时分布式搜索分析引擎,内部使用 Lucene 做索引与搜索。它提供"准实时搜索"能力,并且能动态集群规模,弹性扩容。

Elasticsearch 使用 Lucene 作为其全文搜索引擎,用于处理纯文本的数据,但 Lucene 只是一个库,提供建立索引、执行搜索等接口,但不包含分布式服务,这些正是 Elasticsearch 做的。
下面,我们来介绍一下 ElasticSearch 的相关概念。为了便于初学者理解,我们先将 ElasticSearch 中的概念和 MySQL 中的概念大致地进行对应。但是二者在具体细节上还是有很多差异的,大家深入了解 ElasticSearch 就会将二者区分清楚,不能强行对比等同。
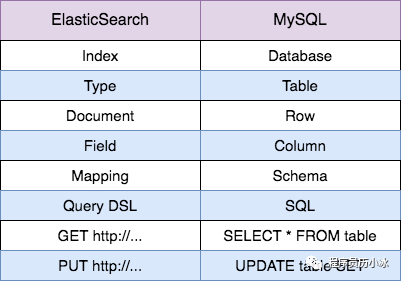
ElasticSearch 中的索引 Index 类似于 MySQL 中的数据库 Database;
ElasticSearch 中的类型 Type 类似于 MySQL 中的表 Table;需要注意,这个概念在 7.x 版本中被完全删除,而且概念上和 Table 也有较大差异;
ElasticSearch 中的文档 Document 类似于 MySQL 中的数据行 Row,每个文档由多个字段 Filed 组成,这个Filed 就类似于 MySQL 的 Column;
ElasticSearch 中的映射 Mapping 是对索引库中的索引字段及其数据类型进行定义,类似于关系型数据库中的表结构 Schema;
ElasticSearch 使用自己的领域语言 Query DSL 来进行增删改查,而 MySQL 使用 SQL 语言进行上诉操作。
ElasticSearch 还有一系列有关其分布式特性的概念,我们这里就暂不介绍了,等后续学习到其分布式特性时在进行介绍。
倒排索引
MySQL 有 B+ 树索引,而 ElasticSearch 则是倒排索引 (Inverted Index),它通过倒排索引来实现比 MySQL 更快的过滤和复杂条件的查询,此外,全文搜索功能也是依赖倒排索引才能实现。下面,我们就具体来看一下何为倒排索引。
倒排索引按照维基百科的描述,是存储文档内容到文档位置映射关系的数据库索引结构。不过只看定义,我是有点迷惑,这不是和 MySQL 的非主键索引类似嘛,为什么要叫它“倒排”呢?这个问题我目前也为搞清楚,可能要等到后续了解了其具体实现才能理解。
我们还是以书籍检索为例,假设有以下数据,每一行就是一个 Document,每个 Document 由 id,ISBN 号,作者名称和评分组成。
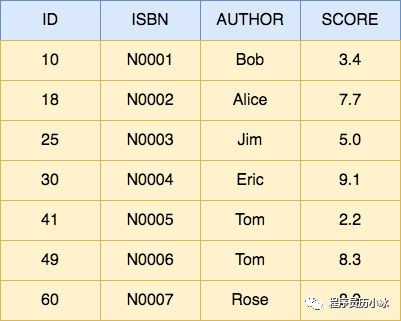
给上述数据按照 ISBN 和 Author 建立的倒排索引如下所示。倒排索引是每个字段分开建立的,相互独立。有两个专门的术语,分别是索引 Term 和倒排表 Posting List。字段的值就是 Term,比如 N0007,而 Term 对应的文档 ID 的列表就是 Posting List,对应图中红色的部分。

一般 Term 都是按照顺序排序的,比如 Author 名称就是按照字母序进行了排序,排序之后,当我们搜索某一个 Term 时,就不需要从头遍历,而是采用二分查找。一系列排序后的 Term 就组成了索引表 Term Dictionary。
但是 Term Dictionary 往往很大,无法完整放入内存,这是为了更快的查询,还需要再给它创建索引,也就是 Term Index 。
ElasticSearch 使用 Burst-Trie 结构来实现 Term Index,它是一种前缀树 Trie 的一种变种,它主要是将后缀进行了压缩,降低了Trie的高度,从而获取更好查询性能。
Term Index 并不需要像 MySQL 的索引一样,包含所有的 Term,而是包含的是这些 Term 的前缀。它就类似于字典的查询目录,可以进行快速定位到 Term Dictionary 的某一位置,然后再从这个位置向后查询。
综上, Alice,Alf,Arlan,Bob,Tom 等词的倒排索引如下所示。绿色部分是 Term Index,蓝色部分是 Term Dictionary,红色部分是 Posting List。
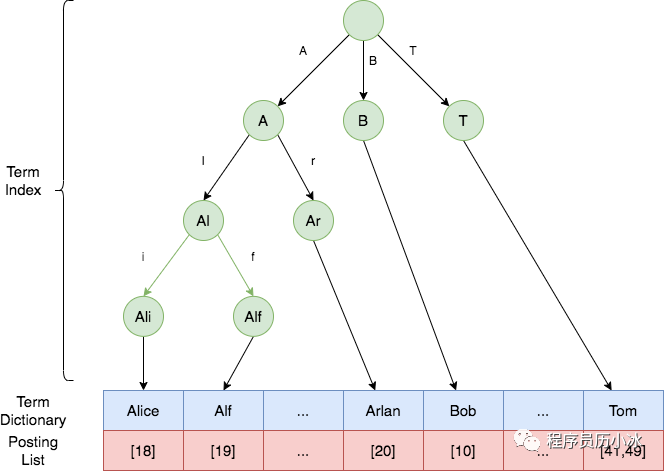
一般来说,Term Index 都是全部缓存在内存中,查询时,先通过其快速定位到 Term Dictionary 对应的大致范围,然后再进行磁盘读取查找对应的 Term,这样就大大减少了磁盘 I/O 的次数。
联合索引查询
了解了 ElasticSearch 的倒排索引后,我们再来看看其如何处理复杂的联合索引查询。比如上述书籍例子中,我们需要查询评分等于2.2并且作者名称叫 Tom的书籍。
理论上,我们只需要分别按照 Score 和 Author 字段的倒排索引进行查询,获取响应的 Posting List,再将其做交集合并即可。
这里又要吐槽一下 MySQL,它是不支持这个合并操作的,它只能按照一个字段的索引进行查询,然后根据另外一个字段的条件做内存过滤。顺便说一下,MySQL 的 join 功能也弱爆了,感兴趣的同学可以了解一下这篇文章
而 ElasticSearch 则支持使用跳表 Skip List和 Bitset 的方式将数据集进行合并。
使用 Skip List 结构,同时遍历 Score 和 Author 查询出来的 Posting List,利用其 Skip List 结构,相互跳跃对比,得出合集。
使用 Bitset 结构,对 Score 和 Author 查询出来的 Posting List 的值计算出各自的 Bitset,然后进行 AND 操作。
跳表合并策略
ElasticSearch 在存储 Posting List 数据时,就保存了对应的多级跳表结构响应的数据,这也体现了其空间换时间的基本思想。
这里先介绍一下跳表的基本概念,它其实是一种可以进行二分查找的有序链表。跳表在原有的有序链表上面增加了多级索引,通过索引来实现快速查找。首先在最高级索引上查找最后一个小于当前查找元素的位置,然后再跳到次高级索引继续查找,直到跳到最底层为止,通过这种方式,加快了查询的速度。
比如,按照 Score 查出来的 Posting List 为[2,3,4,5,7,9,10,11],按照 Author 查出来的结果为 [3,8,9,12,13],则二者的跳表结构如下图所示。
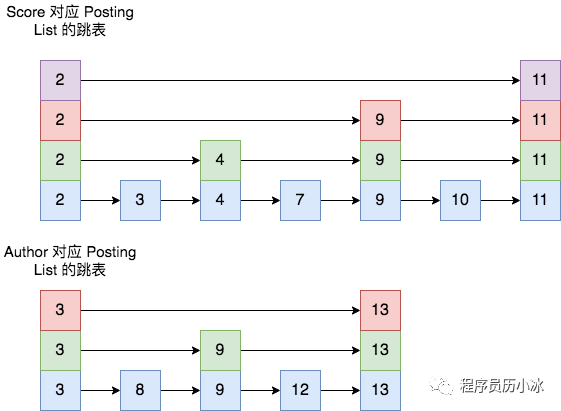
具体合并过程则是先选最短的 posting list,也就是 Author 的结果集,从其最小的一个 id 开始,将其作为当前最大值。然后依次剩余 posting list 中查找大于或等于该值的位置。
比如上述结果集中,先去 Score 结果集中查找 3,找到后,就表明 3是二者的合集元素之一;然后再重新开启一轮,选取 Author 结果集中 3 的下一个值 8 ,去 Score 结果集查询 8,发现了大于等于 8 的最小的值是 9 ,所以不可能有共同的值 8,然后再去 Author 结果集查找 9 ,发现其大于等于 9 的最小值是 12,所以再去 Score 结果集中查找大于等于 12的值,发现并不存在;最终得出二者的合集就只有[3]。
在查询过程中,每个 posting list 都可以根据当前 id 通过 skip list 快速跳过不符合的 id 值,加速整个合并取交集的过程。
ElasticSearch 对于较长的 posting list 也会使用 Frame Of Reference 进行压缩编码,减少了磁盘占用,减少了索引尺寸。有关具体存储结构的实现我们后续再进行细聊。
Bitset 合并策略
ElasticSearch除了使用 skipList 来进行数据磁盘读取时的合并操作外,还会将一些查询条件对应的结果集 posting list 进行内存缓存,也就是所谓的 Filter Cache,为了后续再次复用。
为了减少内存缓存所消耗的内存空间大小,ElasticSearch 没有使用单纯的数组和 bitset 来存储 posting list,而是使用要压缩效率更高的 Roaring Bitmap。
我们可以先来讲一下单纯数组或 bitset 数据结构为什么并不使用。比如如下一道较为常见的面试题目:
给定含有40亿个不重复的位于[0, 2^32 - 1]区间内的整数的集合,如何快速判定某个数是否在该集合内?
如果我们要使用 unsigned long 数组来存储它的话,也就需要消耗 40亿 * 32 位 = 160 Byte,大致是 16000 MB。
如果要使用位图 Bitset 来存储的话,即某个数位于原集合内,就将它对应的位图内的比特置为1,否则保持为0。这样只需要消耗 2 ^ 32 位 = 512 MB,这可只有原来的 3.2 % 左右。
但是,Bitset 也有其缺陷,也就是稀疏存储的问题,比如上述集合并不是 40亿,而是只有2,3个,那么 Bitset 中只有少数几位是1,其他位都是 0,但是它仍然占用了 512 MB。
而 RoaringBitmap 就是为了解决稀疏存储的问题。下图就是 RoaringBitmap 的基本原理示意图。
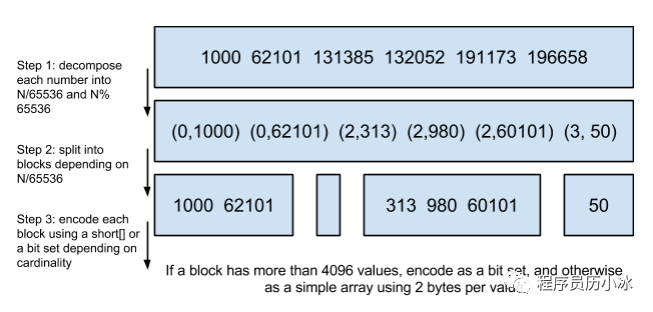
首先,如上图所示,计算出32位无符号整数和 65536 的除数和余数。其含义表示,将32位无符号整数按照高16位分桶,即最多可能有2^16=65536个桶,术语惩治为 container。存储数据时,按照数据的高16位找到 container(找不到就会新建一个),再将低16位放入container中。也就是说,一个 RoaringBitmap 就是很多container的集合。
然后 container 内具体的存储结构要根据存入其内数据的基数来决定。
基数小于 2 ^ 12 次方即 4096时,使用unsigned short类型的有序数组来存储,最大消耗空间就是 8 KB。
基数大于 4096 时,则使用大小为 2 ^ 16 次方的普通 bitset 来存储,固定消耗 8 KB。当然,有些时候也会对 bitset 进行行程长度编码(RLE)压缩,进一步减少空间占用。
ElasticSearch 就是使用 Roaring Bitmap 来缓存不同条件查询出来的 posting list,然后再进行与操作计算出最终结果集。
后记
至此,我们也算了解了 ElasticSearch 为什么比 MySQL 更适合复杂条件查询,但是有好就有弊,因为为了查询做了这么多的准备工作,ElasticSearch 的插入速度就会慢于 MySQL,而且数据存入ES后并不是立马就能检索到。
参考文章
http://www.nosqlnotes.com/technotes/searchengine/lucene-invertedindex/
https://zhuanlan.zhihu.com/p/33671444
https://www.cnblogs.com/forfuture1978/archive/2010/04/04/1704258.html
https://www.jianshu.com/p/818ac4e90daf
推荐阅读:
API 面试四连杀:接口如何设计?安全如何保证?签名如何实现?防重如何实现?
Spring Boot 中引入 MyBatisPlus 的常规流程