
三个烂怂八股文,变成两个场景题,打得我一脸懵逼.
你好呀,我是歪歪。
这篇文章来盘一下我最近遇到的两个有意思的代码案例,有意思的点在于,拿到代码后,你一眼望去,没有任何毛病。然后一顿分析,会发现破绽藏的还比较的深。
几个基础招式的一套组合拳下来,直接把我打懵逼了。
你也来看看,是不是你跺你也麻。

第一个场景
首先第一个是这样的:
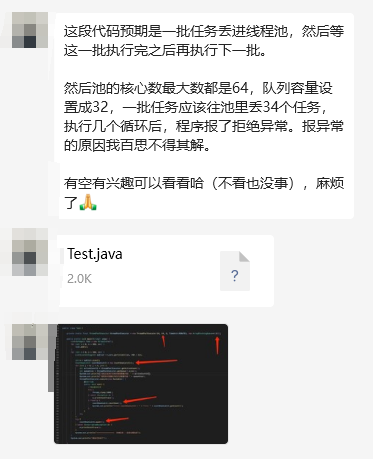
一个读者给我发来的一个关于线程池使用的疑问,同时附上了一个可以复现问题的 Demo。
我打开 Demo 一看,一共就这几行代码,结合问题描述来看想着应该不是啥复杂的问题:
我拿过来 Demo,根本就没看代码,直接扔到 IDEA 里面跑了两次,想着是先看看具体报错是什么,然后再去分析代码。
但是两次程序都正常结束了。
好吧,既然没有异常,我也大概的瞅了一眼 Demo,重点关注在了 CountDownLatch 的用法上。
我是横看竖看也没看出问题,因为我一直都是这样用的,这就是正确的用法啊。
于是从拿到 Demo 到定位问题,不到两分钟,我直接得出了一个大胆的结论,那就是:常规用法,没有问题:
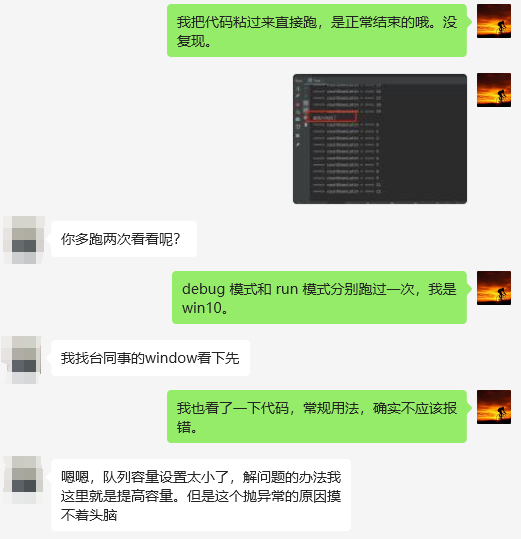
然后我们就结束了这次对话。
过了一会,我准备关闭 IDEA 了。鬼使神差的,我又点了一次运行。
你猜怎么着?
居然真的报错了,抛出了 rejectedExecution 异常,意思是线程池满了。
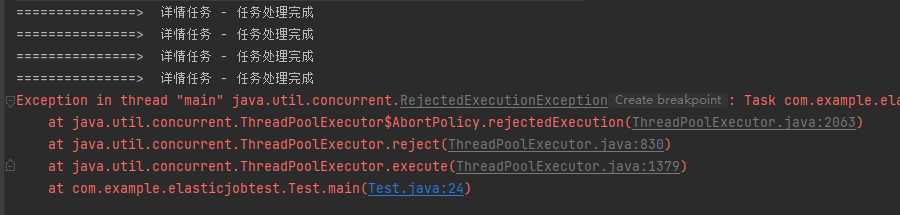
哦哟,这就有点意思了。

带大家一起盘一盘。
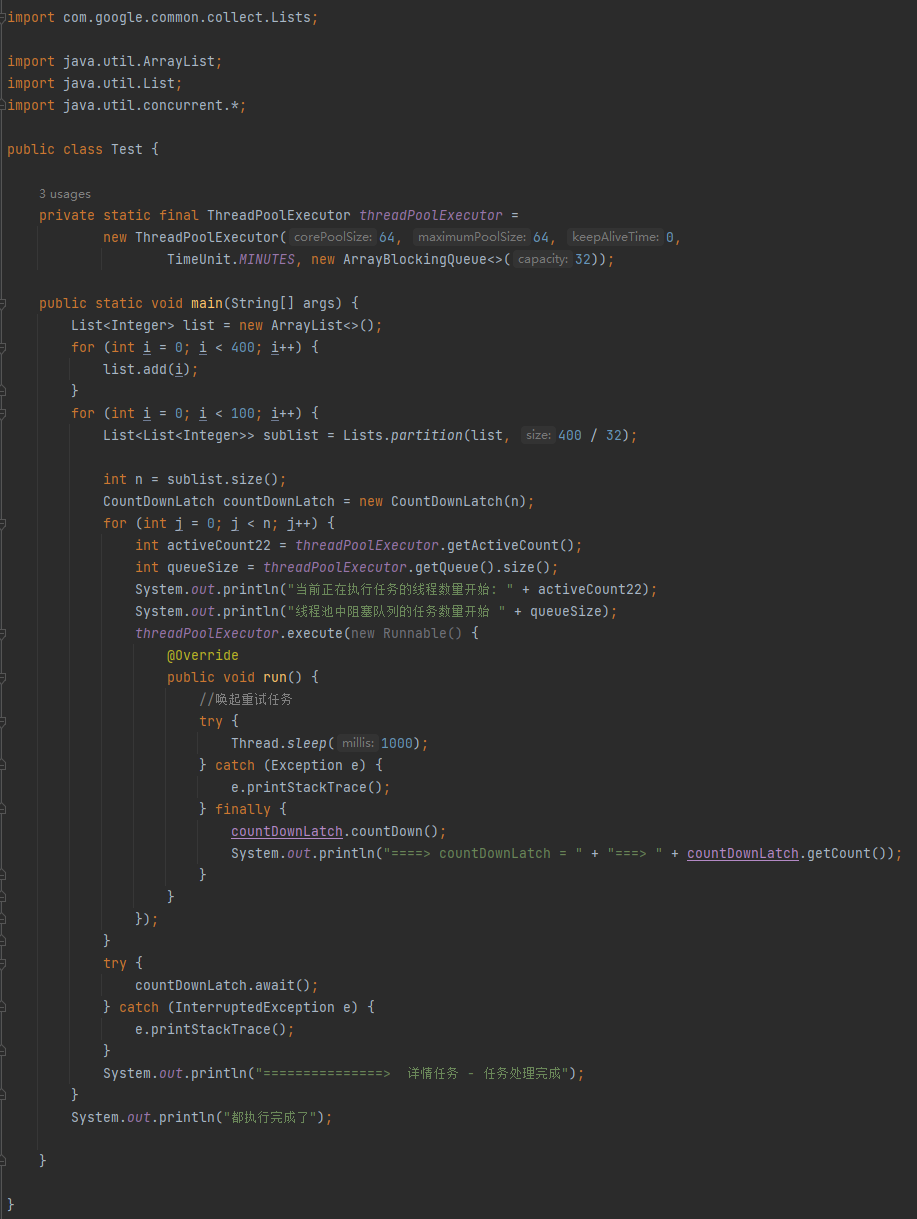
首先我们还是过一下代码,为了减少干扰项,便于理解,我把他给我的 Demo 稍微简化了一点,但是整体逻辑没有发生任何变化。
简化后的完整代码是这样的,你直接粘过去,引入一个 guava 的包就能跑:
import com.google.common.collect.Lists;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.*;
public class Test {
private static final ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(64, 64, 0, TimeUnit.MINUTES, new ArrayBlockingQueue<>(32));
public static void main(String[] args) {
List<Integer> list = new ArrayList<>();
for (int i = 0; i < 400; i++) {
list.add(i);
}
for (int i = 0; i < 100; i++) {
List<List<Integer>> sublist = Lists.partition(list, 400 / 32);
int n = sublist.size();
CountDownLatch countDownLatch = new CountDownLatch(n);
for (int j = 0; j < n; j++) {
threadPoolExecutor.execute(() -> {
try {
Thread.sleep(1000);
} catch (Exception e) {
e.printStackTrace();
} finally {
countDownLatch.countDown();
}
});
}
try {
countDownLatch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("===============> 详情任务 - 任务处理完成");
}
System.out.println("都执行完成了");
}
}
/**
* <dependency>
* <groupId>com.google.guava</groupId>
* <artifactId>guava</artifactId>
* <version>31.1-jre</version>
* </dependency>
*/
一起分析一波代码啊。
首先定义了一个线程池:
private static final ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(64, 64, 0, TimeUnit.MINUTES, new ArrayBlockingQueue<>(32));
该线程池核心大小数和最大线程数都是 64,队列长度为 32,也就是说这个线程池同时能容纳的任务数是 64+32=96。
main 方法里面是这样的:
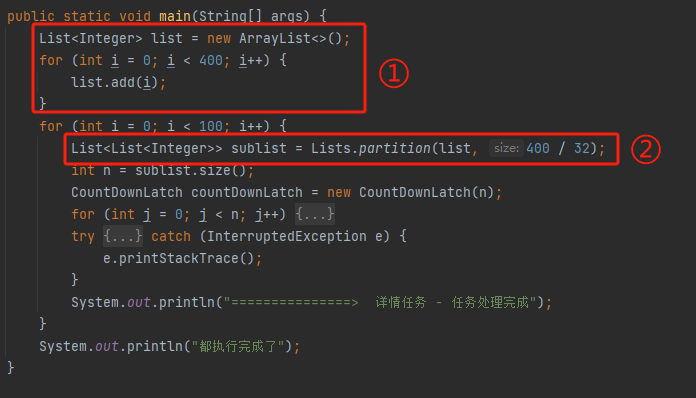
在实际代码中,肯定是有具体的业务含义的,这里为了脱敏,就用 List 来表示一下,这个点你知道就行。
编号为 ① 的地方,是在给往 list 里面放 400 个数据,你可以认为是 400 个任务。
编号为 ② 的地方,这个 List 是 guava 的 List,含义是把 400 个任务拆分开,每一组有 400/32=12.5 个任务,向下取整,就是 12 个。
具体是什么个意思呢,我给你看一下 debug 的截图你就知道了:
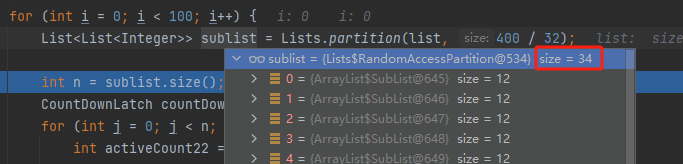
400 个任务分组,每一组 12 个任务,那就可以拆出来 34 组,最后一组只有 4 个任务:
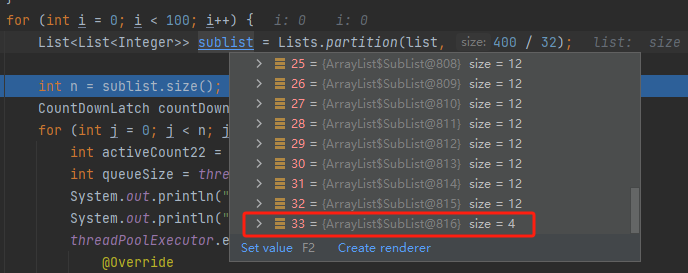
但是这都不重要,一点都不重要好吧。
因为后续他根本就没有用这个 list ,只是用到了 size 的大小,即 34 。
所以你甚至还能拿到一个更加简洁的代码:
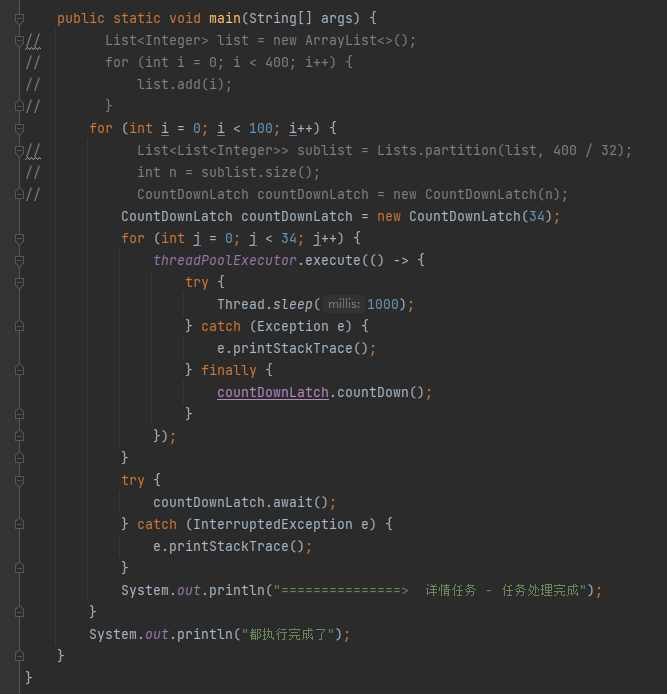
为什么我最开始的时候不直接给你这个最简化的代码,甚至还让你多引入一个包呢?
因为歪师傅就是想体现这个简化代码的过程。
按照我写文章的经验,在定位问题的时候,一定要尽量多的减少干扰项。排除干扰项的过程,也是梳理问题的过程,很多问题在排除干扰项的时候,就逐渐的能摸清楚大概是怎么回事儿。
如果你遇到一个让你摸不着头脑的问题,那就先从排除干扰项做起。
好了,说回我们的代码。现在我们的代码就只有这几行了,核心逻辑就是我圈起来的这个方法:
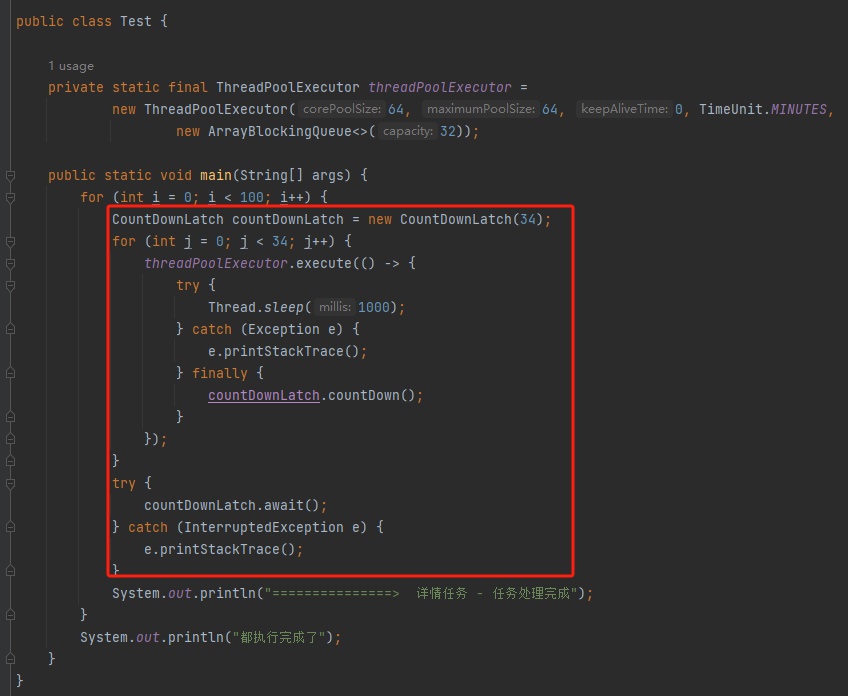
而圈起来这个部分,主要是线程池结合 CountDownLatch 的使用。
对于 CountDownLatch 我一般只关注两个地方。
第一个是 new 的时候传入的“令牌数”和调用 countDown 方法的次数能不能匹配上。只有保持一致,程序才能正常运行。
第二个地方就是 countDown 方法的调用是不是在 finally 方法里面。
这两个点,在 Demo 中都是正确的。
所以现在从程序分析不出来问题,我们怎么办?

那就从异常信息往回推算。
我们的异常信息是什么?
触发了线程池拒绝策略:
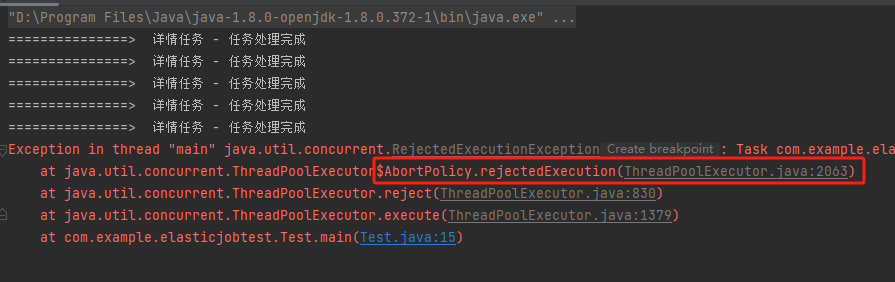
什么时候会出现线程池拒绝策略呢?
核心线程数用完了,队列满了,最大线程数也用完了的时候。
但是按理来说,由于有 countDownLatch.await() 的存在,在执行完 for 循环中的 34 次 countDownLatch.countDown() 方法之前,主线程一定是阻塞等待的。
而 countDownLatch.countDown() 方法在 finally 方法中调用,如果主线程继续运行,执行外层的 for 循环,放新的任务进来,那说明线程池里面的任务也一定执行完成了。
线程池里面的任务执行完成了,那么核心线程就一定会释放出来等着接受下一波循环的任务。
这样捋下来,感觉还是没毛病啊?

除非线程池里面的任务执行完成了,核心线程就一定会释放出来等着接受下一波循环的任务,但是不会立马释放出来。
什么意思呢?
就是当一个核心线程执行完成任务之后,到它进入下一次可以开始处理任务的状态之间,有时间差。
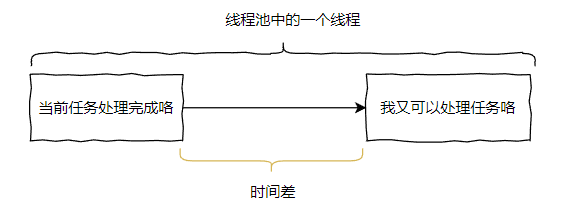
而由于这个时间差的存在,导致第一波的核心线程虽然全部执行完成了 countDownLatch.countDown(),让主线程继续运行下去。但是,在线程池中还有少量线程未再次进入“可以处理任务”的状态,还在进行一些收尾的工作。
从而导致,第二波任务进来的时候,需要开启新的核心线程数来执行。
放进来的任务速度,快于核心线程的“收尾工作”的时间,最终导致线程池满了,触发拒绝策略。
需要说明的是,这个原因都是基于我个人的猜想和推测。这个结论不一定真的正确,但是伟人曾经说过:大胆假设,小心求证。
所以,为了证明这个猜想,我需要找到实锤证据。
从哪里找实锤呢?
源码之下,无秘密。
当我有了这个猜想之后,我立马就想到了线程池的这个方法:
java.util.concurrent.ThreadPoolExecutor#runWorker
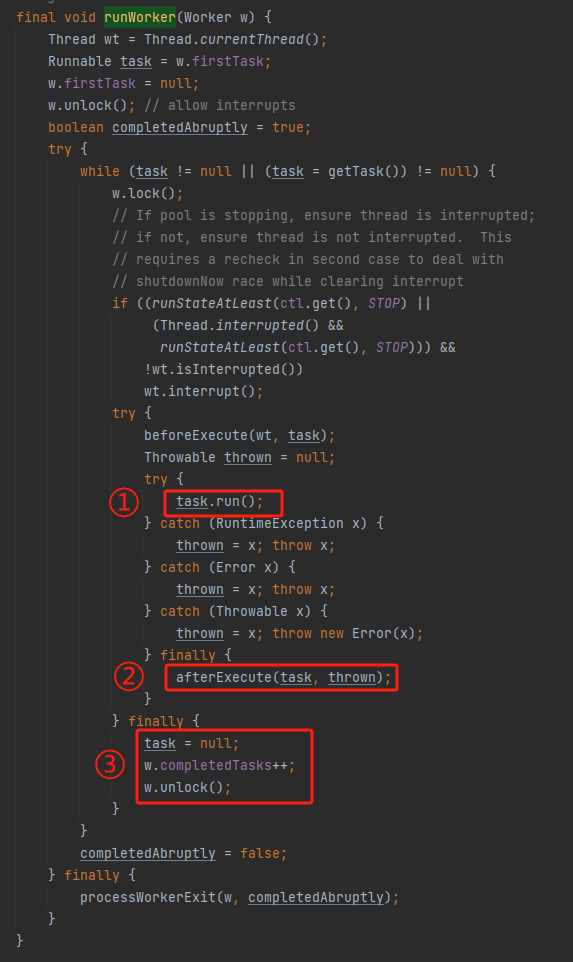
标号为 ① 的地方是执行线程 run 方法,也就是这一行代码执行完成之后,一个任务就算是执行完成了。对应到我们的 Demo 也就是这部分执行完成了:
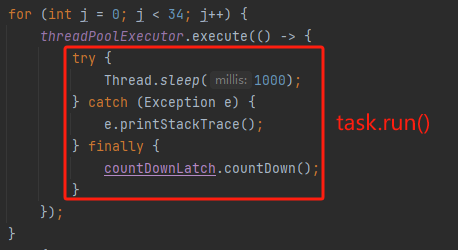
这部分执行完成了,countDownLatch.countDown() 方法也执行完成了。
但是这个核心线程还没跑完呢,它还要继续往下走,执行标号为 ② 和 ③ 处的收尾工作。
在核心线程执行“收尾工作”时,主线程又咔咔就跑起来了,下一波任务就扔进来了。
这不就是时间差吗?
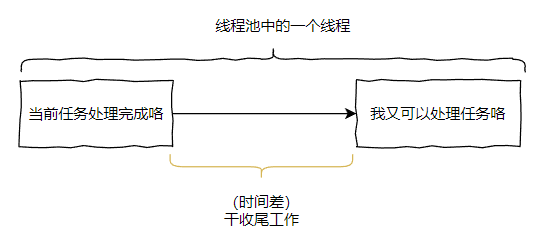
另外,我再问一个问题:线程池里面的一个线程是什么时候处于“来吧,哥们,我可以处理任务了”的状态的?
是不是要执行到红框框着的这个地方 WAITING 着:
java.util.concurrent.ThreadPoolExecutor#getTask
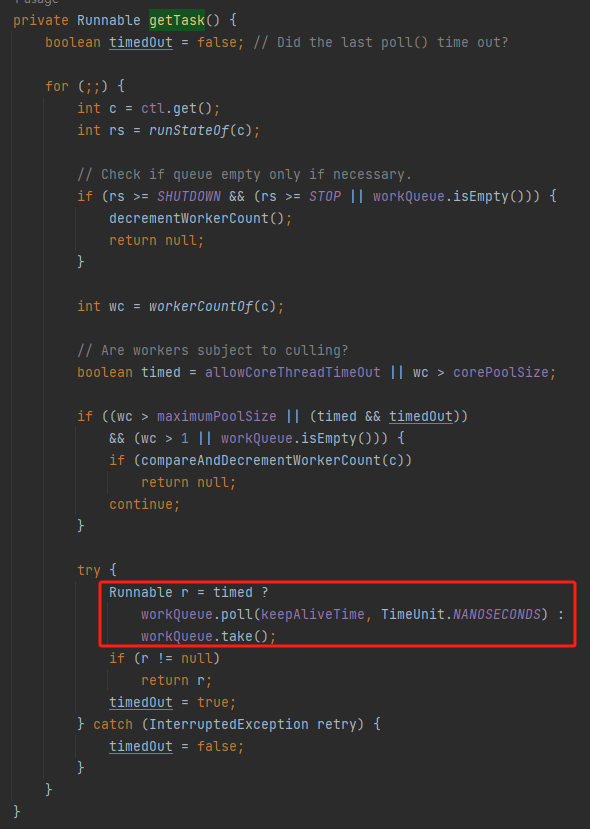
那在执行到这个红框框之前,还有一大坨代码呢,它们不是收尾工作,属于“就绪准备工作”。
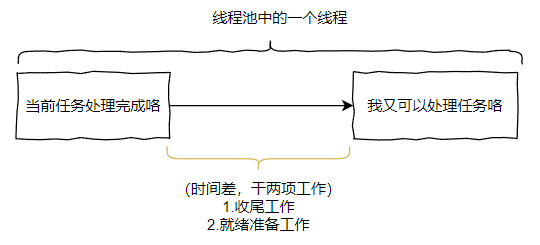
现在我们再捋一捋啊。
线程池里面的一个线程在执行完成任务之后,到下一次可以执行任务的状态之间,有一个“收尾工作”和“就绪准备工作”,这两个工作都是非常快就可以执行完成的。
但是这“两个工作”和“主线程继续往线程池里面扔任务的动作”之间,没有先后逻辑控制。
从程序上讲,这是两个独立的线程逻辑,谁先谁后,都有可能。
如果“两个工作”先完成,那么后面扔进来的任务一定是可以复用线程的,不会触发新开线程的逻辑,也就不会触发拒绝策略。
如果“主线程继续往线程池里面扔任务的动作”先完成,那么就会先开启新线程,从而有可能触发拒绝策略。
所以最终的执行结果可能是不报错,也可能是抛出异常。
同时也回答了这个问题:为什么提高线程池的队列长度,就不抛出异常了?

因为队列长度越长,核心线程数不够的时候,任务大不了在队列里面堆着。而且只会堆一小会儿,但是这一小会,给了核心线程足够的时间去完成“两个工作”,然后就能开始消耗队列里面的任务。
另外,提出问题的小伙伴说换成 tomcat 的线程池就不会被拒绝了:

也是同理,因为 tomcat 的线程池重写了拒绝策略,一个任务被拒绝之后会进行重试,尝试把任务仍回到队列中去,重试是有可能会成功的。
对应的源码是这个部分:
org.apache.tomcat.util.threads.ThreadPoolExecutor#execute(java.lang.Runnable, long, java.util.concurrent.TimeUnit)
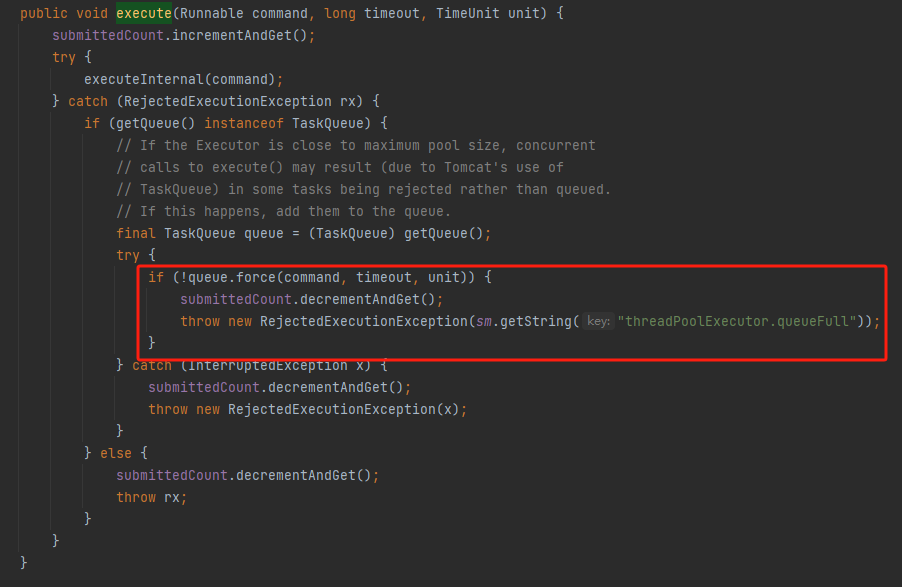
这就是我从源码中找到的实锤。
但是我觉得锤的还不够死,我得想办法让这个问题必现一下。
怎么弄呢?
如果要让问题必现,那么就是延长“核心线程完成两个工作”的时间,让主线程扔任务的动作”的动作先于它完成。
很简单,看这里,afterExecute 方法:
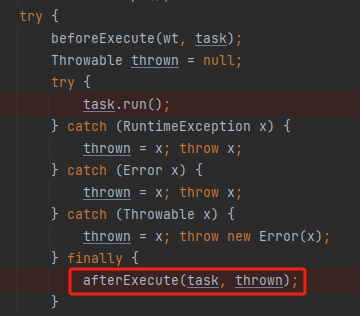
线程池给你留了一个统计数据的口子,我们就可以基于这个口子搞事情嘛,比如睡一下下:
private static final ThreadPoolExecutor threadPoolExecutor =
new ThreadPoolExecutor(64, 64, 0, TimeUnit.MINUTES,
new ArrayBlockingQueue<>(32)) {
@Override
protected void afterExecute(Runnable r, Throwable t) {
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
};
由于收尾任务的时间过长,这样“主线程扔任务的动作”有极大概率的是先执行的,导致触发拒绝策略:
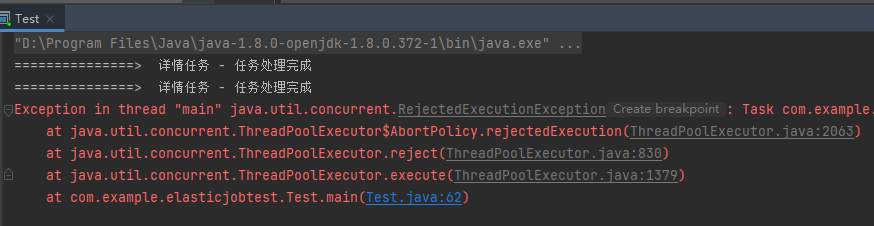
到这里,这个问题其实就算是分析完成了。
但是我还想分享一个我在验证过程中的一个验证思路,虽然这个思路最终并没有得到我想要的结论,但是技多不压身,你抽空学学,以后万一用得上呢。
前面说了,在我重写了 afterExecute 方法之后,一定会触发拒绝策略。
那么我在触发拒绝策略的时候,dump 一把线程,通过 dump 文件观察线程状态,是不是就可以看到线程池里面的线程,可能还在 RUNNING 状态,但是是在执行“两个工作”呢?
于是就有了这样的代码:
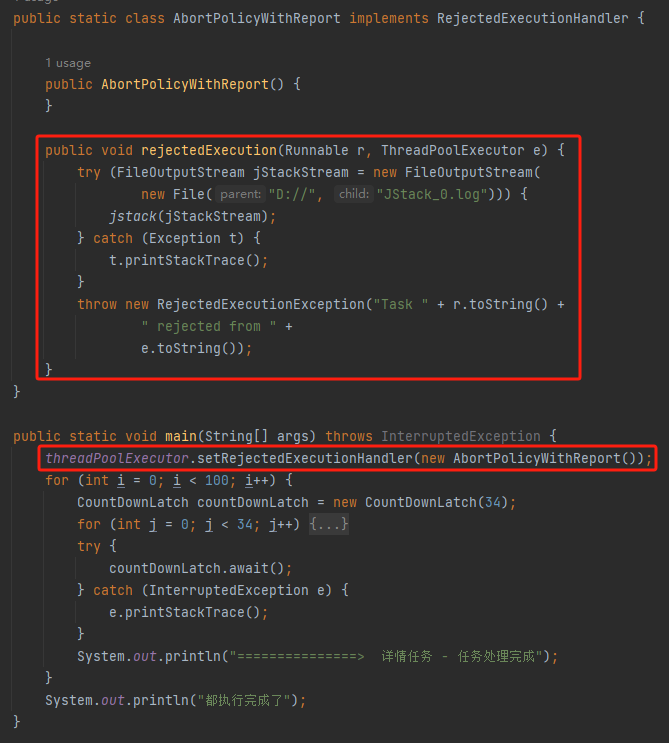
我自定义了一个拒绝策略,在触发拒绝策略的时候,dump 一把线程池:
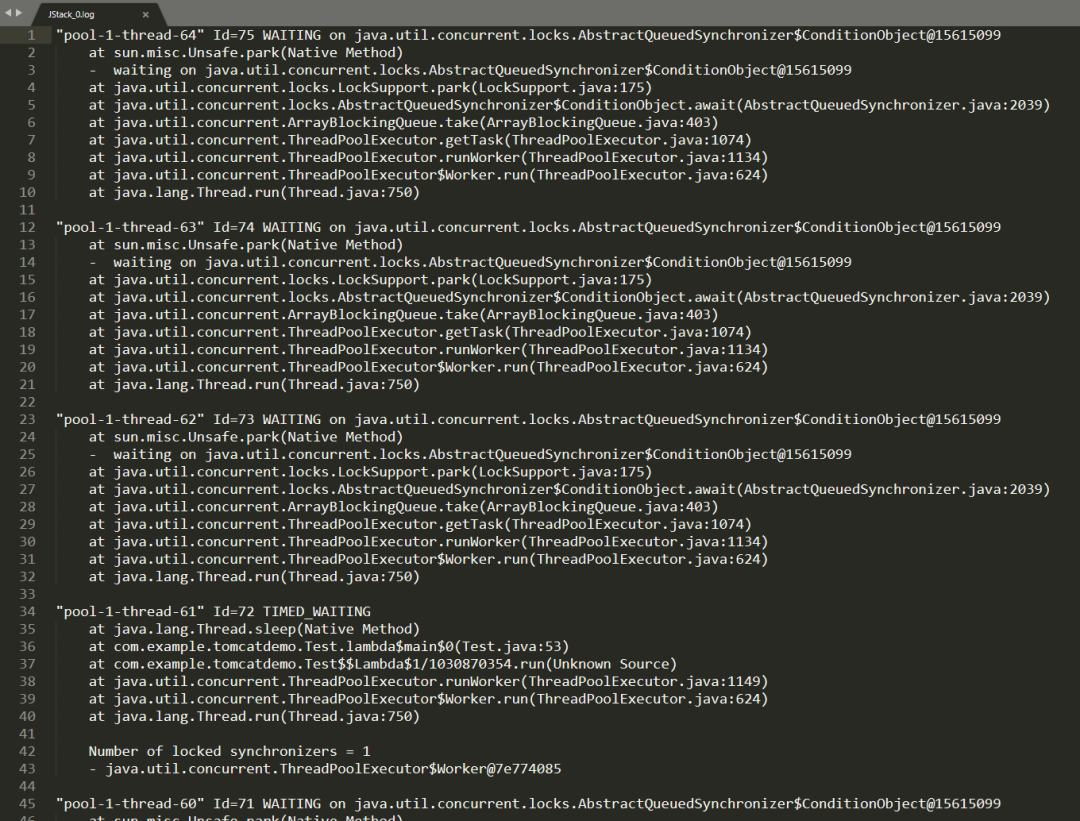
但是很不幸,最终 dump 出来的结果并不是我期望的,线程池里面的线程,不是在 TIMED_WAITING 状态就是在 WAITING 状态,没有一个是 RUNNING 的。
为什么?
很简单,因为在触发拒绝策略之后,dump 完成之前,这之间代码执行的时间,完全够线程池里面的线程完成“两个工作”。
虽然你 dump 了,但是还是晚了一点。
这一点,可以通过在 dump 前面输出一点日志进行观察验证:
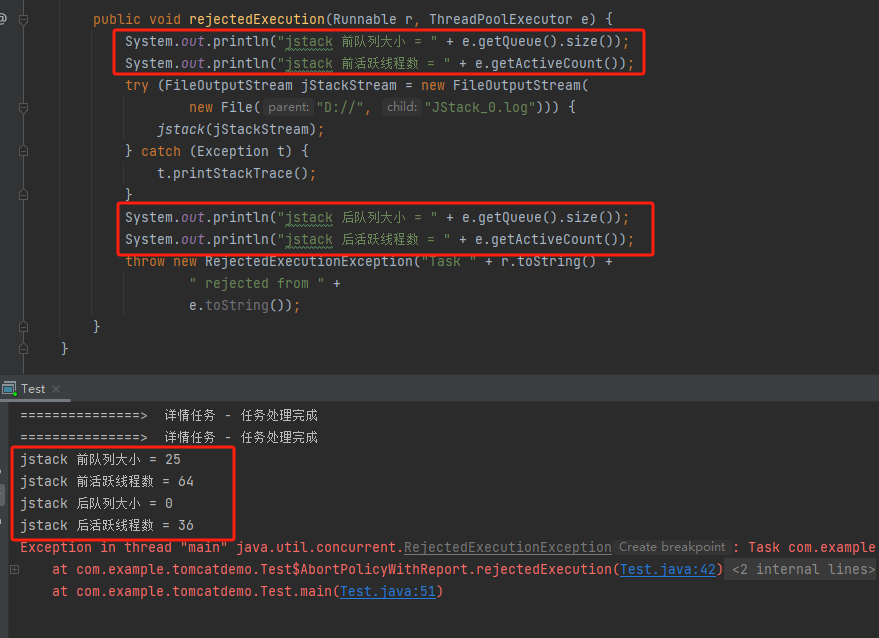
虽然我没有通过 dump 文件验证到我的观点,但是你可以学习一下这个手段。
在正常的业务逻辑中触发拒绝策略的时候,可以 dump 一把,方便你分析。
那么问题就来了?
怎么去 dump 呢?
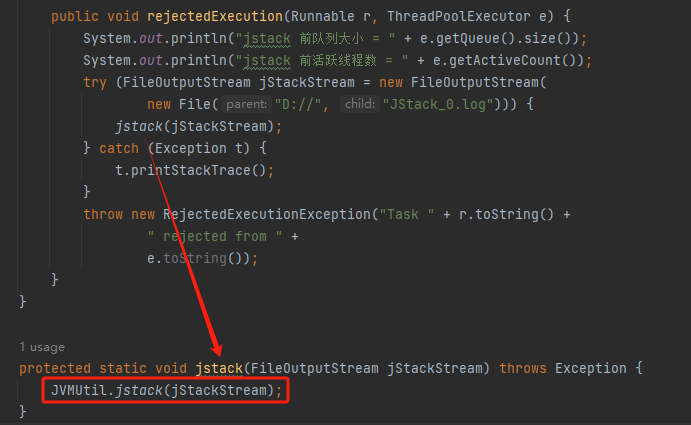
关键代码就这一行:
JVMUtil.jstack(jStackStream);
这个方法其实是 Dubbo 里面的一个工具,我只是引用了一下 Dubbo 的包:
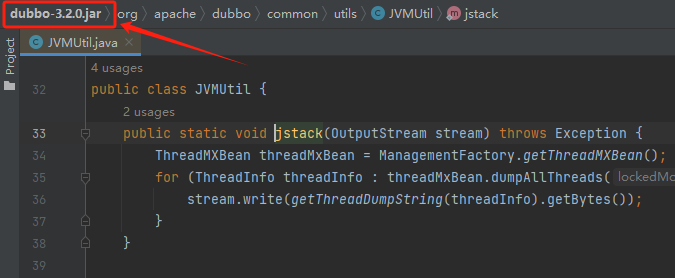
但是你完全可以把这个工具类粘出去,粘到你的项目中去。
你的代码很好,现在它是我的了。

最后,我还是必须要再补充一句:
以上从问题的定位到问题的复现,都是基于我个人的分析,从猜测出发,最终进行验证的。有可能我猜错了,那么整个论证过程可能都是错的。你可以把 Demo 粘过去跑一跑,带着怀疑一切的眼光去审视它,如果你有不同的看法,可以告诉我,我也学习一下。
最后,你想想整个过程。
拆开了看,无非是线程池和 CountDownLatch 的八股文的考察,这两个玩意都是面试热点考察部分,大家应该都背的滚瓜烂熟。
在实际工作中,这两个东西碰撞在一起也是经常有的写法,但是没想到的是,在套上一层简单的 for 循环之后,完全就变成了一个复杂的问题了。
这玩意着实是把我打懵逼了。以后把 CountDownLatch 放在 for 循环里面的场景,都需要多多注意一下了。

第二个场景
这个场景就简单很多了。
当时有个小伙伴在群里扔了一个截图:
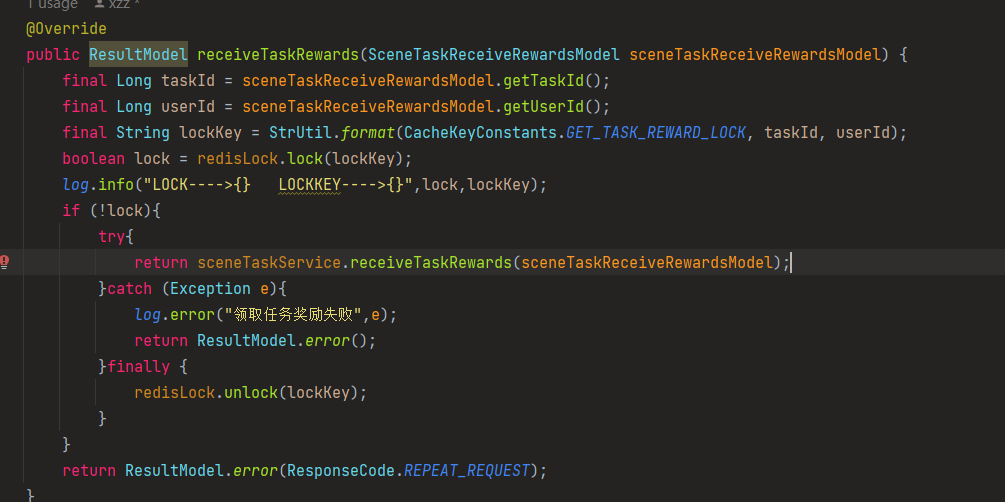
需要注意的是, if(!lock) 他截图的时候是给错了,真实的写法是 if(lock),lock 为 true 的时候就是加锁成功,进入 if。
同时这个代码这一行是有事务的:
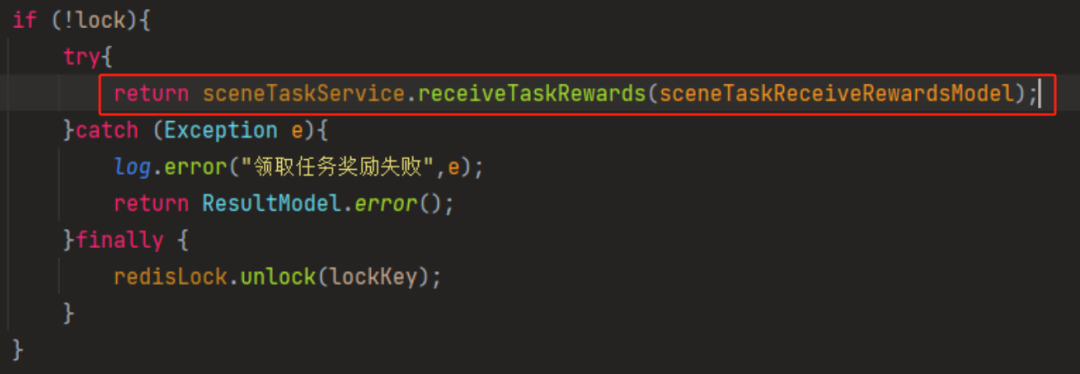
写一个对应的伪代码是这样的:
if(加锁成功){
try{
//save有事务注解,并且确认调用的service对象是被代理的对象,即事务的写法一定是正确的
return service.save();
} catch(Exception e){
//异常打印
} finally {
//释放锁
unlock(lockKey);
}
}
就上面这个写法,先加锁,再开启事务,执行事务方法,接着提交事务,最后解锁,反正歪师傅横看竖看是没有发现有任何毛病的。
但是提供截图的小伙伴是这样描述的。
当他是这样写的时候,从结果来看,程序是先加锁,再开启事务,执行事务方法,然后解锁,最后才提交事务:
当时我就觉得:这现象完全超出了我的认知,绝不可能。
紧接着他提供了第二张截图:
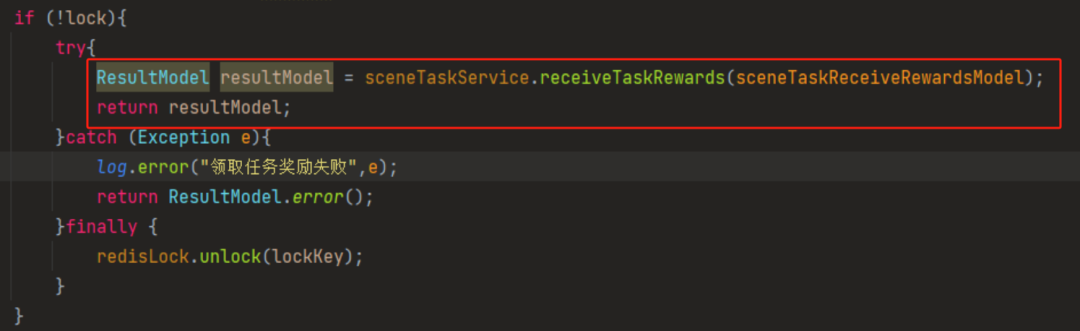
他说这样拆开写的时候,事务就能正常生效了:

这两个写法的唯一区别就是一个是直接 return,一个是先返回了一个 resultModel 然后在 return。
在实际效果上,我认为是没有任何差异的。
但是他说这样写会导致锁释放的时机不一样。
我还是觉得:

然而突然有人冒出来说了一句:try 带着 finally 的时候,在执行 return 语句之前会先执行 finally 里面的逻辑。会不会是这个原因导致的呢?
按照这个逻辑推,先执行了 finally 里面的释放锁逻辑,再执行了 return 语句对应的表达式,也就是事务的方法。那么确实是会导致锁释放在事务执行之前。
就是这句话直接给我干懵逼了,CPU 都快烧了,感觉哪里不对,又说不上来为什么。
虽然很反直觉,但是我也记得八股文就是这样写的啊,于是我开始觉得有点意思了。
所以我搞了一个 Demo,准备本地复现一下。
当时想着,如果能复现,这可是一个违背直觉的巨坑啊,是一个很好的写作素材。
可惜,没有复现:


最后这个哥们也重新去定位了原因,发现是其他的 BUG 导致的。
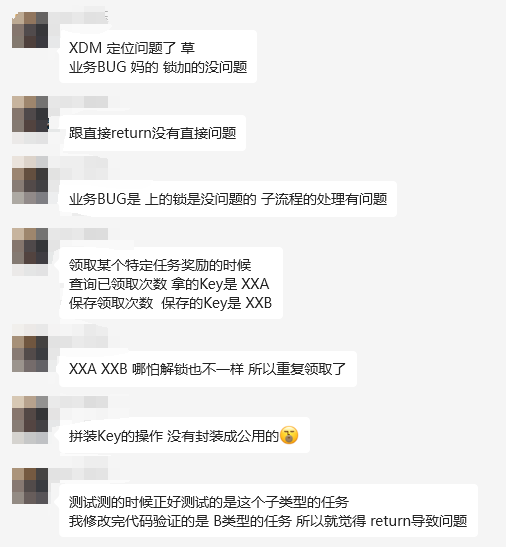
另外,关于前面“try 带着 finally”的说法其实说的并不严谨,应该是当 try 中带有 return 时,会先执行 return 前的代码,然后把需要 return 的信息暂存起来,接着再执行 finally 中的代码,最后再通过 return 返回之前保存的信息。
这才是写在八股文里面的正确答案。
要永远牢记另一位伟人说过:实践是检验真理的唯一标准。
遇事不决,就搞个 Demo 跑跑。
关于这个场景,拆开来看就是关于事务和锁碰撞在一起时的注意事项以及 try-return-finally 的执行顺序这两个基础八股而已。
但是当着两个糅在一起的时候,确实有那么几个瞬间让我眼前一黑,又打得我一脸懵逼。
最后,事务和锁碰撞在一起的情况,上个伪代码:
@Service
public class ServiceOne{
// 设置一把可重入的公平锁
private Lock lock = new ReentrantLock(true);
@Transactional(rollbackFor = Exception.class)
public Result func(long seckillId, long userId) {
lock.lock();
// 执行数据库操作——查询商品库存数量
// 如果 库存数量 满足要求 执行数据库操作——减少库存数量——模拟卖出货物操作
lock.unlock();
}
}
如果你五秒钟没看出这个代码的问题,秒杀这个问题的话,那歪师傅推荐你个假粉丝看看这篇文章:《几行烂代码,我赔了16万。》
好了,就酱,打完收工~
好啦,本文的技术部分就到这里了。
下面这个环节叫做[荒腔走板],技术文章后面我偶尔会记录、分享点生活相关的事情,和技术毫无关系。我知道看起来很突兀,但是我喜欢,因为这是一个普通博主的生活气息。
荒腔走板

1 月 17 日的时候,手机上某 APP 突然给我弹了一个消息,说“还记得十年前的今天在干什么吗”。
于是我点进去一看,就是上面这张照片。
10 年前,我还在读大二,1 月 17 日应该是学校放寒假了,这张照片是我从成都做大巴车回老家的时候拍得。
那一年从成都到老家还没有通动车,每次回家都是买大巴车的票回去,一路上要坐超过 3 个小时的车,遇上堵车的情况,那就不知道什么时候能回家了。
记得有一年小长假,我和 Max 同学一起从成都回老家,当时也不能提前在网上购票,都是需要到现场窗口购买。结果小长假车站的人流量非常可怕,我们一大早就到了,但是只买到了当天下午很晚的一班车。
那个时候购车票我记得甚至不需要实名制,于是我就在退票的地方和等车的地方像个社牛一样大声呼喊,有没有要换 xx 班次车的。
没想到还真的从一个大哥手上换到了两张上午的车票,他想下午再走。
Max 同学一路上都在夸我:真机智。
这些记忆随着动车的开通,也就慢慢的成为了遥远的历史。
2019 年 10 月底,老家的车站也搬走了。
那一年我 25 岁,这个车站是我在老家居住时,每天的必经之路,我几乎在这个车站门口来来回回走了 25 年。小的时候,父母就是做长途汽车回家过年的,我记得每次去接他们的时候,都是在晚上,站在出站口,很冷,伸着脖子看着每一辆进站的大巴车。长大一点了,我就在这个车站坐车去乡下读书,周末放假又从乡下坐车回到这个车站。寒来暑往,25 年。
2019 年,随着老家动车的开通,它从老城区迁走了,换到了城郊动车站附近。
看着自己熟悉的东西渐渐的消失在自己的视野中。
我很怀念它们。
·············· END ··············

推荐👍 : Spring解决泛型擦除的思路不错,现在它是我的了。
你好呀,我是歪歪。我没进过一线大厂,没创过业,也没写过书,更不是技术专家,所以也没有什么亮眼的title。
当年高考,随缘调剂到了某二本院校计算机专业。纯属误打误撞,进入程序员的行列,之后开始了运气爆棚的程序员之路。
说起程序员之路还是有点意思,可以 点击蓝字,查看我的程序员之路。