单张、批量识别图片中文字(百度文字识别+Python的tklinker+打包pyinstaller)
共 8130字,需浏览 17分钟
·
2022-02-09 17:36
昨天我姐问我有没有软件可以批量识别图片上的文字,她在帮客户做资料整理,但是用的方法只能一张一张上传识别,不仅效率低还浪费时间。
我就找了找批量识别的软件,下载下来觉得:嗯?不错,界面也挺好,小东西做的还挺别致。但是,识别三张就停止了,提示非最新版本要联系客服升级之类的,妥妥的套路,果断删除。又找了一个,嗯?界面更加好看一点儿,人家就很直接,三张之后提示购买会员,还显示了几种VIP的费用,很“人性”嘛。
但是,在这个万物开源的互联网时代,让程序员掏腰包买软件是不可能滴,反正我是不会,啊哈哈。我首想到了反编译,把三张的限制取消,之前看过一些ios逆向工程的东西,这些应该都是通的。搜索了一番之后,有这么个方法,下载一个软件,把exe拖进去,就能显示源码了。又让我下东西,我就觉得很烦了,毕竟还是占空间的嘛。
so,我写写就好了嘛,毕竟也是一名程序员,怎么能忘了呢。16年公司项目中身份证识别用到了OCR做身份证扫描,当时还在做iOS开发,好像用的一个第三方,细节嘛忘得差不多了(而且做app的话,我姐又不是iOS系统)。这次就用python的GUI然后打包成exe吧,翻翻我的笔记,对的19年12月份学习到的python打包那些刚好用上。要考虑到客户需求以及易用性,哈哈,然后就开始了。
一、关键需求点分析:
批量、图片文字识别、导出文本、操作便捷、图形化界面
二、用到的技术:
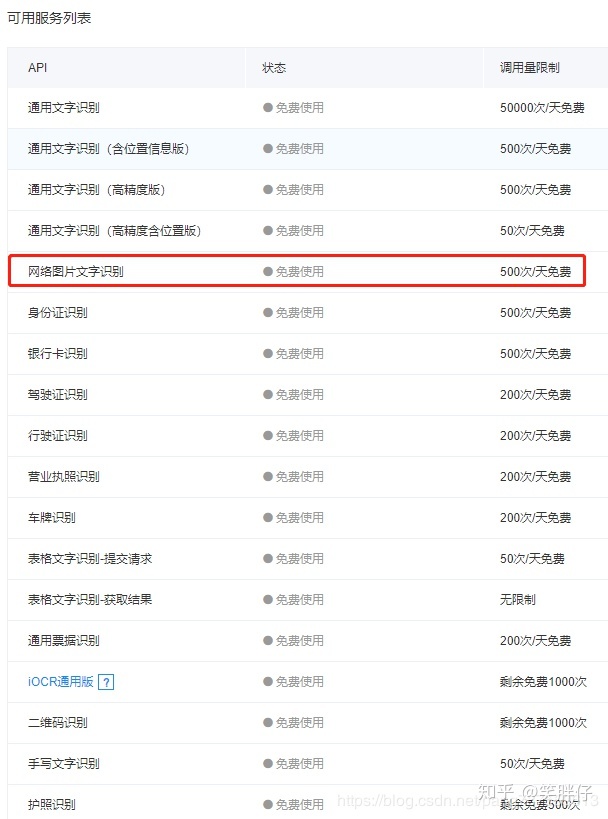
1、百度AI开放平台的通用文字识别SDK(没有广告成分,搜到什么用什么,免费调用量足够了),我的代码中用的是“网络图片文字识别”,可根据需求,自行调整;

2、python的tklinker模块、打包工具pyinstaller; 3、也可以直接写入txt;
三、踩到的坑:
前一天的代码,第二天优化改改改之后,再用新图片来识别发现不行了,一度以为是哪里写错了,各种找原因,以为是获取文件夹路径方式不对,就自己复制了路径进来,发现报错了。
坑1:图片路径——转义
运行报错:SyntaxError: (unicode error) 'unicodeescape' codec can't decode bytes in position 2-3: tr
我文件夹中复制来的路径:C:\Users\78755\Desktop\test\1.png
filePath = 'C:\Users\78755\Desktop\test\1.png'
报错原因:在windows系统当中读取文件路径可以使用\,但是在python字符串中\有转义的含义,如\t可代表TAB,\n代表换行,所以我们需要采取一些方式使得\不被解读为转义字符。
解决方案:
1、在路径前面加r,保持字符原始值的意思。
filePath = r'C:\Users\78755\Desktop\test\1.png’
2、替换为双反斜杠
filePath = 'C:\\Users\\78755\\Desktop\\test\\1.png’
3、替换为正斜杠
filePath = ‘C:/Users/78755/Desktop/test/1.png’坑2:后缀——python批量修改指定文件夹下图片后缀
import os
# 此处我是将test文件夹下全部.jpg后缀修改了成了.png并给图片重新命名
os.chdir(r'C:\Users\78755\Desktop\test'); # 指定文件夹路径
count = 1; # 初始序号
# os.listdir(path) 方法用于返回指定的文件夹(path)包含的文件或文件夹的名字的列表,如果path=None,则使用path="."
for item in [x for x in os.listdir(".")]:
# os.path.isfile( )判断某一对象(需提供绝对路径)是否为文件
# 并且后缀以.jpg结尾
if os.path.isfile(item) and os.path.splitext(item)[1] == '.jpg':
os.rename(item, '%s.png' % (count));
count += 1;
print(item);四、实现:
1、安装OCR Python SDK
OCR Python SDK目录结构
├── README.md
├── aip //SDK目录
│ ├── __init__.py //导出类
│ ├── base.py //aip基类
│ ├── http.py //http请求
│ └── ocr.py //OCR
└── setup.py //setuptools安装支持Python版本:2.7.+ ,3.+ 安装使用Python SDK有如下方式:
- 如果已安装pip,执行
pip install baidu-aip即可。 - 如果已安装setuptools,执行
python setup.py install即可。
2、新建AipOcr
AipOcr是OCR的Python SDK客户端,为使用OCR的开发人员提供了一系列的交互方法。
参考如下代码新建一个AipOcr:
from aip import AipOcr
""" 你的 APPID AK SK """
APP_ID = '你的 App ID'
API_KEY = '你的 Api Key'
SECRET_KEY = '你的 Secret Key'
client = AipOcr(APP_ID, API_KEY, SECRET_KEY)在上面代码中,常量APP_ID在百度智能云控制台中创建,常量API_KEY与SECRET_KEY是在创建完毕应用后,系统分配给用户的,均为字符串,用于标识用户,为访问做签名验证,可在AI服务控制台中的应用列表中查看。
3、单张识别:
# 单张图片识别
i=open(r'C:\Users\78755\Desktop\test\1.png','rb')
image = i.read()
result=client.basicGeneral(image)
#将所有的文字都合并到一起
for item in result['words_result']:
print(item['words'])4、批量识别:
# 图片批量识别
filePath = r'C:\Users\78755\Desktop\test'
def get_file_content(filePath):
with open(filePath, 'rb') as fp:
return fp.read()
for root, dirs, files in os.walk(".", topdown=False):
for name in files:
if 'png' in name:
filePath = os.path.join(root, name)[2:]
options = {
'detect_direction': 'true',
'language_type': 'CHN_ENG',
}
result = aipOcr.webImage(get_file_content(filePath), options)
print(result)
for i in result['words_result']:
print(i['words'])5、写入txt文件:
# 写入txt
f = open("文件名.txt", "a") #a 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。
f.write('要写入的内容')
f.close()6、Python GUI之tkinter窗口视窗的创建,并实现选择文件夹路径并展示路径的功能:
import tkinter as tk # 使用Tkinter前需要先导入
from tkinter import *
from tkinter.filedialog import askdirectory
# GUI
# 第1步,实例化object,建立窗口window
window = tk.Tk()
# 第2步,给窗口的可视化起名字
window.title('批量识别图片文字')
# 第3步,设定窗口的大小(长 * 宽)
window.geometry('1000x700') # 这里的乘是小x
# 选择文件夹路径方法
def selectPath():
path_ = askdirectory()
path.set(path_)
path = StringVar()
# 第4步,在窗口界面设置放置Button按键
selectedButton = tk.Button(window, text='选择文件夹', font=('Arial', 12), width=10, height=1, command=selectPath).place(x=50, y=20)
# 第5步,在图形界面上设定标签展示选择好的文件夹路径
var = tk.StringVar() # 将label标签的内容设置为字符类型,用var来接收hit_me函数的传出内容用以显示在标签上
pathLabel = tk.Label(window, textvariable=path, bg='gray', fg='white', font=('Arial', 12), width=30, height=2).place(x=180,y=20)
# 说明: bg为背景,fg为字体颜色,font为字体,width为长,height为高,这里的长和高是字符的长和高,比如height=2,就是标签有2个字符这么高
# 第6步,主窗口循环显示
window.mainloop()7、完整代码:
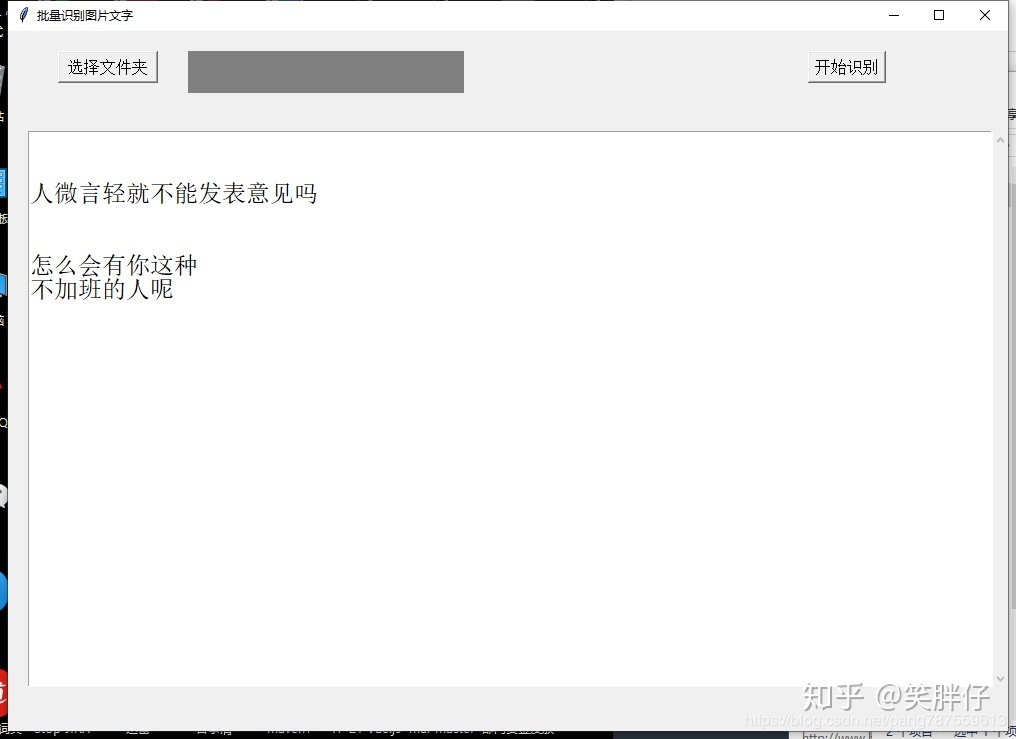
(1)、融合图片识别和图形化界面,可自定通过窗口进行选择图片文件夹进行识别(将要识别的图片放到同一文件夹下即可,此处以.png后缀为例); (2)、识别结果的展示用到了tklinker的scrolledtext; (3)、窗口大小及各控件样式可调整;
# encoding:utf-8
# author:笑胖仔
from aip import AipOcr
import os
import tkinter as tk # 使用Tkinter前需要先导入
from tkinter import *
from tkinter.filedialog import askdirectory
from tkinter import scrolledtext
""" 你的 APPID AK SK """
APP_ID = '你的 App ID'
API_KEY = '你的 Api Key'
SECRET_KEY = '你的 Secret Key'
client = AipOcr(APP_ID, API_KEY, SECRET_KEY)
# GUI
# 第1步,实例化object,建立窗口window
window = tk.Tk()
# 第2步,给窗口的可视化起名字
window.title('批量识别图片文字')
# 第3步,设定窗口的大小(长 * 宽)
window.geometry('1000x700') # 这里的乘是小x
# 选择文件夹路径方法
def selectPath():
path_ = askdirectory()
path.set(path_)
path = StringVar()
# 第4步,在窗口界面设置放置Button按键
selectedButton = tk.Button(window, text='选择文件夹', font=('Arial', 12), width=10, height=1, command=selectPath).place(x=50, y=20)
# selectedButton.pack()
# 第5步,在图形界面上设定标签
var = tk.StringVar() # 将label标签的内容设置为字符类型,用var来接收hit_me函数的传出内容用以显示在标签上
pathLabel = tk.Label(window, textvariable=path, bg='gray', fg='white', font=('Arial', 12), width=30, height=2).place(x=180,y=20)
# 说明: bg为背景,fg为字体颜色,font为字体,width为长,height为高,这里的长和高是字符的长和高,比如height=2,就是标签有2个字符这么高
# pathLabel.pack()
# 第6步,展示识别结果
resourceScrolledtext = scrolledtext.ScrolledText(window, width=80, height=23,font=("隶书",18)) #滚动文本框(宽,高(这里的高应该是以行数为单位),字体样式)
resourceScrolledtext.place(x=20, y=100) #滚动文本框在页面的位置
# 识别文字方法
def scanPics():
filePath = path.get()
# 读取图片
def get_file_content(filePath):
with open(filePath, 'rb') as fp:
return fp.read()
for root, dirs, files in os.walk(".", topdown=False):
for name in files:
if 'png' in name:
filePath = os.path.join(root, name)[2:]
options = {
'detect_direction': 'true',
'language_type': 'CHN_ENG',
}
result = client.webImage(get_file_content(filePath), options)
print(result)
resourceScrolledtext.insert("insert", '\n\n')# 在scrolledtext插入间隔,使每张图片识别内容中间有间隔
for i in result['words_result']:
print(i['words'])
# # 如果需要写入txt,将此段解注释即可
# f = open("文件名.txt", "a") #a 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。
# f.write(i['words'] + '\n')
# f.close()
# 将识别结果插入scrolledtext,在窗口试图中显示
resourceScrolledtext.insert("insert", i['words'] + '\n')
# 第7步,识别文字按钮
scanButton = tk.Button(window, text='开始识别', font=('Arial', 12), command=scanPics).place(x=800,y=20)
# scanButton.pack()
# 第8步,主窗口循环显示
window.mainloop()8、将python打包成.exe文件:
(1)、安装pyinstaller:pip install pyinstaller
(2)、打包:cd 到文件目录下,如test.py文件,pyinstaller -F test.py
(3)、执行完之后,会多出一个.spec文件以及build、dist两个目录,dist中的.exe文件直接运行即可;
9、测试:






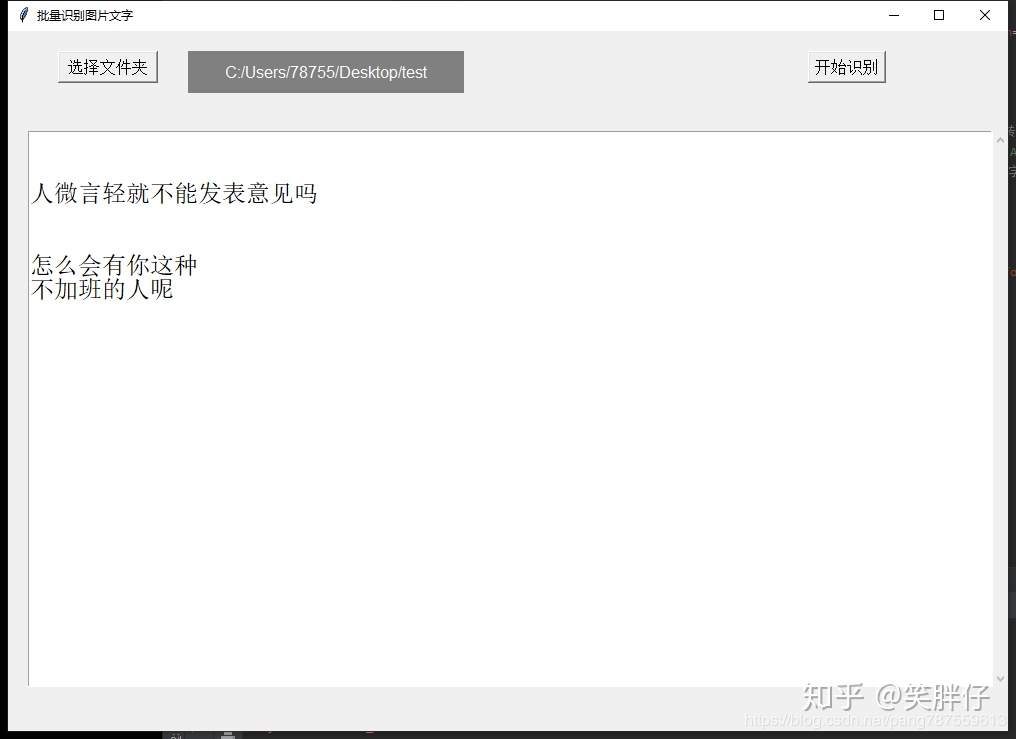
10、后续测试:
按之前步骤进行打包成exe后,反复测试都识别不成功,且命令行没有返回任何结果,而程序内运行正常。开始寻找可能的原因,并进行测试。
预测原因:“打包后exe程序不能发送网络请求”
测试1(无果):
以为是打包后的exe程序没有进行网络请求,网上有说是使用了第三方库的话,用pyinstaller打包前,需要把\Lib\site-packages下相应的包复制到同要打包的.py文件同一目录,经反复测试无用。
测试2(成功):
新建一文件requestTest.py,用request做单张图片识别请求并打印结果,测试打包成exe之后能否成功调用接口。运行打包后的exe,报错:FileNotFoundError: [Errno 2] No such file or directory: '呢呢呢.png'


尝试将资源图片复制到打包好的exe程序同目录下,即为dist目录下。此时再打开exe程序,点击识别,成功打印出结果(但是,此时已不关乎GUI中选择路径的功能,直接点击识别即可识别,不知其中缘由,但是解除了我“打包后exe程序不能发送网络请求”的猜测)。
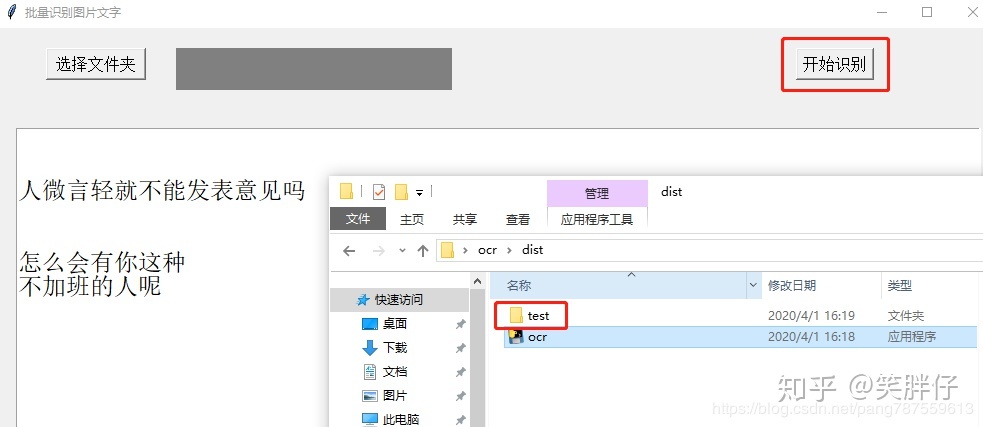
测试3(成功):
仍然换回ocr.py进行打包,打包成功后,选择文件夹,开始识别,果然还是无打印结果。把要识别的文件夹放入dist文件夹下,再打开exe,直接点击开始识别,识别成功。

11、补充:
pyinstaller打包,一些可选参数:
使用顺序:pyinstall -i 图标名称.ico -n 打包后程序名称 -w -F 要打包的文件名.py
先图标路径,再程序路径
(1)、打包单文件模式:-F (2)、打包成文件夹:-D (3)、修改icon(图标后缀.ico,不可自行修改,网上有转.ico格式的方法):-i xxx.ico (4)、修改打包后的程序名称:-n (5)、不弹出命令行行:-w
如我的程序:pyinstaller -i 笑胖仔.ico -n 批量识别图片中文字 -w -F ocr.py