Flink入门 02.安装部署
Flink支持多种安装模式
Local—本地单机模式,学习测试时使用
Standalone—独立集群模式,Flink自带集群,开发测试环境使用
StandaloneHA—独立集群高可用模式,Flink自带集群,开发测试环境使用
On Yarn—计算资源统一由Hadoop YARN管理,生产环境使用
1 Local本地模式
1.1 原理
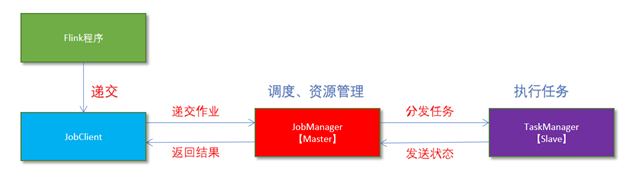
Flink程序由JobClient进行提交
JobClient将作业提交给JobManager
JobManager负责协调资源分配和作业执行。资源分配完成后,任务将提交给相应的TaskManager
TaskManager启动一个线程以开始执行。TaskManager会向JobManager报告状态更改,如开始执行,正在进行或已完成。
作业执行完成后,结果将发送回客户端(JobClient)
1.2 操作
下载安装包
https://archive.apache.org/dist/flink/
上传flink-1.13.2-bin-scala_2.11.tgz到cdh68的指定目录
解压
[song@cdh68 ~]$ tar -zxvf /data20/download/flink-1.13.2-bin-scala_2.11.tgz -C ~/app/如果出现权限问题,需要修改权限
[song@cdh68 ~]$ chmod -R 755 /home/song/app/flink-1.13.2配置环境变量
[song@cdh68 ~]$ cat .bashrc
# set flink env
export FLINK_HOME=/home/song/app/flink-1.13.2
export PATH=$FLINK_HOME/bin:$PATH
[song@cdh68 ~]$ source .bashrc
1.3 测试
准备文件
[song@cdh68 ~]$ vim data/flink/words.txt
Hello Java
Hello Scala
Hello Flink启动Flink本地集群
[song@cdh68 ~]$ app/flink-1.13.2/bin/start-cluster.sh
Setting HBASE_CONF_DIR=/etc/hbase/conf because no HBASE_CONF_DIR was set.
Starting cluster.
Setting HBASE_CONF_DIR=/etc/hbase/conf because no HBASE_CONF_DIR was set.
Setting HBASE_CONF_DIR=/etc/hbase/conf because no HBASE_CONF_DIR was set.
Starting standalonesession daemon on host cdh68.bigdata.com.
Setting HBASE_CONF_DIR=/etc/hbase/conf because no HBASE_CONF_DIR was set.
Setting HBASE_CONF_DIR=/etc/hbase/conf because no HBASE_CONF_DIR was set.
Starting taskexecutor daemon on host cdh68.bigdata.com.虽然配置了环境变量,但是最好使用绝对路径启动,因为好多大数据组件,都有start-cluster.sh命令,避免冲突
使用jps可以查看到下面两个进程
TaskManagerRunner StandaloneSessionClusterEntrypoint 访问Flink的Web UI
http://cdh68:8081
slot在Flink里面可以认为是资源组,Flink是通过将任务分成子任务并且将这些子任务分配到slot来并行执行程序。
执行官方示例
[song@cdh68 ~]$ flink run app/flink-1.13.2/examples/batch/WordCount.jar --input data/flink/words.txt --output data/flink/wordOut.txt
[song@cdh68 ~]$ cat data/flink/wordOut.txt
flink 1
hello 3
java 1
scala 1--output不用提前创建
停止Flink
[song@cdh68 ~]$ app/flink-1.13.2/bin/stop-cluster.sh
Setting HBASE_CONF_DIR=/etc/hbase/conf because no HBASE_CONF_DIR was set.
Setting HBASE_CONF_DIR=/etc/hbase/conf because no HBASE_CONF_DIR was set.
Setting HBASE_CONF_DIR=/etc/hbase/conf because no HBASE_CONF_DIR was set.
Stopping taskexecutor daemon (pid: 132331) on host cdh68.bigdata.com.
Setting HBASE_CONF_DIR=/etc/hbase/conf because no HBASE_CONF_DIR was set.
Setting HBASE_CONF_DIR=/etc/hbase/conf because no HBASE_CONF_DIR was set.
Stopping standalonesession daemon (pid: 131975) on host cdh68.bigdata.com.启动shell交互式窗口(目前所有Scala 2.12版本的安装包暂时都不支持 Scala Shell)
[song@cdh68 ~]$ start-scala-shell.sh local执行如下命令:
scala> benv.readTextFile("/home/song/data/flink/words.txt").flatMap(_.split(" ")).map((_,1)).groupBy(0).sum(1).print()
(Flink,1)
(Hello,3)
(Java,1)
(Scala,1)退出shell:
scala> :q
good bye ..
2 Standalone独立集群模式
2.1 原理
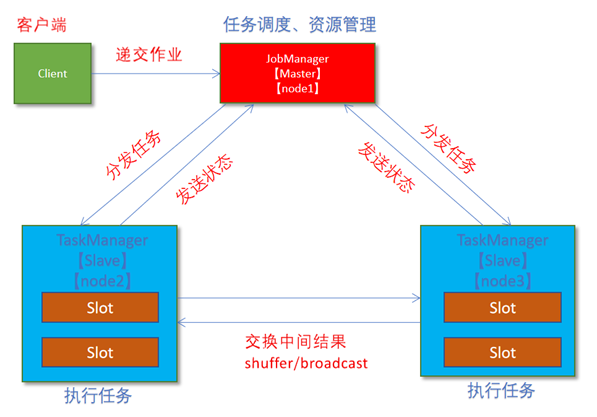
client客户端提交任务给JobManager
JobManager负责申请任务运行所需要的资源并管理任务和资源,
JobManager分发任务给TaskManager执行
TaskManager定期向JobManager汇报状态
2.2 操作
集群规划:
服务器: cdh68(Master + Slave): JobManager + TaskManager
服务器: cdh69(Slave): TaskManager
服务器: cdh70(Slave): TaskManager
修改flink-conf.yaml
[song@cdh68 ~]$ vim app/flink-1.13.2/conf/flink-conf.yaml修改内容如下:
jobmanager.rpc.address: cdh68
jobmanager.memory.process.size: 4096m
#taskmanager.memory.process.size: 1728m
taskmanager.memory.flink.size: 16384m
taskmanager.numberOfTaskSlots: 4
web.submit.enable: true
#历史服务器
jobmanager.archive.fs.dir: hdfs://nameservice1/flink/completed-jobs/
historyserver.web.address: cdh68
historyserver.web.port: 8082
historyserver.archive.fs.dir: hdfs://nameservice1/flink/completed-jobs/修改masters
[song@cdh68 ~]$ vim app/flink-1.13.2/conf/masters
cdh68:8081修改workers
[song@cdh68 ~]$ vim app/flink-1.13.2/conf/workers
cdh68
cdh69
cdh70添加HADOOP_CONF_DIR环境变量
[song@cdh68 ~]$ vim .bashrc
# set hadoop env
export HADOOP_CONF_DIR=/etc/hadoop/conf
[song@cdh68 ~]$ source .bashrc
[song@cdh68 ~]$ echo $HADOOP_CONF_DIR
/etc/hadoop/conf每台节点都要添加
分发
[song@cdh68 ~]$ scp -r app/flink-1.13.2/ cdh69:~/app/
[song@cdh68 ~]$ scp -r app/flink-1.13.2/ cdh70:~/app/
2.3 测试
启动集群,在cdh68上执行如下命令
[song@cdh68 ~]$ app/flink-1.13.2/bin/start-cluster.sh
Starting standalonesession daemon on host cdh68.bigdata.com.
Starting taskexecutor daemon on host cdh68.bigdata.com.
Starting taskexecutor daemon on host cdh69.bigdata.com.
Starting taskexecutor daemon on host cdh70.bigdata.com.
# 或者单独启动
[song@cdh68 ~]$ app/flink-1.13.2/bin/jobmanager.sh ((start|start-foreground) cluster)|stop|stop-all
[song@cdh68 ~]$ app/flink-1.13.2/bin/taskmanager.sh start|start-foreground|stop|stop-all启动历史服务器(没啥用,直接看Flink Web UI即可)
[song@cdh68 ~]$ app/flink-1.13.2/bin/historyserver.sh start
Starting historyserver daemon on host cdh68.bigdata.com.访问Flink UI界面或使用jps查看
http://cdh68:8081/#/overview
TaskManager界面:可以查看到当前Flink集群中有多少个TaskManager,每个TaskManager的slots、内存、CPU Core是多少

执行官方测试案例
[song@cdh68 ~]$ hdfs dfs -put data/flink/words.txt /data/wordcount/input
[song@cdh68 ~]$ flink run app/flink-1.13.2/examples/batch/WordCount.jar \
--input hdfs://nameservice1/data/wordcount/input/words.txt \
--output hdfs://nameservice1/data/wordcount/output/wordCount.txt
[song@cdh68 ~]$ hdfs dfs -cat /data/wordcount/output/wordCount.txt
flink 1
hello 3
java 1
scala 1停止Flink集群
[song@cdh68 ~]$ app/flink-1.13.2/bin/stop-cluster.sh
Stopping taskexecutor daemon (pid: 164979) on host cdh68.bigdata.com.
Stopping taskexecutor daemon (pid: 147217) on host cdh69.bigdata.com.
Stopping taskexecutor daemon (pid: 226601) on host cdh70.bigdata.com.
Stopping standalonesession daemon (pid: 164456) on host cdh68.bigdata.com.
3 Standalone-HA高可用集群模式
此处不想多介绍,生产环境一般使用flink on yarn
3.1 原理
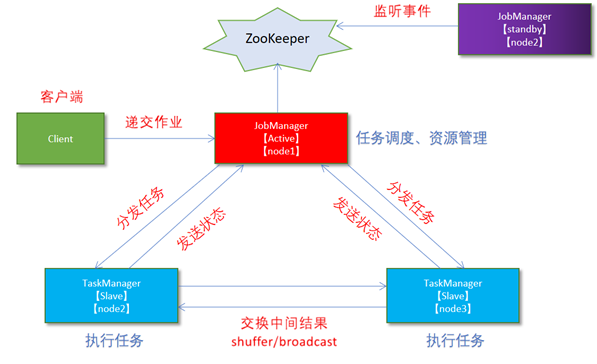
从之前的架构中我们可以很明显的发现 JobManager 有明显的单点问题(SPOF,single point of failure)。JobManager 肩负着任务调度以及资源分配,一旦 JobManager 出现意外,其后果可想而知。
在 Zookeeper 的帮助下,一个 Standalone的Flink集群会同时有多个活着的 JobManager,其中只有一个处于工作状态,其他处于 Standby 状态。当工作中的 JobManager 失去连接后(如宕机或 Crash),Zookeeper 会从 Standby 中选一个新的 JobManager 来接管 Flink 集群。
3.2 操作
集群规划
服务器: node1(Master + Slave): JobManager + TaskManager
服务器: node2(Master + Slave): JobManager + TaskManager
服务器: node3(Slave): TaskManager
启动ZooKeeper
zkServer.sh status
zkServer.sh stop
zkServer.sh start启动HDFS
/export/serves/hadoop/sbin/start-dfs.sh停止Flink集群
/export/server/flink/bin/stop-cluster.sh修改flink-conf.yaml
vim /export/server/flink/conf/flink-conf.yaml
# 在Standalone基础上,增加如下内容
# 开启HA,使用文件系统作为快照存储
state.backend: filesystem
# 启用检查点,可以将快照保存到HDFS
state.backend.fs.checkpointdir: hdfs://node1:8020/flink-checkpoints
# 使用zookeeper搭建高可用
high-availability: zookeeper
# 存储JobManager的元数据到HDFS
high-availability.storageDir: hdfs://node1:8020/flink/ha/
# 配置ZK集群地址
high-availability.zookeeper.quorum: node1:2181,node2:2181,node3:2181修改masters
node1:8081
node2:8081同步
scp -r /export/server/flink/conf/flink-conf.yaml node2:/export/server/flink/conf/
scp -r /export/server/flink/conf/flink-conf.yaml node3:/export/server/flink/conf/
scp -r /export/server/flink/conf/masters node2:/export/server/flink/conf/
scp -r /export/server/flink/conf/masters node3:/export/server/flink/conf/修改node2上的flink-conf.yaml
vim /export/server/flink/conf/flink-conf.yaml
jobmanager.rpc.address: node2重新启动Flink集群,node1上执行
/export/server/flink/bin/stop-cluster.sh
/export/server/flink/bin/start-cluster.sh
使用jps命令查看
发现没有Flink相关进程被启动
查看日志
cat /export/server/flink/log/flink-root-standalonesession-0-node1.log发现如下错误:
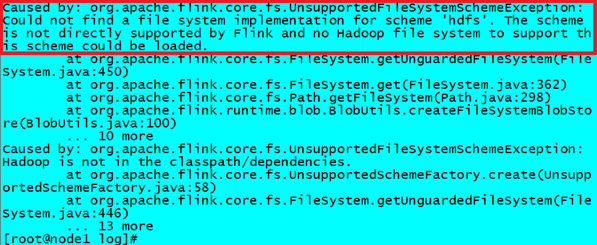
因为在Flink1.8版本后,Flink官方提供的安装包里没有整合HDFS的jar
下载jar包并在Flink的lib目录下放入该jar包并分发使Flink能够支持对Hadoop的操作
下载地址:
https://flink.apache.org/downloads.html
放入lib目录
cd /export/server/flink/lib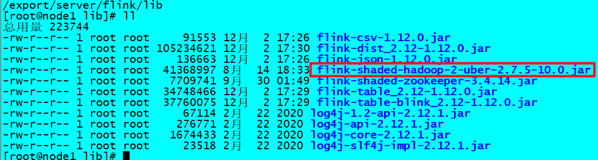
分发
for i in {2..3};
do
scp -r flink-shaded-hadoop-2-uber-2.7.5-10.0.jar node$i:$PWD;
done重新启动Flink集群,node1上执行
/export/server/flink/bin/start-cluster.sh使用jps命令查看,发现三台机器已经ok
3.3 测试
访问WebUI
http://node1:8081/#/job-manager/config
http://node2:8081/#/job-manager/config
执行wc
/export/server/flink/bin/flink run /export/server/flink/examples/batch/WordCount.jarkill掉其中一个master
重新执行wc,还是可以正常执行
/export/server/flink/bin/flink run /export/server/flink/examples/batch/WordCount.jar停止集群
/export/server/flink/bin/stop-cluster.sh
4 Flink On Yarn模式
4.1 原理
4.1.1 为什么使用Flink On Yarn?
在实际开发中,使用Flink时,更多的使用方式是Flink On Yarn模式,原因如下:
Yarn的资源可以按需使用,提高集群的资源利用率
Yarn的任务有优先级,根据优先级运行作业
基于Yarn调度系统,能够自动化地处理各个角色的 Failover(容错)
JobManager 进程和 TaskManager 进程都由 Yarn NodeManager 监控 如果 JobManager 进程异常退出,则 Yarn ResourceManager 会重新调度 JobManager 到其他机器 如果 TaskManager 进程异常退出,JobManager 会收到消息并重新向 Yarn ResourceManager 申请资源,重新启动 TaskManager
4.1.2 Flink如何和Yarn进行交互?
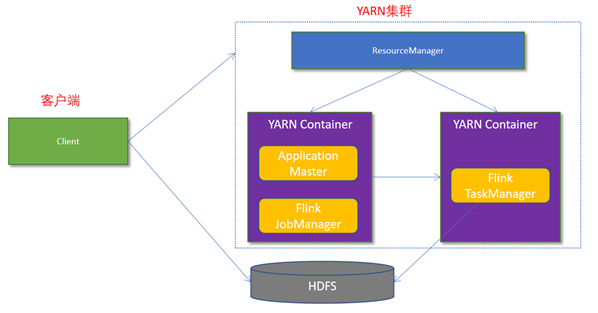
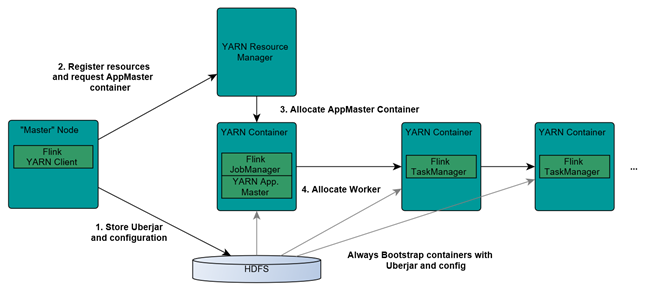
Client上传jar包和配置文件到HDFS集群上
Client向Yarn ResourceManager提交任务并申请资源
ResourceManager分配Container资源并启动ApplicationMaster,然后AppMaster加载Flink的Jar包和配置构建环境,启动JobManager
JobManager和ApplicationMaster运行在同一个container上。
一旦他们被成功启动,AppMaster就知道JobManager的地址(AM它自己所在的机器)。
它就会为TaskManager生成一个新的Flink配置文件(他们就可以连接到JobManager)。
这个配置文件也被上传到HDFS上。
此外,AppMaster容器也提供了Flink的web服务接口。
YARN所分配的所有端口都是临时端口,这允许用户并行执行多个Flink
ApplicationMaster向ResourceManager申请工作资源,NodeManager加载Flink的Jar包和配置构建环境并启动TaskManager
TaskManager启动后向JobManager发送心跳包,并等待JobManager向其分配任务
4.1.3 三种方式
Session模式
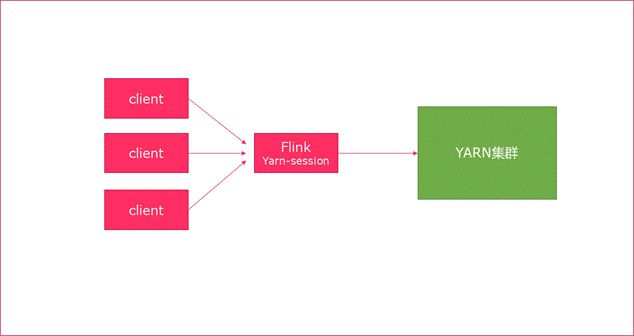
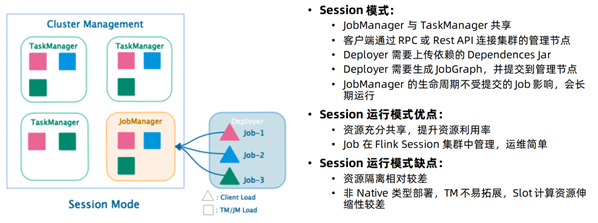
特点:需要事先申请资源,启动JobManager和TaskManger
优点:不需要每次递交作业申请资源,而是使用已经申请好的资源,从而提高执行效率
缺点:作业执行完成以后,资源不会被释放,因此一直会占用系统资源
应用场景:适合作业递交比较频繁的场景,小作业比较多的场景
Per-Job模式
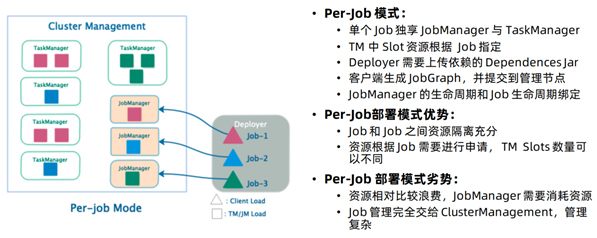
特点:每次递交作业都需要申请一次资源
优点:作业运行完成,资源会立刻被释放,不会一直占用系统资源
缺点:每次递交作业都需要申请资源,会影响执行效率,因为申请资源需要消耗时间
应用场景:适合作业比较少的场景、大作业的场景
Application 模式
4.2 操作
Make sure that the
HADOOP_CLASSPATHenvironment variable is set up (it can be checked by runningecho $HADOOP_CLASSPATH). If not, set it up usingexport HADOOP_CLASSPATH=`hadoop classpath`
关闭yarn的内存检查
vim /export/server/hadoop/etc/hadoop/yarn-site.xml添加:
说明:
是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true。
在这里面我们需要关闭,因为对于flink使用yarn模式下,很容易内存超标,这个时候yarn会自动杀掉job
同步
scp -r /export/server/hadoop/etc/hadoop/yarn-site.xml node2:/export/server/hadoop/etc/hadoop/yarn-site.xml
scp -r /export/server/hadoop/etc/hadoop/yarn-site.xml node3:/export/server/hadoop/etc/hadoop/yarn-site.xml重启yarn
/export/server/hadoop/sbin/stop-yarn.sh
/export/server/hadoop/sbin/start-yarn.sh
4.3 测试
4.3.1 Session模式
yarn-session.sh(开辟资源) + flink run(提交任务)
在yarn上启动一个Flink会话,cdh68上执行以下命令
[song@cdh68 ~]$ yarn-session.sh --detached
2021-08-30 18:13:47,565 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Deploying cluster, current state ACCEPTED
JobManager Web Interface: http://cdh69.bigdata.com:33201
2021-08-30 18:13:54,039 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli [] - The Flink YARN session cluster has been started in detached mode. In order to stop Flink gracefully, use the following command:
$ echo "stop" | ./bin/yarn-session.sh -id application_1625993468363_0037
If this should not be possible, then you can also kill Flink via YARN's web interface or via:
$ yarn application -kill application_1625993468363_0037
Note that killing Flink might not clean up all job artifacts and temporary files.查看UI界面
http://cdh68:8088/cluster
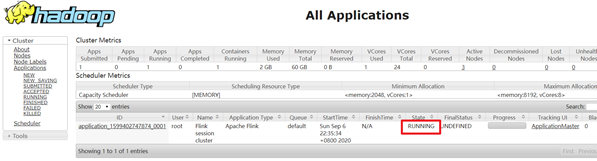
使用flink run提交任务:
[song@cdh68 ~]$ hdfs dfs -rm /data/wordcount/output/wordCount.txt
[song@cdh68 ~]$ flink run -t yarn-session \
-Dyarn.application.id=application_1625993468363_0037 \
app/flink-1.13.2/examples/batch/WordCount.jar \
--input hdfs://nameservice1/data/wordcount/input/words.txt \
--output hdfs://nameservice1/data/wordcount/output/wordCount.txt
[song@cdh68 ~]$ hdfs dfs -cat /data/wordcount/output/wordCount.txt
flink 1
hello 3
java 1
scala 1运行完之后可以继续运行其他的小任务
通过上方的ApplicationMaster可以进入Flink的管理界面

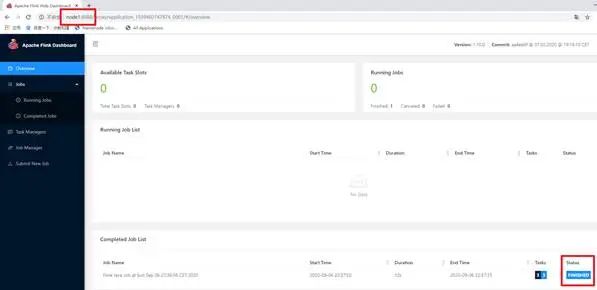
关闭yarn-session:
[song@cdh68 ~]$ yarn application -kill application_1625993468363_0037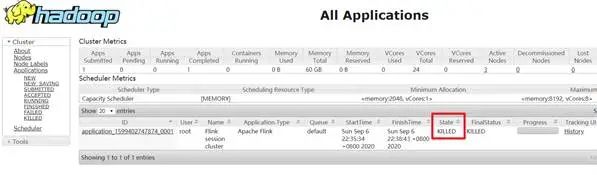
The session mode will create a hidden YARN properties file in
/tmp/.yarn-properties-<username>, which will be picked up for cluster discovery by the command line interface when submitting a job.[song@cdh68 ~]$ rm -rf /tmp/.yarn-properties-song
4.3.2 Per-Job分离模式
直接提交job
[song@cdh68 ~]$ hdfs dfs -rm /data/wordcount/output/wordCount.txt
[song@cdh68 ~]$ flink run -t yarn-per-job \
-yjm 4096 \
-ytm 16384 \
-ys 4 \
/home/song/app/flink-1.13.2/examples/batch/WordCount.jar \
--input hdfs://nameservice1/data/wordcount/input/words.txt \
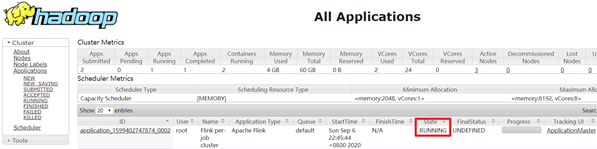
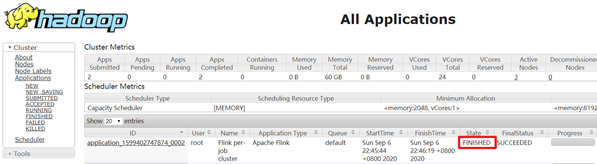
--output hdfs://nameservice1/data/wordcount/output/wordCount.txt查看UI界面
http://cdh68:8088/cluster
注意
在之前版本中如果使用的是flink on yarn方式,想切换回standalone模式的话,如果报错需要删除:
[song@cdh68 ~]$ rm -rf /tmp/.yarn-properties-song因为默认查找当前yarn集群中已有的yarn-session信息中的jobmanager
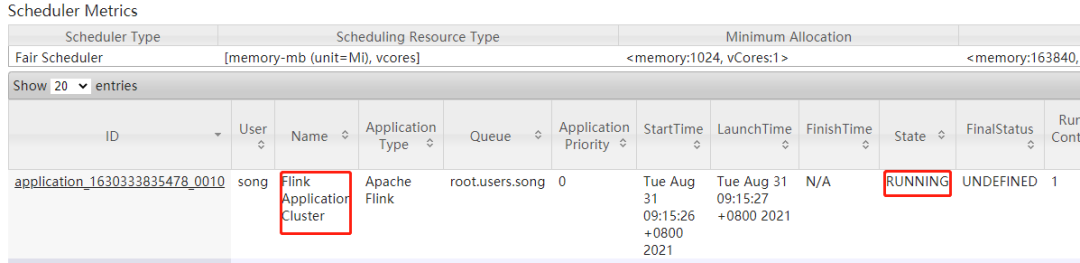
4.3.3 Application分离模式
直接提交job
[song@cdh68 ~]$ hdfs dfs -rm /data/wordcount/output/wordCount.txt
[song@cdh68 ~]$ flink run-application -t yarn-application \
-yjm 4096 \
-ytm 16384 \
-ys 4 \
/home/song/app/flink-1.13.2/examples/batch/WordCount.jar \
--input hdfs://nameservice1/data/wordcount/input/words.txt \
--output hdfs://nameservice1/data/wordcount/output/wordCount.txt查看UI界面
http://cdh68:8088/cluster