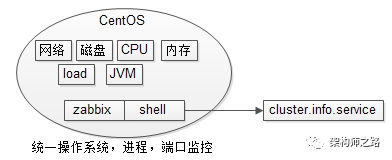
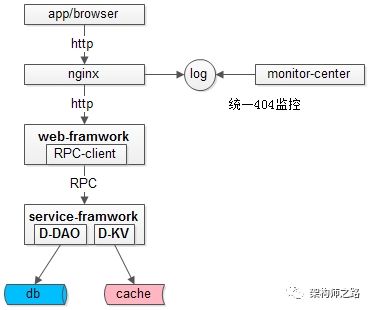
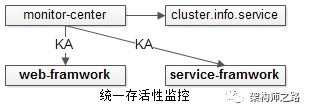
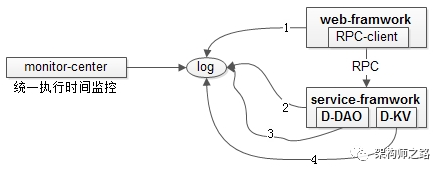
怎样的监控,才真正说明系统有问题?架构师之路关注共 2610字,需浏览 6分钟 ·2020-12-07 00:29 监控不告警,系统就一定没有问题么?怎样的监控,才真正说明系统有问题?今天和大伙聊聊多维度立体化监控。 什么是多维度立体化监控?不同公司或多或少有一些自动化监控手段,例如:(1)http接口监控;(2)log关键字监控;(3)操作系统,进程,端口;(4)http状态码;(5)服务存活性;(6)接口处理时间;(7)RPC接口监控;(8)用户层面监控; 如果只监控一个或少数几个维度:(1)监控到异常时,基本确信系统出现了问题;(2)反过来,没有监控到异常,不能确信系统没有问题; 例如:(1)监控到操作系统CPU100%,系统大概率出现了问题,但CPU正常,并不能说明系统正常,例如tomcat挂了,CPU肯定是正常的,但操作系统监控却探测不到,于是需要进程,端口,存活性等其他监控予以辅助;(2)进程,端口监控到异常,系统大概率出现了问题,但进程在运行,端口在监听,并不能说明系统正常,例如程序死锁,进程和端口是正常的,于是需要接口处理时间等其他监控予以辅助;(3)接口处理时间监控到超时,系统大概率出现了问题,但接口处理时间不超时,并不能说明系统正常,例如数据库挂了,数据库连接拿不到,服务层每个接口都很快返回,并不超时; 这里的观点是:单维度监控易漏报,多维度立体化监控才是监控平台的根本之道。 前文介绍的两篇:《如何在12个小时,搞定http监控?》《如何在12个小时,搞定日志监控?》在设计上都讲究通用+可扩展。接下来介绍的四个维度的监控,在设计上也是看重“通用”“非侵入性”,即被监控的站点和服务无需任何埋点,无需任何修改,被监控模块的负责人无需配合做任何事情,就能全方位cover住。 维度一,如何进行操作系统,进程,端口监控?监控需求:(1)系统的网络是否被打满,磁盘是否有空间,CPU是否繁忙,内存是否用完,负载值是否过高,JVM是否正常;(2)服务进程是否运行;(3)监听端口是否正常;(4)机器间是否联通; 常见方案一:zabbix搞运维的都懂,不展开细聊了,聊多了怕被骂。 常见方案二:shell写一些非常简单的脚本,就能够获取到网络、磁盘、CPU、内存、load、JVM的信息,在配合一些阈值的配置,就能实现超出阈值告警的功能。如果配合集群信息管理服务,通过ps, netstat, telnet等命令,也能快速实现进程,端口,连通性的简易监控。 实现要点:(1)重点考虑扩展性,可配置性,非侵入性;(2)集群信息管理服务(或者,集群信息配置文件); 维度二,如何进行404状态码监控?监控需求:监控http异常状态码。 监控方案:nginx日志统一监控如果实现了http接口统一监控,404监控的必要性并不是这么强,但毕竟实现简单,整一个通用的花不了多少时间。 在聊存活性监控,接口处理时间监控之前,多说几句系统架构,如果实现了框架与组件的统一,统一监控会省非常多的力气。上图是一个典型的互联网分层架构图:(1)最上游是APP和browser;(2)反向代理层是nginx,统一http404状态码监控就实现在这一层;(3)web层,假设自研了web-framework;(4)service层,假设自研了service-framework,web层会通过RPC-client调用service;(5)数据层db,假设自研了Daojia-DAO组件调用db;(6)缓存层cache,假设自研了Daojia-KV组件调用cache; D-DAO和D-KV两个组件并没有大伙想的复杂,初期只是简单的封装了一层而已。 维度三,如何进行服务存活性监控?监控需求:进程和端口的监控,只能保证进程在,端口在,但并不能确定服务是否能响应请求,需要确定服务“活着”。 监控方案:ping-pong式监控,在站点框架,服务框架层面统一实现,提供keepalive接口:(1)在框架层面就可以实现ping-pong接口;(2)监控中心通过集群信息管理服务(或者是配置文件)获取集群类型(web/service),集群IP列表;(3)监控中心统一往集群发送内置的ping-pong请求; 强调两点:(1)如果开源框架不提供ping-pong接口,可以二次开发(要慎重,任何开源框架的二次开发,都是大坑的开始);(2)统一集群信息管理服务,或者,统一集群信息管理配置文件,真的很重要,是技术体系统一的基石; 维度四,如何进行接口执行时间监控?监控需求:(1)http站点接口有没有超时;(2)RPC服务接口有没有超时;(3)db访问有没有超时;(4)cache访问有没有超时;(5)除了超时,还要监控同一个接口的执行时间有没有同比、环比的大幅度波动,例如:一个接口平均响应时间是100ms,突然有一天增加到300ms,即使没有超时,也有理由怀疑接口出现了问题; 监控方案:框架组件统一上报(如上图1,2,3,4)。(1)在web-framework里,对所有http接口进行数据上报,可以上报url,参数,执行时间等核心数据;(2)在service-framework里,对所有RPC接口进行数据上报,可以上报接口,参数,执行时间等核心数据;(3)在DAO里,对所有数据库SQL访问进行数据上报,可以上报sql,参数,执行时间等核心数据;(4)在KV-client里,对所有cache访问进行数据上报,可以上报key,执行时间等核心数据;统一上报是思路,具体上报细节,是通过flume刷日志,还是storm/spark实时流处理,都可以。 总结监控是一个技术活:(1)监控平台的思路是多维度立体化监控;(2)“统一操作系统、http404,服务存活性,接口处理时间”等四大类统一监控的设计核心是“非侵入性”,不需要任何人配合修改,就能实现诸多功能的技术平台,才是好技术平台;(3)统一集群信息管理服务,统一人员信息管理服务,统一告警策略服务(或者配置文件),是统一技术体系的基石;架构师之路-分享技术思路思路比结论更重要,希望大家有收获。调研贵司的监控,涵盖了哪些方面? 浏览 65点赞 评论 收藏 分享 手机扫一扫分享分享 举报 评论图片表情视频评价全部评论推荐 Netflix 怎样做系统监控?公众号程序猿DD0每日倾听 | 怎样才算真正的努力?核桃AI0Netflix是怎样做系统监控的?极客挖掘机0erp系统是怎样的,有没有人告知下?怎么说呢,ERP系统就是一个为企业提供决策、计划、控制与经营业绩评估的全方位和系统化的管理平台,打个比喻,ERP是企业的大脑和神经系统,负责新闻的收集,处理,指挥。也可以说ERP就是企业的一面镜子,让企业的流程可见、可控。市面上性价比比较高的系统,有智邦国际ERP,可帮助企业管理规范化,提高企业的管理水平;提高员工的作业效率;降低企业的运营成本帮助企业决策;降低库存占用和积压风险 ,降低应收账款占用和坏账风险以及降低企业整体运营成本。AsuraTeam-Monitor功能强大的监控系统Monitor是一个功能强大、灵活的监控系统。系统安装简单,配置简单,相比zabbix,nagios,cacti,小米监控等都使用相当简单。只需要会写脚本,语言不限就可以实现任意监控需求。它具有以下特有问题!公子龙0JBisonJboss监控系统JBison.com 是一个用来监控 JBoss 服务器运行的网站,每五分钟检查一次并绘制监控曲线。MonitUNIX系统监控Monit 是一个Linux/UNIX系统上开源的进程、文件、目录和文件系统监控和管理工具,可自动维怎样的变量命名,才显得有文化?前端宇宙0Linux-dashLinux 监控系统Linux-dash 是一个低开销 Linux 服务器监控系统,基于 Web 的监控界面。Linux点赞 评论 收藏 分享 手机扫一扫分享分享 举报
 下载APP
下载APP