
在家搭建大数据分布式计算环境!
0. 前言
分布式并行编程可以大幅提高程序性能,实现高效的批量数据处理。分布式程序运行在大规模计算机集群上(廉价的服务器),可以并行执行大规模数据处理任务,从而获得海量的计算能力。因此目前常用的大数据软件都可以部署在分布式计算环境种。
关于大数据的概论,在前面的文章中已经详细讲解,这里就不再赘述。对于想学习大数据的同学而言,自己在家买设备显然成本过高,租用云服务器的价格也不便宜,对于初学者而言相当的不划算。
如果我们在家也想体验一下大数据软件分布式计算的感觉,那就动手一起来搭建吧!
1. 安装VirtualBox
为了体验分布式的计算环境,就需要有多台设备,但是家用一般也只会有1台物理机器,想体验分布式计算就需要使用虚拟机搭建多个虚拟电脑。
这里我们推荐VirtualBox软件来搭建虚拟机
链接:https://link.zhihu.com/?target=https%3A//www.virtualbox.org/
进入到VirtualBox的页面 点击Download,根据自己的电脑选择相应的版本


安装好VirtualBox后的界面
2. 配置虚拟环境
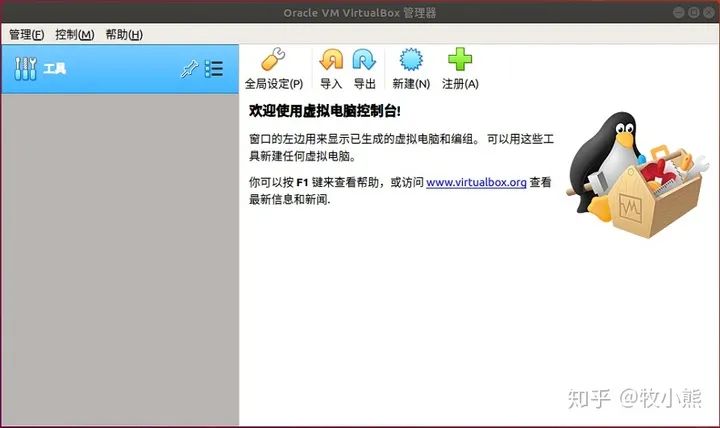
实际的大数据架构一般都会部署到linux系统上,因此对于虚拟机的操作环境我们选择了界面做的不错的Ubantu的操作系统。
点击新建,开始创建虚拟环境,名称就是虚拟机电脑的名称,文件夹就是虚拟机所在的位置,类型我选择Linux,版本根据自己电脑型号选择32-bit和64-bit。
然后点击下一步:
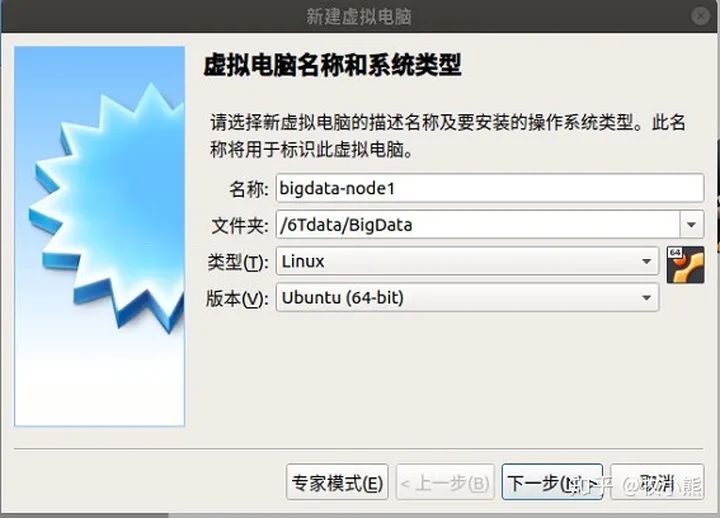
这里需要我们,选择内存大小,这里根据自己的实际机器硬件条件来设置,这里我们建议内存为4G:
然后点击下一步-->点击创建--> 点击下一步-->点击下一步。
直到这里 创建虚拟硬盘 我们稍微给虚拟硬盘的空间大一些50G:
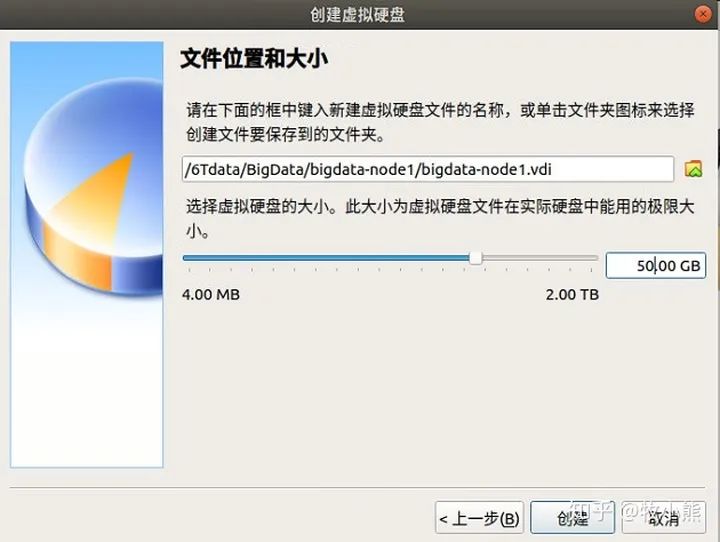
点击创建 这样我们的虚拟机就创建好了。
点击启动。这里会让你选择启动盘,点击注册-->选中提前下载好的Ubantu系统-->点击打开/
注意这里一定要选中Ubantu的系统,不要选择物理设备
选择好ubantu系统后,我确认一下,然后点击启动
Ubantu系统启动!
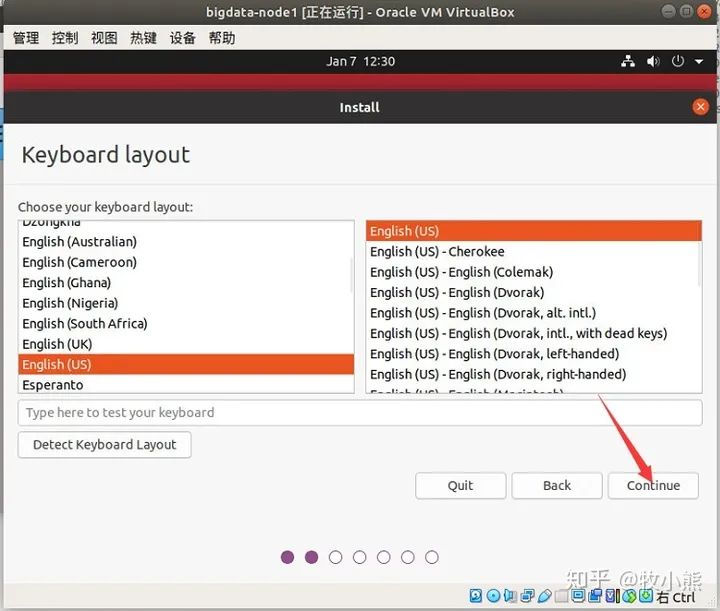
英语不好的同学这里也可以选择汉语
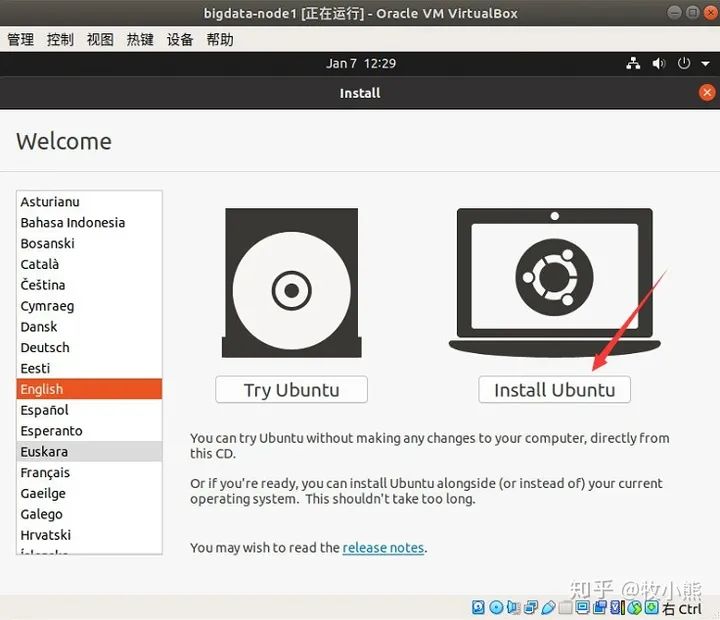
这里可以选择 Noramal installtion 就是正常安装
也可以选择Minimal installtion 就是最小化安装 只安装Ubantu系统所需要的组件,不安装其它东西,能够最大程度减少电脑的压力。
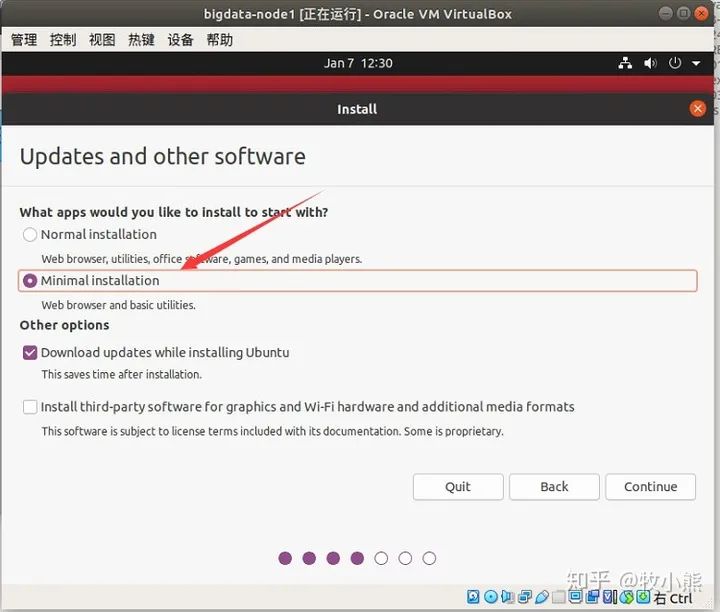
这里选择最小安装
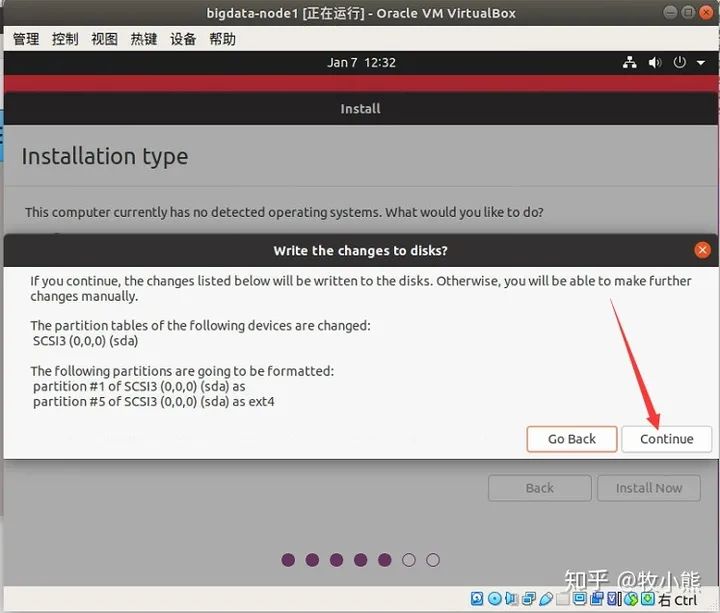
选择所在的时区
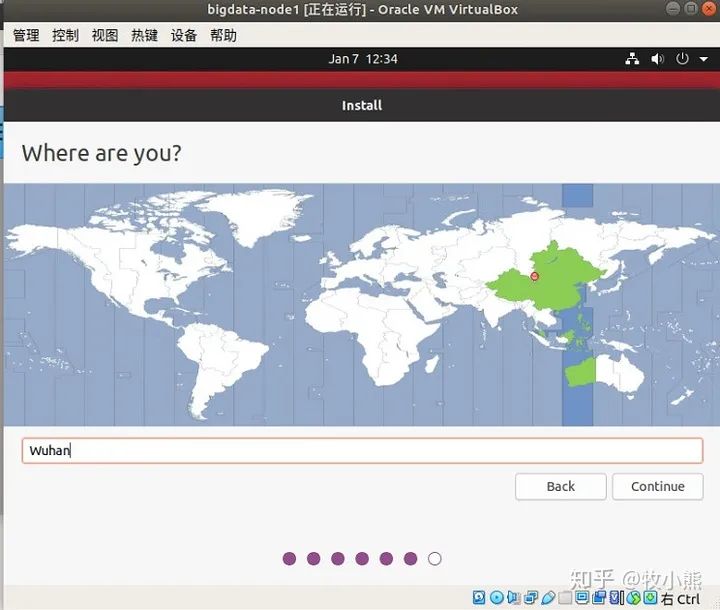
这里就是配置用户名和密码
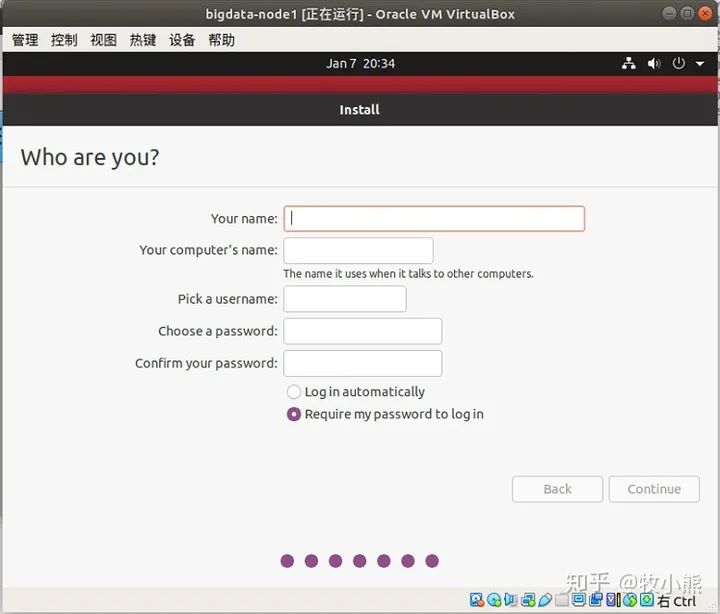
配置密码
配置好了以后进入漫长的等待
这样我们一个虚拟机就建好了
3.配置Virtual Box
3.1 配置粘贴板
点击共享粘贴版-->选择双向
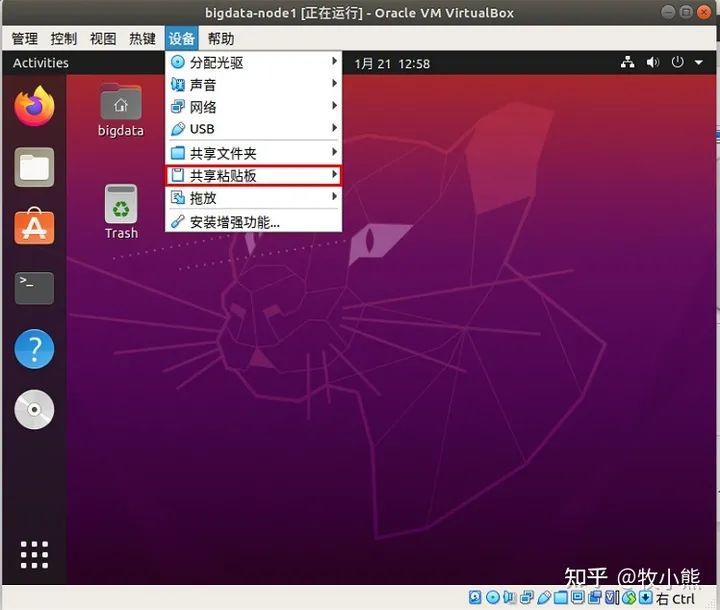
3.2 安装增强功能
点击Eject 退出虚拟光驱
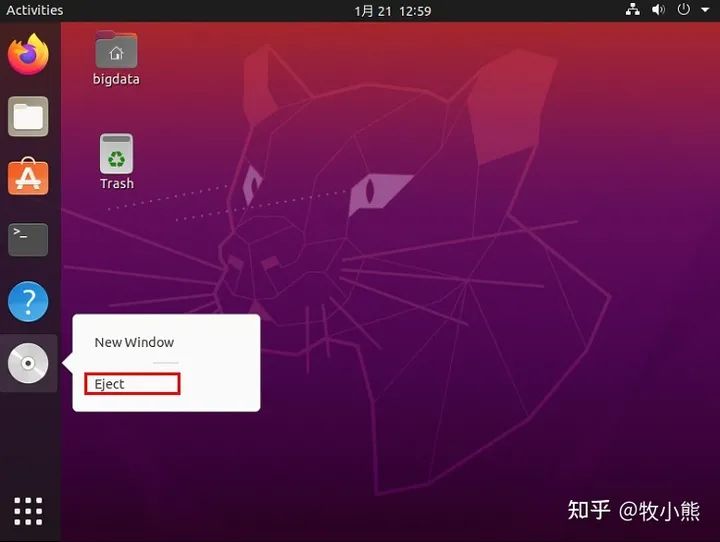
点击设备-->安装增强功能
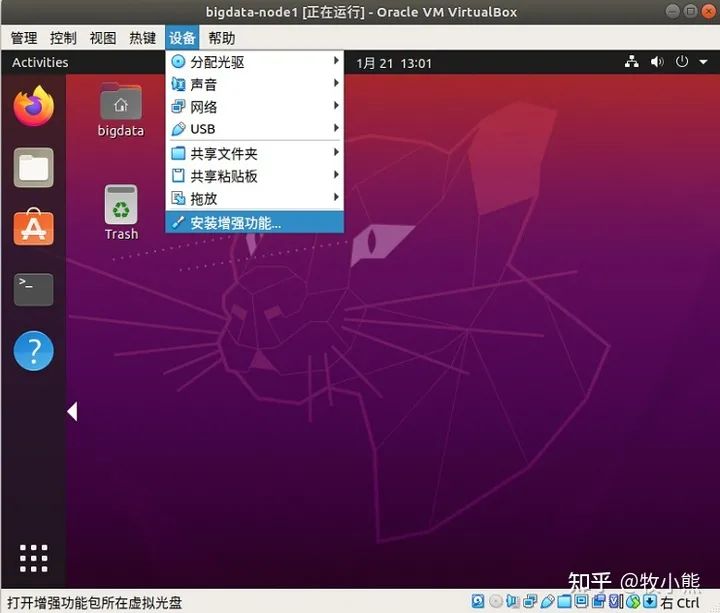
3.3 linux环境以及软件配置
点击Terminal

接下来设置基础的环境
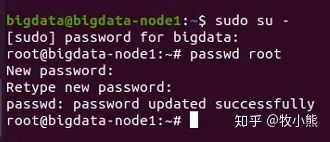
sudo su -
passwd root #设置root密码
exit
#安装必要的软件
sudo apt upgrade -y
sudo apt install vim net-tools -y
sudo apt install software-properties-common
sudo add-apt-repository ppa:deadsnakes/ppa #添加镜像源
sudo apt install openssh-server -y #配置ssh环境
systemctl status ssh
#-----以下为选择安装部分 根据自己实际情况选择-----
sudo apt install python3.8 -y #安装python3.8
sudo apt install default-jre -y
python3 #检验是否安装好
sudo apt install openjdk-11-jdk-headless -y #安装java
java --version
3.4 网络环境配置
我们希望虚拟机能够连接外部网络 同时也能互相连接
接下来设置虚拟机内部网络通信 添加虚拟网络
点击创建
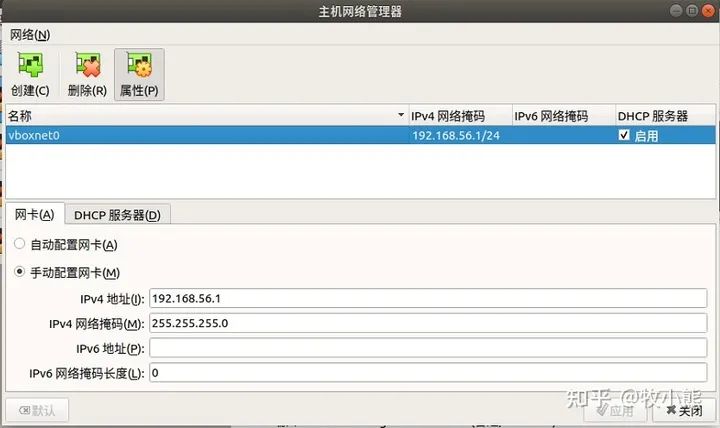
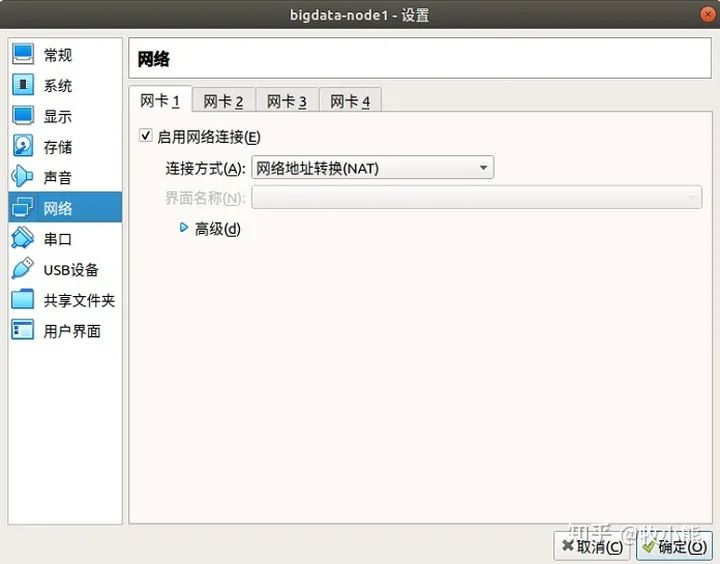
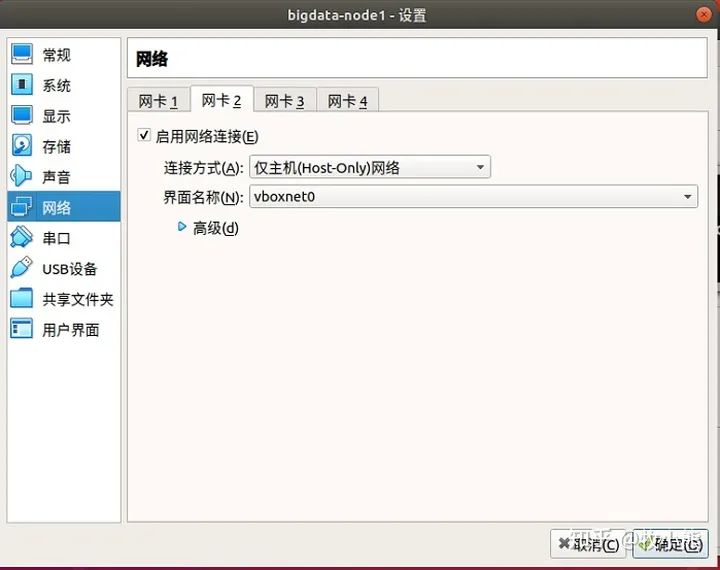
到这里我们单独的一台机器就全部配置好了

接下来就是去做克隆的工作 复制的虚拟机会和前面的一模一样!
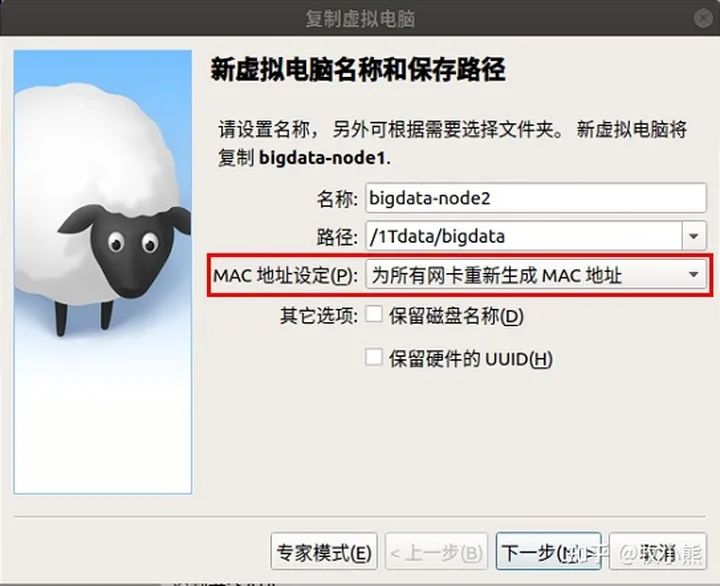
点击虚拟机-->点击右键-->点击复制/clone (修改虚拟机的名称和路径)-->点击下一步-->点击复制
注意这里一定要重新生成MAC地址,不然虚拟机之间通信会有问题!
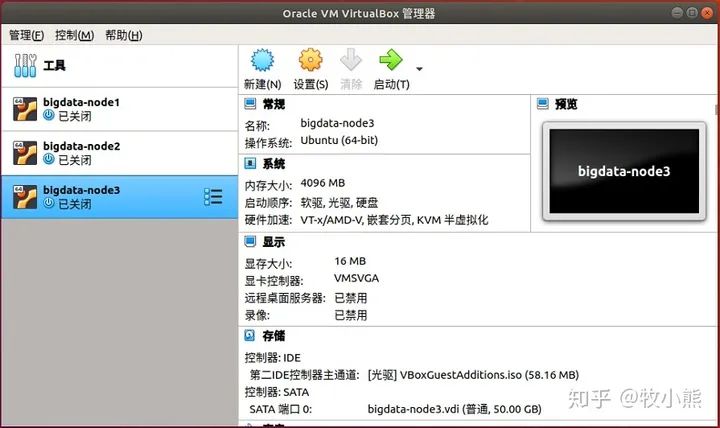
现在我们就有3台配置好的虚拟机了
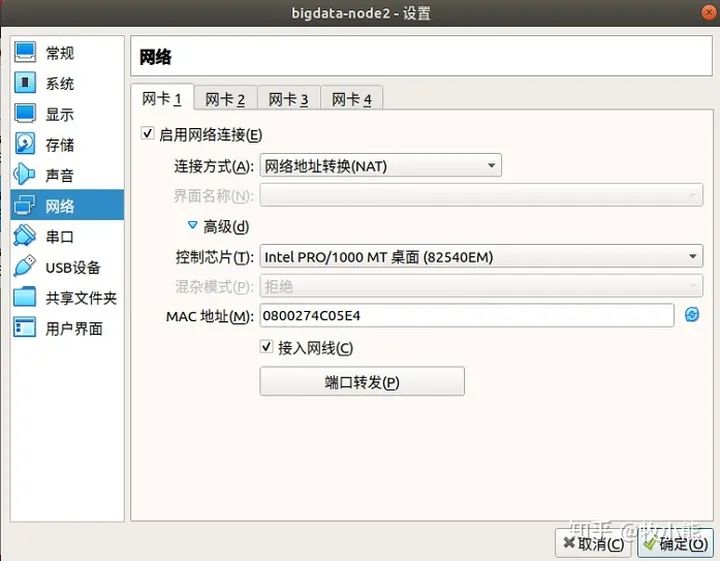
这里我们需要看以下MAC是不是更换了,如果没有更换就点击旁边的刷新按钮随机生成一个
4. 配置分布式的环境
进入到不同的电脑看看虚拟机不同的ip
ifconfig
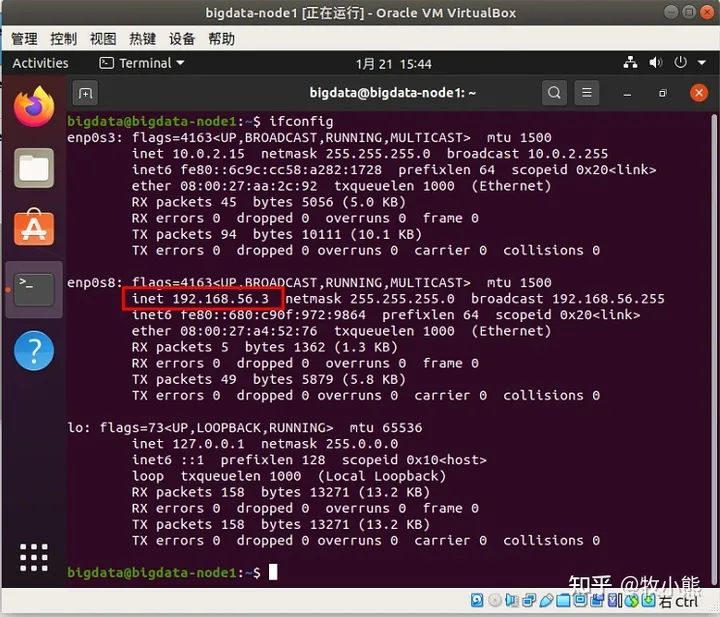
其中这个196.168.56.3就是这个虚拟机局域网的ip
接下来修改机器的名称
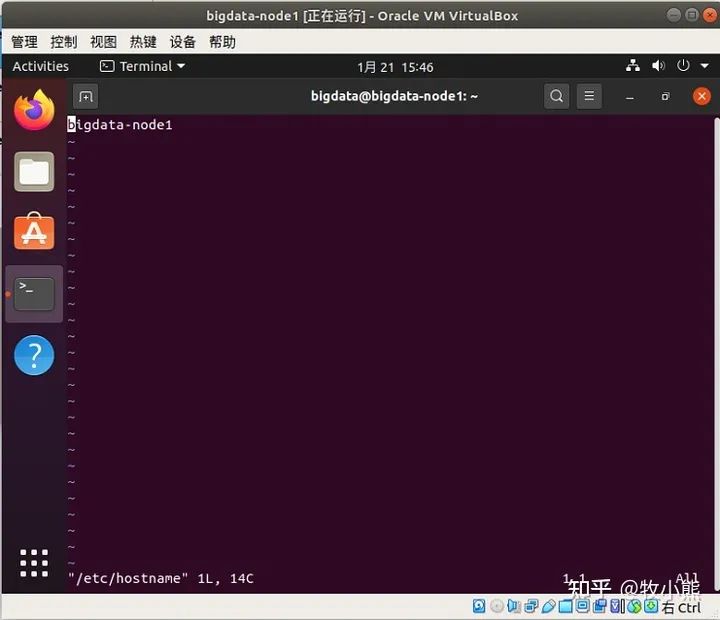
sudo vim /etc/hostname #修改机器名称
按i 进入编辑模式 修改当前机器的名称 比如这台我们修改为bigdata-node1
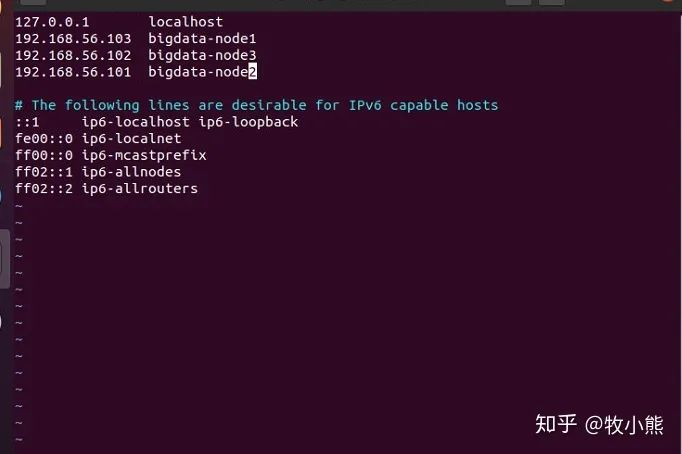
全部修改完后我们修改每台电脑的host:
sudo vim /etc/hosts #修改局域网内的别名
ping bigdata-node2
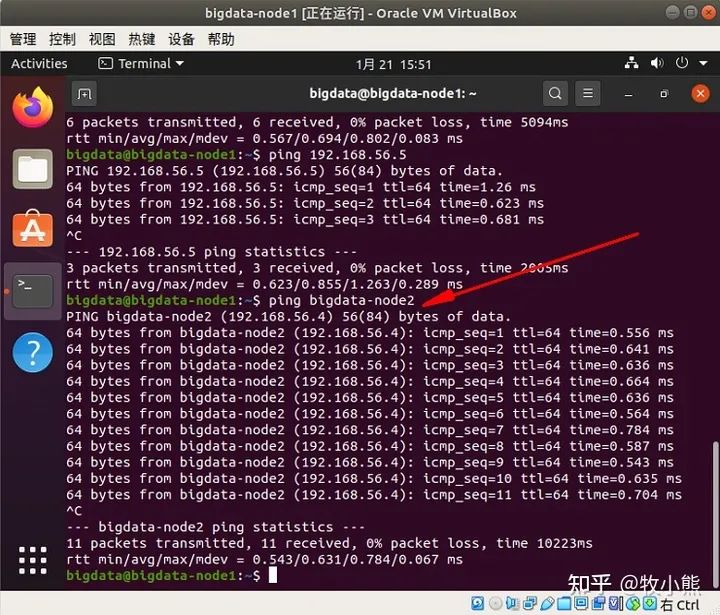
到这里我们分布式计算环境就全部搭建好了
5. 小结
本文通过VirtualBox构建了3台虚拟机,并在虚拟机上安装了Ubantu系统,通过设计虚拟网卡让3台虚拟机之间能够互相通信,这样的虚拟机和真实的分布式环境相当的接近,也方便我们在家体验分布式计算环境。
我们可以在虚拟机上部署Mysql、Hadoop、Hive、zookeeper、kafka等大数据软件,不同的软件部署的方法也不尽相同,由于篇幅的限制,这里我们不详细的介绍这些软件的安装流程。
本文通过介绍虚拟机的安装过程,目的是起到一个抛砖引玉的作用,解决学习大数据过程中没有分布式环境进行实验这一痛点。当然如果条件容许的话,使用云服务器会更好,能进一步理解软件部署到云上的过程。