
快到飞起!欧洲航天局都用的数据库,教你手把手玩转
Part 01 TDSQL PG版(原TBase)的由来和架构解析
第一个是服务体系;
第二个是存储组结构,这个存储组相当于数据治理的一种特性;
第三个是逻辑体系结构,它这个跟开源PG基本上一致;
第四个连接池管理。
一、服务体系
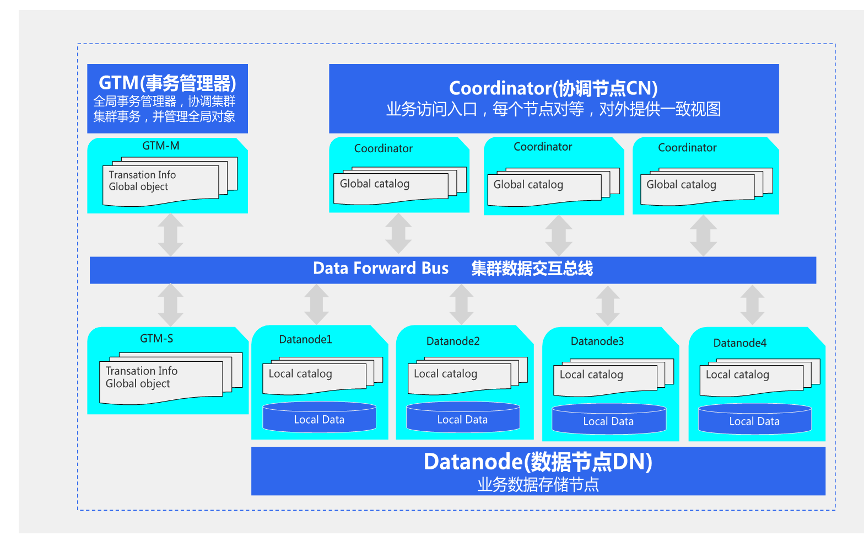
二、存储组结构

三、逻辑体系结构

四、连接池管理

Part 02 数据表使用规范

讲完体系架构,以下分享TDSQL PG版(原Tbase)数据表使用规范和指南,包括普通shard表,分区表,冷热分区表,复制表,四种表都和数据治理有关。


二、分区表

分区表比较适合带时间属性、ID属性的数据,可以实现每一个分片里面的这张表的每个物理子表的数据量尽可能低,能实现快速剪枝,性能更好。举个例子,从五千万到一个亿索引,不分区的话,高速连续写入时性能将降低一半。
三、冷热分区表

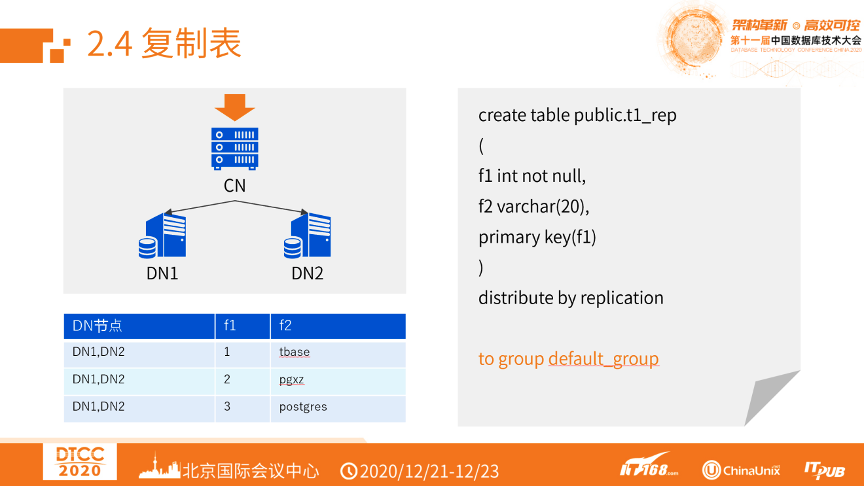
四、复制表
Part 03 索引使用规范
以下介绍TDSQL PG版的索引,包括索引类型、特殊索引,还有索引维护。
一、索引类型
BTREE索引:应用于等值、比较、范围、左右like匹配。
GIN索引:应用于数组包含查询,JSONB查询,全文搜索。
插件pg_trgm:GIN索引扩展,可以实现全模糊查询。
插件btree_gin:应用于任意字段组合查询走索引。
二、特殊索引
三、索引维护
Part 04 增删改使用规范
增删改,为了提高性能,归纳起来有三个部分:合并操作,减少扫描,数据库保护。
一、合并操作
批量插入:使用INSERT INTO .... VALUES(),()大大提高数据入库的效率。
插入更新:使用insert into xxxx values(1,'tbase',2) ON CONFLICT (f1,f2) DO UPDATE SET f3 = 2; 减少交互。
更新返回:利用returning * 特性实现更新数据同时返回影响的数据。
二、减少扫描
分片剪枝:查询/修改/删除数据时限制在尽可能少的分片中执行,水平扩展能力就越好。
分区剪枝:查询/修改/删除分区表数据时使用分区字段做为过滤条件,从而最小成本的减少扫描的数据块。
冷热存储访问剪枝:访问冷热分区表中需要明确指定时间,将查询限制在某个存储组中进行。
索引使用:索引可以快速定位到数据块,大大减少io读取开销。
三、数据库保护
评论