
还在自己画IP?仅用10张图片,还你一个百变小鹿IP形象!

点击 ▲ 三分设 关注,和 10 万设计师一起成长
三分设 x 阿里健康设计

之所以我们能利用 Stable Diffusion 亦或者是 Midjourney 来生成千变万化的图片,这都得益于背后 AI 模型与算法的配合,通过训练让计算机学会自然语言和图形的对应关系,从而实现文生图、图生图等能力。那么AI之前没学过的内容(如公司或机构的原创 IP 、场景、元素等设计)我们是不是可以通过二次训练让 AI 学习掌握,之后通过自然语言描述就能实现百变设计呢?接下来我将以小鹿 LoRA 模型为例,详解 AI 图形模型的训练方法。
00.
前言
AIGC模型概念
在开始正式的训练之前,我们先回顾一下基础的 AI 模型概念。这次 LoRA 训练所有内容都是基于“ Stability AI ”这家公司所开源的 AI 模型“ Stable Diffusion ”,自一年前来从SD1.5 版本迭代到 SD2.1 版本,目前市面上流行的 SD 风格化模型,基本上都是基于这两款原始模型训练而来的;就在不久前其开源了最新的 SDXL 模型,这次迭代可以说是一次革命性的,其模型的参数量是 V1.0 版本的十倍达到了百亿级[1]!
SDXL的难度更低效果更好!
SDXL 不仅扩大了参数量而且质量也得到了大幅提升,模型学习的每张图的像素达到了1024*1024 ,较与之前两个版本的源模型相比,其使用难度更低,效果更好,对描述词的包容度也非常的高[1],之前我们写描述词时,除了准确描述我们需要生成的主题外,还需要大量的晦涩的咒语来提升产出质量,现在使用 SDXL 不仅不需要这些额外的词,而且能通过自然语言的句式来完成高质量的产出。
XIAOLU_LoRA Baes SDXL
SDXL 产出的图像会具有更多的细节,这是归功于其创新的“ Refiner ”结构[1],这次开源出来的模型包含了两个部分,一个是基础模型另一个是优化器及“ Refiner ”,两个模型共达到了 13G ;其工作原理是用基础模型出图后再用“ Refiner ”模型精加工,使细节水平得到了飞跃。最后其基本具备了写字的能力,可以直接让其在画面中生成文字设计,这将有助于 AI 在更多场景下的创新应用。
为什么我要在这着重介绍这款模型呢?因为最终的小鹿 LoRA 模型是基于 SDXL 这款源模型训练而来的,其之后的使用也需要遵循 SDXL 的出图流程,且二次训练的模型在各个原始模型间是不兼容的。
*关于SDXL更多内容可阅读官方文档:https://stability.ai/blog/stable-diffusion-sdxl-1-announcement
*SD WebUI的更新方法(以适配SDXL):https://bigcokeee.notion.site/SD-WebUI-a6687598c6b84e8abba46ffb598d3e4d?pvs=4
为什么我们选择训练LoRA模型?

最后我们还需要弄清楚一张 AI 图片的生成是由哪些因素决定的,首先“小鹿”是阿里健康设计的原创 IP 形象,即使学习了 100 亿张图像的 SDXL 的模型也无法直接生成“小鹿”这种专属的 IP ,那么我们如何让 AI 理解“小鹿”的形象呢?这就需要我们训练 LoRA 这种特征模型来帮助基础大模型掌握“小鹿”的形象特征。
接下来我们将正式进入到小鹿 LoRA 模型训练的步骤详解:
01.
LoRA模型训练SOP
首先,LoRA 模型的训练可以大致归为三个部分及:前期准备、AI的学习过程和模型的产出。
具体来说,在前期准备中我们需要准备训练的原始素材,一般简单的主体需要至少 15 张图片,而复杂的主体需要至少 100 张图片。在图片预处理中我们需要整理学习集、计算训练步数、用“ tag ”来对每张图片进行描述。在 AI 学习过程中,需要确认学习的底模调整学习参数,以及分析学习的结果数据来帮助对比反复调整参数,筛选出最佳的学习模型,最终产出 LoRA 模型。
02.
LoRA模型训练详解
流程化解析小鹿LoRA模型训练的工作流
接下来我将流程化解析小鹿 LoRA 模型训练的工作流以及每一步的注意事项。
*工作流将在绿色框中列出,注意事项将在黄色框中列出
Step1. 前期准备
首先在前期准备中,❶新建一个学习集里面包含了:“ image ”、“ log ”、“ model ”三个文件夹;❷在“ image ”文件夹中需要确认训练步数,也可以对图像做拆分训练(建更多的子文件夹如❸);Tips:每个文件夹的名称格式必须为训练步数+下划线+自定义名称。一般来说二次元图像 10-16 步/张图,写实人物 17-35 步/张图,场景一般需要 50 步/张图以上的训练。
Step2. SD预处理图像
接下我们需要对图像做预处理,这里用到了 SD 的训练模块;首先,❶“资源目录”输入原始图片文件夹路径,“目标目录”输入刚刚我们新建的带有训练步数的文件夹路径。❷保持原始尺寸。❸点选“创建镜像副本”;Tips :在之前的训练流程中我提到了,即使简单主体也需要 15 张以上的原始素材。但是我们这次只有 10 张图片,所以通过镜像副本这个巧妙的办法就可以把 10 张图片变为 20 张,让 AI 从不同的角度来学习原始图像达到以极少的素材完成 LoRA 模型的训练(不是标题党哦~)。❹勾选“使用 Deepbooru 添加说明”及以词组的形式生成描述词。

Step3. 图像预处理打tag
在实际的操作过程中,发现 SD 反推出来的描述词基本是不可用的,这也进一步说明 AI对小鹿这个 IP 形象是完全没有认知的。所以需要重新撰写了每张图片的描述词从整体开始描述:
首先,❶我会告诉 AI 这是一个 3D 渲染的 IP 形象; Tips:加入“触发词”(这一步非常关键),触发词是用来调用 LoRA 特征的关键因素之一,这里我用小鹿的拼音“ XIAOLU ”作为触发词;❷对小鹿的服饰做了描述:“一个白大褂和绿色的领带还带着一个听诊器”。❸对小鹿的面部特征做了详细的描述及:“面朝左侧,眼睛和嘴巴睁开着在笑着”。❹之后是手部特征,“左手抬起来在打招呼,右手摆向后方”。❺最后原始素材都是透明背景,但是AI是无法学习透明背景的,所以将 png 转为 jpg 格式,并对空白的背景做了相应的描述。
依照以上方式,对每张图片进行详细的描述,描述的越详细 LoRA 模型就越精细,且可个性化调控的部分就越多。
Step4. 部署和运行kohya_SS AI模型调惨的WebUI
完成了前期的图片预处理后,我们就可以正式的进入到 AI 的学习过程中;这里我们需要通过“ Koya_SS ”[6]可视化的工具与 AI 算法进行交互。部署的过程和运行我这里就不展开了,基本是与" SD WebUI "部署和运行的方式一致。
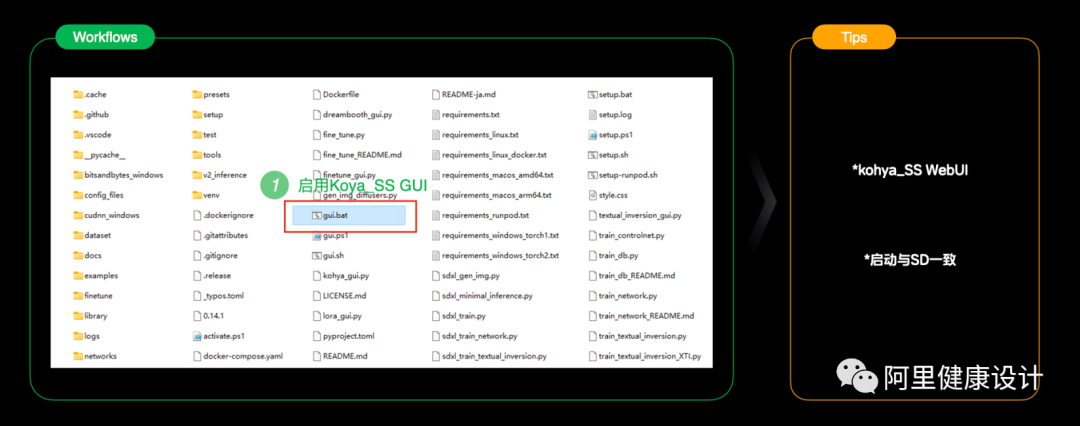
*“Kohya_SS”的部署运行方法:https://bigcokeee.notion.site/Kohya_SS-db935802b467407fb416d5f13c77b975?pvs=4
Step5. 选择底模&模型类型
进入到Koya SS界面后,
❶可以看到顶部包含了“Dreambooth”就是Checkpoint大模型的训练模块和LoRA的训练模块,以及后面的模型融合模块。今天我们主要讲的是LoRA的训练模块;
❷选择训练的底模,选择“custom”选项我们能自定义底模的路径;这里我使用的是之前提到的最新的SDXL的源模型,链接完路径后我们需要勾选上后两个选项(如下图❹❺)。
Step6. 选择底模&模型类型
❶进入“Folders”模块,需要链接前期准备阶段的文件夹路径:
❷“Image folder”:就是我们的原始素材和描述文本,
❸“output folder”:就是完成训练后LoRA的保存地址,
❹“Logging folder”:是保存的AI学习过程中的日志数据方便我们监看学习过程和反复调整参数。
❺我们需要取一个模型的名称;Tips:该名称必须是英文且不能有空格,可以用下划线来连接。
Step7. “Parameters”参数
接下来,我们进入到正式的调参环节,这里我只对必选项做详细的说明:
❶“ LoRA type ”我们选择常规项,这有利于我们之后 LoRA 模型融合的兼容性。
❷选择同时学习图片的张数,张数越多训练越快但精细度越低,这里一般保持1就可以了。❸选择训练轮数
❹选择每轮保存的数量,这里我训练的8轮每轮保存一个模型,最后会产出8个LoRA模型。❺填入之前标注文件格式“.txt”。
❻训练和保存的精度选择“ fp16 ”。
❼填入电脑的 CPU 的核心数。
❽优化器选择“ W8bit ”。
❾“ LR warmup ”设置学习预热百分比。
❿学习模型选择“ cosine with restars ”,这里的学习率在后面一步我会讲到。
*AI学习算法:可视化图表选择最佳学习算法
下图是一些学习算法的可视化图表,可以看到不同算法里学习率随着学习步数的变化。如果一直保持高的学习率会导致 LoRA 模型训练过拟合,而较低的学习率则会造成欠拟合,这里我最推荐使用“ cosine with restars ” 这个学习算法(如下图红框所示)。
Step8. 学习图片尺寸、学习率、图片裁切和精细度
❶设置学习图片的尺寸,这里设置保持和底模一致及 SDXL 的“ 1024*1024 ”。❷勾选“裁切”选项,AI 会根据图片内容裁切到上述的尺寸。❸文本学习率和❹特征学习率设置,一般文本学习率是特征学习率的 1/2 或者 1/10 。这里也可以用科学计数法来表示 1e-5 也等于 0.00005 。❺模型精细度选择,二次元一般设置在 64 以上,写实照片设置在 128 以上,场景模型在 256 以上。❻ Network Alpha 与前者模型精细度保持一致。
*“Text Encoder learning rate”:把打tag的关键词转换为AI可理解的模型
Step9. Advanced:高级选项(如配置不够的可选项)
❶进入到高级设置模块;
❷如果运行的电脑配置不够可以勾选下面的三个选项,来提升训练速度。
这样我们全部的参数就调整完了!!
Step10. 最后开始训练前Print检查参数
在最后的开始训练前,我们可以先点击“ Print ”(如下图❶),检查训练参数设置;中可以看到我们有 20 张原始素材、每张图片训练 22 步,一轮训练就是 440 步;我们一共训练 8 轮,每轮保存一个模型,那么总步数就是 440*8 就是 3520 步,以及预热总步数是 528 步(如下图“Tips”所示)。
*漫长的AI学习过程:近22个小时… …
点击开始训练后就是漫长的等待,由于 SDXL 底膜的参数量庞大,完成8轮训练,总耗时需要近 22 个小时(如下图❶所示),是之前 SD1.5 的十倍左右;在后台的代码里我们能看到,每轮训练的损失值(如下图❷所示),是 AI 对我们模型参数和素材的评分; Tips :一般保持在 0.1 左右比较好,但也不是绝对,最后是否采用该 LoRA 还是得看实际的出图对比来确认最终的版本。
*LOG数据板:根据数据反馈多版本迭代
点击 log 看板按钮,就可以看到实时的学习数据,对比不同学习参数反馈的数据,可以帮我们做出及时调整,和对比选出最佳的 LoRA 模型;如下图右下红框学习率曲线图与上述选择的“ cosine with restars ”学习算法一致。
如何选出最佳LoRA版本呢?
在这次小鹿 IP 训练过程中,我一共训练了 6 个版本共 42 个 LoRA 模型,前 4 个版本是用 SD1.5 和 SD2.1 作为底模训练的,后两个版本是 SDXL 作为底模训练的;这么多版本的模型我们怎样选出最理想的 LoRA 呢?
Plan A:SDxypolt多版本对比
在前四个版本中,我用到了“ Additional Networks ”插件和 xy 脚本自动化的方式,来对比不同 LoRA 在不同权重下的出图质量,如下图红框所示。
XYplot脚本自动化:多版本对比
这是前几个版本 LoRA 模型与权重对比的 xy 轴图,可以看到用 SD1.5 和 2.1 底模训练出来的模型质量并不高,所以前面几个版本模型就废弃了

Plan B:ComfyUI(更专业的AI控制工具)工作流
由于 SDXL 的工作流还暂不支持 Add Networks 插件,我们这里可以用更专业 Comfy UI ,一个基于工作流与 AI 模型交互的界面,这个工具可以帮我们从最底层的算法逻辑来调用 AI 模型。
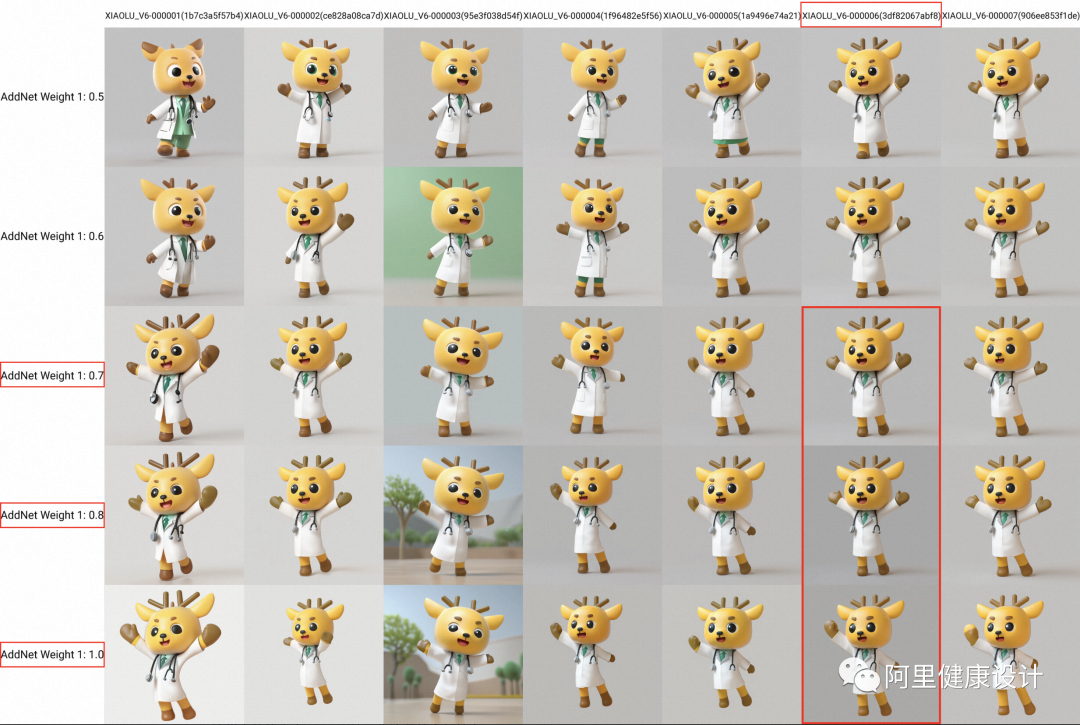
XIAOLU_V6模型对比:XIAOLU_LoRA_V6_1-7 xy plot
最后,下图是小鹿 LoRA 第 6 版的 7 个模型的权重对比图,这里 LoRA 模型的权重越高代表着与原始训练集越接近;经过对比小鹿 V6 版的 6 号模型,权重在 0.6-1 之间都与原始训练集非常接近,所以选择它为最终的小鹿 LoRA 模型(如下图红框所示)。
这样完整的小鹿LoRA训练工作流程就全部结束了!!
03.
小鹿LoRA模型应用
未来可能:AI课海报实例
接下来,我以这次AI课的海报制作为例,聊一聊小鹿LoRA模型的应用和未来的可能;
在之前的文本标签词里我们对小鹿的每个部分都打了 tag ,那么就意味着在文生图中调用小鹿LoRA并替换这些 tag 就能让小鹿穿着不同的服饰,做出不同的造型,和融入在不同的背景中。
为了展现这次分享的主题“百变小鹿IP”和传递“AI魔法”的概念,我在文生图中我写入了“穿着魔法斗篷拿着魔法棒的小鹿”,以及为了视觉更突出,加入了“强烈的光效”和“深色的背景环境”的描述词(如下图“ Prompt ”所示)。

XIAOLU_LoRA_V6.6:txt2img
下图是在不断调整提示词过程中生成的小鹿IP图像,可以看到小鹿可以很好的融合到任何环境中,以及摆出不同的造型,穿着不同的服饰,拿着不同的道具,所以小鹿LoRA配合 SDXL 基础模型就实现了百变小鹿IP形象!
最终选择了下图的小鹿手拿魔法棒身披红色斗篷,以及强烈氛围光效的这张图作为“AI LoRA训练课”海报的主视觉(如下图右侧所示)。
无限可能
有了这样一个小鹿IP形象LoRA,再通过云端部署 SD ,LoRA 模型便能在团队内共享使用,无论是设计师亦或其他专业的同学都能通过文本描述直接生成任意造型的小鹿形象,这无不大大提升了IP形象的产出效率和扩展 IP 形象的设计边界。

为什么说“只有想象不到的,没有生成不了的”呢?首先“没有生成不了的”,任何一个新的视觉化的概念或者原创IP(如系列 LOGO 、游戏场景、直播礼品元素等设计)只要将其正确的交给 AI 学习,AI 都能学会并且还可以举一反三;而“只有想象不到的”呢在目前阶段 AI 仍是一个提效的工具,最终 AI 如何产生它的价值还得是看我们各位设计师的主观能动性,所以我们也不要担心哪天我们就被 AI 所取代了,我们要做的就是不断的开拓我们的眼界,接受它学习它应用它,让 AI 能为我们所用!!

[1] Stability AI. 'Announcing SDXL 1.0'. 26 Jul 2023. https://stability.ai/blog/stable-diffusion-sdxl-1-announcement
- END -
我们相信设计师和创造者一样是思想家






