
还不懂Docker?一个故事安排的明明白白!
程序员受苦久矣
多年前的一个夜晚,风雨大作,一个名叫Docker的年轻人来到Linux帝国拜见帝国的长老。

“Linux长老,天下程序员苦于应用部署久矣,我要改变这一现状,希望长老你能帮帮我”
长老回答:“哦,小小年纪,口气不小,先请入座,你有何所求,愿闻其详”
Docker坐下后开始侃侃而谈:“当今天下,应用开发、测试、部署,各种库的依赖纷繁复杂,再加上版本之间的差异,经常出现在开发环境运行正常,而到测试环境和线上环境就出问题的现象,程序员们饱受此苦,是时候改变这一状况了。”

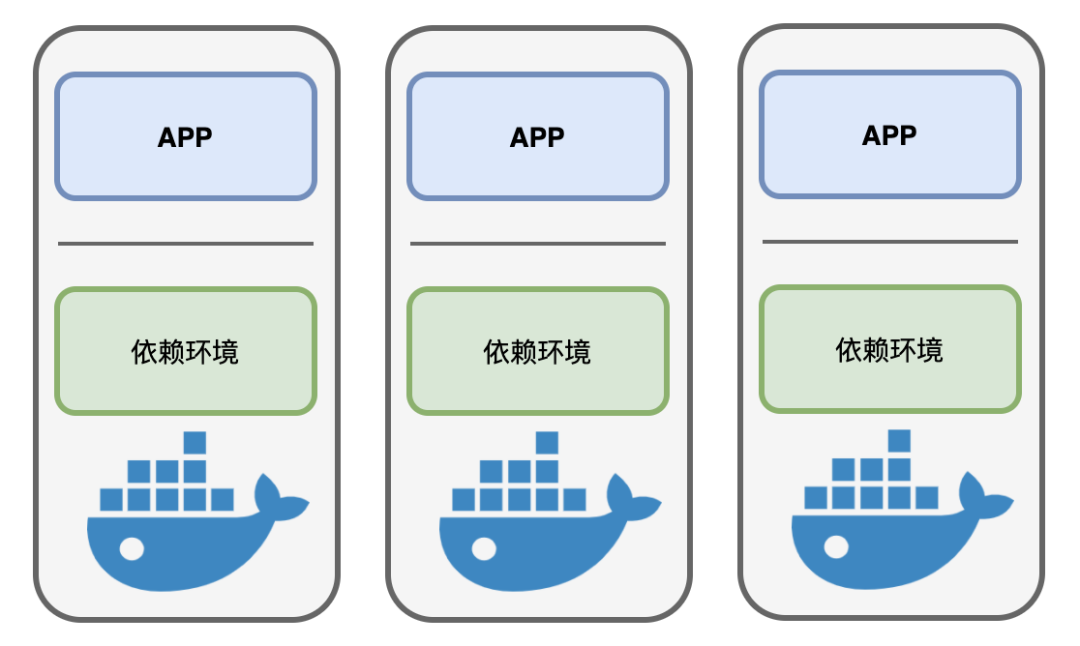
Docker回头看了一眼长老接着说到:“我想做一个虚拟的容器,让应用程序们运行其中,将它们需要的依赖环境整体打包,以便在不同机器上移植后,仍然能提供一致的运行环境,彻底将程序员们解放出来!”
Linux长老听闻,微微点头:“年轻人想法不错,不过听你的描述,好像虚拟机就能解决这个问题。将应用和所依赖的环境部署到虚拟机中,然后做个快照,直接部署虚拟机不就可以了吗?”
Docker连连摇头说到:“长老有所不知,虚拟机这家伙笨重如牛,体积又大,动不动就是以G为单位的大小,因为它里面要运行一个完整的操作系统,所以跑起来格外费劲,慢就不说了,还非常占资源,一台机器上跑不了几台虚拟机就把性能拖垮了!而我想要做一个轻量级的虚拟容器,只提供一个运行环境,不用运行一个操作系统,所有容器中的系统内核还是和外面的宿主机共用的,这样就可以批量复制很多个容器,轻便又快捷”
Linux长老站了起来,来回踱步了几圈,思考片刻之后,忽然拍桌子大声说到:“真是个好想法,这个项目我投了!”
Docker眼里见光,喜上眉梢,“这事还真离不开长老的帮助,要实现我说的目标,对进程的管理隔离都至关重要,还望长老助我一臂之力!”
“你稍等”,Linux长老转身回到内屋。没多久就出来了,手里拿了些什么东西。
“年轻人,回去之后,尽管放手大干,我赐你三个锦囊,若遇难题,可依次拆开,必有大用”

Docker开心的收下了三个锦囊,拜别Linux长老后,冒雨而归。
锦囊1:chroot & pivot_root
受到长老的鼓励,Docker充满了干劲,很快就准备启动他的项目。
作为一个容器,首要任务就是限制容器中进程的活动范围——能访问的文件系统目录。决不能让容器中的进程去肆意访问真实的系统目录,得将他们的活动范围划定到一个指定的区域,不得越雷池半步!
到底该如何限制这些进程的活动区域呢?Docker遇到了第一个难题。
苦思良久未果,Docker终于忍不住拆开了Linux长老送给自己的第一个锦囊,只见上面写了两个函数的名字:chroot & pivot_root。
Docker从未使用过这两个函数,于是在Linux帝国四处打听它们的作用。后来得知,通过这两个函数,可以修改进程和系统的根目录到一个新的位置。Docker大喜,长老真是诚不欺我!
有了这两个函数,Docker开始想办法怎么来“伪造”一个文件系统来欺骗容器中的进程。
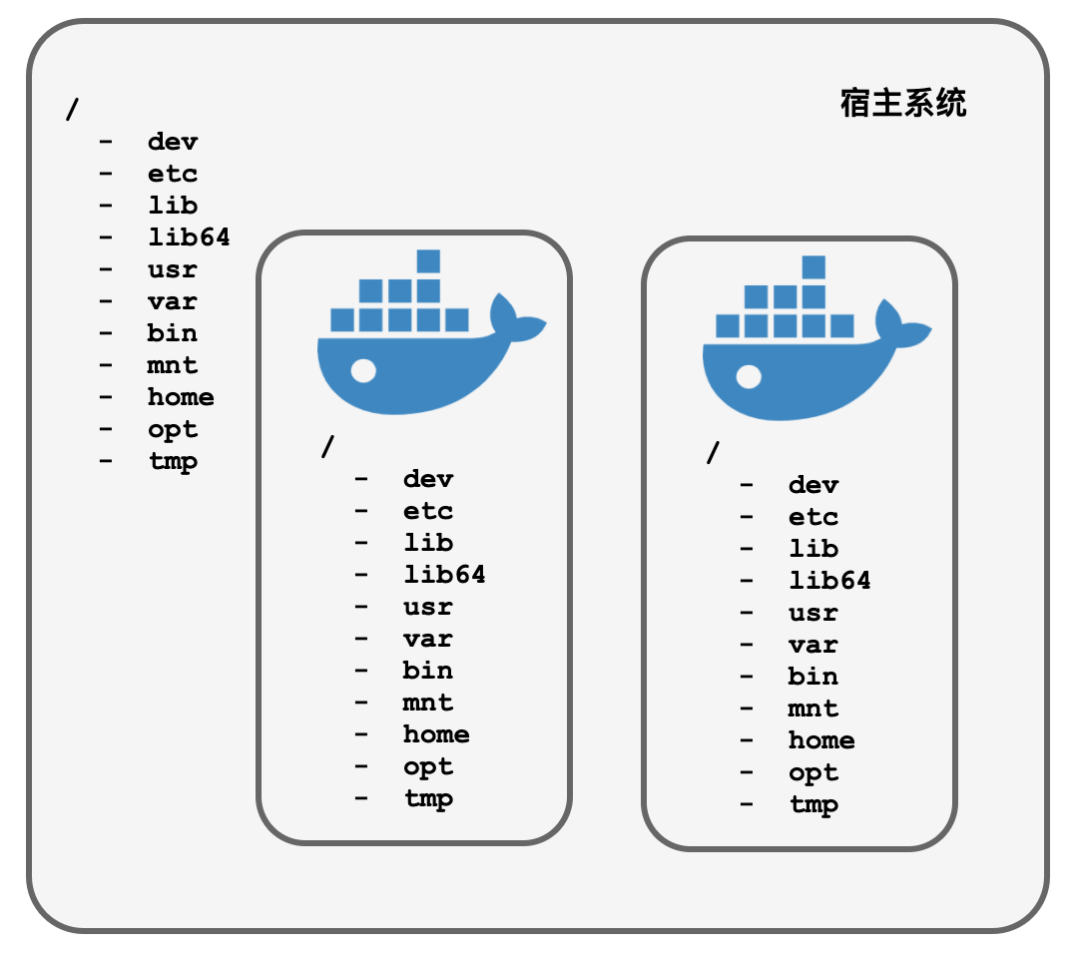
为了不露出破绽,Docker很聪明,用操作系统镜像文件挂载到容器进程的根目录下,变成容器的rootfs,和真实系统目录一模一样,足可以以假乱真:
$ ls /
bin dev etc home lib lib64 mnt opt proc root run sbin sys tmp usr var
锦囊2:namespace
文件系统的问题总算解决了,但是Docker不敢懈怠,因为在他心里,还有一个大问题一直困扰着他,那就是如何把真实系统所在的世界隐藏起来,别让容器中的进程看到。
比如进程列表、网络设备、用户列表这些,是决不能让容器中的进程知道的,得让他们看到的世界是一个干净如新的系统。
Docker心里清楚,自己虽然叫容器,但这只是表面现象,容器内的进程其实和自己一样,都是运行在宿主操作系统上面的一个个进程,想要遮住这些进程的眼睛,瞒天过海,实在不是什么容易的事情。
Docker想过用HOOK的方式,欺骗进程,但实施起来工作太过复杂,兼容性差,稳定性也得不到保障,思来想去也没想到什么好的主意。
正在一筹莫展之际,Docker又想起了Linux长老送给自己的锦囊,他赶紧拿了出来,打开了第二个锦囊,只见上面写着:namespace。
Docker还是不解其中之意,于是又在Linux帝国到处打听什么是namespace。
经过一阵琢磨,Docker总算是明白了,原来这个namespace是帝国提供的一种机制,通过它可以划定一个个的命名空间,然后把进程划分到这些命名空间中。
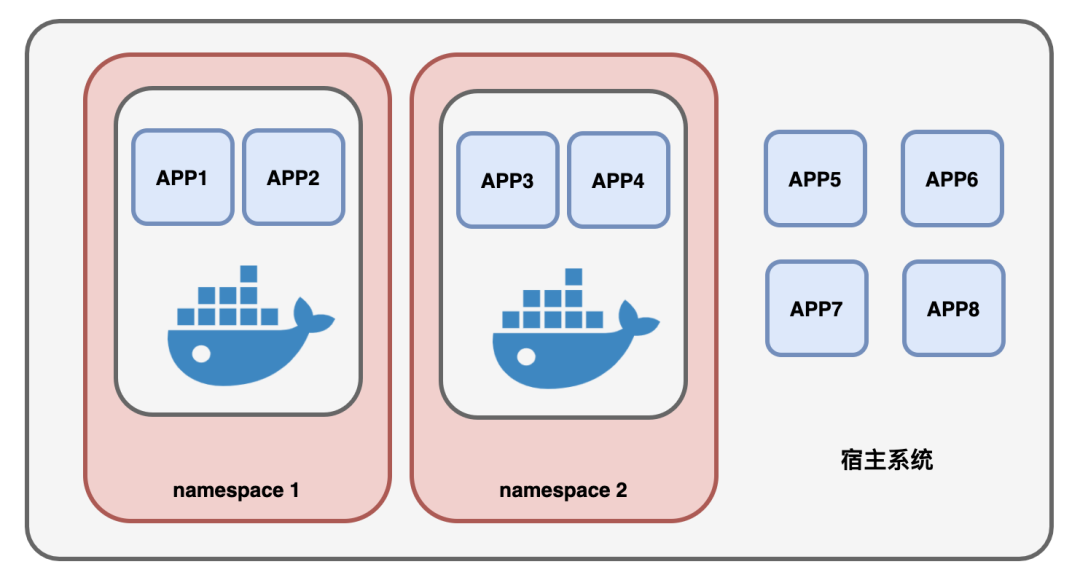
而每个命名空间都是独立存在的,命名空间里面的进程都无法看到空间之外的进程、用户、网络等等信息。
这不正是Docker想要的吗?真是踏破铁鞋无觅处,得来全不费功夫!
Docker赶紧加班加点,用上了这个namespace,将进程的“视野”锁定在容器规定的范围内,如此一来,容器内的进程彷佛被施上了障眼法,再也看不到外面的世界。
锦囊3:CGroup
文件系统和进程隔离的问题都解决了,Docker心里的石头总算是放下了。心里着急着想测试自己的容器,可又好奇这最后一个锦囊写的是什么,于是打开了第三个锦囊,只见上面写着:CGroup。
这又是什么东西?Docker仍然看不懂,不过这一次管不了那么许多了,先运行起来再说。
试着运行了一段时间,一切都在Docker的计划之中,容器中的进程都能正常的运行,都被他构建的虚拟文件系统和隔离出来的系统环境给欺骗了,Docker高兴坏了!
很快,Docker就开始在Linux帝国推广自己的容器技术,结果大受欢迎,收获了无数粉丝,连nginx、redis等一众大佬都纷纷入驻。
然而,鲜花与掌声的背后,Docker却不知道自己即将大难临头。
这天,Linux帝国内存管理部的人扣下了Docker准备“处决”掉他,Docker一脸诧异的问到,“到底发生了什么事,为什么要对我下手?”
管理人员厉声说到:“帝国管理的内存快被一个叫Redis的家伙用光了,现在要挑选一些进程来杀掉,不好意思,你中奖了”
Redis?这家伙不是我容器里的进程吗?Docker心中一惊!
“两位大人,我认识帝国的长老,麻烦通融通融,找别人去吧,Redis那家伙,我有办法收拾他”
没想到他还认识帝国长老,管理人员犹豫了一下,就放了Docker到别处去了。
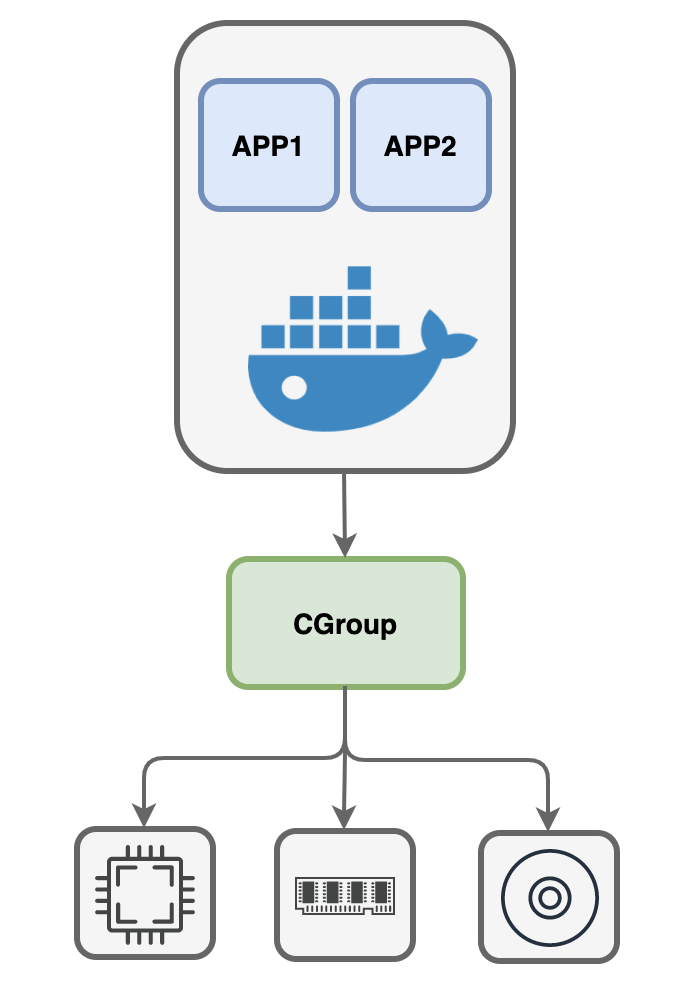
惊魂未定的Docker,思来想去,如果不对容器中的进程加以管束,那简直太危险了!除了内存,还有CPU、硬盘、网络等等资源,如果某个容器进程霸占着CPU不放手,又或者某个容器进程疯狂写硬盘,那迟早得连累到自己身上。看来必须得对这些进程进行管控,防止他们干出出格的事来。
这时候,他想起了Linux长老的第三个锦囊:CGroup!说不定能解这燃眉之急。
经过一番研究,Docker如获至宝,原来这CGroup和namespace类似,也是Linux帝国的一套机制,通过它可以划定一个个的分组,然后限制每个分组能够使用的资源,比如内存的上限值、CPU的使用率、硬盘空间总量等等。系统内核会自动检查和限制这些分组中的进程资源使用量。
Linux长老这三个锦囊简直太贴心了,一个比一个有用,Docker内心充满了感激。
随后,Docker加上了CGroup技术,加强了对容器中的进程管控,这才松了一口气。
在Linux长老三个锦囊妙计的加持下,Docker可谓风光一时,成为了Linux帝国的大名人。
然而,能力越大,责任越大,让Docker没想到的是,新的挑战还在后面。