
10分钟教会你看懂top

Average吧。今天这篇文章和大家说说怎么看这个“Load Average”。
Load Average
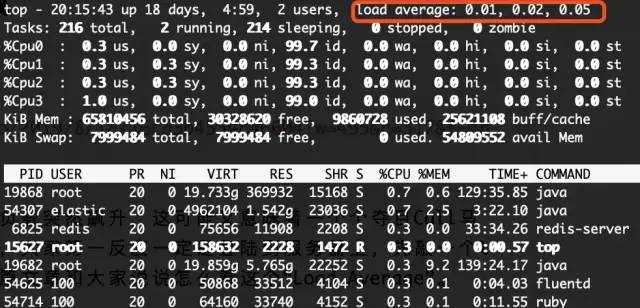
很多人说Load Average这一个指标就能说明系统负载高了,这句话是对的。那么具体是哪里压力大了呢?这三个数值是怎么计算出来的呢?可能很多人一下子都说不上来。
先来说说定义吧:在一段时间内,CPU正在处理以及等待CPU处理的进程数之和。三个数字分别代表了1分钟,5分钟,15分钟的统计值。
所以,这个数值的确能反应服务器的负载情况。但是,这个数值高了也并不能直接代表这台机器的性能有问题。可能是因为正在进行CPU密集型的计算,也有可能是因为I/O问题导致运行队列堵了。所以,当我们看到这个数值飙升的时候,还得具体问题具体分析。直接升级机器是简单粗暴,但是治标不治本。
top命令一行一行看
top命令输出了很多参数,真正的服务器负载情况我们要综合其他参数一起看。
第一行:top - 20:41:08 up 18 days, 5:24, 2 users, load average: 0.04, 0.03, 0.05top:当前时间up:机器运行了多少时间users:当前有多少用户load average:分别是过去1分钟,5分钟,15分钟的负载
具体需要关注的果然还是load average这三个数值。大家都知道,一个CPU在一个时间片里面只能运行一个进程,CPU核数的多少直接影响到这台机器在同时间能运行的进程数。所以一般来说Load Average的数值别超过这台机器的总核数,就基本没啥问题。
第二行:Tasks: 216 total, 1 running, 215 sleeping, 0 stopped, 0 zombieTasks:当前有多少进程running:正在运行的进程sleeping:正在休眠的进程stopped:停止的进程zombie:僵尸进程
第三行:%Cpu(s): 0.2 us, 0.1 sy, 0.0 ni, 99.8 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 stus: 用户进程占CPU的使用率sy: 系统进程占CPU的使用率ni: 用户进程空间改变过优先级id: 空闲CPU占用率wa: 等待输入输出的CPU时间百分比hi: 硬件的中断请求si: 软件的中断请求st: steal time
这一行代表了CPU的使用情况,us长期过高,表明用户进程占用了大量的CPU时间。us+sy如果长期超过80或者90,可能就代表了CPU性能不足,需要加CPU了。
第四行&第五行KiB Mem : 65810456 total, 30324416 free, 9862224 used, 25623816 buff/cacheKiB Swap: 7999484 total, 7999484 free, 0 used. 54807988 avail Memtotal:内存总量free:空闲内存used:使用的buffer/cache:写缓存/读缓存
第五行往下PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND19868 root 20 0 19.733g 369980 15180 S 0.7 0.6 129:53.91 java19682 root 20 0 19.859g 5.766g 22252 S 0.3 9.2 139:42.81 java54625 100 20 0 50868 33512 4104 S 0.3 0.1 0:04.68 fluentdPID:进程idUSER:进程所有者PR:优先级。数值越大优先级越高NI:nice值,负值表示高优先级,正值表示低优先级VIRT:进程使用的虚拟内存总量SWAP:进程使用的虚拟内存中被换出的大小RES:进程使用的、未被换出的物理内存大小SHR:共享内存大小SHR:共享内存大小S:进程状态。D表示不可中断的睡眠状态;R表示运行;S表示睡眠;T表示跟踪/停止;Z表示僵尸进程。%CPU:上次更新到现在的CPU占用百分比 ;%MEM:进程使用的物理内存百分比 ;TIME+:进程使用的CPU时间总计,单位1/100秒;COMMAND:命令名/命令行
这些就是进程信息了,从这里可以看到哪些进程占用系统资源的概况。
其他命令
top当然是我们最常见的查看系统状况的命令。其他命令还有很多。vmstat,w,uptime ,iostat这些都是常用的命令。
综上
看懂这些具体参数以后,就知道自己的代码到底哪方面需要改进了,是优化内存消耗,还是优化你的代码逻辑,当然无脑堆机器也可以,只要你说服的了老板!

评论