
基于线程池的线上服务性能优化
你好,我是雨乐!
最近居家办公。正在发愁摸哪条鱼的时候,产品突然在群里at了我一下,说到某某订单曝光异常,让配合看看。
仔细询问了下订单信息,乖乖,原来用的是6年前开发的一个功能,要知道这个功能自上线后基本很少用,不知道为什么现在开始用起来了,只能先放弃摸鱼,先配合解决问题,毕竟要靠这个来吃饭的。
需求背景
在广告中,经常有这样一种需求场景,需要将某个广告定向投放给某一批指定用户。即假设有一个adid,指定了投放用户1和用户2,那么只有在用户1和用户2的流量请求过来的时候,才会返回给adid,而其他用户的流量,均不会返回该adid。
一般情况下,指定用户多达几百万个甚至上千万个,将这些用户ID直接随着广告订单推送过来,显然不切实际,所以当时的设计方案是广告主将包含有指定用户ID的数据包上传到广告后台,然后生成一个url,而该url则随着广告订单推送过来。在引擎中,有个服务专门订阅了广告订单消息,如果发现该广告订单是指定用户投放,则将url指向的数据包中的数据获取后,进行实时加载,这样当其用户ID流量过来的时候,就能匹配上该广告。

初始设计
在开始本节之前,我们不妨先思考几分钟,如果让你来实现这个功能,该如何实现呢?

好了,让我们把时间调回到2016年年底,产品提出该需求的时间点。
当时看了该需求,还是蛮简单的。为了便于内容理解,将加载定向包的服务称之为Retargeting。
Retargeting服务就两个基本功能:
订阅广告订单消息队列 如果获取到了有定向包的广告订单,则下载该定向包,然后获取里面的数据,建立倒排索引
是不是很简单,代码也非常好写,下载定向包可以使用libcurl,也可以使用wget进行下载然后读取文件加载到内存,当时因为排期比较紧张,所以选择了wget方式来实现,因为数据量比较大,所以使用redis作为倒排索引的存储媒介。
假设有一个广告订单我们称之为ad,其包含一个定向包地址url,此时会做如下几件事:
1、使用如下命令进行下载url所指向的定向包
auto cmd = "wget -t 3 -c -r -nd -P /data1/data/ –delete-after -np -A .txt http://url.txt";
auto fp = popen(cmd.str().c_str(), "r");
if (!fp) {
return;
}
2、以文件形式打开该包
// 获取本地包地址,如/data1/data/url.txt
fp = fopen(path.c_str(), "r");
std::string id;
char buf[128] = {'\0'};
while (fgets(buf, 128, fp)) {
id = buf;
boost::replace_all(id, " ", "");
boost::replace_all(id, "\r", "");
boost::replace_all(id, "\n", "");
noost::replace_all(id, "\^M", "");
if (!id.empty()) {
ids.emplace_back(id);
}
}
3、Redis中建立倒排索引
for (auto item : ids) {
redis_client_->SAdd(item, adid);
}
好了,到了此处,Retargeting服务功能已经基本都实现了。
在召回引擎中,当流量来了之后,会先以用户ID为key,从redis中获取指定投放该设备ID的adid,然后返回。
代码编译完后,在测试环境下了个单,推送,然后模拟请求,召回,完美。

问题初现
定向包功能,尤其是对于KA广告主,是不屑使用的,毕竟他们财大气粗,要的就是脑白金似的推广效果,即「只关注展示量,而不在乎是否有效果」。奈何随着国家政策的一步步调整,广告行业都开始勒紧裤腰带过日子,之前的大广告主也开始关注投放效果了,毕竟品效合一嘛。于是,他们开始挖掘了一批用户,在后台开始投放,尝试投放效果。随着此类定向包订单越来越多,之前实现的Retargeting也开始出现瓶颈了。。。
毕竟该功能使用不多,所以大部分情况下,产品或者运营提出问题的时候,都会找个借口搪塞回去。直到某一天,产品直接甩出来一张图,说某个部门老大非常看重的一个广告主的定向包投放曝光为0,并扬言当天解决不了,就通过其它渠道进行投放。。。
既然是部门老大都找过来了,那就不得不找下原因了,于是从订单的url是否有效开始查起,定向包设备的有效覆盖率,一直到整个订单的推送时间,一切都正常,看来问题出在ReTargeting服务了,服务正常,加载也正常,无意间看了下消费进度,不看不知道,一看吓一跳。才刚刚消费到昨天的订单,也就是说当天要投放的订单还没开始加载,怪不得还没有曝光,就这进度,有曝光才怪。
顺便看了眼服务状态,乖乖,CPU占用这么低。。。

尝试优化
既然CPU占用这么低,那么有没有可能从CPU占用这个角度进行优化呢,提升CPU占用,提高服务处理能力,这样就能加快其加载速度了。对于这种,一般稍微有点经验的,就会知道该怎么优化,对,就是使用多线程。
既然决定使用多线程,那么就得彻底点,多线程处理订单,在每个订单中,又采用多线程进行数据加载和处理,我们暂且称之为M*N多线程设计模型,如下:
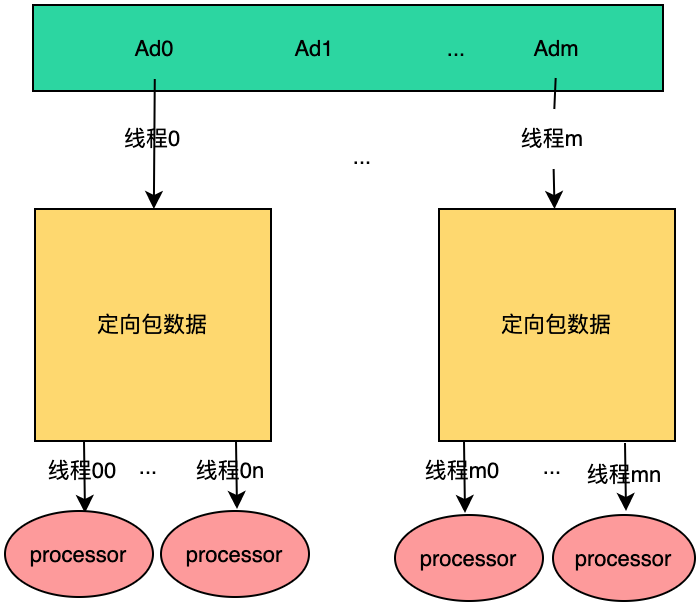
在上图中,采用多线程方式对Retargeting服务进行优化,假设此时有m个定向包订单,则会同时有m个线程进行处理,每个线程处理一个定向包订单,看起来很完美,等等,会不会有其他问题呢?要不然一开始为什么就不这么设计呢?
大家知道,对于多线程程序,「线程的执行顺序,完成时间是不可控的」,使用上述设计方案,如果多个线程「同时处理多个不同的订单,那么是没有任何问题的」,但是,如果对于另外一种场景,该方案就不可行了,如下:
假设此时销售创建了一个定向包订单ad0,先推送上线。然后发现订单有问题,所以随即推送下线。那么此时消息队列中有两条消息,先是ad0的上线消息,然后是ad0的下线消息。基于上述多线程设计模型,假设线程1执行订单上线,线程2执行订单下线,可能的结果就有如下几种:
先执行上线订单加载,再执行下线订单加载,此种情况符合预期 下线订单先完成,然后上线订单完成,此种情况最终与我们期望的相反 上线订单和下线订单同时执行,且中间交叉进行,结果不可控
很明显,该种方案不可行,尽管其最大可能地优化了性能,但是得不到正确的结果,即使性能再好,又有啥用呢?
难道多线程设计模型真的不适用于我们这个服务吗?
不妨调整下思路,在上述的方案分析中,多个线程同时处理多个订单就会有问题,换句话说在M*N多线程设计模型中,正是因为M>1导致了结果不可预期,那么如果M=1呢?这样会不会就会避免上述问题呢?
我们仍然以上述案例进行举例,因为是单线程处理消息队列,那么永远都是先处理上线消息,然后再处理下线消息,这样的结果永远符合我们的预期。
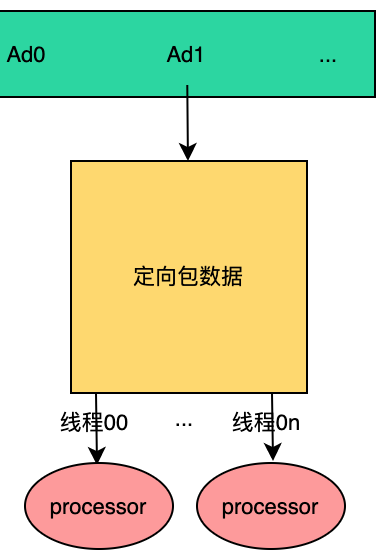
既然方案已经定了,那么就可以直接写代码了。在该方案中,我们用到了多线程进行处理,如果每次来了订单消息都创建多个线程进行处理,处理完成后,销毁线程。虽然也可以这么做,但多少对性能有所影响,所以干脆使用线程池来完成吧。base库中有之前手撸的线程池,直接拿来使用。
for (auto did : ids) {
thread_pool.enqueue([did, adid, this]{
RedisClient client;
redis_client_pool_.Pop(&client);
if (client) {
client->SAdd(did, adid);
redis_client_pool_.Push(client);
}
});
}
}
编译、部署、测试,一气呵成,没问题。开始上线,上线完成,看了下CPU利用率,完美:

数据说话,对比下优化前后同一个订单的处理时间:
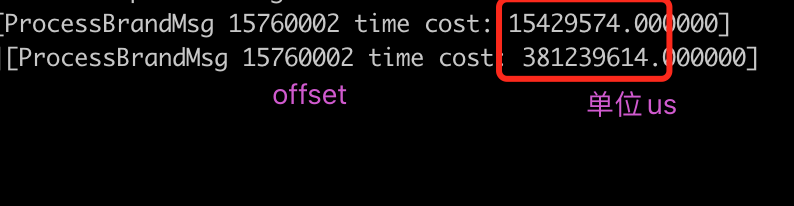
性能提升接近30倍,符合预期。。。
结语
需求,总是自我技术提升,架构升级优化的动力源。有时候,一个简单的小优化,就能达到事半功倍的效果。
最近在跟某友提到此事的时候,对方随即来了一句祖传屎山,只能跟其解释,这是6年前自己造的,含着泪也要进行优化,哈哈哈哈。
好了,今天的文章就到这,我们下期见!
如果对本文有疑问可以加笔者微信直接交流,笔者也建了C/C++相关的技术群,有兴趣的可以联系笔者加群。