
Hudi 剖析 | Apache Hudi 内核之文件标记机制深入解析
1. 摘要
Hudi 支持在写入时自动清理未成功提交的数据。Apache Hudi 在写入时引入标记机制来有效跟踪写入存储的数据文件。在本博客中,我们将深入探讨现有直接标记文件机制的设计,并解释了其在云存储(如 AWS S3、Aliyun OSS)上针对非常大批量写入的性能问题。并且演示如何通过引入基于时间轴服务器的标记来提高写入性能。
2. 为何引入Markers机制
Hudi中的marker是一个表示存储中存在对应的数据文件的标签,Hudi使用它在故障和回滚场景中自动清理未提交的数据。
每个标记条目由三部分组成
•数据文件名•标记扩展名 (.marker)•创建文件的 I/O 操作(CREATE - 插入、MERGE - 更新/删除或 APPEND - 两者之一)。
例如标记91245ce3-bb82-4f9f-969e-343364159174-0_140-579-0_20210820173605.parquet.marker.CREATE指示相应的数据文件是91245ce3-bb82-4f9f-969e-343364159174-0_140-579-0_20210820173605.parquet 并且 I/O 类型是 CREATE。
在写入每个数据文件之前,Hudi 写入客户端首先在存储中创建一个标记,该标记会被持久化,在提交成功后会被写入客户端显式删除。
标记对于写客户端有效地执行不同的操作很有用,标记主要有如下两个作用
•删除重复/部分数据文件:通过 Spark 写入 Hudi 时会有多个 Executor 进行并发写入。一个 Executor 可能失败,留下部分数据文件写入,在这种情况下 Spark 会重试 Task ,当启用speculative execution时,可以有多次attempts成功将相同的数据写入不同的文件,但最终只有一次attempt会交给 Spark Driver程序进程进行提交。标记有助于有效识别写入的部分数据文件,其中包含与后来成功写入的数据文件相比的重复数据,并在写入和提交完成之前清理这些重复的数据文件。•回滚失败的提交:写入时可能在中间失败,留下部分写入的数据文件。在这种情况下,标记条目会在提交失败时保留在存储中。在接下来的写操作中,写客户端首先回滚失败的提交,通过标记识别这些提交中写入的数据文件并删除它们。
接下来我们将深入研究现有的标记机制,阐述其性能问题,并演示新的基于时间轴服务器的标记机制来解决该问题。
3. 现有的直接标记机制及其局限性
现有的标记机制简单地创建与每个数据文件相对应的新标记文件,标记文件名如前面所述。每个 marker 文件被写入在相同的目录层次结构中,即提交即时和分区路径,在Hudi表的基本路径下的临时文件夹.hoodie/.temp下。例如,下图显示了向 Hudi 表写入数据时创建的标记文件和相应数据文件的示例。在获取或删除所有marker文件路径时,该机制首先列出临时文件夹.hoodie/.temp/<commit_instant>下的所有路径,然后进行操作。
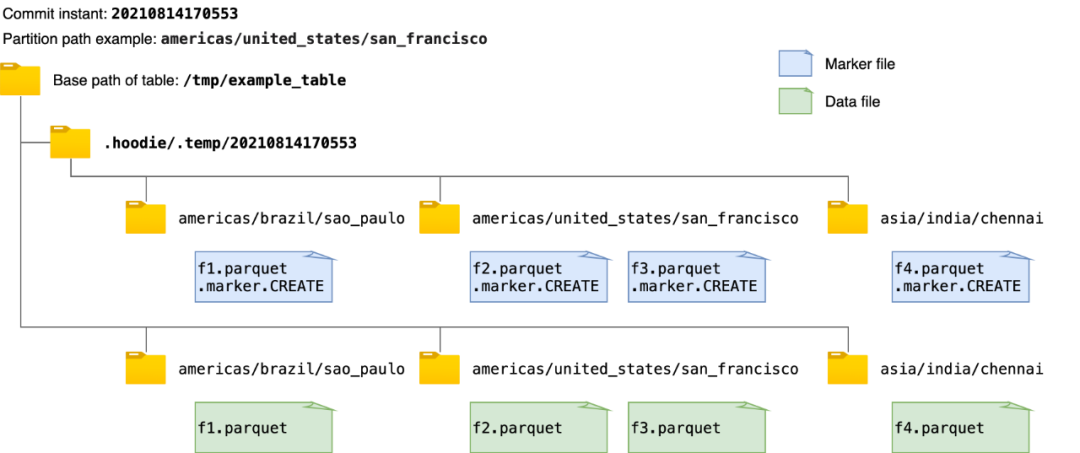
虽然扫描整个表以查找未提交的数据文件效率更高,但随着要写入的数据文件数量的增加,要创建的标记文件的数量也会增加。这可能会为 AWS S3 等云存储带来性能瓶颈。在 AWS S3 中,每个文件创建和删除调用都会触发一个 HTTP 请求,并且对存储桶中每个前缀每秒可以处理的请求数有速率限制。当并发写入的数据文件数量和 marker 文件数量巨大时,marker 文件的操作会成为写入性能的显着性能瓶颈。而在像 HDFS 这样的存储上,用户可能几乎不会注意到这一点,其中文件系统元数据被有效地缓存在内存中。
4. 基于时间线服务器的标记机制提高写入性能
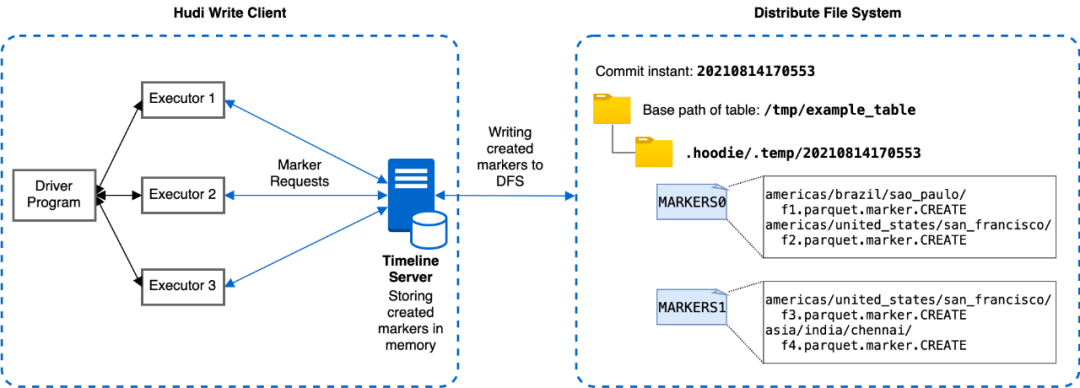
为解决上述 AWS S3 速率限制导致的性能瓶颈,我们引入了一种利用时间线服务器的新标记机制,该机制优化了存储标记的相关延迟。Hudi 中的时间线服务器用作提供文件系统和时间线视图。如下图所示,新的基于时间线服务器的标记机制将标记创建和其他标记相关操作从各个执行器委托给时间线服务器进行集中处理。时间线服务器在内存中为相应的标记请求维护创建的标记,时间线服务器通过定期将内存标记刷新到存储中有限数量的底层文件来实现一致性。通过这种方式,即使数据文件数量庞大,也可以显着减少与标记相关的实际文件操作次数和延迟,从而提高写入性能。
为了提高处理标记创建请求的效率,我们设计了在时间线服务器上批量处理标记请求。每个标记创建请求在 Javalin 时间线服务器中异步处理,并在处理前排队。对于每个批处理间隔,例如 20 毫秒,调度线程从队列中拉出待处理的请求并将它们发送到工作线程进行处理。每个工作线程处理标记创建请求,并通过重写存储标记的底层文件。有多个工作线程并发运行,考虑到文件覆盖的时间比批处理时间长,每个工作线程写入一个不被其他线程触及的独占文件以保证一致性和正确性。批处理间隔和工作线程数都可以通过写入选项进行配置。
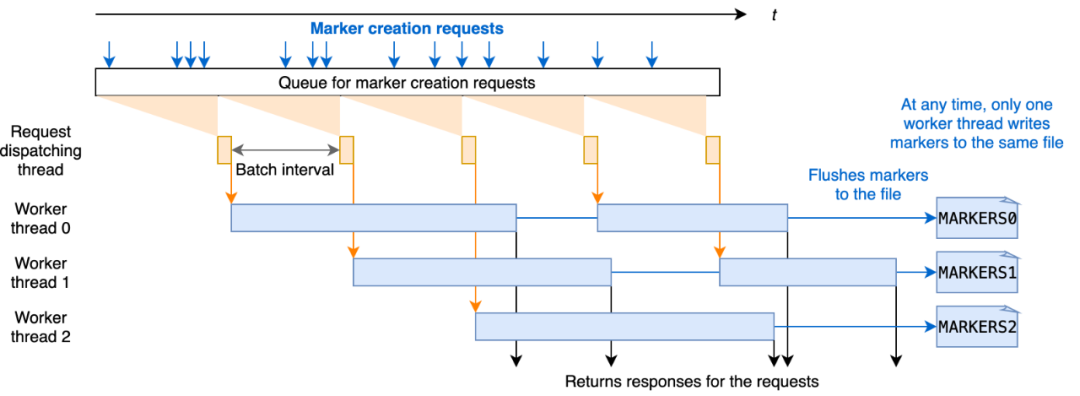
请注意工作线程始终通过将请求中的标记名称与时间线服务器上维护的所有标记的内存副本进行比较来检查标记是否已经创建。存储标记的底层文件仅在第一个标记请求(延迟加载)时读取。请求的响应只有在新标记刷新到文件后才会返回,以便在时间线服务器故障的情况下,时间线服务器可以恢复已经创建的标记。这些确保存储和内存中副本之间的一致性,并提高处理标记请求的性能。
5. 标记相关的写入选项
我们在 0.9.0 版本中引入了以下与标记相关的新写入选项,以配置标记机制。
•hoodie.write.markers.type,要使用的标记类型。支持两种模式: direct,每个数据文件对应的单独标记文件由编写器直接创建; timeline_server_based,标记操作全部在时间线服务中处理作为代理。为了提高效率新的标记条目被批处理并存储在有限数量的基础文件中。默认值为direct。•hoodie.markers.timeline_server_based.batch.num_threads,用于在时间轴服务器上批处理标记创建请求的线程数。默认值为20。•hoodie.markers.timeline_server_based.batch.interval_ms,标记创建批处理的批处理间隔(以毫秒为单位)。默认值为50。
6. 性能
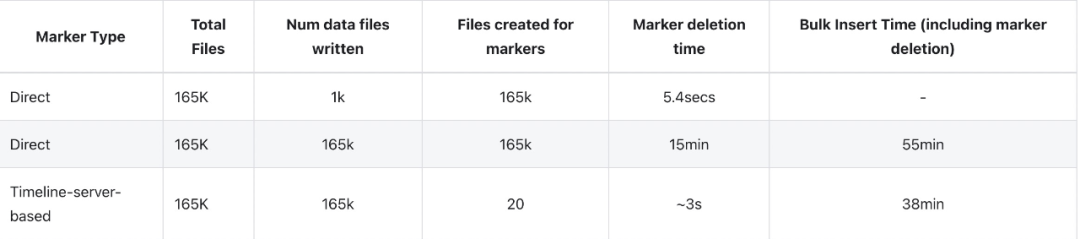
我们通过使用 Amazon EMR 和 Spark 和 S3 批量插入大规模数据集来评估direct和timeline_server_based的标记机制的写入性能。输入数据大约为 100GB。我们通过设置最大 parquet 文件大小为 1MB 和并行度为 240 来配置写入操作以并发生成大量数据文件。正如我们之前提到的,而直接标记机制的延迟对于较小数量的增量写入是可以接受的,对于产生更多数据文件的大批量插入/写入,开销会急剧增加。
如下图所示,由于是批处理,基于时间线服务器的标记机制生成的存储标记的文件要少得多,从而导致标记相关的 I/O 操作的时间要少得多,因此与直接相比,写入完成时间减少了 31%。标记文件机制。
7. 总结
我们发现由于 AWS S3 等云存储上文件创建和删除调用的速率限制,现有的直接标记文件机制会导致性能瓶颈。为了解决这个问题我们引入了一种利用时间线服务器的新标记机制,它将标记创建和其他与标记相关的操作从各个 Executor 委托给时间线服务器,并使用批处理来提高性能。使用 Spark 和 S3 在 Amazon EMR 上进行的性能评估表明,与标记相关的 I/O 延迟和整体写入时间有所减少。
推荐阅读
Apache Hudi 0.9.0版本重磅发布!更强大的流式数据湖平台
Apache Hudi数据不知道怎么删除?多种方式快来Get!