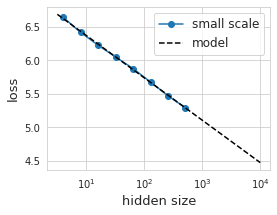
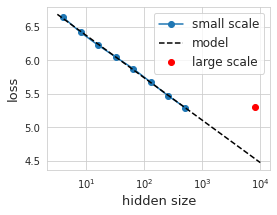
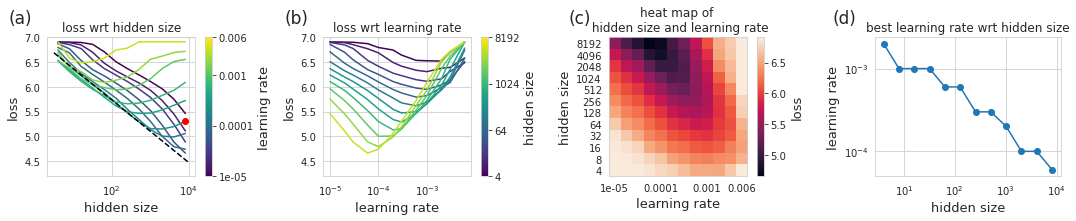
模型大十倍,性能提升几倍?谷歌研究员进行了一番研究视学算法关注共 2849字,需浏览 6分钟 ·2022-02-11 23:19 选自lukemetz.blog作者:Luke Metz机器之心编译编辑:泽南搞大模型,大到一次训练要花几百万刀买算力,没钱重训的那种,会不会花冤枉钱?随着深度学习模型的体量越来越大,进行任何形式的超参数调整都会变得非常昂贵,因为每次训练运行都可能要花费数百万美元。因此一些研究旨在探究「随着模型大小增加,性能提高程度」的规律。进行这种规律预测有助于让更小规模的研究拓展到更大更贵,但性能更高的环境。通过利用在多个模型大小上执行的小规模实验,人们可以找到简单的函数比例关系(通常是幂律关系),这些函数可以在花费训练所需的计算之前预测大型模型的性能。理论是美好的,实际上想这么做显然会遇到一些困难。如果不够谨慎,推断扩展性能可能会产生误导,导致公司投资数百万来训练一个性能不比小模型更好的模型。本文会通过一个示例来介绍这是如何发生的,以及发生这种情况的一种原因。作为研究扩展效应的示例,假设我们的目标是在具有 3 个隐藏层的宽得夸张的 MLP 中训练 ImageNet。我们要从 64、128 和 256 隐藏大小开始,并使用这些来选择超参数,在本例中为 Adam 找到了 3e-4 的学习率。我们还将训练的长度固定为 30k 权重更新,每 batch 有 128 张图像。接下来,我们就可以试图理解我们的模型是如何随着隐藏层大小而变化的了。我们可以训练各种大小的模型,并查看性能如何变化,绘制结果。具有不同隐藏层体量的 8 个不同模型的性能(以蓝色显示)。拟合出来的线性回归(黑色虚线)在理想情况下应该能够预测给定隐藏层大小的损失。你会发现,这数据看起来惊人地呈线性分布。太好了,我们找到了「规律」!我们可以用最小二乘法找到这种线性关系的系数:loss(hsize) = 7.0 - 0.275 log(hsize)。根据经验,这似乎在隐藏层大小上保持了两个数量级以上。漂亮的插值让人感到兴奋,我们认为我们可以将隐藏大小外推一个数量级以上来训练更大的模型。然而令人沮丧的是,我们发现实际情况下模型的性能大大偏离了预测曲线。较大模型(红色显示)实现的性能非常差,并且大大低于我们对较小规模模型(黑色虚线)的预测。在现实世界中,考虑到最近一段时间模型的体量,这样的差错可能会导致数千甚至上百万美元。在大于 100 亿的参数范围内,进行任何形式的实验来找出模型的错误几乎是不可能的。幸运的是,我们的示例工作规模很小,因此可以负担得起对实验进行详尽无遗的测试——在这种情况下,我们可以运行 12 个模型大小,每个模型具有 12 个不同的学习率(每个有 3 个随机初始化),共计 432 次试验。上图展示了我们使用 12 种不同的学习率训练 12 种不同模型大小的结果。每个小图用了不同的表示方法。在 (a) 中展示了不同隐藏层大小实现的损失,学习率以彩色显示——我们之前的推断是使用单一的学习率。在 (b) 中,我们展示了给定学习率的损失,其中隐藏层数量以颜色区分。较大的模型达到较低的损失,但需要较小的学习率。在 (c) 中,我们展示了显示学习率与隐藏层大小的热图,这里的每个像素都是完整训练运行的结果。在 (d) 中,我们查看给定隐藏层大小的最佳学习率。有了这些数据,故事就变得很清楚了,也就不足为奇了。随着我们增加模型大小,最佳学习率会缩小。我们还可以看到,如果我们简单地以较小的学习率进行训练,我们将在给定模型大小下接近我们最初预测的性能。我们甚至可以对最佳学习率和模型大小之间的关系进行建模,然后使用这个模型来提出另一种预测。最佳学习率与隐藏层大小 (d) 的关系图看起来是线性的,因此结合起来不会有太大的障碍。即使有了这样的修正,我们怎么知道这不是再次用一些其他超参数来实现的 trick,会在下一个隐藏大小的数量级上造成严重错误?学习率似乎很重要,但是学习率时间表呢?其他优化参数呢?架构决策呢?宽度和深度之间的关系如何?初始化呢?浮点数的精度(或缺乏)呢?在许多情况下,各种超参数的默认值和接受值都设置在相对较小的范围内——谁能说它们适用于更大的模型?随着训练大模型成为了学界业界的新潮流,模型体量扩展关系的问题似乎不断出现。即使是简单的事情,如使用此处所示的模型体量和学习率之比也并不总是能成功(例如为语言模型指定微调过程)。在这里值得记住的是讨论模型体量关系的论文《Scaling Laws for Neural Language Models》:https://arxiv.org/abs/2001.08361其讨论了很多问题如宽度、深度、体量、和 LR 之间的关系,还有 Batch size 大小的关系(https://arxiv.org/abs/1812.06162),但研究者也承认忽略了很多其他的问题。他们还讨论了计算量和数据大小的关系,但在这里我们不讨论或进行改变。他们提出的缩放定律是在假设基础模型是用性能最好的超参数训练的假设下设计的。所以对于潜在的误导性推断,我们能做些什么呢?在理想的情况下,我们将充分了解模型的各个方面如何随比例变化,并利用这种理解来设计更大尺度的模型。没有这一点,外推似乎令人担忧,并可能导致代价高昂的错误。然而,考虑到有多少因素在起作用,要达到完全理解这一点是不可能的。考虑到计算成本,在每个尺度上调整每个参数看来并不是正确的解决方案。那该怎么办?一种潜在的解决方式是使用缩放定律来预测性能极限。随着规模的扩大,如果性能偏离幂律关系,人们应该将其视为未正确调整或设置好的信号。听说这是 OpenAI 经常使用的思路。换句话说,当扩展没有按预期工作时,这可能意味着正在发生一些有趣的事情。知道该怎么做,或者要调整哪些参数来修复这种性能下降可能极具挑战性。在我看来,必须平衡使用缩放定律来推断更大范围的性能,并实际评估性能。从某种意义上来说,这是显而易见的,它们只实践中所做工作的粗略近似。随着模型尺度研究的发展,我们希望这种平衡可以更加明确,并且可以更多地利用缩放关系来实现更多的小规模研究。以这个特定的例子为例,虽然我们发现用固定的学习率进行简单的性能预测并不能外推,但我们确实发现了模型大小和学习率之间的线性关系,这导致模型可以在测试的模型大小范围内进行推测。如果我们尝试推断更大的模型,是否还有其他一些我们遗漏的因素呢?这是有可能的,不运行实验很难知道。原文链接:http://lukemetz.com/difficulty-of-extrapolation-nn-scaling/© THE END 转载请联系视学算法公众号获得授权投稿或寻求报道:content@jiqizhixin.com 浏览 37点赞 评论 收藏 分享 手机扫一扫分享分享 举报 评论图片表情视频评价全部评论推荐 性能提升,星辰AI大模型TeleChat-12B评测GiantPandaCV0挑选有用样本,提升模型整体性能!NLP从入门到放弃0如何利用多任务学习提升模型性能?NLP从入门到放弃0LLM性能最高60%提升!谷歌ICLR 2024力作:让大语言模型学会「图的语言」 新智元报道 编辑:Mindy【新智元导读】图是组织信息的一种有用方式,但LLMs主要是在常规文本上训练的。谷歌团队找到一种将图转换为LLMs可以理解的格式的方法,显著提高LLMs在图形问题上超过60%的准确性。在计算机科学领域,图形结构由节点(代表实体)如何用 IDEA 提升十倍开发效率?Hollis0只需一行CSS代码,让长列表网页的渲染性能提升几倍以上!前端技术江湖0Zend OpcachePHP 性能提升ZendOpcache前身是ZendOptimizer+,在03年改名Opcache,通过opcode缓存和优化提供更快的PHP执行过程。他会将预编译后的php文件存储在共享内存中以供以后的使用,避免Pyshippython 性能提升工具Pyship用于打包python2.7的执行文件,使其运行性能能有和原生程序一样的体验。使用条件:安装ActiveStateTcl/Tk8.5安装XcodeSDKsudoln-s/usr/bin/clPyshippython 性能提升工具Pyship 用于打包python 2.7的执行文件,使其运行性能能有和原生程序一样的体验。使用条件Zend OpcachePHP 性能提升Zend Opcache 前身是Zend Optimizer +,在03年改名Opcache,通过o点赞 评论 收藏 分享 手机扫一扫分享分享 举报
 下载APP
下载APP