BERT为何无法彻底干掉BM25??

大数据文摘授权转载自夕小瑶的卖萌屋
作者:QvQ
近些年来,相比传统检索模型,大规模预训练式transformers结构的引入在各类任务上都有显著的提升。而这种提升在不同的数据集上有着特殊的模型设置,而当前依旧无法充分理解这些模型为什么以及如何可以更好的工作。
古人云:知己知彼,方能百战不殆。而现在的NN模型尚不能做到知己,又怎么进行下一步的升级迭代呢?今天让我们来看一下信息检索任务上,基于Bert的交叉编码器相比传统的BM25排序算法的异同有哪些呢?
How Different are Pre-trained Transformers
for Text Ranking?
https://arxiv.org/abs/2204.07233
热身一下
与传统的基于词的方法(如BM25或Query-Likelihood)相比,神经信息检索最近经历了令人印象深刻的性能提升。
由于诸如BERT这类模型具有大量参数,所以它能处理具有长范围依赖和复杂的句子结构。
当将BERT应用于排序时,它可以在query和doc之间构建深度交互,从而允许揭示复杂的关联模式,而不仅仅是简单的term匹配。
到目前为止,BERT交叉编码器所取得的巨大性能增益并没有被很好地解释。
我们对BERT模型到底是基于何种特征来用于计算句子相关性的匹配原则以及使用该模型的排序结果与BM25等传统稀疏排序算法的关系知之甚少。
BERT通过query和doc之间的术语交互直接捕获相关性信号,本文对BERT的交叉编码器(Cross-Encode,下文简称CE)与BM25的排序算法有何联系做一些研究。
首先提出以下几个问题:
RQ1: CE和BM25到底有和不同?
RQ1.2: CE是否对BM25检索到的相同结果进行了更好的排序?
RQ1.3: CE能更好地召回被BM25遗漏的结果吗?
其次,分别量化精确匹配和软匹配对整体效果的贡献,因为它们构成了传统稀疏检索和神经检索匹配范式之间最直接的对比。更具体地说,需要明确以下问题:
RQ2: CE是否能体现term完全匹配?
RQ3: CE能找到“不可能相关”的结果吗?
实验
1.实验配置
用BERT的CE对包含n个term的query和包含m个term的doc同时编码:
其中[CLS]会送入二进制分类器层以将文章分类为相关或非相关,然后将相关性概率用作相关性得分,重新排序的文章。

在MS-MARCO数据集上实验了TREC 2020 Deep Learning Track的文章召回任务,实验结果如上表。可以看到CE在所有指标上都优于BM25。
2.实验结论
RQ1: CE和BM25的排序结果有何不同?
为了探寻CE对最终排序结果的影响,作者记录了每个doc最初在BM25排序算法中的位置。并将排序分成四个不同范围:1-10, 11-100, 101-500, 501-1000(下文会用10, 100, 500和1000表示)。
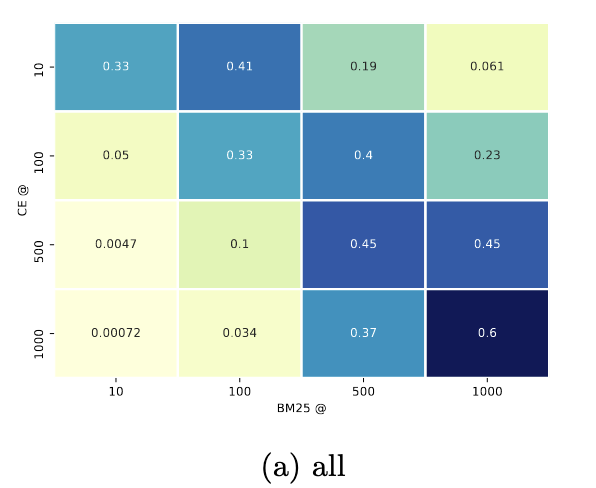
上图反应了CE和BM25排序结果的差异性。每个单元格表示同一范围内来分别来自CE和BM25文档的比例,举个栗子:(a)图第一行表示CE重新排名的第1-10位的文件来自最初BM25排名中第1-10位的33%,第11-100位的41%,第101-500位的19%和第501-1000位的6.1%。可以发现:
(1)CE和BM25在排序在top结果中有着很大的差异 (33% CE@10),即仅有33%的结果相同;而在低分段(60% CE@1000)则相反。
(2)BM25排名靠前的doc很少被CE排序靠后,而被BM25排序较后的doc则有20%的概率排在CE的top10里。这表明精确匹配是一个重要的基础排序策略,而CE的软匹配能力是BM25所不具备的。
RQ1.2: CE是否对BM25检索到的相同结果进行了更好的排序?
为了回答这个问题,作者将根据NIST 2020的判定指标将候选结果分为【高度相关】、【相关】和【不相关】三类文档。
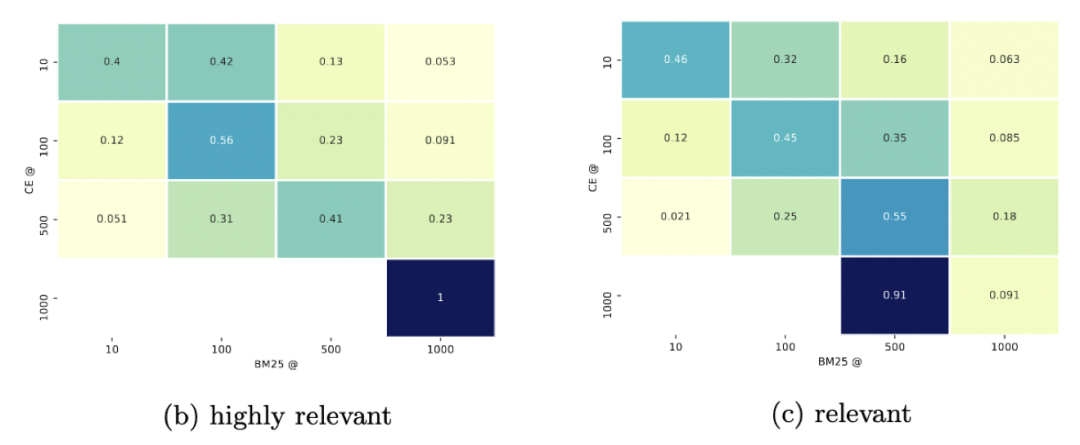
对于【高度相关】的文档,排序结果在CE@10中表现出较低的一致性(40%),这意味着两种方法对于各自头部文档相关性的定义有着很大的不同。
对于【相关】的文档,可以观察到CE和BM25在头部排序范围内有46%的重叠部分,另外占比较大的部分(32%)来自BM25@100。即对于CE的头部相关文档而言,仍然有22%排在BM25算法的100位以后,这说明BM25还是明显低估了许多文档的相关性。
而这也并不意味着BM25算法被完爆,对于【高度相关】文档而言,同样有17%(E@100: 12% + CE@500: 5%)的文档,被CE排在较靠后的位置,而这些文档位于BM25排序算法的top10,该结论在【相关】文档的统计中也有体现。
令人意外的是,对于部分【高度相关】文档,CE和BM25都将其排序较后(@1000),且重合度竟达到的完美的100%,说明这两类算法都不具备对此类文档的识别能力。

那么,对于那些【不相关】而又排序靠前的文档,两种算法又表现如何呢?
可以看到了CE@10里,大量【不相关】文档来自BM25排序中较后的位置(47% BM25@100, 23% BM25@500, 5% BM@1000),这表明CE高估了许多被BM25算法正确地认为【不相关】文档的相关性。(好家伙,你堂堂1亿参数的BERT也有看走眼的时候?)
RQ1.3: CE能更好地召回被BM25遗漏的结果吗?
重点关注CE的前10个排序结果可以更准确的掌握对于头部结果的召回情况。
如(b)图中所示:对于CE召回的前十条【高度相关】结果,其中有将近一半(42%)只能排在BM25算法的10-100位,13%的【高度相关】只能排在BM25算法的100-500位,甚至还有5%的【高度相关】排在BM25算法的500-1000位。
相同的结论同样可以在【相关】结果集中体现。
这证明了CE的卓越能力,它可以召回BM25非常不看好而实际却是高度相关的文档。这也正是神经模型相比传统稀疏匹配算法的真正潜力所在。
RQ2: CE是否能体现term完全匹配?
文档中查询词的存在与否是排序相关性的最强信号之一,作者通过从doc中剥离出精确匹配所需要的term,从而量化term完全匹配对效果的贡献。
具体做法是将doc中所有的非query term都改用[MASK]标记替换,使模型仅保留原始文档的框架,从而迫使CE仅依赖query和doc之间的精准term匹配:

可以看到表中第一行【Only Q】的指标,其实还是很出人意料的,该排序指标甚至全面低于BM25算法,这也说明了CE其实并没有对精确term匹配有一个充分的利用。(笔者感觉这里也不能完全说明这个结论,因为作者并没有对原模型重新fine-tune,过多的[MASK]token可能会影响模型的判断)
RQ3: CE能找到“不可能相关”的结果吗?
虽然CE可以同时利用精确term匹配和语义匹配,但与传统term级匹配算法相比,其最大的优势在于通过考虑上下文信息克服对term匹配的依赖,即语义泛化能力。
不是通过term精确匹配的方法我们称之为“软匹配”,神经网络模型正是基于这种软匹配可以召回传统方法无法召回的doc。
同样为了剥离和量化软匹配的效果,通过mask掉doc中所有与query相同的term,仅保留上下文环境,观察效果的变化。
如上标中的【Drop Q】所示,CE可以做到在doc完全没有与query有重叠term的情况下也能对文档进行较为合理的评分,排序结果甚至要优于BM25算法!!!
这即在意料之外,其实也在情理之中。毕竟CE有着其自带的MLM任务,如果可以,它甚至可以预测出被mask的term(那么你删不删对它有什么影响呢?)。
当然仅依靠上下文就能做到比传统的BM25算法要优秀,这一点也算是意料之外的。这也证明了CE做到了“语义理解”,展现了其强大的泛化潜力。
一些思考
根据以上实验对比,可以得到一些比较有意思的结论:
(1)对于两种算法来讲,排名靠前的doc的差异性要更大且越是【高度相关】的文档这种差异性越大,而排名靠后的doc则具有更强的一致性。(真是幸福各有千秋,而不幸如出一辙= =)
(2)对于实验结果中DCG的涨点,可以看出CE的主要提升是召回了被BM25低估的doc(即召回的显著提升)。同时也引入了一些误差,即CE高估了一些原本被BM25排序正确的低相关性doc。
(3)一些被CE大大低估的【高度相关】的doc,反而BM25的排序更加准确。但是很遗憾,作者并没有给出具体的case示例,如果想进一步提高NN模型的性能,其实是应该更多的关注这一批case的。
最后,在检索任务中,现在仍没有实验表明NN模型可以完全替代传统基于term的稀疏匹配算法。不管是召回还是排序阶段,这两者依旧是相辅相成的关系。
而真正需要思考的是如何balance这两者的排序结果,以及为什么百亿参数的模型在部分case上依旧不如传统term匹配算法。
搜索之路,道阻且长啊~