
从提高 Elasticsearch 搜索体验说开去......
1、实战问题
球友提问:怎么搜索才能使得结果是最好的呢?
我这边一个搜索功能,实现做法就是将用ik分词器配合multi查询实现的。
中途也追加了客户所在领域相关词汇字典。
但是客户一直反馈搜索体验不好。
如果想要提高搜索体验还能从那些方面入手呢?
来自:死磕 Elasticsearch 知识星球
这个问题非常有代表性,我在实际产品开发中也遇到过。
2、从几个例子说搜索体验
示例一:“慕X网”输入“触发器”的搜索截图。

注意:我输入的是“触发器”,返回结果第一条没有问题,其他几条有关:“触”、“发”的,可以说和我的搜索没有关系。
站在用户体验的角度,我认为:体验很差,返回了很多不相关的数据。
示例二:某题库APP,不支持跳转翻页。
如下所示,题库共1703题,包含:判断题、选择题。
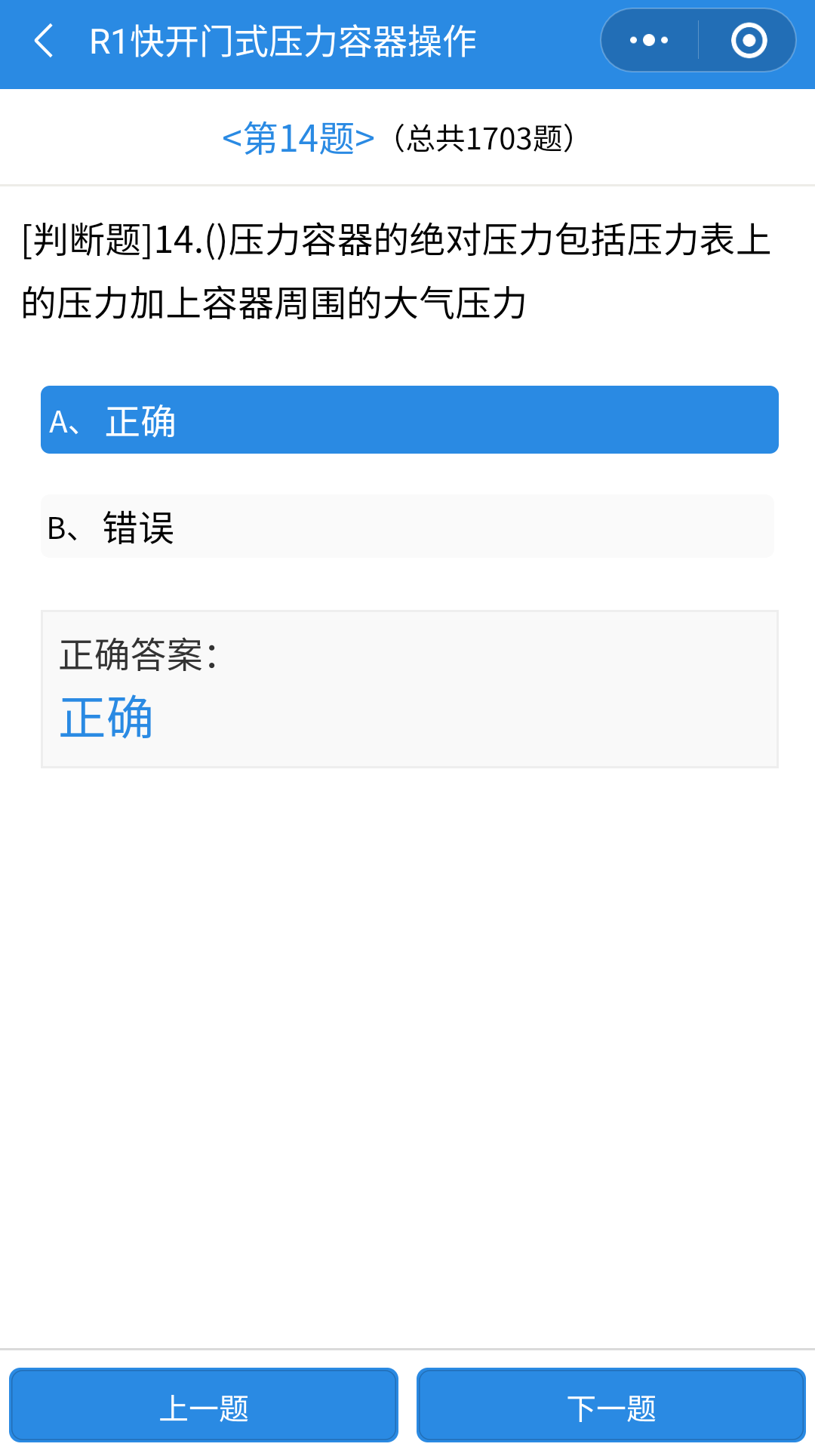
只支持:点击:上一题、下一题。
实际场景:
当做了100道、200道的时候,只有选择题;到底多少选择题? 当退出后,需要点击几百下进入自己上次做到的最后一道题.....
这不是用户体验差,这是没有用户体验,开发者完全没有动脑子的设计,用户会"怀疑人生"。

示例三:电商搜索“秋天第一条秋裤”,该返回什么?

放大查看图片,亮点自现
这是个见仁见智的问题,究竟返回什么,各个电商公司都有自己的评判。
但,单纯站在用户的角度,高下立判。
铭毅一句话点评:
拼多多
“活该你发展快”,的确返回结果就是预期结果,且友好的推荐了所在地域的“秋裤”信息。
淘宝
中规中矩,至少能返回“秋裤”。
京东
没有找到商品,为你推荐“秋裤”,“干嘛推荐,直接返回不就完了”。
当当
好家伙!推荐的都是“秋天”的商品。你是用户,你咋想?
“尼玛,什么玩意?” “五味杂陈” “不知所云”
......
基本上可以得出结论:公司发展速度和搜索体验成正比。
3、有数据的地方,就有搜索
信息泛滥和爆炸的今天,搜索无处不在。基本可以形象的概括为:“有数据的地方,就有搜索“。
搜索可能是用户最常用到的功能之一,学习、工作、衣食住行等各个环节都离不开搜索。
学习
输入关键词,搜索靠谱的免费或付费网络资源。
工作
遇到错误码,通过Google 搜索获得答案。
搜索微信聊天记录,看看之前都聊的某个关键有价值信息。
衣
网上购买衣服,实际就是搜索、选择的过程。
食
日常中午订外卖,选择外卖的过程,就是搜索的过程,离公司近+评价高=下单几率大。
住
出差订酒店,搜一下,对比选择个性价比高的。
行
十一自驾游,出行前高德导航,输入目的地搜索结果,根据返回结果,选择合适路线。
正如:搜索体验的分析文章指出:“搜索框的设计及其可用性问题其实是一个不容忽视的要点。
一个好的搜索体验也许并不能让用户对你的产品产生特别的好感,但是一个不好的搜索体验却能给你的产品带来致命的打击。
所以无论是为了给用户提供更好的服务,还是避免用户产生消极的体验感受,做好搜索的体验对一个内容型产品来说都是至关重要的。“
判定搜索体验好不好,搜索结果满足用户需求已是最低门槛要求,以下内容都是能带来良好搜索体验的考察点、用户关注点:
搜索框:
1)在视觉上突出搜索框、搜索框与放大镜icon配合使用;
2)将搜索框置于用户预期的位置;
3)提供搜索按钮;
4)合适的尺寸
毫不客气的说:“在导航栏最显眼位置放置搜索框是对用户最起码的尊重”!
可搜索内容提示:告诉用户他们可以搜索哪些内容

每个页面都要有搜索框
使用智能推荐/匹配机制

智能推荐或匹配可以节省用户的输入成本。
普通用户不太善于组织搜索语言:在这种情况下如果他们没有在第一步就表达清楚问题,那么接下来也很难成功找到合适的搜索结果。
当智能匹配发挥作用后,它就能帮助用户表达清楚搜索的问题,进而找到满意的答案。
一句话,好的搜索体验就是好的用户体验,而好的用户体验自然和用户留存、甚至公司发展挂钩。
4、用户搜索的五个核心环节拆解
“搜索就像是用户与 App 或者网站之间的对话,用户通过提问表达信息需求,App 或者网站通过展示结果来作为回应。
用户期待流畅的搜索体验,并且基于搜索结果的质量用户通常会对一个 App 的价值形成一个快速的判断。”
在搜索的过程中,用户的经历大致可以分为五个部分,分别是:发现搜索、输入关键词、等待结果、查看结果、完成搜索,每个步骤的体验都是整体体验的一部分,将对用户最终对搜索体验产生影响。
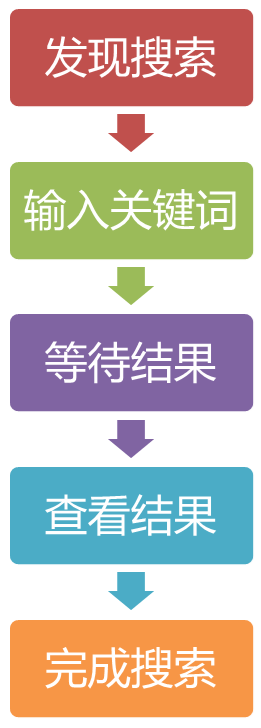
4.1 发现搜索
如前所述,搜索框要醒目,搜索栏甚至会独立于头部并且会在UI界面中占据视觉焦点的位置,用户很容易就能找到。
4.2 输入关键词
要能提示用户,输入什么关键词。 能根据用户输入的某几个关键,给出“搜索提示”,如前谷歌搜索截图。 复杂组合搜索,类似谷歌【高级搜索】,要有辅助控件,筛选日期、排除关键词设置、排序方式、与或非表达式等。
4.3 等待结果
响应要快,用户的忍耐是有限度的,超过3秒不返回,估计用户就流失了。 如果的确响应慢,可以有响应动画或者提示信息友好提示。 能识别用户输入,必要结果用户历史搜索习惯,整合后返回最优TOP N结果。
4.4 查看结果
用户根据搜索返回,筛选的过程。 如果没有结果,建议不要直接返回“0”条结果,可以有其他推荐信息,比如:提示用户换关键词等。
4.5 完成搜索
有满足需求结果,搜索结束。 没有满足用户的结果,用户会换关键词继续搜,或者用户流失去别的APP或者网站了。
若要完善用户体验,这几个步骤缺一不可、都得下功夫。
5、Elasticsearch 搜索的底层逻辑
明白下面两个过程,就能很好的理解 Elasticsearch 搜索。

以下仅针对:text的全文检索的文本类型。
5.1 写入索引化过程
文档写入 Elasticsearch 不是直接写入,而是根据你Mapping定义的分词器(默认:standard)分词,构建倒排索引后写入。
分词器的选型,决定分词的粒度,分词的粒度决定后续的检索指标是否能达标。
5.2 数据检索过程
检索环节,不是输入什么就检索什么,而是不同的检索语句,会有不同的检索机制。 检索环节,选择什么检索类型,结果也会完全不一致。
比如:“match”细粒度检索和“match_phrase”粗粒度短语匹配,将是截然不同的搜索结果。
match:会首先把你输入的关键词进行切分后再检索。
match_phrase:会把你输入的词当做短语进行检索。
6、Elasticsearch 搜索体验可量化的指标
用户体验是感官反应,但感觉的搜索结果需要量化下。
如何量化?实际本质指标就是:查准率(精确率)、查全率(召回率)。
6.1 召回率
定义:本次搜索结果中包含的相关文档占整个集合中所有相关文档的比率。
衡量检索结果的查全率。
6.2 精确率
定义:本次搜索结果中相关文档所占的比例。
衡量检索结果的查准率。
具体可以根据混淆矩阵来理解,
| 相关 | 不相关 | |
|---|---|---|
| 返回 | 真正例(tp) | 伪正例(fp) |
| 未返回 | 伪反例(fn) | 真反例(tn) |
已知上述矩阵,那么准确率和召回率可以按如下方法计算:
召回率:= tp / (tp + fn) * 100%;
精确率:= tp / (tp + fp) * 100%
如果还不好理解,知乎上通俗解释:
召回率:正样本有多少被召回了(召回了多少)。
精确率:你认为的正样本,有多少猜对了(猜的准确性如何)。
7 、如何改进 Elasticsearch 搜索体验
前面也提到了,搜索五环节环环相扣。搜索体验是:设计、前端、后端、决策层、管理层都要考虑的事情,不能简单的理解为是技术问题。
本文仅对 Elasticsearch 后端技术实现层面做下解读:
7.1 根据业务场景选择合适的分词器
注意,没有最好的分词器、没有适合所有业务场景的通用分词器,需要结合业务场景择优选择。
如果要求细粒度,只要存在就要召回,那 ngram 分词适合或者 7.9+ 新推出的 wildcard 数据类型优先考虑。
需要提前做下切词对比,以验证不同分词器是否满足业务。中文选择:IK、结巴、ansj或者其他。
切词对比核心 API :analyzer 要活学活用。
POST _analyze
{
"text":"提供全球卓越的云计算服务_助力企业无忧上云",
"analyzer": "ik_smart"
}
选型 IK,要区分:ik_smar 与 ik_max_word。
ik_smart是粗粒度的分词(返回尽可能少,逼近贴合人工分词);
ik_max_word是细粒度的分词(返回尽可能多)。
7.2 注意词典的选择与更新
“巧妇难为无米之炊“,“巧妇“是分词器,词典是“米”。
分词器再牛逼,没有靠谱的词典也是徒劳。
所以,词典选择的好,分词才会越准确。
建议:在基础词库相对全的前提下,需要结合业务场景添加属于自己的行业词库、领域词库等。
即便添加了行业、领域词典,也涵盖不全新词怎么办?
比如:新的网络词汇、行业领域词汇不能面面俱到导致分词不正确,用户体验差怎么办?
由于分词器作为插件,原始词典一旦配置,是不支持动态更新的,需要借助第三方机制实现。
比如:IK 词典的动态更新实现机制:结合修改 IK 分词器源码 + 动态更新 mysql 词条达到更新词典的目的。
7.3 重视 Mapping 环节数据建模
text 类型的 fielddata是内存耗费大户,除非必须,不建议开启。
根据是否需要排序或者聚合决定是否启用 keyword 类型。
不需要索引的字段,“index”设置为“false”。
不需要存储的字段,“store”设置为“false”。
大文本如 word,pdf 文本信息,考虑切分成小的片段后存储。
7.4 根据业务场景,选择合适的搜索类型
如前所述:match 和 match_phrase 适用场景不同、高下立判。
match应对的是:查全率高,召回率高但准确率低。
match_phrase则是:短语匹配,查准率高、召回率低。
wildcard 模糊匹配,除非必须,不建议使用。
当然,还有其他检索类型,如:query_string, fuzzy等,需要结合业务场景做出选择。
7.5 追求极致响应速度,要做取舍权衡
用户的忍耐时间非常有限, 不要让用户等。
加大数据节点的内存和堆内存的配比 _source 字段非必要不返回 不在检索返回阶段做复杂的业务处理
包含但不限于:
1)二重以上聚合
2)wildcard 或者 regex 正则检索
3)自定义高亮
高亮实现根据业务类型做好选型
注意:当文件>1MB(大文件)时候,尤其适合 fvh 高亮方式。
做好业务取舍
比如:默认 from,size 深度分页10000条够了,如果产品经理不同意,需要讨论说服之。
比如:聚合结果不准确是 Elasticsearch 默认机制,要接受或者做其他方案选型(比如:clickhouse),不纠结细节。
7.6 使用智能推荐/匹配机制
简单的搜索框推荐实现 可以借助:prefix 前缀搜索实现。
GET kibana_sample_data_ecommerce/_search
{
"_source": "customer_full_name",
"query": {
"prefix": {
"customer_full_name.keyword": "Ed"
}
}
}
复杂点的推荐实现,需要辅助纠错功能的,借助:Suggester实现。
POST /blogs/_search
{
"suggest": {
"my-suggestion": {
"text": "lucne rock",
"term": {
"suggest_mode": "missing",
"field": "body"
}
}
}
}
篇幅原因,关于 Suggester 解读,
推荐:wood大叔的文章:
https://elasticsearch.cn/article/142
再复杂点的,需要用户行为识别+推荐引擎机制实现。
一个优秀的推荐引擎更趋向于个性化推荐,它可以通过收集用户有价值的数字足迹(如:人口统计、事务细节、交互日志、购买记录、交易记录、浏览记录)和关于产品的信息(例如:规格、用户反馈、与其他产品比较等),来完成推荐之前的数据分析。
8、小结
搜索体验决定用户体验,用户体验决定的产品的用户率进而决定的产品的成败。
著名产品人梁宁老师在《产品思维30讲》提到“我们看到很多新的互联网公司,系统能力不如传统企业,但是可以从传统企业那里抢夺大量用户,靠的就是用户体验。在体量差异这么大的情况下,用户体验能成为核心竞争力;同维度竞争的时候,用户体验更是最核心的竞争力”。
搜索是流量入口,是“兵家“(各APP、网站)用户体验必争之地。
搜索体验的迭代是没有终点的,研究的多深、做的多仔细都不为过。
大家有好的思路和建议也欢迎补充交流。
参考:
http://www.woshipm.com/ucd/1037490.html https://zhuanlan.zhihu.com/p/60826371 https://www.jianshu.com/p/677742838595 http://www.chanpin100.com/article/103633 https://www.uisdc.com/search-experience-process-summary http://www.oreilly.com.cn/radar/?p=28 《自己动手做推荐引擎》
推荐:
更短时间更快习得更多干货!
中国40%+Elastic认证工程师出自于此!