
从 Tree Shaking 来走进 Babel 插件开发者的世界
点击上方 前端瓶子君,关注公众号
回复算法,加入前端编程面试算法每日一题群

引言
如果对Babel基础知识和插件开发不是很了解的同学,可以查看这篇文章「前端基建」带你在Babel的世界中畅游[2]补充下
Babel的基础知识哦~
作为前端开发者,无论是作为业务还是学习我相信大家都有一个属于自己的组件库。
这里,我们就从Tree Shaking的角度出发来谈谈如何为我们自己的组件库提供按需加载方式。
何谓Tree Shaking
简单聊聊什么是Tree Shaking
其实Tree Shaking的概念已经耳熟能详了,所谓的“摇树”就是说将我们代码中的没有用到的代码进行摇晃掉,从而减少包的体积。
我们来看一个简单的例子:
// index.js 入口文件
import { funcHao } from './math'
funcHao()
复制代码
// math.js
const funcWang = () => {
const obj = {};
return obj;
};
const funcHao = () => {
console.log('hao');
};
export { funcWang, funcHao };
export {
funcWang,
funcHao
}
复制代码
// webpack.config.js
const { resolve } = require('path');
module.exports = {
mode: 'production',
entry: resolve(__dirname, './src/index.js'),
module: {
rules: [
{
test: /\.js$/,
use: [
{
loader: 'babel-loader',
options: {
presets: ['@babel/preset-env'],
},
},
],
},
],
},
output: {
filename: '[name].js',
},
};
复制代码
这里我们使用webpack新建了一个只有两个文件的项目。
src/index.js: 入口文件,导入math.js中的funcHao方法。src/math.js: 导出两个方法funcHao和funcWang两个方法。
tip: 这里我们配置
babel的原因不单单是为了转译箭头函数,稍微我在后边会讲述为什么这里为配置了一个babel-preset-env。
让我们运行webpack命令打包我们的代码:
// dist/main.js
(()=>{"use strict";console.log("hao")})();
复制代码
我们会发现打包后的代码仅存在console.log("hao"),而funcWang这个函数的内容并没有被打包进入。
其实简单来说这就是所谓的Tree Shaking: 基于 ES Module 规范的 Dead Code Elimination 技术,它会在运行过程中静态分析模块之间的导入导出,确定 ESM 模块中哪些导出值未曾其它模块使用,并将其删除,以此实现打包产物的优化。
简单来说就是删除项目中没有使用到的代码从而达到优化代码的效果。
Tree Shaking工作原理
需要额外注意的是:
Tree Shaking是基于ESM模块基础进行处理的。
至于为什么Tree Shaking需要ESM模块才能使用呢? 让我们来一起看一看这个问题。
简单来说一段js代码的执行过程,需要经历以下三个步骤:
V8通过源码进行词法分析,语法分析生成AST和执行上下文。根据
AST生成计算机可执行的字节码。执行生成的字节码。
在JS的执行过程中,ES Module在第一步时就可以确认对应的依赖关系(编译阶段),并不需要执行就可以确认模块的导入、导出。
ES Module在js编译阶段就可以确定模块之间的依赖关系(import)以及模块的导出(export),所以我们并不需要代码执行就可以根据ESM确定模块之间的规则从而实现Tree Shaking,我们称之为静态分析特性。
同理,对比commonjs模块,它依赖于代码的执行,需要在第三阶段执行完成代码之后才能确认模块的依赖关系。
自然也就不支持Tree Shaking。
关于
ES Module中的动态引入dynamic import,因为它同样是动态需要js执行后才能确认的模块关系。自然也就无法支持Tree Shaking。
为什么我要配置babel-preset-env
上文讲到过我刻意配置了@babel/preset-env处理我们的代码,了解过它的同学可能会清楚。
@babel/preset-env是存在一个modules的配置参数,它的默认值是auto。
modules配置的含义是,在preset-env转译时中启用 ES 模块语法到另一种模块类型的转换。
也许你会在很多教程或者网站上看到,由于Tree Shaking必须基于Es Module模块。
所以如果我们项目中使用到babel-preset-env时需要将它的modules配置为false:相当于告诉babel,"嘿,Babel请保留我代码中的ESM模块规范"。
没错,你配置为false的确没有任何问题,可是上边我们的配置没有进行任何配置,默认值为auto的时候同样进行了Tree Shaking。
你有想过这是为什么吗?日常工作中我相信大部分同学使用preset-env结合业务时也没有刻意配置modules:false吧。
其实根本原因就出现在它的默认参数auto中。
配置为
auto,默认情况下,@babel/preset-env使用`caller`[3]数据来确定是否import()应转换ES 模块和模块功能(例如)。
关于如何理解这段话,比如: 如果我们使用Babel-Loader调用Babel,那么modules将设置为False,因为WebPack支持es模块。
关于
auto参数更加详细的信息,你可以在这次commit[4]中看到。
其实这里我配置preset-env的原因就是想和大家讲述一下关于modules:auto的含义,我相信还是有不少朋友对于modules:auto之前仍然是一知半解的状态。
实现组件库Tree Shaking思路
在讲述了何谓Tree Shaking之后,让我们真正来动手基于Babel来实现一个Tree Shaking插件吧!
组件库Tree Shaking历程
首先,在老版本的webpack中是不支持将代码编译成为Es module模块的,所有就会导致一些组件库编译后的代码无法使用Tree Shaking进行处理。(因为它编译出来的代码压根就不是ES Module呀!)
所以老版本组件库中,比如element-ui中借用babel-plugin-component,老版本ant-design使用babel-plugin-import进行分析代码从而实现Tree Shaking的效果。
关于这两个插件其实是类似的效果,我们会在之后重点讲述这部分内容。
细心的朋友可能也发现了,在目前的antd和element-plus中官网中提到已经能够完全的支持Tree Shaking功能了。
没错!这正是因为它的的代码现在打包后会额外打出一份ES Module的模块规范代码,在结合package.json中的module字段,可以不借助于任何插件在ES Module模块下完美的进行Tree-Shaking。
既生瑜,何讲亮?
也许有的同学会问到了,既然现在很多构建工具都支持打包ES Module规范,如此我们将组件库直接打包为ES Module规范不就可以了吗?为什么费事费力写这么一个babel插件去使用。
首先,之所以选择写这样一个Tree Shaking插件更多的原因是想让大家通过这样一个插件"管中窥豹"。在了解了Tree Shaking和组件库的发展历程之后,在结合之前业内的实践去学习Babel插件的开发流程。我个人看来这个插件是最适合入门且思路清晰的。
其次,我们的组件库的确可以打包成为Es Module形式直接支持Tree Shaking,但是难免有一些我们在业务中使用到的库打包生成的文件并不是基于ES Module规范的。
此时,如果我们使用到的这些库。不同的方式存放于独立的文件之中的话,我们完全可以基于我们自己开发的Tree Shaking插件在引入时候进行语句分析从而实现Tree Shaking的功能。
比如我们以为lodash为例子:
import { cloneDeep } from 'lodash'
// ... 业务代码
复制代码
当你这样使用lodash时,由于打包出来的lodash并不是基于esm模块规范的。所以我们无法达到Tree Shaking的效果。
import cloneDeep from 'lodash/cloneDeep'
// ... 业务代码
复制代码
此时,由于lodash中的cloneDeep方法存在的位置是一个独立的文件--lodash/cloneDeep文件。
当我们这样引入时,相当于仅仅引入了一个js文件而已。就可以显著的减少引入的体积从而删除无用的代码。
当然现阶段
lodash已经提供了es标准的库,这里我们只是用它来举例从而让大家更好的理解而已。
Babel插件实现Tree Shaking的原理
其实上边针对于lodash的例子已经非常接近于插件所要实现的功能了。
在使用import引入特定的库方法时(非默认),我们分析对应的import语句从而改写对应的import语句:引入对应的方法指向对应的独立文件就可以Tree Shaking的效果了。
当然也许有同学会好奇,我直接这样可以吗:
import cloneDeep from 'lodash/cloneDeep'
import join from 'lodash/join'
import findLast from 'lodash/findLast'
// ....
复制代码
Emm...这样的确可以实现效果,不过嘛。作为一个合格的前端工程师怎么能写出这样冗余的代码呢。
import { cloneDeep,join,findLast } from 'lodash'
复制代码
相比之下,这样岂不是更清爽嘛😂。
实现Babel插件
需要使用到的Babel包
文章中顶部链接已经贴出了一份详尽的Babel配置指南和基础插件开发者指南了。这里我就简单提一下关于插件开发中使用到的babel相关的tool package:
@babel/core: 核心babel转译包,这里主要使用到它的transform方法。babel/types:babel工具包,这里使用它来生成对应的AST节点和调用对应检查节点API。babel/handbook:babel插件开发者手册,这里[5]涵盖了babel插件对应的流程和API。
开发插件
讲了那么多原理,让我们在真正来到Coding阶段吧!
// index.js
const core = require('@babel/core');
const babelPluginImport = require('./babel-plugin-import');
const sourceCode = `
import { Button, Alert } from 'hy-store';
`;
const parseCode = core.transform(sourceCode, {
plugins: [
babelPluginImport({
libraryName: 'hy-store',
}),
],
});
console.log(sourceCode, '输入的Code');
console.log(parseCode.code, '输出的结果');
复制代码
index.js中我们首先建立一个测试文件。用来测试我们的插件。这里调用了我们写好的插件,并且输入了源代码import { Button, Alert } from 'hy-store';。
我们希望的打印结果是:
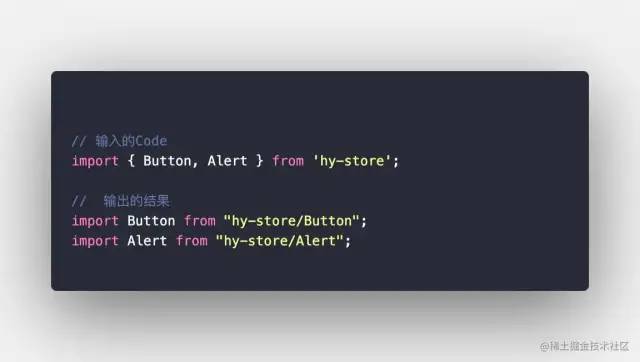
同时我们的插件需要接受一个参数为libraryName的参数。这个参数用来告诉我们的插件:仅针对于这个libraryName的导入语句进行处理。
在搭建好基础的测试插件代码后,让我们来进入插件内部的逻辑:
Babel插件本质上就是一个对象中包含一个visitor属性,从而针对visitor属性上的key进行深度遍历生成的AST,匹配到对应visitor上的key时触发对应的方法从而进行对AST节点的增删改查实现生成新的AST->生成新的code。
当然你也可以导出一个函数,函数返回这个对象。
让我们先来进行基础的插件结构开发:
const core = require('@babel/core');
const t = require('@babel/types');
function babelPluginImport(options) {
const { libraryName = 'hy-store' } = options;
return {
// babel插件就是基于`visitor`观察者模式
visitor: {
// do something
},
};
}
module.exports = babelPluginImport;
复制代码
接下下让我们打开--Astexplorer[6],输入我们的输入代码和输出代码:
我们首先来看看输入(需要分析)代码:
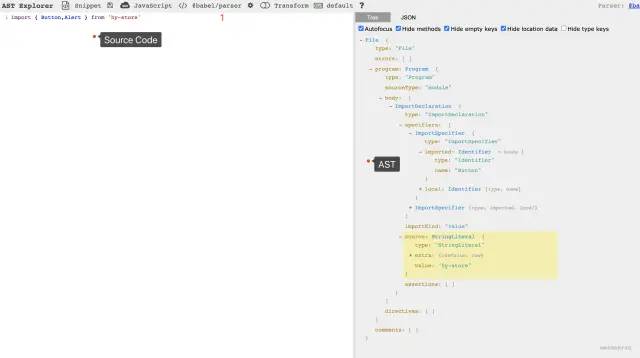
注意 1位置我们选择编译器为@babel/parser。同时我们在左侧输入我们的 source Code。右侧就会动态生成对应的 AST。
同样的操作让我们再来输入targetCode(分析后生成的代码)来看一看吧:
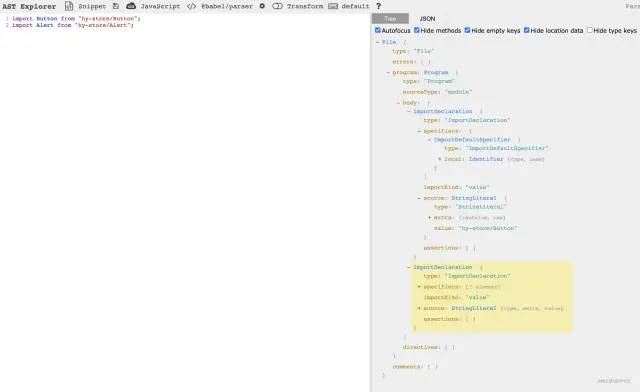
看到这里的同学,我希望你停一停往下看,自己稍微对比下这两棵树的差距。在脑海中思考如果将source中的Tree转化为target中的Tree,需要怎么处理。
让我们稍微来捋一捋:
首先当我们碰到
ImportDeclaration语句时,需要判断它的source是否来自于我们的libararyName这个库。当匹配引入我们的对应库时,我们还需要遍历当前
ImportDeclaration节点中的specifiers中是否包含默认导出ImportDefaultSpecifier。当上述两个条件都满足时,进入我们之后的逻辑处理。
引入( import)的是我们传入匹配的libraryName。引入语句中不包含 import xx from libraryName(默认导出语句)。我们需要遍历左侧
ImportDeclaration中的specifiers,将specifiers中每一个导出语句修改成为对应独立文件路径的默认导出语句。
简单来说,一个Tree Shaking Babel Pluign需要经历的就是上述四个步骤。
const t = require('@babel/types');
function babelPluginImport(options) {
const { libraryName = 'hy-store' } = options;
return {
visitor: {
// 匹配ImportDeclaration时进入
ImportDeclaration(nodePath) {
// checked Validity
if (checkedDefaultImport(nodePath) || checkedLibraryName(nodePath)) {
return;
}
const node = nodePath.node;
// 获取声明说明符
const { specifiers } = node;
// 遍历对应的声明符
const importDeclarations = specifiers.map((specifier, index) => {
// 获得原本导入的模块
const moduleName = specifier.imported.name;
// 获得导入时的重新命名
const localIdentifier = specifier.local;
return generateImportStatement(moduleName, localIdentifier);
});
if (importDeclarations.length === 1) {
// 如果仅仅只有一个语句时
nodePath.replaceWith(importDeclarations[0]);
} else {
// 多个声明替换
nodePath.replaceWithMultiple(importDeclarations);
}
},
},
};
// 检查导入是否是固定匹配库
function checkedLibraryName(nodePath) {
const { node } = nodePath;
return node.source.value !== libraryName;
}
// 检查语句是否存在默认导入
function checkedDefaultImport(nodePath) {
const { node } = nodePath;
const { specifiers } = node;
return specifiers.some((specifier) =>
t.isImportDefaultSpecifier(specifier)
);
}
// 生成导出语句 将每一个引入更换为一个新的单独路径默认导出的语句
function generateImportStatement(moduleName, localIdentifier) {
return t.importDeclaration(
[t.ImportDefaultSpecifier(localIdentifier)],
t.StringLiteral(`${libraryName}/${moduleName}`)
);
}
}
module.exports = babelPluginImport;
复制代码
至此,我们一个最基础的Tree Shaking Babel plugin已经实现了。
你可以发现它仅仅只有60行代码,但是麻雀虽小五脏俱全。针对于一个Babel插件的开发流程以及核心思路我相信大家在熟练掌握了这个插件的开发思想后,针对于其他类似需求完全可以做到游刃有余。
接下来让我们运行一下我们最开始的代码:
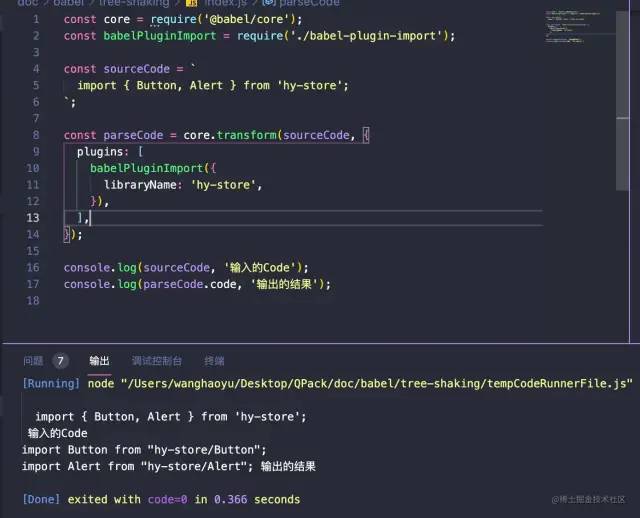
大功告成!!
针对于这个Babel Plugin其实还很很多可以优化的feature。
比如
组件库中的
css/scss/less等样式支持Tree Shaking引入。组件库中路径支持动态参数传入。
...
这些细节我会在之后的commit中进行依次完善,有兴趣的同学到可以在[这里看到它的代码地址]。(github.com/19Qingfeng/…[7])
写在结尾
至此,我们针对于Tree Shaking结合Babel Plguin的讲述到这里就完成了。
文章中的Plugin的例子只是我个人觉得比较实用的一个易用简单讲解的🌰,更多的我还是希望的是大家在业务/工具中碰到一些棘手的问题时,不要忘记我们还可以从定制Babel Plugin的角度去尝试思考解决问题的不同方式。
在之后的代码仓库[8]中我会扩展更多的Babel Learn Feature去总结分享给每一个奋斗在前端路上的同学。
如果大家有什么疑问也可以在评论区互相交流,我会第一时间进行回复😂~
我的博客即将同步至腾讯云+社区,邀请大家一同入驻:cloud.tencent.com/developer/s…[9]
关于本文
来源:19组清风
https://juejin.cn/post/7028584587227824158