
这,就很抽象!
大家好,我是 Jack。
上周末,可把我忙坏了,公司有活动,周六参加了一天,周日又做了一天的视频。
新视频,还在赶制中,7 月份视频又鸽了一个月,难受~ 不过新视频绝对精彩,信我!
今天,聊聊“多模态”的两个算法,MDETR 挺有意思,DALL·E Mini 很抽象。
MDETR
今年,是“多模态”百家争鸣的一年,各种多模态算法,层出不穷。
MDETR 一种端到端的多模态推理算法,可以支持文本和图像的同时推理。
这就很有意思了。
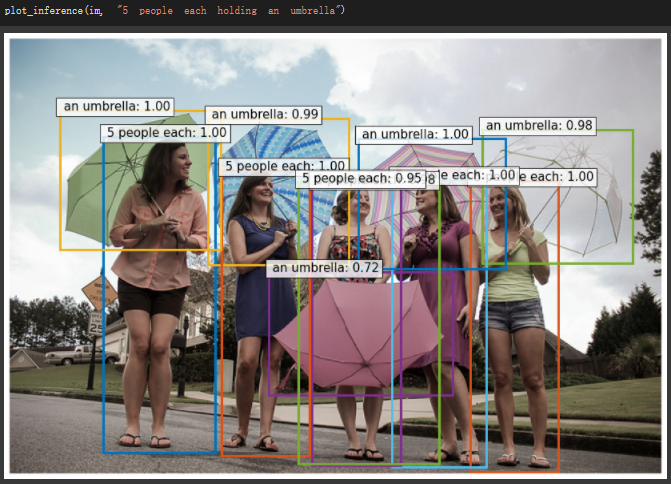
输入:
5 people each holding an umbrella
MDETR 可以找出对应的人,并框选出来:
输入:
A green umbrella. A pink striped umbrella. A plain white umbrella
MDETR 只框选文字描述的目标:

这就是多模态,视觉和文本的结合。
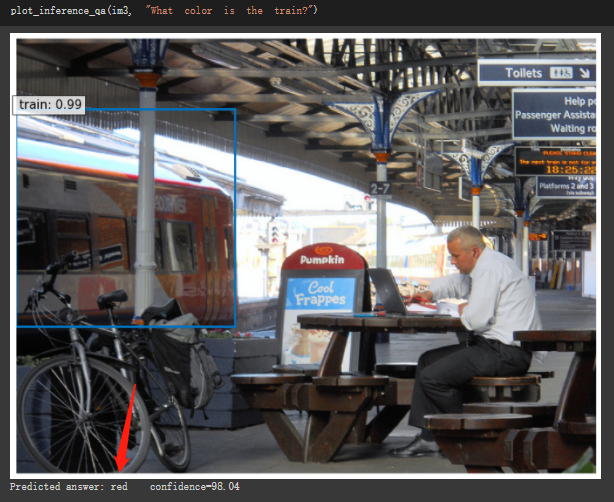
甚至可以问:
What color is the train?
MDETR 可以告诉你是红色,并且把火车框选出来。
MDETR 是基于 DETR 实现的调制检测器,结合 NLP 来执行目标检测任务,真正实现了端到端的多模态推理。
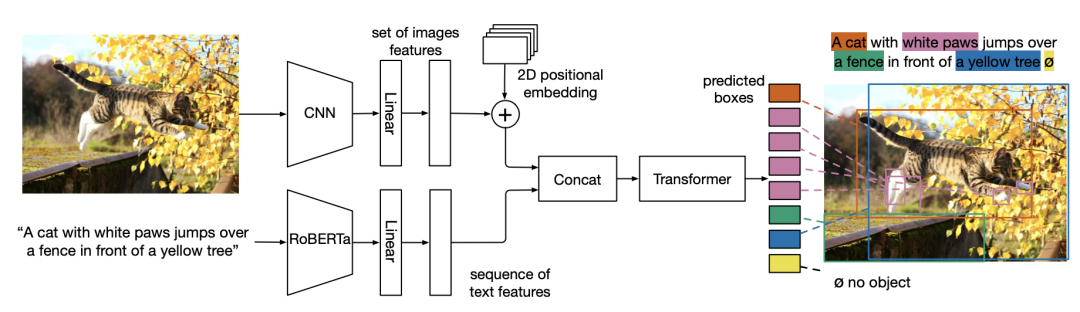
对于图像,MDETR 采用的是一个 CNN 作为 backbone 提取视觉特征,然后引入位置编码;对于语言,采用训练好的 Transformer 语言模型来生成与输入值相同大小的 hidden state,然后作者采用了一个模态相关的 Linear Projection 将图像和文本特征映射到一个共享的 embedding 空间。
接着,将图像 embedding 和语言 embedding 进行 concat ,生成一个样本的图像和文本特征序列。
项目地址:
https://github.com/ashkamath/mdetr
DALL·E Mini
没错,这也是“多模态”的另一作品。
我之前在出过的 Transformer 教程中,提到过 DALL·E:
DALL·E,可以魔法一般地按照自然语言文字描述直接生成对应图片!
输入文本:鳄梨形状的扶手椅。
AI 生成的图像:

DALL·E Mini 是 DALL·E 迷你版,模型缩小了 27 倍。
我试着体验了一下,给模型输入了:
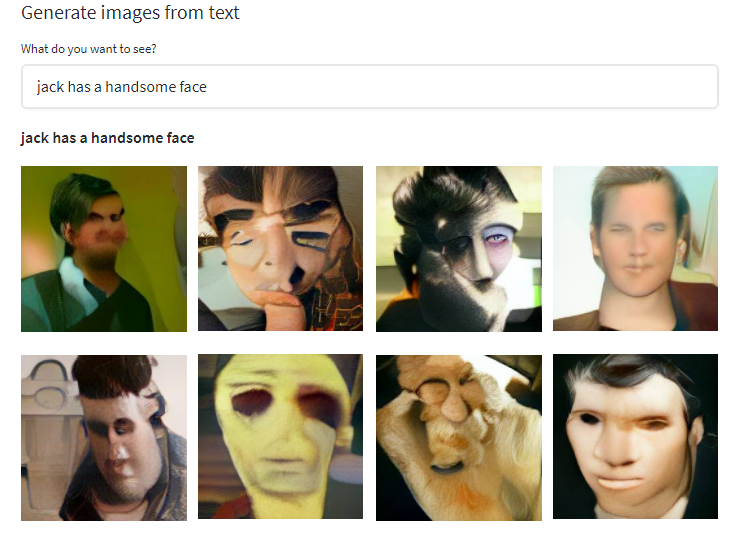
jack has a handsome face
Jack 拥有一张英俊帅气的脸,没错,就是这么不要 face。
一看结果,好家伙,抽象派的毕加索,都不敢这么画:
我又试了下:
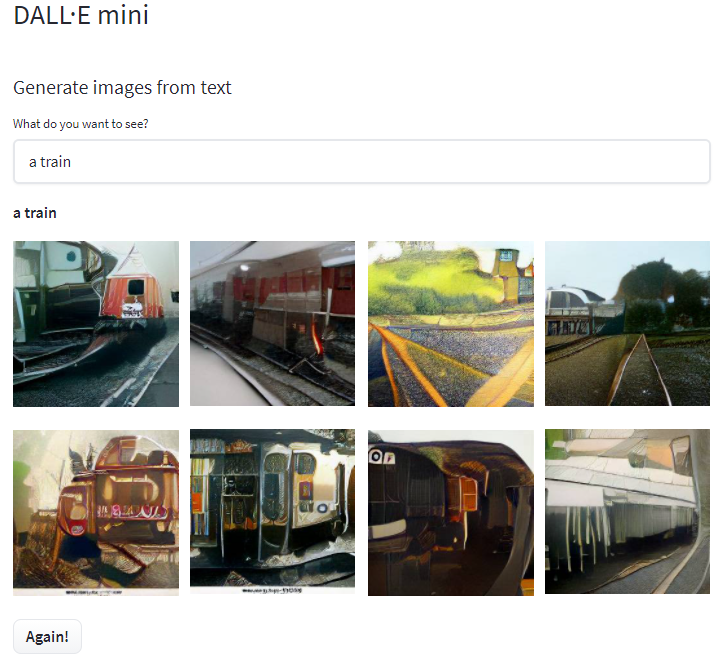
a train
虽然,是那么回事,但这画的真“抽象”。
DALL·E Mini 倒是可以当做“抽象”作画使用,写实的画,要差太多。
因为 Mini 版本的原因,效果上,感觉也要弱于 DALL·E 。
可以看下,论文中展示的一些样例:

看着还可以,算法的思想还是很值得我们学习的。
项目地址:
https://github.com/borisdayma/dalle-mini
总结
“多模态”大势所趋,利用闲暇时间学习学习。
我是 Jack ,我们下期见!
