
如何才能让你的程序实现自动更新?
当我们写了一个软件的时候,有时候因为其他地方的调整,之前的版本已经不再适用,而再次发布,再次分享新软件的链接,对用户很不友好,这时候就需要给旧版本一个通道,让它能够有检测新版本的功能并且自动升级。

当然解决的方法不唯一,我是这么操作的,在每次软件打开的时候就访问一个特定的网站,然后获取它显示的内容,我们把每次更新后的版本都发布在那个网站上面,当旧软件获取到了新软件的信息后,旧提示,有新的软件升级,然后自动下载到指定的目录。
话不多说,干活。我个人来说经常把一些东西上传到蓝奏云上,最主要的原因是它不限速,只需要获取到蓝奏云的个人主页,就可以查看发表了哪些内容。
比如:
https://vk666.lanzous.com/b00z8pwpg
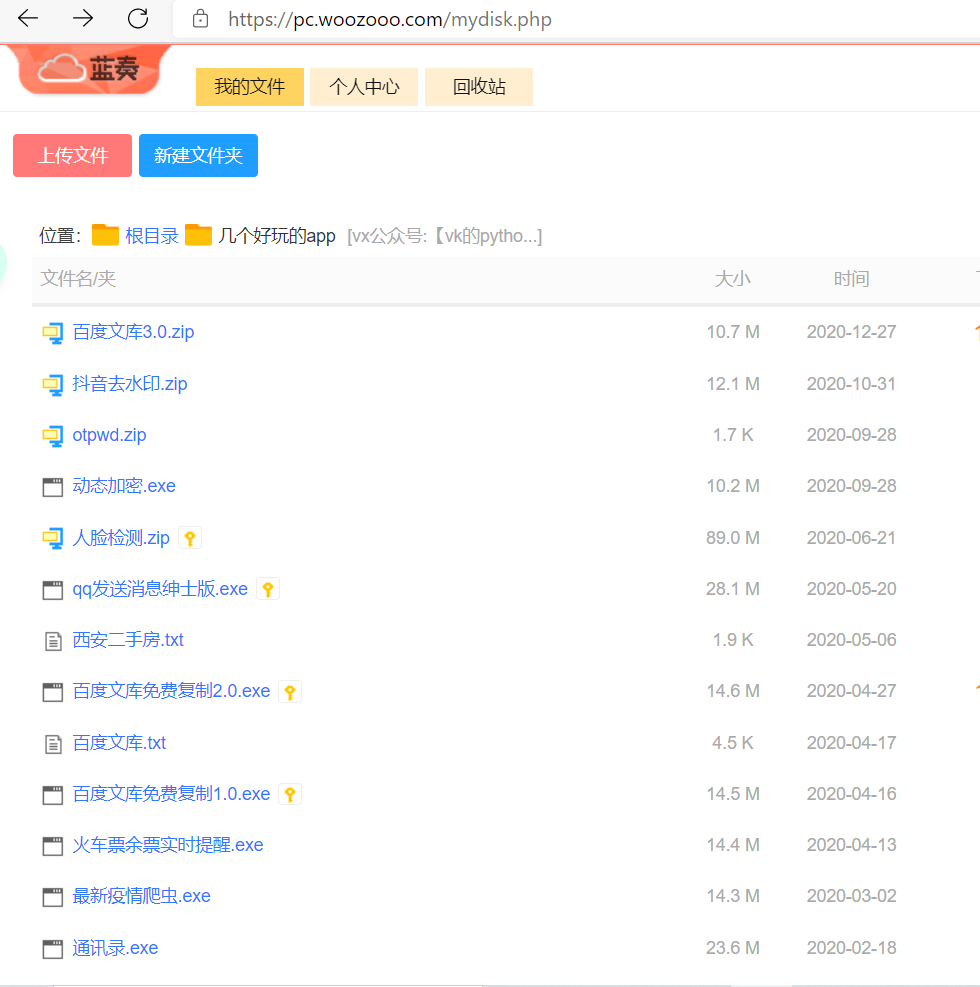
一个软件的旧版本的名字叫xxx.1.0,而新版本的名字叫xxx.2.0,通过旧软件提取这个页面的所有名字,当发现了有大于2.0的版本的时候,就提示用户,有新的更新了。
url="https://vk666.lanzous.com/b00z8pwpg"headers={'User-Agent':'Mozilla/5.0(WindowsNT10.0;Win64;x64)AppleWebKit/537.36(KHTML,likeGecko)Chrome/88.0.4324.96Safari/537.36Edg/88.0.705.56',}res = requests.get(url,headers=headers)r=res.textimport re#用正则表达式,把后面的版本号提取出来pattern1=re.compile('var (.+?);')
这下提示的内容有了,就剩自动下载了,拿蓝奏云举例吧。
怎么才能获取到软件名字对应的下载链接呢。
在想要获取链接的软件名字那里右键,然后点击检查,查看它对应的html内容,在标签的href下发现了下载链接
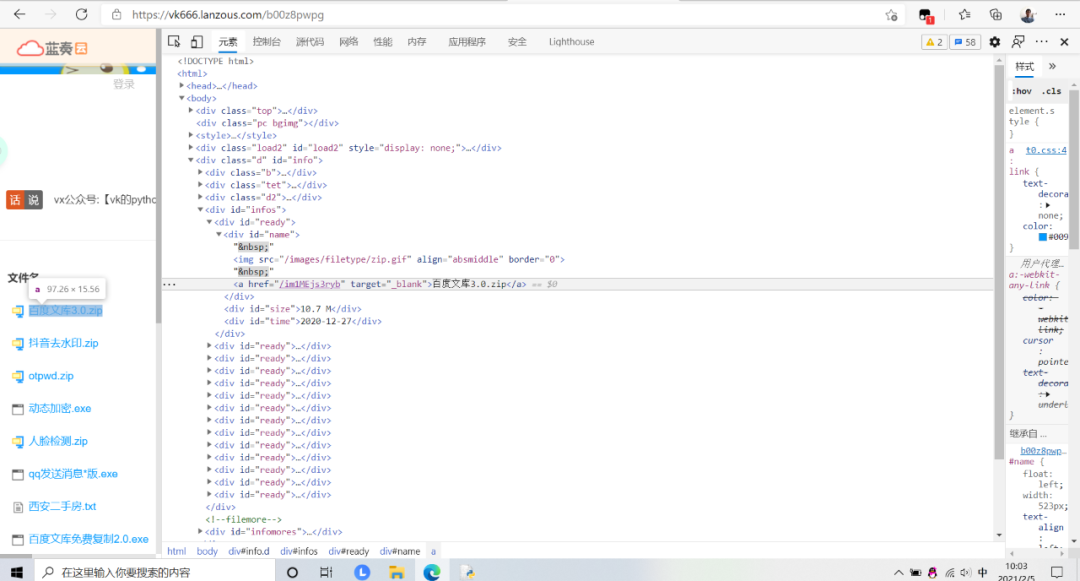
就产生了这样的想法,我们直接用
res = requests.get(url,headers=headers)print(res.text)
这样获取页面的html文本,最后通过各种解析方法,从html里面提取出对应的链接就行。但是仔细观察一下 当我们刷新网页的时候,这里div标签和head都闪了一下,表示有新的内容填入。
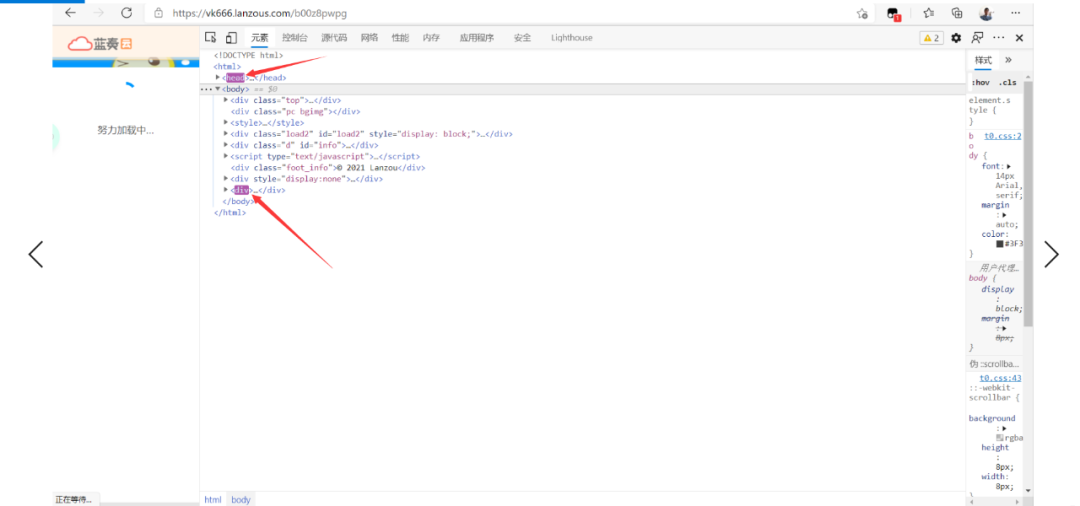
说明了什么,这个网页不是一个静态的网页,而是根据js动态渲染的一个网页,如果直爬取静态内容,肯定获取不到想要的信息。
这时候,就可以通过抓包,来看看浏览器到底对服务器进行了什么操作,来显示这些动态的内容呢?打开网络,发现了这些信息,逐步排查以后发现了这样一个post包。
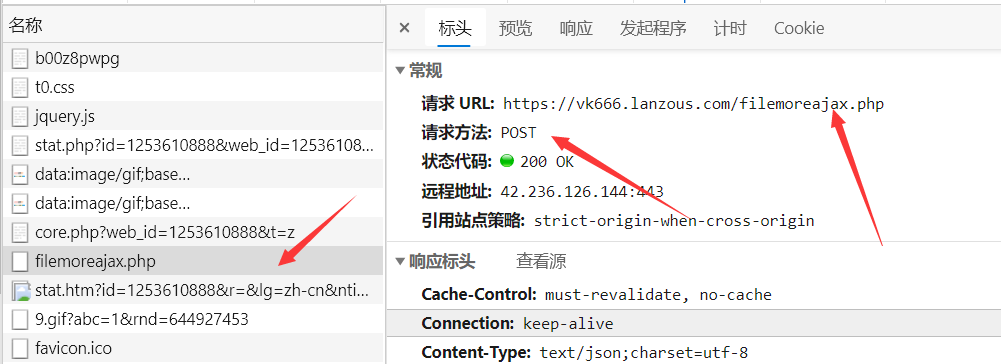
查看它的响应内容,发现了正是我们想要的内容。
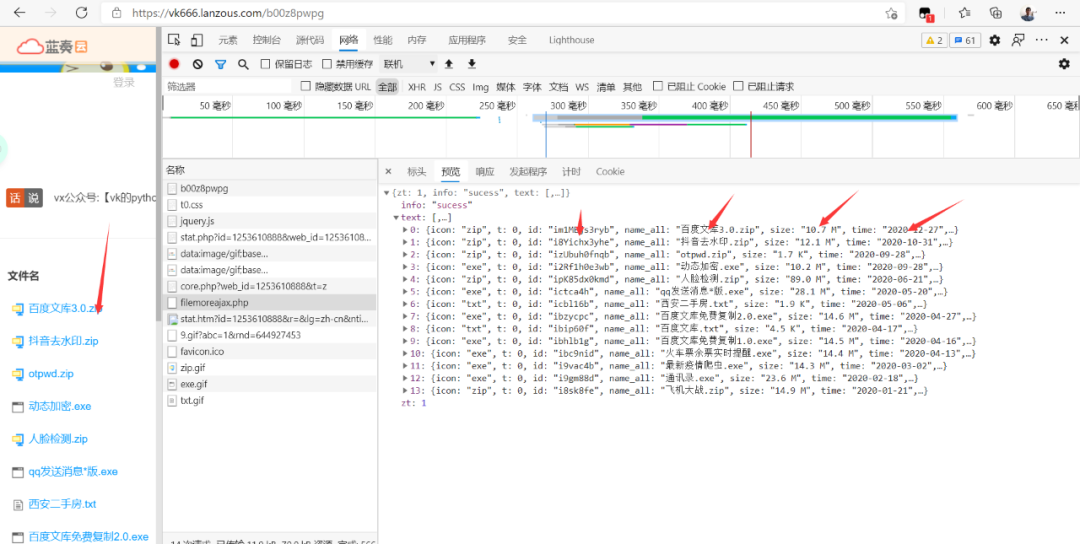
是一个json格式的数据包含了id ,name 等。浏览器向服务器提交了这个包,服务器返回了我们想要的信息。这时候,就想起了用程序模拟这个方式。模拟之前,需要查看到底发送了什么内容。
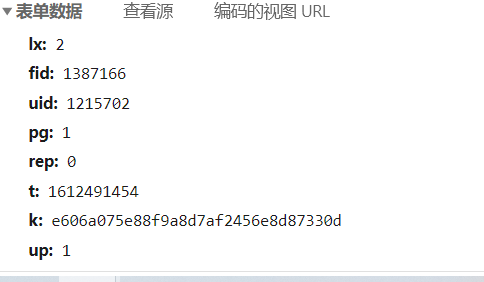
经过不断刷新以后,发现只有t和k是不断变化的,这个t一看就是时间戳,只剩下k不知t,在网络页面下,Ctrl+f全局搜索k的值,看看它在哪个文件里有一次出现了.最后在这个包里发现了。
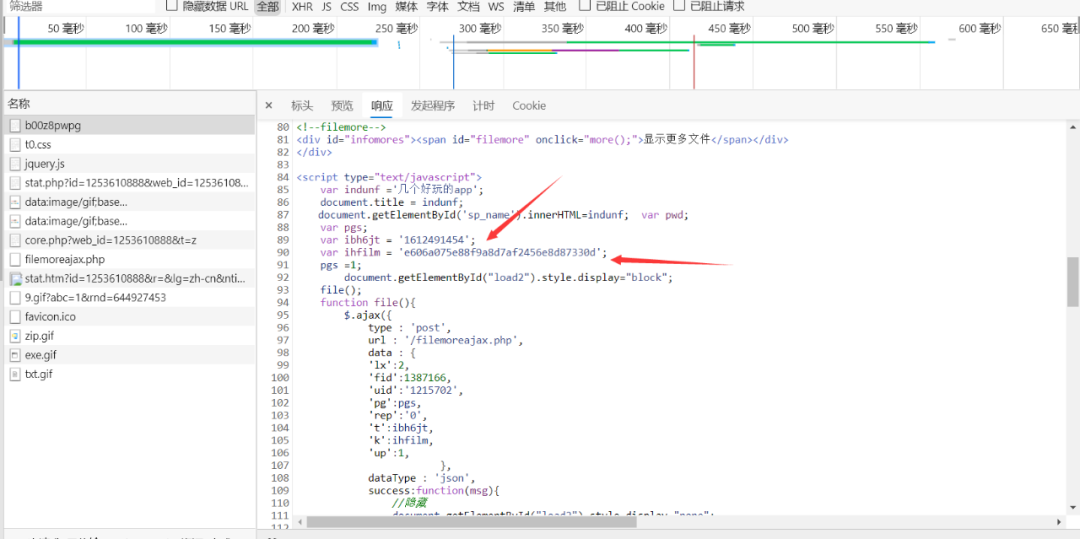
从这个包的返回值里解析出来k的值,然后再把它当作数据,提交到
https://vk666.lanzous.com/filemoreajax.php
就可以获取想要的信息了。
url="https://vk666.lanzous.com/b00z8pwpg"headers={'User-Agent':'Mozilla/5.0(WindowsNT10.0;Win64;x64)AppleWebKit/537.36(KHTML,likeGecko)Chrome/88.0.4324.96Safari/537.36Edg/88.0.705.56',}res = requests.get(url,headers=headers)r=res.textimport repattern1=re.compile('var (.+?);')t=pattern1.findall(r)[3]k=pattern1.findall(r)[4]k=k.split("'")[1].split("'")[0]t=t.split("'")[1].split("'")[0]data={'lx':'2','fid':'1387166','uid':'1215702','pg':'1','rep':'0','t':t,'k':k,'up':'1',}url='https://vk666.lanzous.com/filemoreajax.php'res = requests.post(url,headers=headers,data=data)data=res.json()data=data['text']
注意这里的t也必须是从这个包里获取的t值,是当时服务器的时间戳,而不是本地的时间戳。
点开详细页面发现,每个文件的下载链接就是 :https://vk666.lanzous.com+一组数。而这组数正是之前获得的id 。
问题又来了,这个普通下载按钮下的链接才是真正的下载链接,怎么才能获取到呢,老方法,刷新,发现在html里面是动态加载的,抓包。真正的下载url就在这个地方。
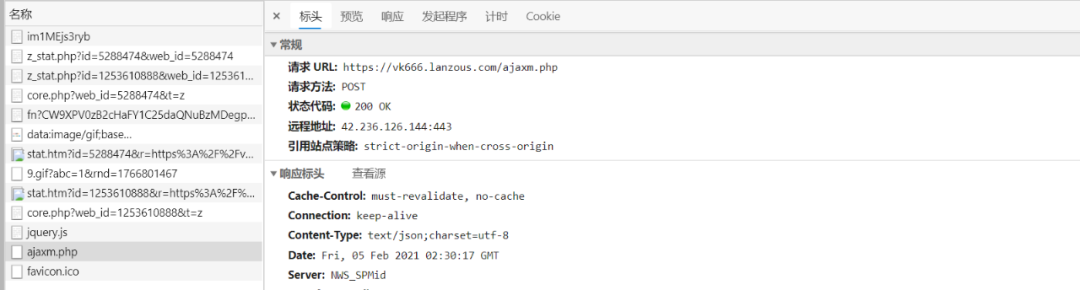
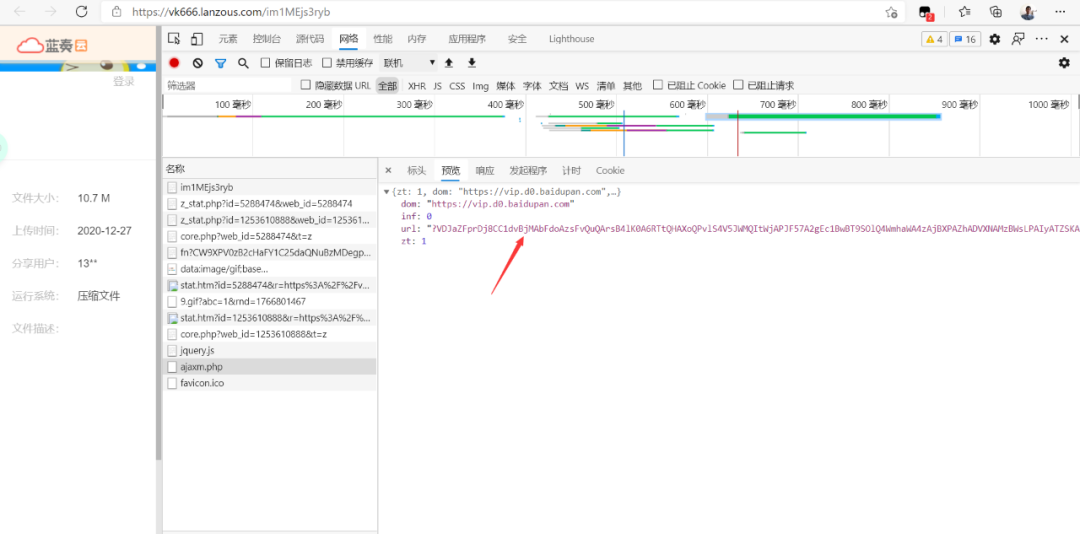
又是post老方法,找到需要提交的数据,就可以获取。
与之前方法一模一样,这里不再赘述。
完整代码
import timeimport requestsfrom parsel import Selectordef get_update():url="https://vk666.lanzous.com/b00z8pwpg"headers={'User-Agent':'Mozilla/5.0(WindowsNT10.0;Win64;x64)AppleWebKit/537.36(KHTML,likeGecko)Chrome/88.0.4324.96Safari/537.36Edg/88.0.705.56',}res = requests.get(url,headers=headers)r=res.textimport repattern1=re.compile('var (.+?);')t=pattern1.findall(r)[3]k=pattern1.findall(r)[4]k=k.split("'")[1].split("'")[0]t=t.split("'")[1].split("'")[0]data={'lx':'2','fid':'1387166','uid':'1215702','pg':'1','rep':'0','t':t,'k':k,'up':'1',}url='https://vk666.lanzous.com/filemoreajax.php'res = requests.post(url,headers=headers,data=data)data=res.json()data=data['text']name_data={}size_data={}url_2='https://lanzous.com/'name_list=name_data.keys()for i in data :name_data[i['name_all']]=url_2+i['id']size_data[i['name_all']]=i['size']for i in name_list:num=re.sub("\D", "", i)if num >'30':url=name_data[i]res=requests.get(url,headers=headers)data=res.textrep=Selector(data)texts=rep.css("iframe[src*='/']::attr(src)").extract()[0]texts=url_2+texts.split('/')[1]res=requests.get(texts,headers=headers)pattern2=re.compile("(?<='signs':ajaxdata,'sign':')(.+?)(?=','ves':1,)")sign=pattern2.findall(res.text)[0]data={'action':'downprocess','signs':'?cftdf','sign':sign,'ves':'1','websign':''}headers={'User-Agent':'Mozilla/5.0(WindowsNT10.0;Win64;x64)AppleWebKit/537.36(KHTML,likeGecko)Chrome/88.0.4324.96Safari/537.36Edg/88.0.705.56','referer':texts}url_3='https://vk666.lanzous.com/ajaxm.php'res=requests.post(url_3,data=data,headers=headers)res=res.json()down_url='https://vip.d0.baidupan.com/file/'+res.get('url')return size_data,down_urlelse:return 0
把以上程序当作一个库引入主程序,每次运行主程序前,运行一遍更新程序就好。
看完这篇以后,相信我们对http更加熟悉了,再来想想,上一篇我们写过的一个简单的http服务器,可是要是有一百个,一千个用户同时访问怎么办呢?
下一篇啊,我会说说,多任务(多进程,多线程,协程)