
快过年了,来写首诗不?(二)
上一篇中,我们以及完成了数据的处理,当我们有了数据之后,就可以搭建模型进行训练了,这里我们的模型是使用RNN进行搭建的。
模型搭建

诗词数据集不同于我们之前介绍的MNIST数据集图像并不会随着时间而改变,所以使用多层感知器或者卷积神经网络都能达到不错的效果。
然而,人工智能所要解决的问题很多是顺序性的,如自然语言处理(同一时间只能听到一个字,之前的语言会影响到之后语音的含义),视频图像处理(视频时一张张的图片,依照时间顺序所组成的),气象观测数据(气象信息随着时间不断改变)等。
以26个英文字母为例,我想你看见下面的这一排字母,应该很快就能想起它的排序

然而,当要求你尝试着反着说这些字母,我敢打赌这要困难的多。除非你之前练习过这个特定的序列。

接着,我们来一个更有趣的,直接从字母F开始,首先,你会在前几个字母上挣扎,但是在你的大脑拿起图案后,剩下的就会自然而然。因此,有一个非常合乎逻辑的原因是困难的。你将字母表作为序列学习,顺序存储是一种使大脑更容易识别序列模式的机制。

同样的,我们可以联想到RNN也应该存在着 这个循序存储的抽象概念。但是RNN时如何学习这个概念的呢?我们先来看一个传统的神经网络,他有输入层,隐藏层和输出层。

我们如何训练一个前馈神经网络,以便能够使用以前的信息来影响以后的信息呢?如果我们在神经网络中添加一个可以传递先前信息的循环它将会变成什么呢?这基本上就是一个递归神经网络了。RNN让循环机制充当高速公路以允许信息从一个步骤流到下一个步骤。
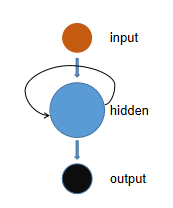
让我们通过一个RNN用例来更好地理解它是如何工作的。假设我们想要构建一个聊天机器人,以为它们现在非常受欢迎。假设聊天机器人可以根据用户输入的文本对意图进行分类。
为了解决这个问题。首先,我们将使用RNN对文本序列进行编码。然后,我们将RNN输出馈送到前馈神经网络中,该网络将对用户输入意图进行分类。
假设用户输入:what time is it?首先,我们将句子分解为单个单词。RNN按顺序工作,所以我们一次只能输入一个字。
第一步是将“What”输入RNN,RNN编码“what”并产生输出。第一步是将“What”输入RNN,RNN编码“what”并产生输出
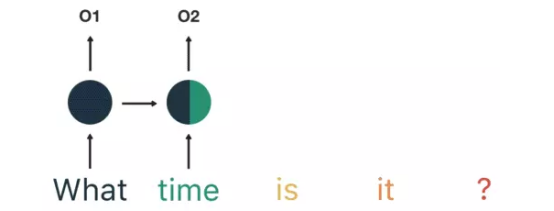
我们重复这个过程,直到最后一步。你可以通过最后一步看到RNN编码了前面步骤中所有单词的信息。

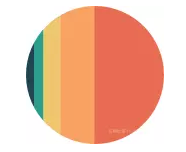
可能你已经注意到隐藏状态中奇怪的颜色分布,这是说明RNN为短期记忆的问题,也就是RNN梯度消失的问题,这在其他神经网络架构中也很普遍。由于RNN处理很多步骤,因此难以保留先前步骤中的信息。正如你所看到的,在最后的时间步骤中,“what”和“time”这个词的信息几乎不存在。
RNN会受到短期记忆的影响,那么我们如何应对呢?为了减轻短期记忆的影响,研究者们创建了两个专门的递归神经网络,一种叫做长短期记忆或简称LSTM。另一个是门控循环单位或GRU。LSTM和GRU本质上就像RNN一样,但它们能够使用称为“门”的机制来学习长期依赖。这些门是不同的张量操作,可以学习添加或删除隐藏状态的信息。由于这种能力,短期记忆对他们来说不是一个问题。
总而言之,RNN适用于处理序列数据以进行预测,但却会受到短期记忆的影响。RNN的短期存储问题并不意味着要完全跳过它们并使用更多进化版本,如LSTM或GRU。RNN具有更快训练和使用更少计算资源的优势,这是因为要计算的张量操作较少。当你期望对具有长期依赖的较长序列建模时,你应该使用LSTM或GRU。关于LSTM GRU我们将会在后面一一为同学们讲解。
然后我们新建一个CreateModel.py文件,使用RNN搭建的网络结构如下,5000是我们字典的长度。
def model():input_tensor = Input(shape=(6, 5000))rnn= SimpleRNN(256, return_sequences=True)(input_tensor)dropout = Dropout(0.5)(rnn)rnn= SimpleRNN(256)(dropout)dropout = Dropout(0.5)(rnn)dense = Dense(5000, activation='softmax')(dropout)model = keras.models.Model(inputs=input_tensor, outputs=dense)return model
开始训练
接着,我们可以定义参数,编译模型进行训练了:
batch_size=256split=0.9=get_data()# 打乱数据random.shuffle(cont)# gan=将数据分为训练和测试=cont[:int(len(cont)*split)],cont[int(len(cont)*split):]# gan=gen_data(cont,wordlist,16)model=model()model.summary()# model=keras.models.load_model('www.h5')='categorical_crossentropy',optimizer=keras.optimizers.Adam(3e-3), metrics=['accuracy'])=batch_size),steps_per_epoch=len(x_train*50)//batch_size,validation_data=gen_data(x_test,wordlist,batch_size=batch_size),validation_steps=len(x_test*50)//batch_size,epochs=10)model.save('www.h5')
当然,为了更好地在训练过程中,看到识别的结果,我们还可以自定义一个回调函数可视化训练过程的诗句。
class show(callbacks.Callback):def __init__(self):self.model=modeldef on_epoch_end(self, epoch, logs=None):self.model.save('www.h5')def on_epoch_begin(self, epoch, logs=None):for _ in range(3):ranint=random.randint(1,20000)words=cont[ranint].split(',')[0]+','# xdata=one_host(words,5000,1)for i in range(18):x_data = words[-6:]cont_index = [wordlist.index(i) if i in wordlist else wordlist.index('z') for i in x_data]next_ = self.peridct([cont_index])words += next_print('\n-----------------------------')print(words)def peridct(self,char):xdata=one_host(char,5000,1)xdata=xdata.reshape(-1,6,5000)p = self.model.predict(xdata)return wordlist[p.argmax()]show=show()
然后记得在fit中调用一下
=batch_size),steps_per_epoch=len(x_train*50)//batch_size,validation_data=gen_data(x_test,wordlist,batch_size=batch_size),validation_steps=len(x_test*50)//batch_size,epochs=10,callbacks=[show])
训练过程可视化
第一个周期(第一句是我们从诗句列表中随机取的,后面的是预测的结果,此时还没学到诗的格式):

第二个周期(可以看到已经学到了5言绝句的格式了,但是诗句不能为我们所理解):

多个训练周期之后:

后续预告
接下来,会给大家带来藏头诗、随机生成诗句、以及给出首句的五言绝句生成: