
学好Python,必须熟练掌握的几种数据结构【文末送书】
导读
伟大先辈尼古拉斯·沃斯曾这样说过:程序=数据结构+算法,这在程序员界堪称经典的公式,其意义不亚于物理学界中的E=mc2。实际上,其意在阐明编程的核心在于掌握数据结构与算法!如果把一名优秀的程序员比作武林高手,那么数据结构即为招式,算法则是内功,二者缺一不可。当下,Python语言非常火热,学好Python就必须掌握好这些数据结构的常用用法。

python提供了多种数据结构可供选择,除了全局的列表、字典、集合和元组4个基本类型外,collections模块提供了一些定制化的数据结构集合类数据结构,array和heapq模块则分别提供了数组和堆数据结构,本文就这4种类型加以分别介绍。
本文所指数据结构特指容器类数据结构,不包含int、str、boolean等单数据类型。
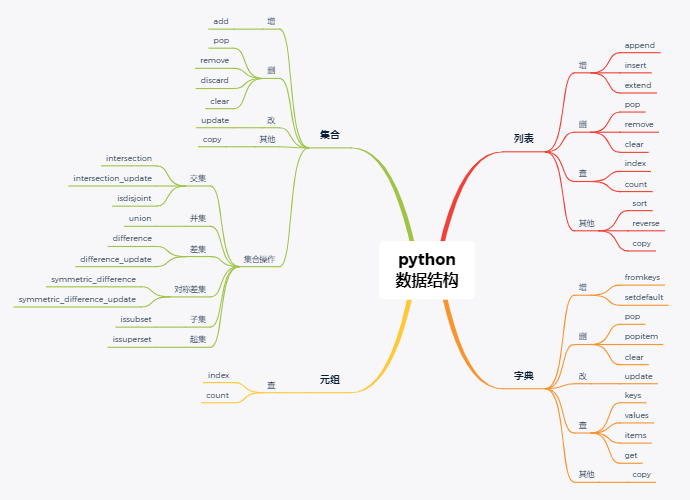
python全局内置的容器类数据结构主要有4种:分别是列表(list)、字典(dict)、集合(set)和元组(tuple),这个排名先后顺序也基本代表了使用频率,尤其是列表和字典,堪称是python中的万能数据结构,其简单而强大的接口、灵活多变的推导式用法,注定了二者可以满足大部分场景使用需求。其中:
list的最大特点是支持多种类型的元素(包括嵌套其他数据结构),且支持灵活的切片操作,再辅以强大的列表推导式,必须熟练掌握;
dict的最大特点是以键值对形式保存数据,提供了O(1)复杂度的查找和插入操作,在某些要求计算效率的场景下尤为好用;
set某种程度上可看做是仅有key的dict结构,其底层也是哈希实现,元素间具有无序特性。最为便捷的是,set提供了数学意义上的集合操作,例如交、并、补和差集等,这在某些场景下颇为奏效;
tuple在python中是略显鸡肋的一种数据结构,与list的唯一区别在于tuple是不可变类型,所以不支持元素的插入、更改和删除操作。当然,某些场景下,tuple的不可变特性也具有一些好的用法,例如防止对只读数据的误编辑、作为字典的key(list因其可变性,所以不能作为字典的key)
更为完整的4种通用数据结构可以参考历史文章:Simple is better than complex——python中4大数据结构常用接口简介!
在掌握了内置的4大通用数据结构之后,如果习惯于刷LeetCode等平台的算法题,那么就一定会用到collections模块,这堪称是一个装B炫酷的神技。

在collections内置的9种数据结构中,个人使用最为频繁的当属其中的3种,分别是:
Counter,计数器。继承自dict数据结构,接收一个可迭代对象或字典类型,统计所有元素及其出现的次数,且统计元素保留迭代对象中元素出现的先后顺序,并将元素及其计数值存储为key:value值。这里,计数可以是任何整数值,包括0和负数。常用的结果处理方法包括:most_common(),统计出现次数最多的元素及次数、结果集合的加减交并等操作,其中most_common是最为常用的方法;
defaultdict:默认字典。也是继承自dict数据结构,与通用dict的最大区别在于默认字典的value自带初始化数据类型,例如defaultdict(int)表示默认value为整数0的字典结构,defaultdict(list)则表示默认value为列表的字典结构,虽说只是增加了一个初始化的操作,但却节省了待查找key值是否存在及相应初始化操作,还是非常方便的;
deque:双端队列。学习数据结构中必然会涉及到栈和队列,其中栈意味着后入先出,而队列则是先入先出,二者分别在某些场景下有着非常高效的操作。由于栈的实现完全可由普通列表实现,而队列则不然(用列表简单实现队列时并不能保证O(1)的入列和出列)。实际上,deque是一个基于链表实现的双端队列,并且提供了与普通列表高度相近的方法名,例如pop(),popleft(),append(),appendleft(),extend()和extendleft(),由名字即可联想其使用。但其一个缺点是不支持切片,毕竟是底层基于链表实现的数据结构。在广度优先遍历算法中,个人习惯使用deque。
关于这3种好用的数据结构,更为详尽的使用和实战详见Python的内置容器不止有list/dict/set/tuple!
在其他语言中,array基本上是非常常用的数据结构,但由于python语言的动态特性,不同数据类型也可以混搭,所以list这种万金油般的存在便占尽了风头。但也不得不承认的一个事实是,list数据结构效率并不高。为此,当list中所有数据类型一致时,尤其是全为数值型元素时,选用array实际上是更为明智的选择。
python提供了专用的array模块,该模块提供了array方法,接收一个数据类型和一个可迭代对象完成初始化操作。实际上,array的方法接口几乎沿用了列表的接口思想,包括元素的增加和减少,甚至函数名称都较为相近,例如都有切片操作和append/pop/remove接口等。其与list的主要区别在于:
array 和list均为序列类型,占用连续内存空间,但array更为紧凑,且所有元素类型必须相同;
list支持嵌套复杂数据结构,而array不支持。实际上,array支持的类型字符包括b, B, u, h, H, i, I, l, L, q, Q, f or d
list接口更为丰富,操作方法更为灵活(包括列表推导式),但array操作效率更高
然而,论操作简便其不如list,论功能强大则又输于numpy,实际上个人除了学习一下array之外,真的就没再用过了……
一般而言,学过数据结构之后总要学些算法,而在众多算法之中,排序可谓是最为基础却又相当经典的算法场景之一。而在学习排序算法时,总会遇到一种叫做堆排序的算法,其理想情况下可以实现与归并排序、快速排序相同的算法复杂度——O(nlogn),主要得益于其特定的数据结构:堆。具体又分为大顶堆和小顶堆,其实本质是一样的。

虽然长的像棵树,但堆的底层其实就是一个数组。
抛却堆的具体实现不说,堆的应用场景其实也是较为受限的,最为擅长的当属寻找TOPK,当K=1时则可循环实现排序的过程,具体可参考历史文章python排序算法。所以这也注定了堆数据结构中最为常用的方法包括:
heapify,将一个列表按堆的方式重新组织存储
heappop,从堆中弹出一个元素,并保持堆的特性
heappush,向堆中加入一个元素,并保持堆的特性
nlargest,返回n个最大值(大顶堆)
nsmallest,返回n个最小值(小顶堆)
最后,感谢北京大学出版社赞助,送书《数据结构与算法基础Python语言实现》1本:
通过本书,你将全面系统的掌握常用数据结构类型及Python实现、经典算法原理,对于Python初学者来说十分有用!
送书规则:截至周六12月19日上午10:00,公众号后台查看阅读最多和分享最多前3名中挑选一名幸运读者,届时会通过截图公布结果并添加微信联系。注:限于公众号当前体量,送书数量有限,但只要稍微刷一刷历史文章的阅读和转发,就可轻松上榜TOP3。送书活动后续将持续进行,敬请多多分享在看点赞。
相关阅读: