浏览器渲染原理
前言
当我们输入一个url之后,页面会在很短时间内呈现给我们。这个过程其实相当复杂,浏览器在背后给我做了很多的事。除去一些诸如DNS解析的等边角料工作,整体可以大致分为网络和渲染。
渲染
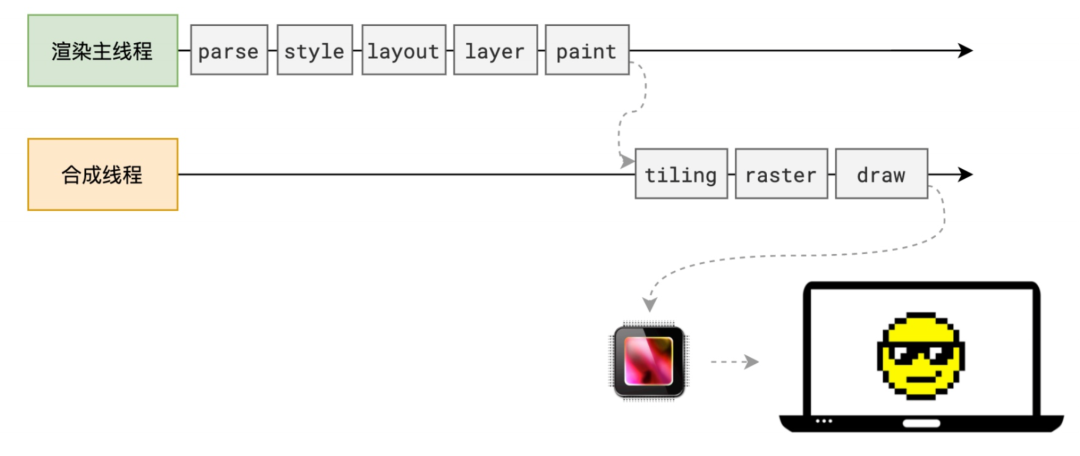
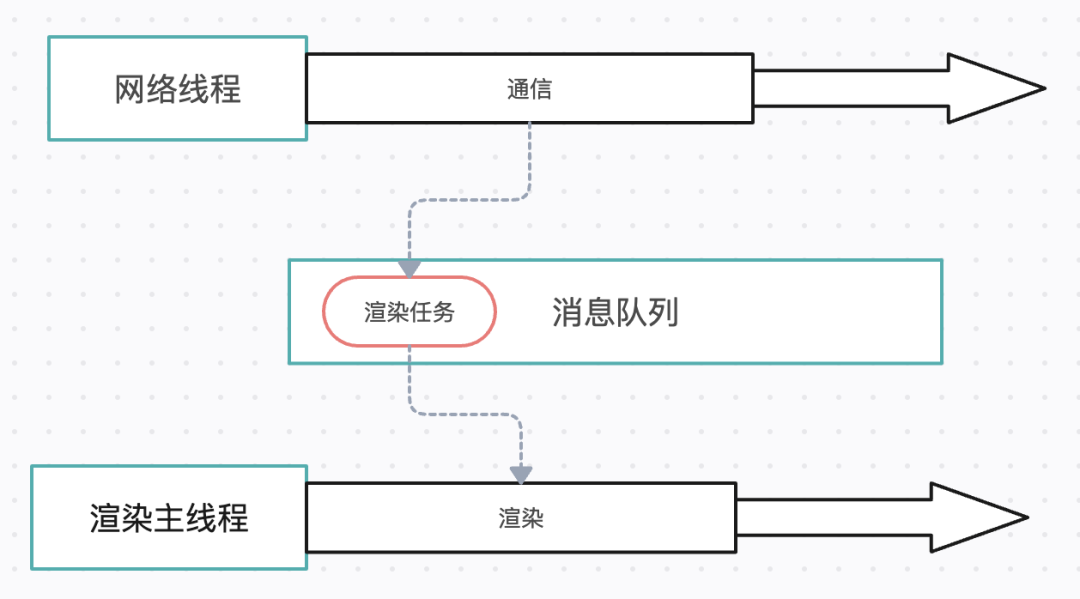
浏览器的网络线程接收到HTML文档后,会生成一个渲染任务,并将其添加到渲染主线程的消息队列。在事件循环机制的作用下,渲染主线程会取出消息队列中的渲染任务,开启渲染流程。
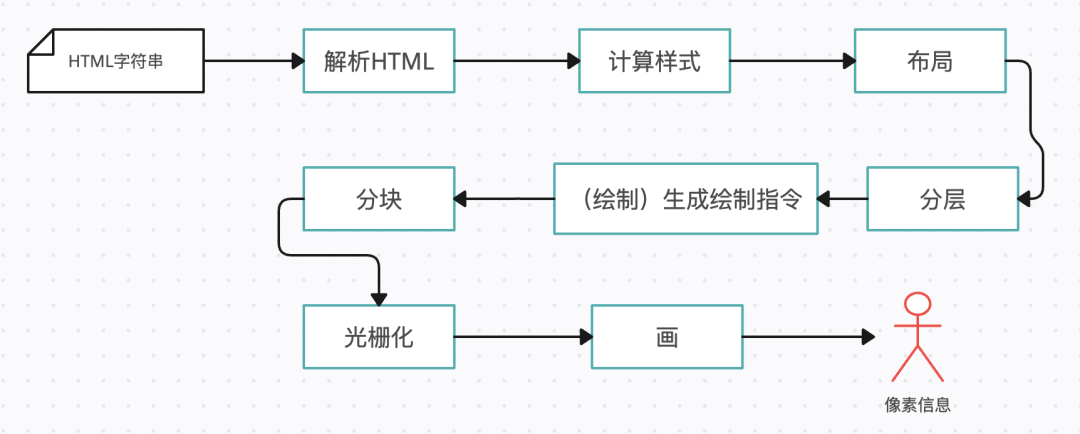
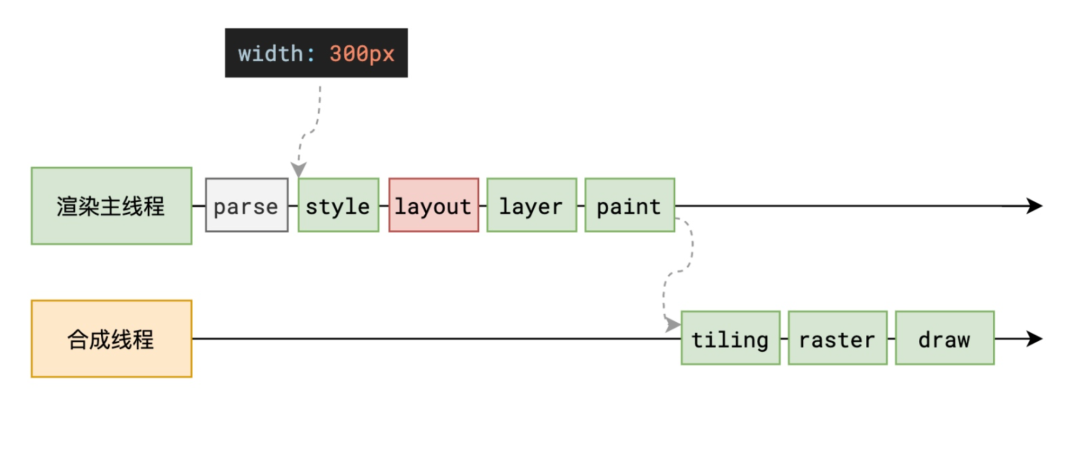
整个渲染流程分为多个阶段:解析HTML、计算样式、布局、分层、绘制、分块、光栅化、画。每个阶段都有明确的输入输出,上一阶段的输出会成为下一阶段的输入,这样整个渲染过程就形成了一条组织严密的生产流水线。
解析HTML-Parse HTML
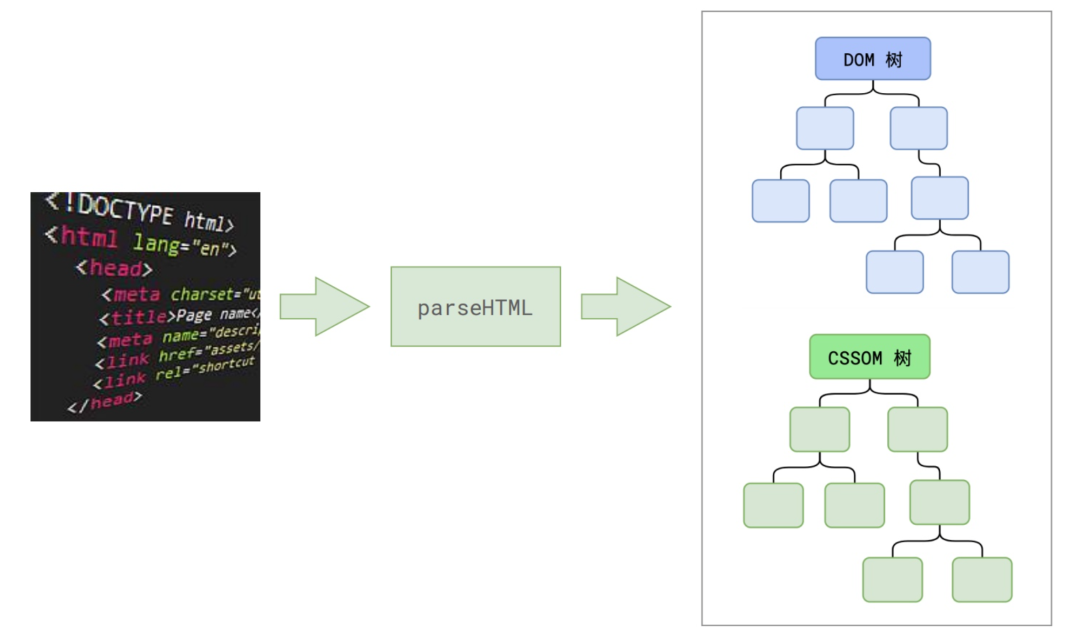
第一步就是解析 HTML,生成 DOM 树。
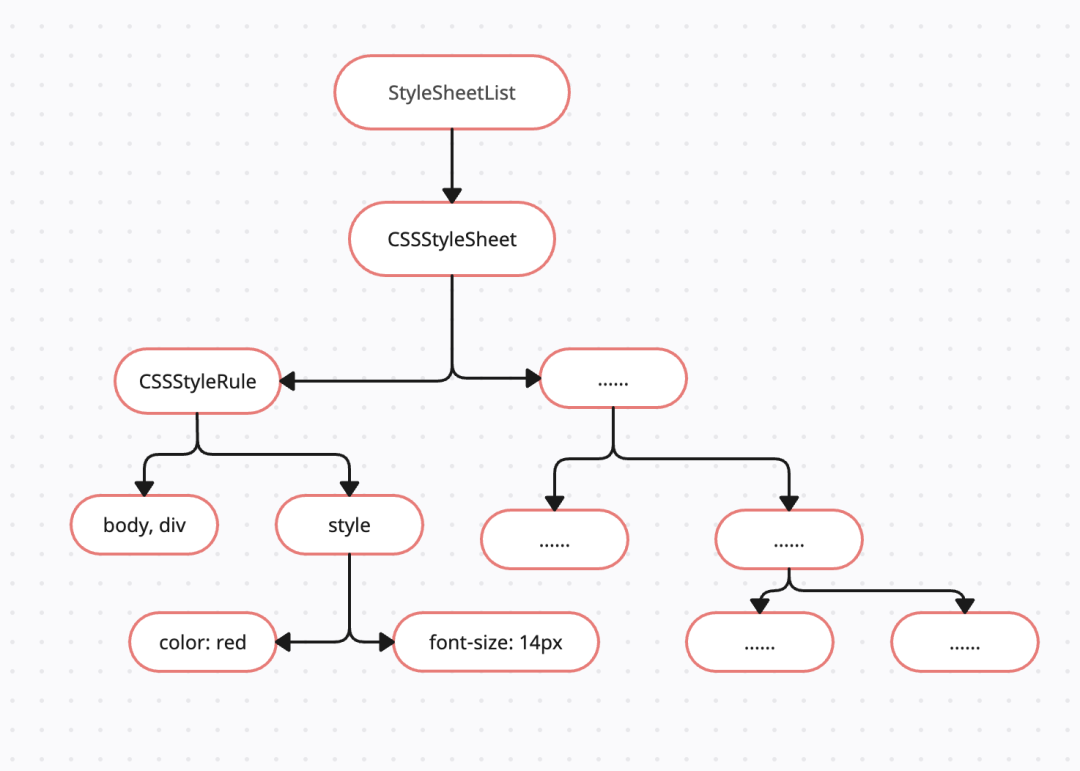
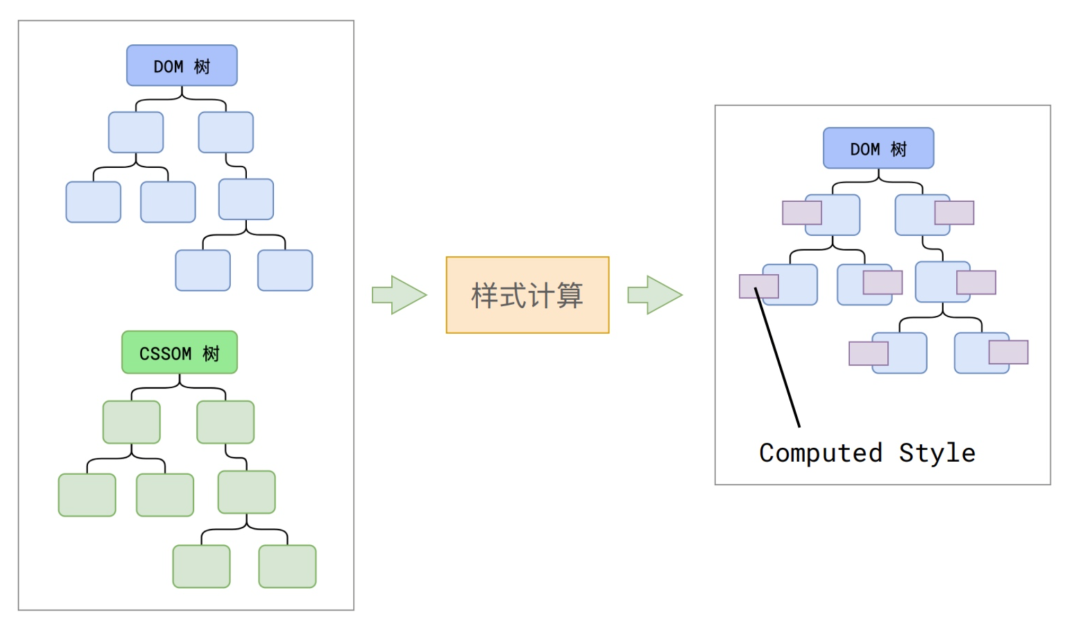
在主线程上解析HTML字符串,得到DOM树(html元素、文本、注释等节点的信息)和CSSOM树。
CSSOM树会包含浏览器默认样式、内部样式、外部样式、内联样式:
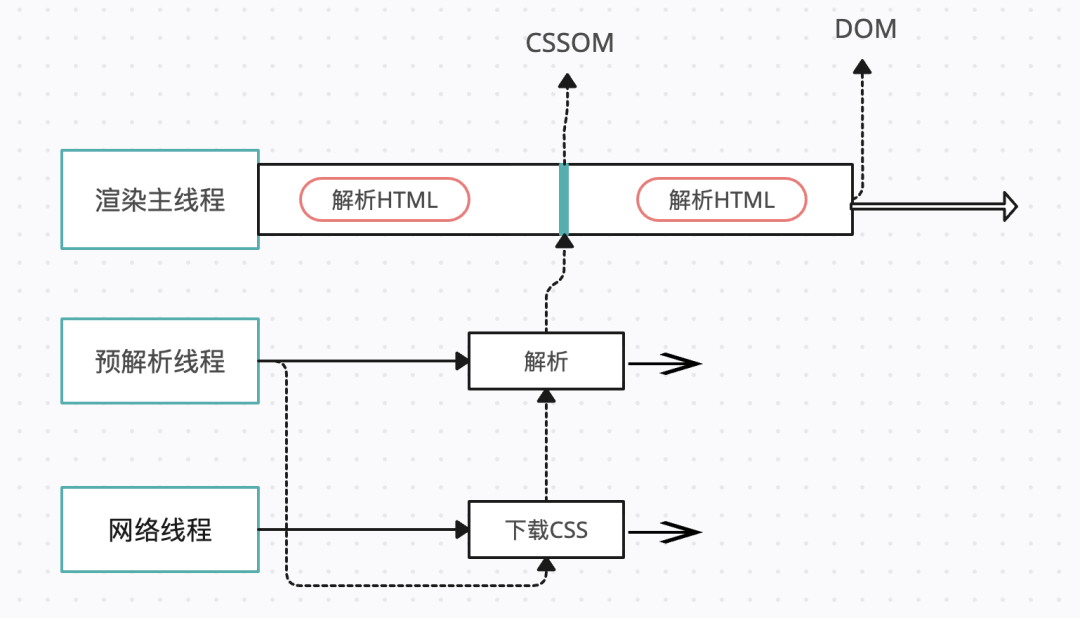
在解析过程中,遇到CSS就解析CSS,遇到JS就执行JS。为了提高解析效率,浏览器会在解析之前,启动一个预解析线程,率先下载外部的CSS文件和JS文件。
如果主线程解析到link的位置,此时link的CSS资源文件还没下载解析好,主线程不会等待,继续解析后面的HTML。这是因为下载和解析CSS是在预解析线程中进行的,这就是CSS不会阻塞HTML解析的原因。
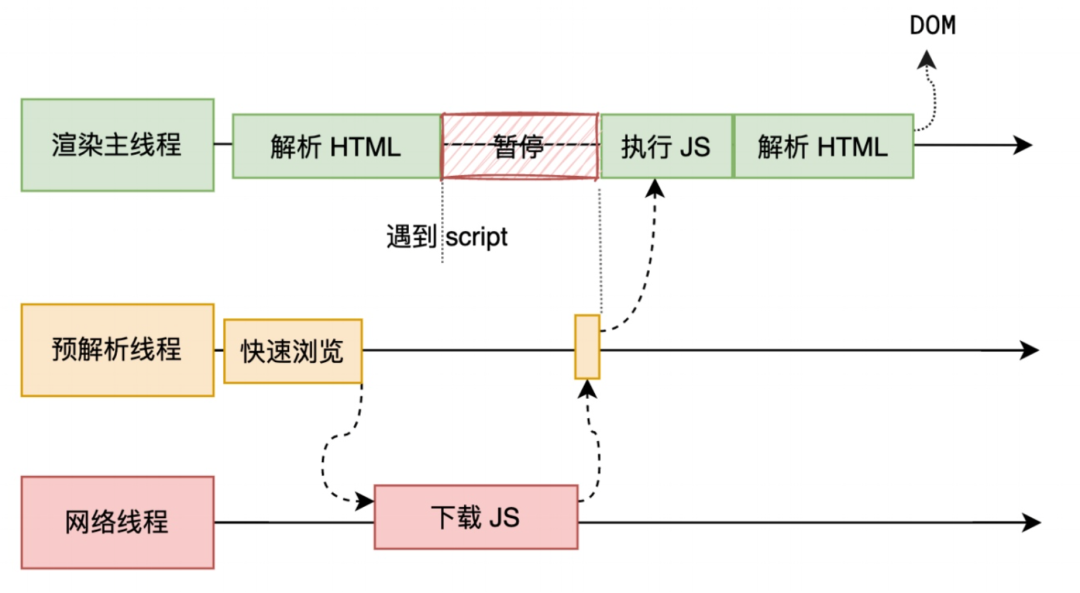
因此,如果我们想加快首屏的渲染,建议将 script 标签放在 body 标签底部。
当然现代浏览器都提供了非阻塞的下载方式,async和defer。
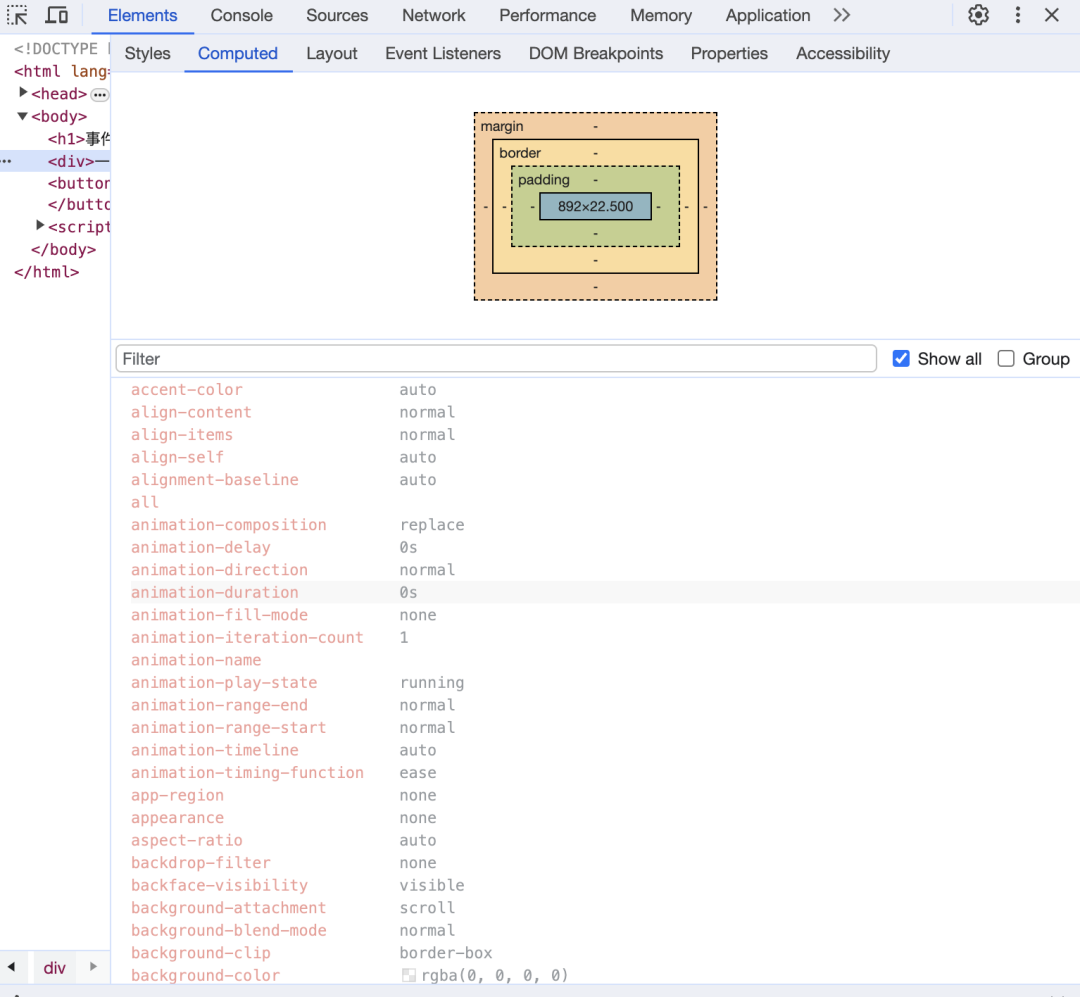
得到每个节点计算后的最终样式,如下图,我们可以看到任何元素都会有全量的CSS属性:
• 确定声明值
• 层叠冲突 (重要性、特殊性、源次性)
• 使用继承
• 使用默认值
渲染主线程会遍历整棵DOM树,依次计算出DOM树的每个节点的最终样式,称为 Computed Style。在这个过程,很多预设值会变成绝对值,相对单位会变成绝对单位。这一步完成之后,将会得到一棵带有样式的DOM树。
根据每个节点的样式信息算出节点的几何信息(尺寸和位置),得到布局(Layout)树。
对于一个元素来说,它的尺寸和位置经常与它的包含块(containing block)有关,即我们经常说的它是相对于哪个元素,例如 width: 100% 。
如何确定包含块?
确定一个元素的包含块的过程完全依赖于这个元素的position属性:
• static、relative、sticky:包含块可能由它的最近的祖先块元素(如 inline-block、block )
• absolute:由它的最近的 position 的值不是 static 的祖先元素
• fixed:在连续媒体的情况下包含块是viewport
• absolute或fixed:包含块也可能是由满足以下条件的最近父级元素
○ transform或 perspective 的值不是 none。
○ will-change的值是 transform 或 perspective。
○ filter的值不是 none
○ contain的值是 paint
○ backdrop-filter的值不是 none
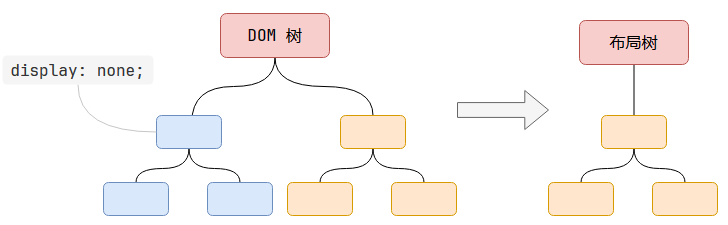
DOM树和Layout树不一定是一一对应的,如隐藏(dispay: none)的元素就不会出现在Layout树中;
又如伪元素在DOM树中并不存在,但是会出现在Layout树中,因为它拥有几何信息。
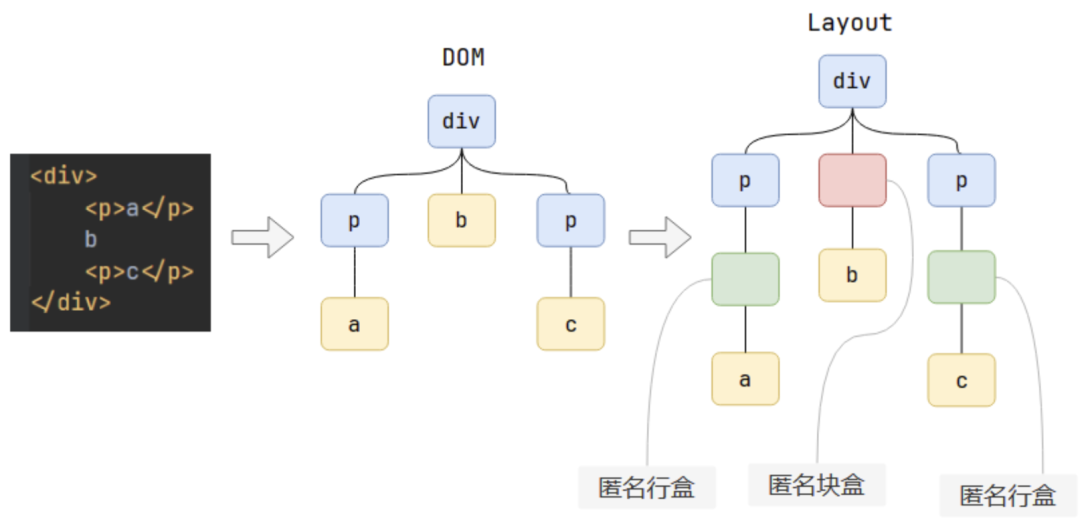
文本内容必须在行盒中,行盒和块盒不能相邻。
如果在块盒中直接写入内容,则会在中间生成一个匿名行盒;如果块盒和行盒相邻,则为行盒外部生成一个匿名块盒。
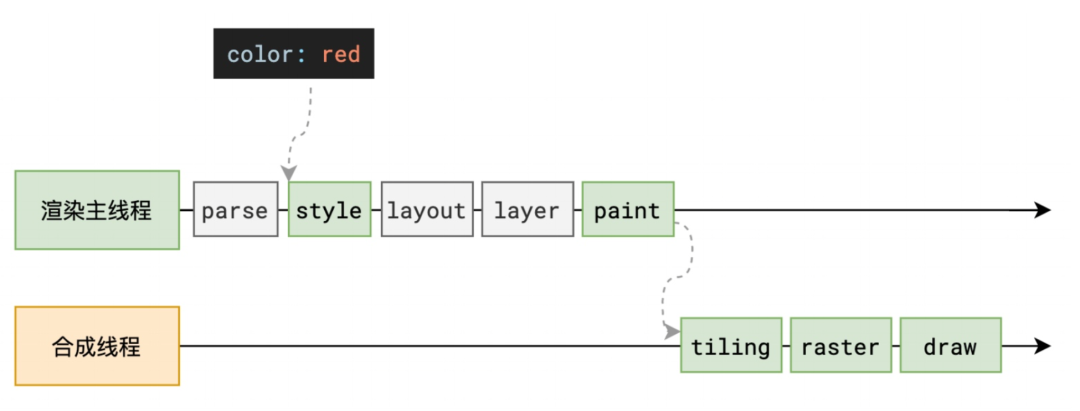
重排(Reflow) 的本质就是重新计算Layout布局树。当进行了会影响布局树的操作后,需要重新计算布局树,就会引发重新Layout。 浏览器为了避免连续的多次操作导致布局树反复计算,就会合并这些操作,生成一个渲染任务,等到下一次事件循环再进行计算。所以,改动CSS属性所造成的Reflow是异步完成的。 正因为如此,当 JS 获取布局属性时(如clientWidth),就可能造成无法获取到最新的布局信息。 于是浏览器在反复权衡下,最终决定获取属性时,立即 Reflow(同步)。
渲染主线程将会使用一套复杂的策略对整个布局树进行分层。分层的好处在于,将来某一层改变之后,仅会对该层进行后续处理,不影响其他分层,从而提升效率。
首先需要生成绘制的指令,主线程会为每个分层生成绘制指令集,表明如何进行绘制,用于描述这一层的内容如何画出来。
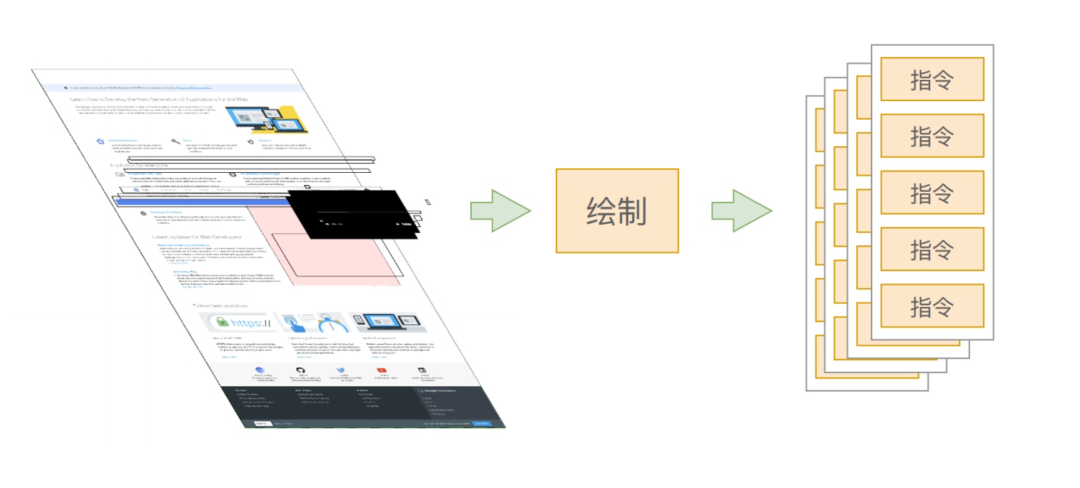
移动画笔到 (x,y) 绘制宽为w,高为h的矩形......
实际上,canvas是浏览器将绘制过程封装后提供给开发者的工具。
重绘(repaint) 的本质就是重新根据分层信息计算了绘制指令。当改动可见样式后,就需要重新计算绘制指令,引发 Repaint。由于元素的布局(Layout)信息也属于可见样式,所以 Reflow 一定会引起 Repaint。
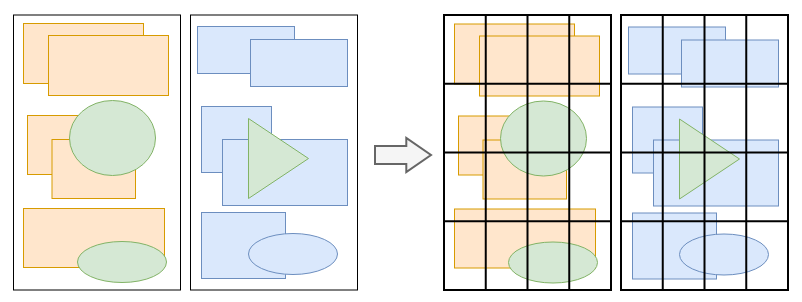
分块-Tiling
分块会将每一层分成多个小的区域。
 完成生成绘制指令集之后,主线程会将每个图层的绘制指令信息提交给合成线程,剩余工作将由合成线程完成。
完成生成绘制指令集之后,主线程会将每个图层的绘制指令信息提交给合成线程,剩余工作将由合成线程完成。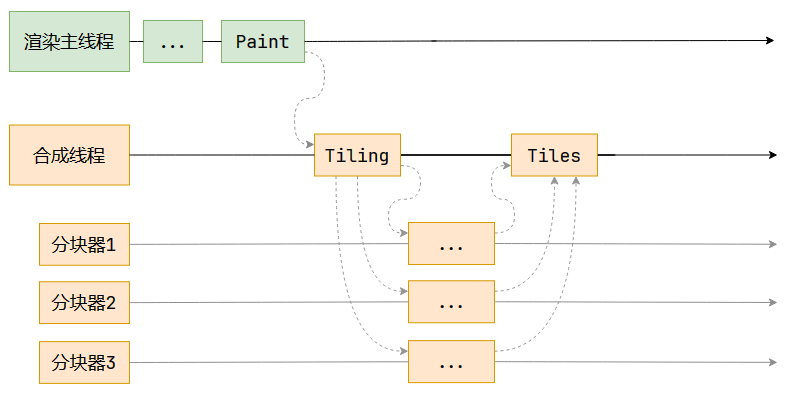 合成线程首先会对每个图层进行分块,将其划分成更多的小区域。它会从线程池中拿出多个线程来完成分块工作。
合成线程首先会对每个图层进行分块,将其划分成更多的小区域。它会从线程池中拿出多个线程来完成分块工作。Tips: 合成线程和渲染主线程都位于渲染进程里。
分块完成后,会进入光栅化阶段。合成线程会将块信息交给GPU进程,以极高的速度完成光栅化,GPU会开启多个线程来完成光栅化,并且优先处理靠近视口的块(类似于懒加载策略,以提高性能)。
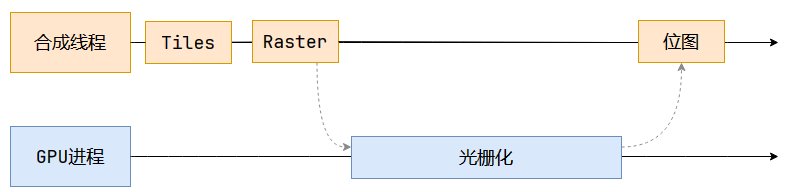
光栅化就是将每个块变成位图(像素点)。
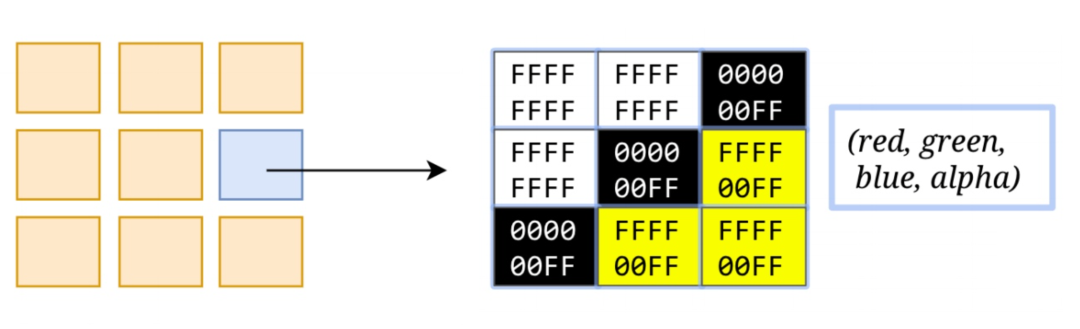
合成线程会计算出每个位图在屏幕上的位置,交给GPU进行最终的呈现。
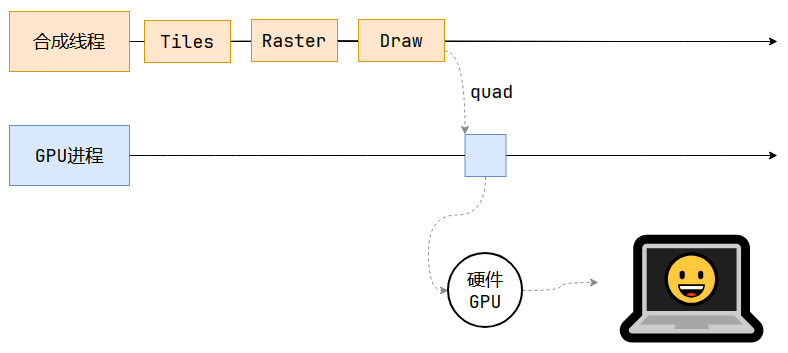
合成线程拿到每个层、每个块的位图后,生成一个个的quad(指引)信息,指明位图信息位于屏幕上的位置,以及会考虑到transform的旋转、偏移、缩放等矩阵变换。
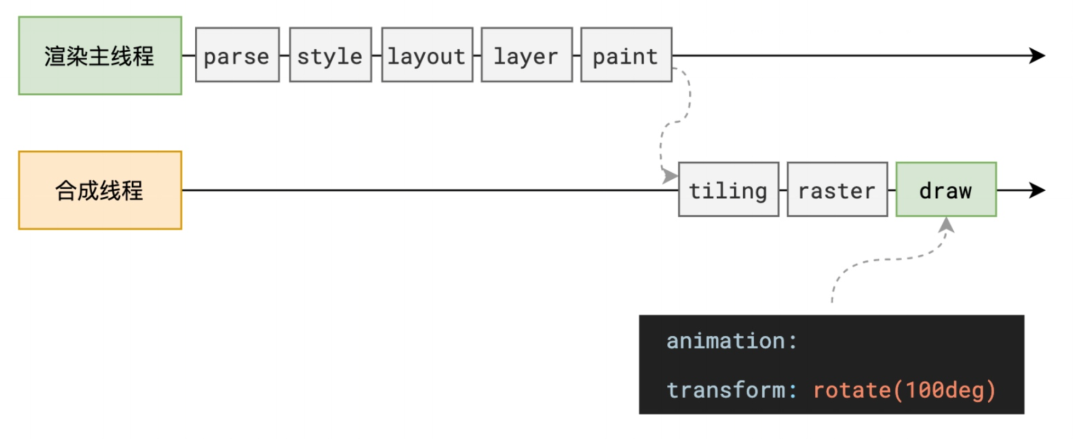
如上图中,为什么合成线程不直接将结果交给硬件,将内容显示到屏幕上,而要先转交给GPU进程,由GPU进程转发呢?
其实是因为合成线程和渲染主线程都属于渲染进程,渲染进程处于沙盒中,无法进行系统调度,即无法直接与硬件GPU通信,所以需要GPU进程中转一下。
总结
整体的流程如下: